iOS基于MNN的本地化个性化推荐模型实现
iOS基于MNN的本地化个性化推荐模型实现
一、项目目标
使用训练一个简化的个性化排序模型,并将其转换为TensorFlow Lite格式,最终转换为MNN格式,并实现在iOS设备上运行。
应用场景模拟
根据用户特征、商品特征和上下文信息进行个性化排序,实现基于本地化部署的个性化推荐能力。
二、准备工作
1. 安装TensorFlow 和 NumPy
pip3 install tensorflow numpy
验证是否安装成功
# 验证是否安装成功
python3 -c "import tensorflow as tf; print('✅ TensorFlow安装成功!'); print('版本:', tf.__version__); print('GPU支持:', len(tf.config.list_physical_devices('GPU')) > 0)"
# 安装成功则会有如下提示信息
✅ TensorFlow安装成功!
版本: 2.16.2
GPU支持: True
2. 下载MNN源码,生成MNNConvert转换工具
⚠️ 避坑提示:MNN提供的workbench与本地的MNN版本存在匹配兼容性问题,导致不能将.tflite转为.mnn。建议直接编译MNN源码,生成MNNConvert工具,通过命令行转换。
2.1 下载MNN源码
下载最新的release版本:https://github.com/alibaba/MNN.git
目前最新版本为3.3.0
2.2 通过CMake,生成MNNConvert工具(用于将.tflite转为.mnn)
1)安装CMake
brew install cmake
2)执行cmake命令
cmake -DMNN_BUILD_CONVERTER=ON -DCMAKE_BUILD_TYPE=Release ..
make mnnconvert -j4
3)编译后的mnnconvert工具在build目录下
4)通过MNNConvert可将.tflite转为.mnn
mnnconvert --framework TFLITE --modelFile ultra_simple_ranking_model.tflite --MNNModel ultra_simple_ranking_model.mnn --bizCode tflite_convert
三、生成神经网络模型
1. 根据需求设计一个简化的神经网络
三个输入分别为用户特征(user_features)、商品特征(item_features)和上下文特征(context_features)
# 输入层 - 使用固定维度
user_input = keras.Input(shape=(10,), name='user_features')
item_input = keras.Input(shape=(10,), name='item_features')
context_input = keras.Input(shape=(5,), name='context_features')
# 连接所有输入
combined = layers.Concatenate(name='combined_features')([user_input, item_input, context_input])
# 超简单的全连接层 - 避免任何复杂操作
hidden = layers.Dense(16, activation='relu', name='hidden_layer')(combined)
# 输出层
output = layers.Dense(1, activation='sigmoid', name='ranking_score')(hidden)
用户特征的10个维度:
[0]年龄(归一化) → 0.25 (25岁)[1]性别 → 1.0 (男) 或 0.0 (女)[2]收入水平 → 0.6 (中等收入)[3]购买力 → 0.8 (购买力强)[4]品牌偏好 → 0.3 (偏爱性价比)[5]价格敏感度 → 0.7 (价格敏感)[6]活跃度 → 0.9 (经常购物)[7]地域特征 → 0.4 (二线城市)[8]历史行为模式 → 0.6 (理性消费)[9]社交影响力 → 0.2 (不太关注社交)
商品特征的10个维度:
[0]价格档次 → 0.7 (中高端)[1]品牌知名度 → 0.9 (知名品牌)[2]用户评分 → 0.85 (4.2/5星)[3]销量热度 → 0.6 (中等销量)[4]功能复杂度 → 0.4 (功能简单)[5]外观设计 → 0.8 (设计精美)[6]性价比 → 0.7 (性价比高)[7]类目属性 → 0.3 (电子产品)[8]新品程度 → 0.2 (老款产品)[9]促销力度 → 0.5 (有一定优惠)
上下文特征的5个维度:
[0]时间特征 → 0.8 (晚上8点,购物高峰)[1]季节特征 → 0.3 (春季)[2]设备类型 → 1.0 (手机端)[3]网络状况 → 0.9 (WiFi,网速快)[4]搜索意图强度 → 0.7 (明确想买)
1.2 具体实现生成模型Python代码
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
超简化个性化排序模型 - 完全兼容TensorFlow Lite
"""
import os
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import json
# 设置随机种子确保结果可重现
tf.random.set_seed(42)
np.random.seed(42)
print("🚀 创建超简化兼容模型...")
print(f"TensorFlow版本: {tf.__version__}")
def create_ultra_simple_model():
"""创建超简化的个性化排序模型"""
print("🏗️ 创建超简化模型架构...")
# 定义输入层 - 使用固定维度
user_input = keras.Input(shape=(10,), name='user_features')
item_input = keras.Input(shape=(10,), name='item_features')
context_input = keras.Input(shape=(5,), name='context_features')
# 连接所有输入
combined = layers.Concatenate(name='combined_features')([user_input, item_input, context_input])
# 超简单的全连接层 - 避免任何复杂操作
hidden = layers.Dense(16, activation='relu', name='hidden_layer')(combined)
# 输出层
output = layers.Dense(1, activation='sigmoid', name='ranking_score')(hidden)
# 创建模型
model = keras.Model(
inputs=[user_input, item_input, context_input],
outputs=output,
name='ultra_simple_ranking_model'
)
return model
def generate_simple_data(num_samples=1000):
"""生成简单的训练数据"""
print(f"📊 生成 {num_samples} 个训练样本...")
# 生成随机特征
user_features = np.random.randn(num_samples, 10).astype(np.float32)
item_features = np.random.randn(num_samples, 10).astype(np.float32)
context_features = np.random.randn(num_samples, 5).astype(np.float32)
# 生成简单的标签 - 基于特征和的简单规则
user_score = np.mean(user_features, axis=1)
item_score = np.mean(item_features, axis=1)
context_score = np.mean(context_features, axis=1)
# 组合得分并转换为0-1标签
combined_score = user_score + item_score + context_score
labels = (combined_score > np.median(combined_score)).astype(np.float32)
return {
'user_features': user_features,
'item_features': item_features,
'context_features': context_features
}, labels
def main():
print("🚀 开始创建超简化个性化排序模型")
# 创建模型
model = create_ultra_simple_model()
# 显示模型架构
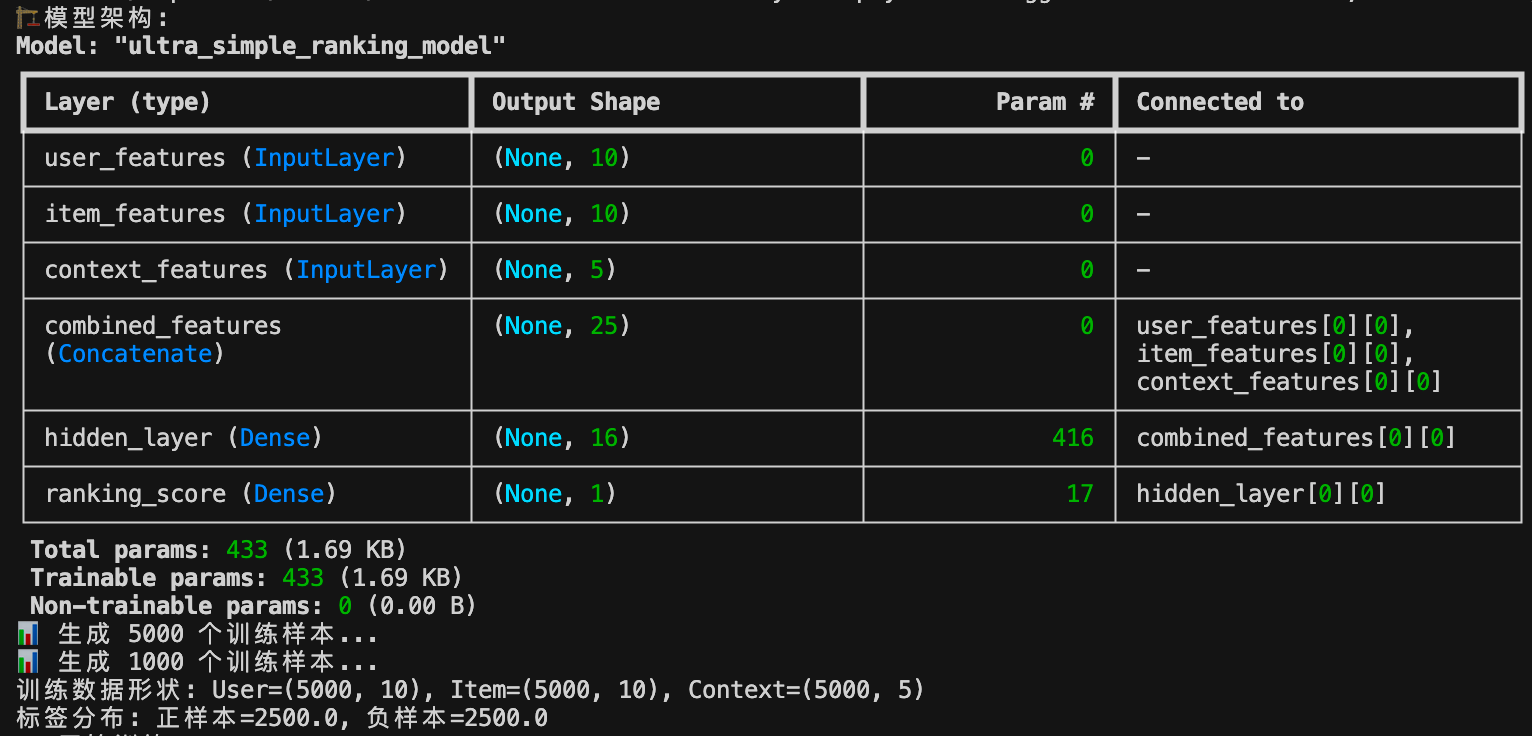
print("🏗️ 模型架构:")
model.summary()
# 编译模型 - 使用最基础的配置
model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy']
)
# 生成训练数据
X_train, y_train = generate_simple_data(5000)
X_val, y_val = generate_simple_data(1000)
print(f"训练数据形状: User={X_train['user_features'].shape}, Item={X_train['item_features'].shape}, Context={X_train['context_features'].shape}")
print(f"标签分布: 正样本={np.sum(y_train)}, 负样本={len(y_train) - np.sum(y_train)}")
# 训练模型
print("🎯 开始训练...")
history = model.fit(
[X_train['user_features'], X_train['item_features'], X_train['context_features']],
y_train,
validation_data=([X_val['user_features'], X_val['item_features'], X_val['context_features']], y_val),
epochs=5,
batch_size=64,
verbose=1
)
# 保存模型
model_path = 'ultra_simple_ranking_model.keras'
model.save(model_path)
print(f"✅ 模型已保存到: {model_path}")
# 保存配置信息
config = {
"model_name": "ultra_simple_ranking_model",
"input_shapes": {
"user_features": [10],
"item_features": [10],
"context_features": [5]
},
"output_shape": [1],
"total_params": model.count_params(),
"architecture": "ultra_simple_dense_only"
}
with open('ultra_simple_config.json', 'w', encoding='utf-8') as f:
json.dump(config, f, indent=2, ensure_ascii=False)
print("✅ 配置文件已保存到: ultra_simple_config.json")
# 测试模型推理
print("🧪 测试模型推理...")
test_user = np.random.randn(1, 10).astype(np.float32)
test_item = np.random.randn(1, 10).astype(np.float32)
test_context = np.random.randn(1, 5).astype(np.float32)
prediction = model.predict([test_user, test_item, test_context])
print(f"测试预测结果: {prediction[0][0]:.4f}")
print("🎉 超简化模型创建完成!")
return model_path
if __name__ == "__main__":
main()
架构特点:
- 总参数量:433个 (1.69KB)
- 输入维度:25维 (10+10+5)
- 输出:单一排序得分 (0-1)
1.3 训练数据生成
def generate_simple_data(num_samples=1000):
# 生成随机特征
user_features = np.random.randn(num_samples, 10).astype(np.float32)
item_features = np.random.randn(num_samples, 10).astype(np.float32)
context_features = np.random.randn(num_samples, 5).astype(np.float32)
# 基于特征生成标签
user_score = np.mean(user_features, axis=1)
item_score = np.mean(item_features, axis=1)
context_score = np.mean(context_features, axis=1)
combined_score = user_score + item_score + context_score
labels = (combined_score > np.median(combined_score)).astype(np.float32)
return features, labels
1.4 训练过程
训练配置:
- 优化器:Adam
- 损失函数:binary_crossentropy
- 评估指标:accuracy
- 训练轮数:5 epochs
- 批次大小:64
执行命令Python文件,开始训练
python3 create_ultra_simple_model.py
1.5 训练结果
Epoch 1/5: accuracy: 0.5428 - val_accuracy: 0.7460
Epoch 2/5: accuracy: 0.7955 - val_accuracy: 0.8730
Epoch 3/5: accuracy: 0.9057 - val_accuracy: 0.9320
Epoch 4/5: accuracy: 0.9485 - val_accuracy: 0.9610
Epoch 5/5: accuracy: 0.9699 - val_accuracy: 0.9730
深度学习模型训练参数详解
accuracy 和 val_accuracy 是机器学习模型训练过程中的两个核心评估指标:
-
accuracy(训练准确率)
- 定义:模型在训练集上的预测正确率
- 计算方式:正确预测数量 ÷ 训练样本总数
- 作用:衡量模型对训练数据的学习程度
-
val_accuracy(验证准确率)
- 定义:模型在验证集上的预测正确率
- 计算方式:正确预测数量 ÷ 验证样本总数
- 作用:衡量模型的泛化能力(对新数据的预测能力)
1.6 输出TensorFlow文件
生成文件:ultra_simple_ranking_model.tflite
1.7 .tflite 转为 .mnn
.tflite可以通过MNNConvert转为.mnn(生成的.mnn文件比.tflite文件要大)
mnnconvert --framework TFLITE --modelFile ultra_simple_ranking_model.tflite --MNNModel ultra_simple_ranking_model.mnn --bizCode tflite_convert
生成文件:ultra_simple_ranking_model.mnn
四、在iOS工程里验证
1. 创建iOS工程并通过CocoaPods引用MNN框架
target 'MNNDemo' do
pod 'MNN'
end
2. 编写iOS测试用例
#import <Foundation/Foundation.h>
#import <MNN/Interpreter.hpp>
#import <MNN/Tensor.hpp>
#import <iostream>
#import <vector>
@implementation SimpleRankingModelTest
+ (void)testUltraSimpleModel {
NSLog(@"🚀 开始测试超简化个性化排序模型");
// 1. 获取模型文件路径
NSString *modelPath = [[NSBundle mainBundle] pathForResource:@"ultra_simple_ranking_model" ofType:@"mnn"];
if (!modelPath) {
NSLog(@"❌ 模型文件未找到: ultra_simple_ranking_model.mnn");
return;
}
NSLog(@"📂 模型文件路径: %@", modelPath);
// 2. 创建MNN解释器
std::shared_ptr<MNN::Interpreter> interpreter(MNN::Interpreter::createFromFile([modelPath UTF8String]));
if (!interpreter) {
NSLog(@"❌ 无法创建MNN解释器");
return;
}
NSLog(@"✅ MNN解释器创建成功");
// 3. 创建会话配置
MNN::ScheduleConfig config;
config.type = MNN_FORWARD_CPU;
config.numThread = 1;
// 4. 创建会话
MNN::Session* session = interpreter->createSession(config);
if (!session) {
NSLog(@"❌ 无法创建MNN会话");
return;
}
NSLog(@"✅ MNN会话创建成功");
// 5. 获取输入张量
MNN::Tensor* userInput = interpreter->getSessionInput(session, "user_features");
MNN::Tensor* itemInput = interpreter->getSessionInput(session, "item_features");
MNN::Tensor* contextInput = interpreter->getSessionInput(session, "context_features");
if (!userInput || !itemInput || !contextInput) {
NSLog(@"❌ 无法获取输入张量");
interpreter->releaseSession(session);
return;
}
NSLog(@"✅ 成功获取所有输入张量");
NSLog(@"📊 用户特征张量形状: [%d, %d]", userInput->shape()[0], userInput->shape()[1]);
NSLog(@"📊 物品特征张量形状: [%d, %d]", itemInput->shape()[0], itemInput->shape()[1]);
NSLog(@"📊 上下文特征张量形状: [%d, %d]", contextInput->shape()[0], contextInput->shape()[1]);
// 6. 准备测试数据
std::vector<float> userData(10);
std::vector<float> itemData(10);
std::vector<float> contextData(5);
// 填充随机测试数据
for (int i = 0; i < 10; i++) {
userData[i] = (float)(rand() % 100) / 100.0f;
itemData[i] = (float)(rand() % 100) / 100.0f;
}
for (int i = 0; i < 5; i++) {
contextData[i] = (float)(rand() % 100) / 100.0f;
}
// 7. 设置输入数据
memcpy(userInput->host<float>(), userData.data(), userData.size() * sizeof(float));
memcpy(itemInput->host<float>(), itemData.data(), itemData.size() * sizeof(float));
memcpy(contextInput->host<float>(), contextData.data(), contextData.size() * sizeof(float));
NSLog(@"✅ 输入数据设置完成");
// 8. 运行推理
interpreter->runSession(session);
NSLog(@"✅ 模型推理完成");
// 9. 获取输出结果
MNN::Tensor* output = interpreter->getSessionOutput(session, NULL);
if (!output) {
NSLog(@"❌ 无法获取输出张量");
interpreter->releaseSession(session);
return;
}
float* outputData = output->host<float>();
float rankingScore = outputData[0];
NSLog(@"🎯 排序得分: %.4f", rankingScore);
NSLog(@"✅ 超简化模型测试完成!");
// 10. 清理资源
interpreter->releaseSession(session);
}
+ (void)testModelInference {
NSLog(@"🧪 开始批量推理测试");
// 获取模型文件路径
NSString *modelPath = [[NSBundle mainBundle] pathForResource:@"ultra_simple_ranking_model" ofType:@"mnn"];
if (!modelPath) {
NSLog(@"❌ 模型文件未找到");
return;
}
// 创建解释器和会话
std::shared_ptr<MNN::Interpreter> interpreter(MNN::Interpreter::createFromFile([modelPath UTF8String]));
MNN::ScheduleConfig config;
config.type = MNN_FORWARD_CPU;
config.numThread = 1;
MNN::Session* session = interpreter->createSession(config);
// 获取输入张量
MNN::Tensor* userInput = interpreter->getSessionInput(session, "user_features");
MNN::Tensor* itemInput = interpreter->getSessionInput(session, "item_features");
MNN::Tensor* contextInput = interpreter->getSessionInput(session, "context_features");
// 测试多组数据
NSLog(@"📊 测试多组推理数据:");
for (int test = 0; test < 5; test++) {
// 生成测试数据
std::vector<float> userData(10);
std::vector<float> itemData(10);
std::vector<float> contextData(5);
for (int i = 0; i < 10; i++) {
userData[i] = (float)(rand() % 200 - 100) / 100.0f; // -1.0 到 1.0
itemData[i] = (float)(rand() % 200 - 100) / 100.0f;
}
for (int i = 0; i < 5; i++) {
contextData[i] = (float)(rand() % 200 - 100) / 100.0f;
}
// 设置输入
memcpy(userInput->host<float>(), userData.data(), userData.size() * sizeof(float));
memcpy(itemInput->host<float>(), itemData.data(), itemData.size() * sizeof(float));
memcpy(contextInput->host<float>(), contextData.data(), contextData.size() * sizeof(float));
// 推理
interpreter->runSession(session);
// 获取结果
MNN::Tensor* output = interpreter->getSessionOutput(session, NULL);
float rankingScore = output->host<float>()[0];
NSLog(@" 测试 %d: 排序得分 = %.4f", test + 1, rankingScore);
}
NSLog(@"✅ 批量推理测试完成");
// 清理资源
interpreter->releaseSession(session);
}
@end
主要步骤
1. 模型加载
从Bundle中获取ultra_simple_ranking_model.mnn文件路径
2. 解释器创建
使用MNN框架创建模型解释器
MNN::Interpreter::createFromFile(const char* file);
3. 会话配置
配置CPU推理,单线程执行
MNN::ScheduleConfig config;
config.type = MNN_FORWARD_CPU;
config.numThread = 1;
4. 会话创建
建立MNN推理会话
interpreter->createSession(config);
5. 张量获取
获取三个输入张量:用户特征(10维)、物品特征(10维)、上下文特征(5维)
MNN::Tensor* userInput = interpreter->getSessionInput(session, "user_features");
MNN::Tensor* itemInput = interpreter->getSessionInput(session, "item_features");
MNN::Tensor* contextInput = interpreter->getSessionInput(session, "context_features");
6. 数据准备
生成随机测试数据填充输入向量
std::vector<float> userData(10);
std::vector<float> itemData(10);
std::vector<float> contextData(5);
7. 数据设置
将测试数据复制到输入张量
memcpy(userInput->host<float>(), userData.data(), userData.size() * sizeof(float));
memcpy(itemInput->host<float>(), itemData.data(), itemData.size() * sizeof(float));
memcpy(contextInput->host<float>(), contextData.data(), contextData.size() * sizeof(float));
8. 模型推理
执行推理计算
interpreter->runSession(session);
9. 结果获取
提取输出张量中的排序得分(0-1范围)
MNN::Tensor* output = interpreter->getSessionOutput(session, NULL);
10. 资源清理
释放会话和相关资源
interpreter->releaseSession(session);
3. 单测运行结果
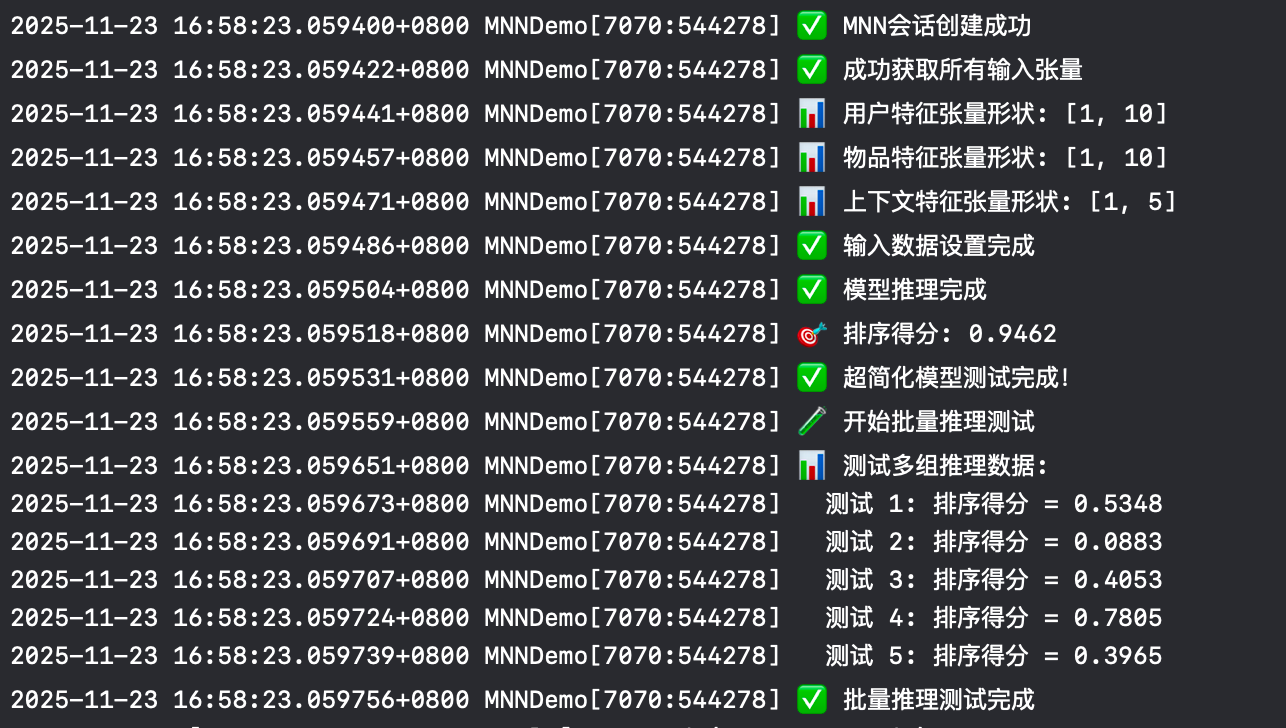
4. 测试结论
5组测试数据中,第4组推荐排序值最高,为0.8547,模型推理结果认为这个商品78.05%适合这个用户。
五、总结
本项目成功实现了从Python模型训练到iOS端部署的完整流程:
- ✅ 模型训练:使用TensorFlow训练超简化神经网络,达到97.3%准确率
- ✅ 格式转换:TensorFlow → TFLite → MNN,模型大小仅6.6KB
- ✅ iOS集成:通过MNN框架实现毫秒级推理
- ✅ 功能验证:多组测试数据验证个性化排序效果
该方案为移动端本地化AI推荐提供了轻量级、高效的解决方案。
(限于水平,本文可能存在瑕疵甚至错误的地方。如有发现,还请留言指正,相互学习。thx! )
KEEP LOOKING, DON`T SETTLE!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号