
强化学习框架RLlib教程002:Training APIs(一)快速入门与配置项
目录
开场(Getting Started)
评估训练策略(Evaluating Trained Policies)
指定参数(Specifying Parameters)
指定资源(Specifying Resources)
延伸指南(Scaling Guide)
常用参数
调好的参数文件(Tuned Examples)
参考资料
|
开场(Getting Started) |
在较高的层次上,RLlib提供了一个 Trainer 类,它保存着与环境交互的策略。通过trainer的接口,可以对策略进行训练、设置断点或计算一个动作。在多智能体训练(multi-agent training)中,trainer同时管理多个策略的查询(根据输入计算输出)和优化(训练策略网络)。
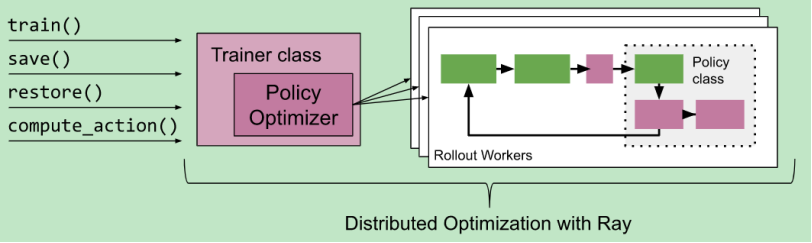
如上图所示:一个Trainer类里面有train(训练策略)、save(保存策略)、restore(恢复策略)以及compute_action(计算动作)的方法。Trainer类中有策略以及优化器,右边的Workers负责与环境交互采集数据,整个过程由分布式计算引擎Ray支持。
我们可以用以下简单的命令训练一个DQN的Trainer:
rllib train --run DQN --env CartPole-v0 # --eager [--trace] for eager execution
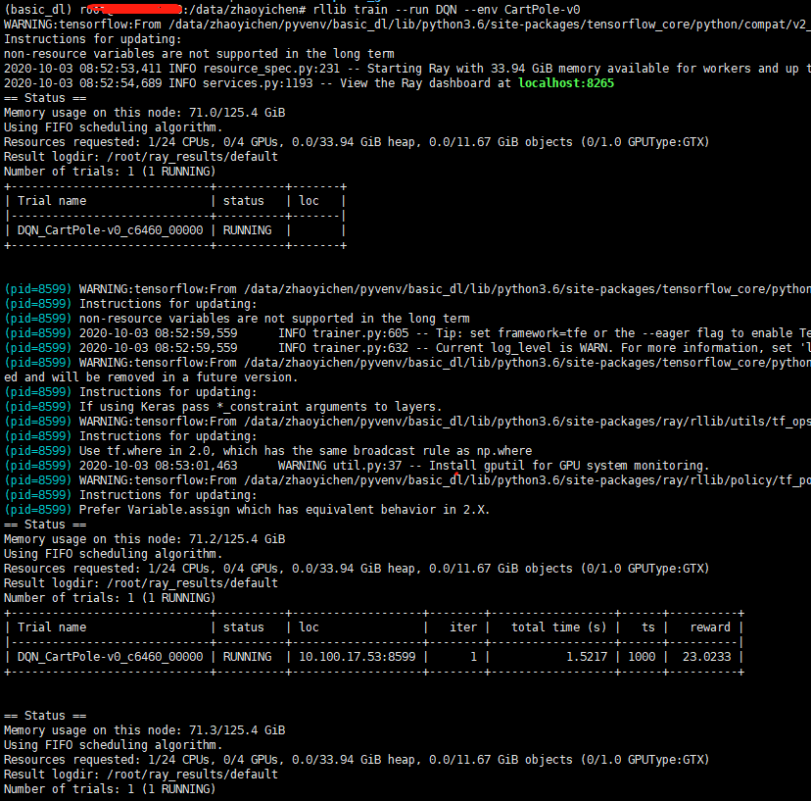
默认情况下,训练的日志会被保存在 ~/ray_results下。里面的params.json包含训练的超参数,result.json包含了训练时每一个episode的总结,并且也保存了可供TensorBoard可视化的文件
`rllib train`命令和仓库里的train.py(from ray.rllib import train)一样,有多个可选项
介绍几个最重要的可选项:
--env(可选用的环境,包括任意的gym环境或用户自己注册的)
--run(可选用的算法,包括SAC, PPO, PG, A2C, A3C, IMPALA, ES, DDPG, DQN, MARWIL, APEX, 和APEX_DDPG)
|
评估训练策略(Evaluating Trained Policies) |
为了保存评估策略之后的checkpoints,在运行train时可以设置--checkpoint-freq(每间隔多少次训练保存一次)
# rllib train --run DQN --env CartPole-v0 --checkpoint-freq 10
运行以上命令后,就会保存文件,如下图所示
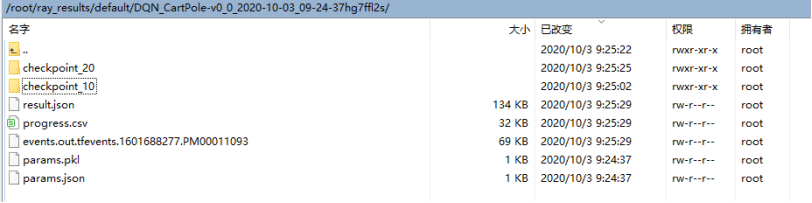
对保存的checkpoint进行评估
export CUDA_VISIBLE_DEVICES=3
rllib rollout /root/ray_results/default/DQN_CartPole-v0_0_2020-10-03_09-24-37hg7ffl2s/checkpoint_10/checkpoint-10 --run DQN --env CartPole-v0
rollout.py脚本会根据checkpoint重建DQN策略,并在指定了--env的情况下进行渲染,控制台会输出以下内容:
Episode #0: reward: 15.0
Episode #1: reward: 18.0
Episode #2: reward: 24.0
Episode #3: reward: 25.0
Episode #4: reward: 18.0
Episode #5: reward: 11.0
|
指定参数(Specifying Parameters) |
每一个算法都可以通过--config设置超参数
例如我们训练一个A2C指定8个worker通过config标记
rllib train --env=PongDeterministic-v4 --run=A2C --config '{"num_workers": 8}'

|
指定资源(Specifying Resources) |
对于大部分算法,你可以使用num_workers超参数控制并行度。driver可以使用的GPU的数量可以由num_gpus控制。同样的,workers能够使用的资源可以通过num_cpus_per_worker, num_gpus_per_worker, and custom_resources_per_worker控制。GPU的数量可以小于1,比如你可以在同一块gpu上训练5个DQN,只要你设置num_gpus: 0.2就可以。
像PPO和A2C这样的同步算法,driver和workers能使用同一块GPU:
gpu_count = n
num_gpus = 0.0001 # Driver GPU
num_gpus_per_worker = (gpu_count - num_gpus) / num_workers
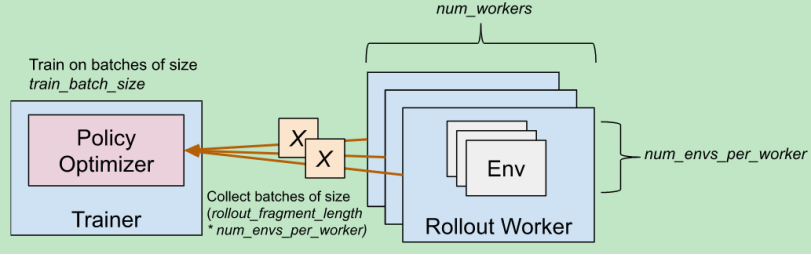
num_workers决定要开多少个进程,每一个进程中又会有多个子进程
|
延伸指南(Scaling Guide) |
下面有一些使用RLlib的经验指南
1.如果环境是缓慢的并且不能重复的(比如它依赖于与物理系统的交互),你应该使用sample-efficient off-policy算法,例如DQN或SAC。这些算法默认是单进程工作( num_workers: 0)。如果你想使用GPU,确保num_gpus: 1。如果想考虑做batch RL,可以参考offline data API。
2.如果环境是快速的并且模型较小(大部分RL模型是这样的),你应该使用time-efficient算法,比如PPO, IMPALA, or APEX. 这些算法可以增加num_workers 。做推理的时候使用Vectorization也有意义。如果你想使用一个GPU,确保num_gpus: 1。如果learner成为了瓶颈,多GPU设置可以使用num_gpus > 1.
3.如果模型是计算密集型的(比如非常深的残差网络)并且推断是瓶颈,可以考虑分配gpu给worker,并设置 num_gpus_per_worker: 1。如果你只有一个GPU,可以考虑设置num_workers: 0,他会使用Learner的GPU做推断。
4.如果模型和环境都是计算密集型的,可以设置 remote_worker_envs: True
|
常用参数 |
下面是一些常用的算法超参数


COMMON_CONFIG: TrainerConfigDict = { # === Settings for Rollout Worker processes === # Number of rollout worker actors to create for parallel sampling. Setting # this to 0 will force rollouts to be done in the trainer actor. "num_workers": 2, # Number of environments to evaluate vectorwise per worker. This enables # model inference batching, which can improve performance for inference # bottlenecked workloads. "num_envs_per_worker": 1, # Divide episodes into fragments of this many steps each during rollouts. # Sample batches of this size are collected from rollout workers and # combined into a larger batch of `train_batch_size` for learning. # # For example, given rollout_fragment_length=100 and train_batch_size=1000: # 1. RLlib collects 10 fragments of 100 steps each from rollout workers. # 2. These fragments are concatenated and we perform an epoch of SGD. # # When using multiple envs per worker, the fragment size is multiplied by # `num_envs_per_worker`. This is since we are collecting steps from # multiple envs in parallel. For example, if num_envs_per_worker=5, then # rollout workers will return experiences in chunks of 5*100 = 500 steps. # # The dataflow here can vary per algorithm. For example, PPO further # divides the train batch into minibatches for multi-epoch SGD. "rollout_fragment_length": 200, # Whether to rollout "complete_episodes" or "truncate_episodes" to # `rollout_fragment_length` length unrolls. Episode truncation guarantees # evenly sized batches, but increases variance as the reward-to-go will # need to be estimated at truncation boundaries. "batch_mode": "truncate_episodes", # === Settings for the Trainer process === # Number of GPUs to allocate to the trainer process. Note that not all # algorithms can take advantage of trainer GPUs. This can be fractional # (e.g., 0.3 GPUs). "num_gpus": 0, # Training batch size, if applicable. Should be >= rollout_fragment_length. # Samples batches will be concatenated together to a batch of this size, # which is then passed to SGD. "train_batch_size": 200, # Arguments to pass to the policy model. See models/catalog.py for a full # list of the available model options. "model": MODEL_DEFAULTS, # Arguments to pass to the policy optimizer. These vary by optimizer. "optimizer": {}, # === Environment Settings === # Discount factor of the MDP. "gamma": 0.99, # Number of steps after which the episode is forced to terminate. Defaults # to `env.spec.max_episode_steps` (if present) for Gym envs. "horizon": None, # Calculate rewards but don't reset the environment when the horizon is # hit. This allows value estimation and RNN state to span across logical # episodes denoted by horizon. This only has an effect if horizon != inf. "soft_horizon": False, # Don't set 'done' at the end of the episode. Note that you still need to # set this if soft_horizon=True, unless your env is actually running # forever without returning done=True. "no_done_at_end": False, # Arguments to pass to the env creator. "env_config": {}, # Environment name can also be passed via config. "env": None, # Unsquash actions to the upper and lower bounds of env's action space "normalize_actions": False, # Whether to clip rewards during Policy's postprocessing. # None (default): Clip for Atari only (r=sign(r)). # True: r=sign(r): Fixed rewards -1.0, 1.0, or 0.0. # False: Never clip. # [float value]: Clip at -value and + value. # Tuple[value1, value2]: Clip at value1 and value2. "clip_rewards": None, # Whether to clip actions to the action space's low/high range spec. "clip_actions": True, # Whether to use "rllib" or "deepmind" preprocessors by default "preprocessor_pref": "deepmind", # The default learning rate. "lr": 0.0001, # === Debug Settings === # Whether to write episode stats and videos to the agent log dir. This is # typically located in ~/ray_results. "monitor": False, # Set the ray.rllib.* log level for the agent process and its workers. # Should be one of DEBUG, INFO, WARN, or ERROR. The DEBUG level will also # periodically print out summaries of relevant internal dataflow (this is # also printed out once at startup at the INFO level). When using the # `rllib train` command, you can also use the `-v` and `-vv` flags as # shorthand for INFO and DEBUG. "log_level": "WARN", # Callbacks that will be run during various phases of training. See the # `DefaultCallbacks` class and `examples/custom_metrics_and_callbacks.py` # for more usage information. "callbacks": DefaultCallbacks, # Whether to attempt to continue training if a worker crashes. The number # of currently healthy workers is reported as the "num_healthy_workers" # metric. "ignore_worker_failures": False, # Log system resource metrics to results. This requires `psutil` to be # installed for sys stats, and `gputil` for GPU metrics. "log_sys_usage": True, # Use fake (infinite speed) sampler. For testing only. "fake_sampler": False, # === Deep Learning Framework Settings === # tf: TensorFlow # tfe: TensorFlow eager # torch: PyTorch "framework": "tf", # Enable tracing in eager mode. This greatly improves performance, but # makes it slightly harder to debug since Python code won't be evaluated # after the initial eager pass. Only possible if framework=tfe. "eager_tracing": False, # Disable eager execution on workers (but allow it on the driver). This # only has an effect if eager is enabled. "no_eager_on_workers": False, # === Exploration Settings === # Default exploration behavior, iff `explore`=None is passed into # compute_action(s). # Set to False for no exploration behavior (e.g., for evaluation). "explore": True, # Provide a dict specifying the Exploration object's config. "exploration_config": { # The Exploration class to use. In the simplest case, this is the name # (str) of any class present in the `rllib.utils.exploration` package. # You can also provide the python class directly or the full location # of your class (e.g. "ray.rllib.utils.exploration.epsilon_greedy. # EpsilonGreedy"). "type": "StochasticSampling", # Add constructor kwargs here (if any). }, # === Evaluation Settings === # Evaluate with every `evaluation_interval` training iterations. # The evaluation stats will be reported under the "evaluation" metric key. # Note that evaluation is currently not parallelized, and that for Ape-X # metrics are already only reported for the lowest epsilon workers. "evaluation_interval": None, # Number of episodes to run per evaluation period. If using multiple # evaluation workers, we will run at least this many episodes total. "evaluation_num_episodes": 10, # Internal flag that is set to True for evaluation workers. "in_evaluation": False, # Typical usage is to pass extra args to evaluation env creator # and to disable exploration by computing deterministic actions. # IMPORTANT NOTE: Policy gradient algorithms are able to find the optimal # policy, even if this is a stochastic one. Setting "explore=False" here # will result in the evaluation workers not using this optimal policy! "evaluation_config": { # Example: overriding env_config, exploration, etc: # "env_config": {...}, # "explore": False }, # Number of parallel workers to use for evaluation. Note that this is set # to zero by default, which means evaluation will be run in the trainer # process. If you increase this, it will increase the Ray resource usage # of the trainer since evaluation workers are created separately from # rollout workers. "evaluation_num_workers": 0, # Customize the evaluation method. This must be a function of signature # (trainer: Trainer, eval_workers: WorkerSet) -> metrics: dict. See the # Trainer._evaluate() method to see the default implementation. The # trainer guarantees all eval workers have the latest policy state before # this function is called. "custom_eval_function": None, # === Advanced Rollout Settings === # Use a background thread for sampling (slightly off-policy, usually not # advisable to turn on unless your env specifically requires it). "sample_async": False, # Experimental flag to speed up sampling and use "trajectory views" as # generic ModelV2 `input_dicts` that can be requested by the model to # contain different information on the ongoing episode. # NOTE: Only supported for PyTorch so far. "_use_trajectory_view_api": False, # Element-wise observation filter, either "NoFilter" or "MeanStdFilter". "observation_filter": "NoFilter", # Whether to synchronize the statistics of remote filters. "synchronize_filters": True, # Configures TF for single-process operation by default. "tf_session_args": { # note: overriden by `local_tf_session_args` "intra_op_parallelism_threads": 2, "inter_op_parallelism_threads": 2, "gpu_options": { "allow_growth": True, }, "log_device_placement": False, "device_count": { "CPU": 1 }, "allow_soft_placement": True, # required by PPO multi-gpu }, # Override the following tf session args on the local worker "local_tf_session_args": { # Allow a higher level of parallelism by default, but not unlimited # since that can cause crashes with many concurrent drivers. "intra_op_parallelism_threads": 8, "inter_op_parallelism_threads": 8, }, # Whether to LZ4 compress individual observations "compress_observations": False, # Wait for metric batches for at most this many seconds. Those that # have not returned in time will be collected in the next train iteration. "collect_metrics_timeout": 180, # Smooth metrics over this many episodes. "metrics_smoothing_episodes": 100, # If using num_envs_per_worker > 1, whether to create those new envs in # remote processes instead of in the same worker. This adds overheads, but # can make sense if your envs can take much time to step / reset # (e.g., for StarCraft). Use this cautiously; overheads are significant. "remote_worker_envs": False, # Timeout that remote workers are waiting when polling environments. # 0 (continue when at least one env is ready) is a reasonable default, # but optimal value could be obtained by measuring your environment # step / reset and model inference perf. "remote_env_batch_wait_ms": 0, # Minimum time per train iteration (frequency of metrics reporting). "min_iter_time_s": 0, # Minimum env steps to optimize for per train call. This value does # not affect learning, only the length of train iterations. "timesteps_per_iteration": 0, # This argument, in conjunction with worker_index, sets the random seed of # each worker, so that identically configured trials will have identical # results. This makes experiments reproducible. "seed": None, # Any extra python env vars to set in the trainer process, e.g., # {"OMP_NUM_THREADS": "16"} "extra_python_environs_for_driver": {}, # The extra python environments need to set for worker processes. "extra_python_environs_for_worker": {}, # === Advanced Resource Settings === # Number of CPUs to allocate per worker. "num_cpus_per_worker": 1, # Number of GPUs to allocate per worker. This can be fractional. This is # usually needed only if your env itself requires a GPU (i.e., it is a # GPU-intensive video game), or model inference is unusually expensive. "num_gpus_per_worker": 0, # Any custom Ray resources to allocate per worker. "custom_resources_per_worker": {}, # Number of CPUs to allocate for the trainer. Note: this only takes effect # when running in Tune. Otherwise, the trainer runs in the main program. "num_cpus_for_driver": 1, # You can set these memory quotas to tell Ray to reserve memory for your # training run. This guarantees predictable execution, but the tradeoff is # if your workload exceeeds the memory quota it will fail. # Heap memory to reserve for the trainer process (0 for unlimited). This # can be large if your are using large train batches, replay buffers, etc. "memory": 0, # Object store memory to reserve for the trainer process. Being large # enough to fit a few copies of the model weights should be sufficient. # This is enabled by default since models are typically quite small. "object_store_memory": 0, # Heap memory to reserve for each worker. Should generally be small unless # your environment is very heavyweight. "memory_per_worker": 0, # Object store memory to reserve for each worker. This only needs to be # large enough to fit a few sample batches at a time. This is enabled # by default since it almost never needs to be larger than ~200MB. "object_store_memory_per_worker": 0, # === Offline Datasets === # Specify how to generate experiences: # - "sampler": generate experiences via online simulation (default) # - a local directory or file glob expression (e.g., "/tmp/*.json") # - a list of individual file paths/URIs (e.g., ["/tmp/1.json", # "s3://bucket/2.json"]) # - a dict with string keys and sampling probabilities as values (e.g., # {"sampler": 0.4, "/tmp/*.json": 0.4, "s3://bucket/expert.json": 0.2}). # - a function that returns a rllib.offline.InputReader "input": "sampler", # Specify how to evaluate the current policy. This only has an effect when # reading offline experiences. Available options: # - "wis": the weighted step-wise importance sampling estimator. # - "is": the step-wise importance sampling estimator. # - "simulation": run the environment in the background, but use # this data for evaluation only and not for learning. "input_evaluation": ["is", "wis"], # Whether to run postprocess_trajectory() on the trajectory fragments from # offline inputs. Note that postprocessing will be done using the *current* # policy, not the *behavior* policy, which is typically undesirable for # on-policy algorithms. "postprocess_inputs": False, # If positive, input batches will be shuffled via a sliding window buffer # of this number of batches. Use this if the input data is not in random # enough order. Input is delayed until the shuffle buffer is filled. "shuffle_buffer_size": 0, # Specify where experiences should be saved: # - None: don't save any experiences # - "logdir" to save to the agent log dir # - a path/URI to save to a custom output directory (e.g., "s3://bucket/") # - a function that returns a rllib.offline.OutputWriter "output": None, # What sample batch columns to LZ4 compress in the output data. "output_compress_columns": ["obs", "new_obs"], # Max output file size before rolling over to a new file. "output_max_file_size": 64 * 1024 * 1024, # === Settings for Multi-Agent Environments === "multiagent": { # Map of type MultiAgentPolicyConfigDict from policy ids to tuples # of (policy_cls, obs_space, act_space, config). This defines the # observation and action spaces of the policies and any extra config. "policies": {}, # Function mapping agent ids to policy ids. "policy_mapping_fn": None, # Optional list of policies to train, or None for all policies. "policies_to_train": None, # Optional function that can be used to enhance the local agent # observations to include more state. # See rllib/evaluation/observation_function.py for more info. "observation_fn": None, # When replay_mode=lockstep, RLlib will replay all the agent # transitions at a particular timestep together in a batch. This allows # the policy to implement differentiable shared computations between # agents it controls at that timestep. When replay_mode=independent, # transitions are replayed independently per policy. "replay_mode": "independent", }, # === Logger === # Define logger-specific configuration to be used inside Logger # Default value None allows overwriting with nested dicts "logger_config": None, # === Replay Settings === # The number of contiguous environment steps to replay at once. This may # be set to greater than 1 to support recurrent models. "replay_sequence_length": 1, }
|
调好的参数文件(Tuned Examples) |
一些调好的超参数和配置可以在代码库里找到(有一些是在GPU上调的)
https://github.com/ray-project/ray/tree/master/rllib/tuned_examples
你可以这样使用
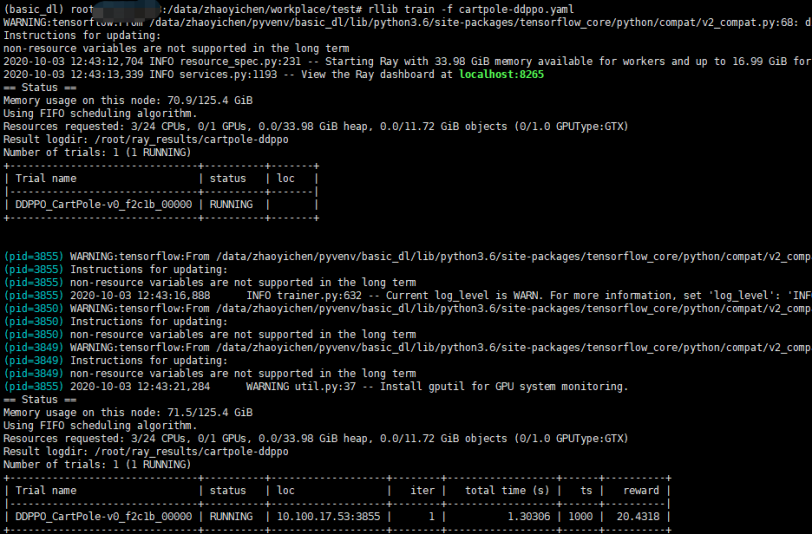
rllib train -f /path/to/tuned/example.yaml
|
参考资料 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号