


强化学习框架RLlib教程004:Training APIs的使用(三)高级pythonAPI
目录
定制训练流程(Custom Training Workflows)
全局协调(Global Coordination)
回调函数和自定义准则(Callbacks and Custom Metrics)
可视化自定义的度量(Visualizing Custom Metrics)
自定义探索行为(Customizing Exploration Behavior)
训练过程中自定义评估(Customized Evaluation During Training)
重写轨迹(Rewriting Trajectories)
课程式学习(Curriculum Learning)
参考资料
|
定制训练流程(Custom Training Workflows) |
在基础的training例子中,Tune在每一次训练迭代中都会调用一次train()并且报告和返回新的训练结果。有时候我们相对整个训练过程进行控制,但是还想在Tune内运行。Tune支持自定义的训练函数可以用来实现自定义训练工作流
即便是非常细粒度的训练过程的控制,你可以使用RLlib的低阶的building blocks直接构建一个完全定制化的训练工作流。
|
全局协调(Global Coordination) |
有时,我们需要协调运行在不同进程中的代码。比如,维护一个全局变量,或者policies使用的超参数。Ray提供了一个通用的方式来实现,即actors。这些actors被分配一个全局名字,并且对他们的处理可以通过这个名字获取。例如,想维护一个共享的全局计数器,他根据环境做累加,并且由driver程序在不同时期读取:


import os os.environ["CUDA_VISIBLE_DEVICES"] = '3' import ray import numpy as np import ray.rllib.agents.ppo as ppo from ray.tune.logger import pretty_print ray.init() import gym # Get a reference to the policy from ray.rllib.agents.ppo import PPOTrainer @ray.remote class Counter: def __init__(self): self.count = 0 def inc(self, n): self.count += n def get(self): return self.count # on the driver counter = Counter.options(name="global_counter").remote() print(ray.get(counter.get.remote())) # get the latest count # in your envs counter = ray.get_actor("global_counter") counter.inc.remote(1) # async call to increment the global count print(ray.get(counter.get.remote())) # get the latest count
Ray actor提供了高水平的性能,因此在更复杂的情况下,它们可以用于实现通信模式,如参数服务器和allreduce。
|
回调函数和自定义准则(Callbacks and Custom Metrics) |
在评估policy的时候可以添加回调函数,这个回调函数可以获取到这个episode里面的状态。某些回调,如on_postprocess_trajectory、on_sample_end和on_train_result,也是可以对中间数据或结果应用自定义后处理的地方。
用户自定义的状态会被存在episode.user_data字典中,自定义的评估值会被保存在episode.custom_metrics 字典中。这些自定义的评估将被聚合并记录在训练结果中。
|
可视化自定义的度量(Visualizing Custom Metrics) |
可以像任何其他training结果一样访问和可视化自定义的度量:
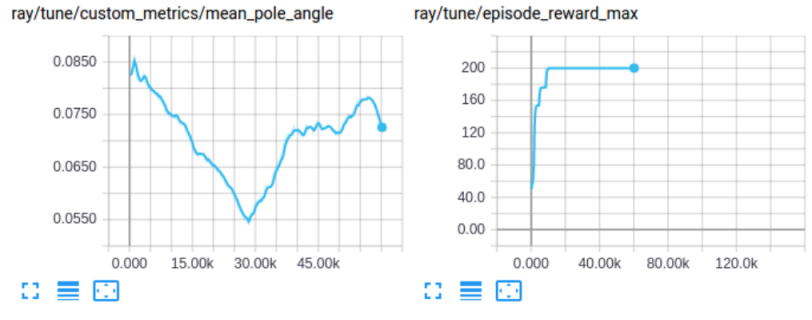
|
自定义探索行为(Customizing Exploration Behavior) |
RLlib提供了一套统一的高层级的API来配置和自定义agent的探索行为,包括从动作分布(随机或固定)中抽取action(how and whether)。这个可以通过内嵌Exploration类来做,可以用Trainer.config["exploration_config"]来配。除了使用内嵌的类,也可以实现内嵌类的子类,然后在config中使用。
每一个policy都有一个Exploration(或其子类)的对象。这个Exploration对象由Trainer’s config[“exploration_config”] 字典创造:
# in Trainer.config:
"exploration_config": {
"type": "StochasticSampling", # <- Special `type` key provides class information
"[c'tor arg]" : "[value]", # <- Add any needed constructor args here.
# etc
}
# ...
下表列出了内嵌的Exploration子类和agent默认使用的情况:
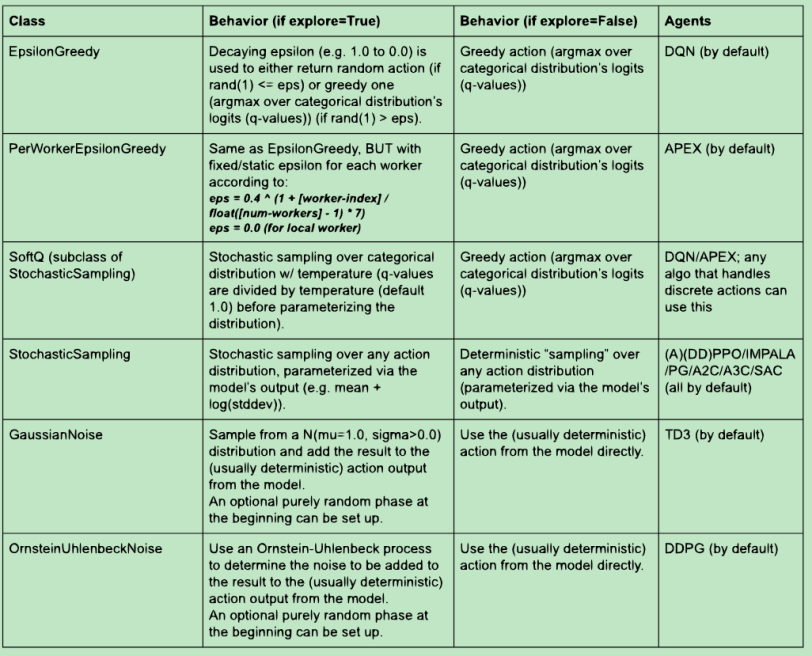
Exploration类实现了get_exploration_action 方法,在里面可以定义额外的探索。它接收模型的输出、action分布类、模型本身、时间步(全局env-sampling步)以及explore开关,输出一个动作和概率:
def get_exploration_action(self,
distribution_inputs,
action_dist_class,
model=None,
explore=True,
timestep=None):
"""Returns a (possibly) exploratory action and its log-likelihood.
Given the Model's logits outputs and action distribution, returns an
exploratory action.
Args:
distribution_inputs (any): The output coming from the model,
ready for parameterizing a distribution
(e.g. q-values or PG-logits).
action_dist_class (class): The action distribution class
to use.
model (ModelV2): The Model object.
explore (bool): True: "Normal" exploration behavior.
False: Suppress all exploratory behavior and return
a deterministic action.
timestep (int): The current sampling time step. If None, the
component should try to use an internal counter, which it
then increments by 1. If provided, will set the internal
counter to the given value.
Returns:
Tuple:
- The chosen exploration action or a tf-op to fetch the exploration
action from the graph.
- The log-likelihood of the exploration action.
"""
pass
在最高级别,Trainer.compute_action 和 Policy.compute_action(s)方法有一个explore开关,会传给xploration.get_exploration_action。如果是None,Trainer.config[“explore”] 会被使用。因此config[“explore”]描述了policy的默认行为,他可以直接关闭探索行为(用于评估的时候)
下面是一些例子,展示了不同的Trainer config使用不同的探索行为:
# All of the following configs go into Trainer.config.
# 1) Switching *off* exploration by default.
# Behavior: Calling `compute_action(s)` without explicitly setting its `explore`
# param will result in no exploration.
# However, explicitly calling `compute_action(s)` with `explore=True` will
# still(!) result in exploration (per-call overrides default).
"explore": False,
# 2) Switching *on* exploration by default.
# Behavior: Calling `compute_action(s)` without explicitly setting its
# explore param will result in exploration.
# However, explicitly calling `compute_action(s)` with `explore=False`
# will result in no(!) exploration (per-call overrides default).
"explore": True,
# 3) Example exploration_config usages:
# a) DQN: see rllib/agents/dqn/dqn.py
"explore": True,
"exploration_config": {
# Exploration sub-class by name or full path to module+class
# (e.g. “ray.rllib.utils.exploration.epsilon_greedy.EpsilonGreedy”)
"type": "EpsilonGreedy",
# Parameters for the Exploration class' constructor:
"initial_epsilon": 1.0,
"final_epsilon": 0.02,
"epsilon_timesteps": 10000, # Timesteps over which to anneal epsilon.
},
# b) DQN Soft-Q: In order to switch to Soft-Q exploration, do instead:
"explore": True,
"exploration_config": {
"type": "SoftQ",
# Parameters for the Exploration class' constructor:
"temperature": 1.0,
},
# c) PPO: see rllib/agents/ppo/ppo.py
# Behavior: The algo samples stochastically by default from the
# model-parameterized distribution. This is the global Trainer default
# setting defined in trainer.py and used by all PG-type algos.
"explore": True,
"exploration_config": {
"type": "StochasticSampling",
},
|
训练过程中自定义评估(Customized Evaluation During Training) |
RLlib将会报告在线训练的回报值,然而在一些场合你也许想用特殊的设置计算回报(比如关闭exploration或者使用特殊的环境配置)
你可以在训练中评估policies通过设置evaluation_interval config,然后还可选evaluation_num_episodes, evaluation_config, evaluation_num_workers, and custom_eval_function参数
默认情况下,exploration是evaluation_config里保持不变的。然而你可以关闭所有的exploration通过:
# Switching off exploration behavior for evaluation workers
# (see rllib/agents/trainer.py)
"evaluation_config": {
"explore": False
}
这有一个端到端的例子,展示了如何设置自定义的在线评估 custom_eval.py。注意:如果你只想在训练结束时评估policy,你可以设置 evaluation_interval: N,N表示停止之前训练迭代数。
|
重写轨迹(Rewriting Trajectories) |
注意:在回调函数on_postprocess_traj 里,你可以获取trajectory batch的所有信息和其他训练的状态信息。这可以用来重写trajectory,在以下情况可能有用:
1.回溯奖励之前的时间步(基于info里的值)
2.添加一个model-based 好奇奖励给reward(你可以训练这个模型使用自己的监督方法)
|
课程式学习(Curriculum Learning) |
有两种方式实现课程式学习。在课程式学习中,agent的任务是随着时间调整训练过程。假设有一个环境类,其中有一个set_phase() 方法,我们可以随着时间调整任务的难度:
方法一:
在调用train()期间使用Trainer的API并更新环境。这个例子展示了trainer在Tune函数中的使用:
import ray
from ray import tune
from ray.rllib.agents.ppo import PPOTrainer
def train(config, reporter):
trainer = PPOTrainer(config=config, env=YourEnv)
while True:
result = trainer.train()
reporter(**result)
if result["episode_reward_mean"] > 200:
phase = 2
elif result["episode_reward_mean"] > 100:
phase = 1
else:
phase = 0
trainer.workers.foreach_worker(
lambda ev: ev.foreach_env(
lambda env: env.set_phase(phase)))
ray.init()
tune.run(
train,
config={
"num_gpus": 0,
"num_workers": 2,
},
resources_per_trial={
"cpu": 1,
"gpu": lambda spec: spec.config.num_gpus,
"extra_cpu": lambda spec: spec.config.num_workers,
},
)
方法二:
使用回调API来更新新的训练结果的环境
import ray
from ray import tune
def on_train_result(info):
result = info["result"]
if result["episode_reward_mean"] > 200:
phase = 2
elif result["episode_reward_mean"] > 100:
phase = 1
else:
phase = 0
trainer = info["trainer"]
trainer.workers.foreach_worker(
lambda ev: ev.foreach_env(
lambda env: env.set_phase(phase)))
ray.init()
tune.run(
"PPO",
config={
"env": YourEnv,
"callbacks": {
"on_train_result": on_train_result,
},
},
)
|
参考资料 |
https://docs.ray.io/en/latest/rllib.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号