
多线程总结
1. 程序,进程,线程
程序:是指令和数据的有序集合,其本身没有任何运行的含义,是一个静态的概念。
进程:正在运行的程序,它是一个动态的概念。是系统资源分配的单位。
线程:是CPU调度和执行的的单位。通常在一个进程中可以包含若干个线程。
多线程:
指在一个程序中同时执行多个线程,每个线程都可以独立运行和完成一定的任务。
多线程程序可以更好地利用计算机的多核处理器和资源,提高程序的运行效率和响应速度。
举例:当我们编写了一个接口,某个时刻,多个用户同时访问那个接口,这种情况,就相当于是多线程访问我们的接口。
2. 线程的创建

2.1 继承Thread方式
- 自定义线程类继承Thread
- 重写run()方法,编写线程执行体
- 创建线程对象,调用start()启动线程
//模拟火车站售票窗口,开启三个窗口售票,总票数为100张
//存在线程的安全问题(之后例子用线程同步解决)
// 需求:有3个窗口卖100张票,票号为1~100。
class Window extends Thread {
// 创建静态变量,保证票数统一。 为啥要用静态变量? 因为静态变量属于类,而不属于某个具体对象。下面的例子要开启三个线程,用static修饰,就能让该属性作为一个共享资源。
// 若不用static修饰,就代表这个属性属于对象了。到时候3个线程,都会有各自的100张票。
static int ticket = 100;
@Override
public void run() {
while (true) {
if (ticket > 0) {
System.out.println(Thread.currentThread().getName() + "售票,票号为:" + --ticket);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
break;
}
}
}
}
public class TestWindow {
public static void main(String[] args) {
Window w1 = new Window();
Window w2 = new Window();
Window w3 = new Window();
w1.setName("窗口1");
w2.setName("窗口2");
w3.setName("窗口3");
w1.start();
w2.start();
w3.start();
}
}
窗口2售票,票号为:4
窗口1售票,票号为:3
窗口3售票,票号为:2
窗口2售票,票号为:1
窗口3售票,票号为:1
窗口1售票,票号为:0 // 因为窗口2在处理最后一张票的时候,窗口3也来处理。就导致了最后一张票被2个窗口同时卖。
2.2 实现Runnable
- 定义实现类实现Runnable接口
- 重写run()方法,编写线程执行体
- 创建线程对象,调用start()启动线程【利用Thread的构造函数,传Runnable实现类对象】
//使用实现Runnable接口的方式,售票
/*
* 此程序存在线程的安全问题:打印车票时,会出现重票、错票
*/
class Window1 implements Runnable {
// 这里就不需要加 static了, 因为创建线程,是通过传参到thread里面。 new Window1() 只实例化了一次
private int ticket = 100;
public void run() {
while (true) {
if (ticket > 0) {
//线程睡眠10秒,暴露重票、错票问题
try {
Thread.currentThread().sleep(10);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "售票,票号为:"+ --ticket);
} else {
break;
}
}
}
}
public class TestWindow1 {
public static void main(String[] args) {
Window1 w = new Window1();
Thread t1 = new Thread(w);
Thread t2 = new Thread(w);
Thread t3 = new Thread(w);
t1.setName("窗口1");
t2.setName("窗口2");
t3.setName("窗口3");
t1.start();
t2.start();
t3.start();
}
}
窗口1售票,票号为:3
窗口3售票,票号为:2
窗口3售票,票号为:1
窗口2售票,票号为:0
窗口1售票,票号为:0 // 因为窗口2在处理最后一张票的时候,窗口1也来处理。就导致了最后一张票被2个窗口同时卖。
2.3 实现Callable【要依赖FutureTaskFutureTask是Future接口的实现类】
- 定义实现类实现Callable接口
- 重写call()方法,编写线程执行体,需要抛出异常,该方法有返回值
- 创建线程对象,调用start()启动线程【利用FutureTask的构造函数,传Callable实现类对象,再利用Thread的构造函数,传FutureTask对象】
2.4 继承Thread与实现Runnable的区别【Runnable 用的最多,因为JAVA是单继承,多实现。该方式还可以继承其他类】
- 启动方式不同,分别是:子类对象.start 和 传入目标对象+Thread对象.start
- 继承Thread后,不能再继承其他类,而实现Runnable方式可以。
3. 线程的状态
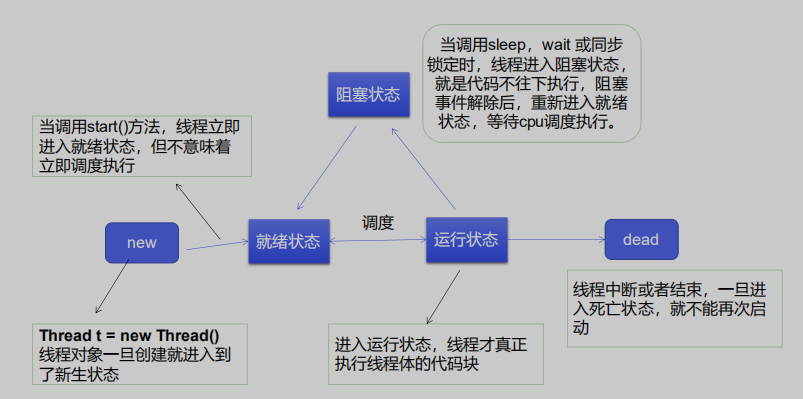
4. 线程常用方法
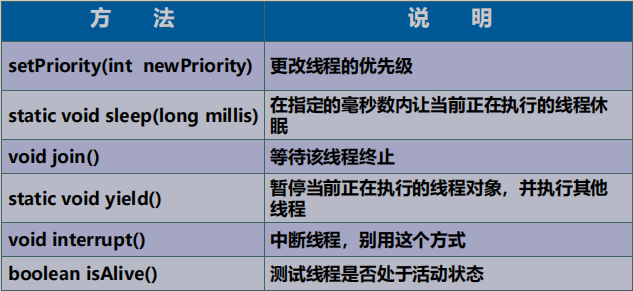
-
start():启动线程并执行相应的run()方法
-
run():子线程要执行的代码放入run()方法中
-
currentThread():静态的,调取当前的线程
-
getName():获取此线程的名字
-
setName():设置此线程的名字
-
yield():调用此方法的线程释放当前CPU的执行权,把执行机会让其他优先级相同或更高的线程。
-
join():在A线程中调用B线程的join()方法,表示:当执行到此方法,A线程停止执行,让B线程加入直到其执行完毕,当某个程序执行流中调用其他线程的join()方法时,调用线程将被阻塞,直到join()方法加入的join线程执行完为止
-
isAlive():判断当前线程是否还存活
-
sleep(long l):显式的让当前线程睡眠l毫秒
-
getPriority():返回线程优先值
-
setPriority(int newPriority):改变线程的优先级
4.1 停止线程
不推荐使用JDK提供的stop(),destroy()来停止线程。而是推荐让线程自己停下来。
建议使用一个标识符进行终止变量,当flag = false时,终止线程运行。

4.2 线程休眠
方法sleep()用于让当前线程休眠(阻塞),该方法可以传指定时间(毫秒数)。使用该方法会抛异常InterruptedException。
每一个对象都有一个锁,sleep不会释放锁。
4.3 线程等待
方法wait()用于让当前线程进入等待(阻塞),会释放锁,该方法属于Object的方法。
该方法可以传指定时间(毫秒数),当超过指定时间,当前线程就被自动唤醒,若没有设置等待时间,线程不会自动苏醒,需要别的线程调用此对象的notify()或notifyAll()方法。唤醒。
注意:wait(),notify(),notifyAll() 方法只能在同步控制方法或者同步控制块里面使用。
notify()和notifyAll() 示例:
notify()是唤醒单个线程,而唤醒哪个线程是不确定的,具体取决于JVM的实现。而notifyAll()是唤醒所有的线程。
//////////////////// 证明wait使当前线程等待 ///////////////////
class ThreadA extends Thread{
public ThreadA(String name) {
super(name);
}
public void run() {
synchronized (this) {
try {
Thread.sleep(1000); // 使当前线阻塞 1 s,确保主程序的 t1.wait(); 执行之后再执行 notify()
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+" call notify()");
// 唤醒当前的wait线程
this.notify();
}
}
}
public class WaitTest {
public static void main(String[] args) {
ThreadA t1 = new ThreadA("t1");
synchronized(t1) {
try {
// 启动“线程t1”
System.out.println(Thread.currentThread().getName()+" start t1");
t1.start();
// 主线程等待t1通过notify()唤醒。
System.out.println(Thread.currentThread().getName()+" wait()");
t1.wait(); // 不是使t1线程等待,而是当前执行wait的线程等待
System.out.println(Thread.currentThread().getName()+" continue");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
//////////////////// wait(long timeout)超时被唤醒 ///////////////////
class ThreadA extends Thread{
public ThreadA(String name) {
super(name);
}
public void run() {
System.out.println(Thread.currentThread().getName() + " run ");
// 死循环,不断运行。
while(true){;} // 这个线程与主线程无关,无 synchronized
}
}
public class WaitTimeoutTest {
public static void main(String[] args) {
ThreadA t1 = new ThreadA("t1");
synchronized(t1) {
try {
// 启动“线程t1”
System.out.println(Thread.currentThread().getName() + " start t1");
t1.start();
// 主线程等待t1通过notify()唤醒 或 notifyAll()唤醒,或超过3000ms延时;然后才被唤醒。
System.out.println(Thread.currentThread().getName() + " call wait ");
t1.wait(3000);
System.out.println(Thread.currentThread().getName() + " continue");
t1.stop();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
4.4 线程优先级
线程的调度:
若某个时刻,某个线程就想被执行,这怎么办?
在计算机中,线程的调度有两种模式:
-
分时调度————————>让所有线程轮流获得CPU的调度
-
抢占式调度————————>让所有线程抢夺CPU的使用权,优先级高的获取CPU调度的概率高
-
Java采用的就是抢占式调度。
为什么明明是抢占式调度,为啥看起来像是同时在执行?
尽管Java中的线程调度是抢占式的,但是由于线程切换的速度非常快,因此多个线程看起来像是同时在执行。
为什么我开启3个线程,其中一个线程要休眠10秒,为什么当该线程最先被调度时,其他2个线程没有等他调度完才能执行。不是说抢占式调度吗?
如果你开启了3个线程,其中一个线程要休眠10秒,而另外两个线程不需要休眠,那么在该线程被调度执行期间,其他线程的执行并不会等待该线程调度完毕。
这是因为Java中的线程调度是由JVM来控制的,而JVM的调度器并不是直接调用操作系统提供的线程调度机制,而是通过在Java程序中模拟线程调度来实现的。
具体来说,JVM会将每个线程分成一个个时间片(也称为时间片片段),并且在每个时间片结束时切换到下一个线程。因此,当一个线程需要休眠时,JVM会将该线程的时间片暂停,同时将其余线程的时间片继续执行,直到休眠的线程重新被唤醒并恢复执行。
来自chatgpt的回答:
抢占式调度:是在多个线程竞争CPU资源的情况下,操作系统会根据线程的优先级等因素来决定哪个线程可以继续执行,如果优先级更高的线程需要执行,那么操作系统会暂停当前正在执行的线程,并切换到优先级更高的线程执行。这样可以确保优先级高的线程尽快得到执行,从而提高程序的响应速度和执行效率。
在Java中,多个线程的调度是由JVM和操作系统共同协调完成的。如果你开启了3个线程,那么在某一时刻只有一个线程能够被CPU调度执行,因为CPU在同一时刻只能执行一个线程的指令。在Java中,线程的调度顺序和优先级并不是绝对的,而是相对的。也就是说,JVM只是倾向于优先执行优先级更高的线程,但并不保证一定会这样做。因此,在编写多线程程序时需要特别小心,避免出现因线程优先级问题导致的程序不稳定或死锁等问题。
4.4.1 线程的优先级
线程的优先级用1~10之间的整数来表示,数字越大优先级越高。注意这句话,只是优先级高的越容易被调度而已。
4.4.2 设置线程的优先级
通过Thread类的setPriority(int newPriority)设置。
示例代码:
// getPriority() 获取优先级
// setPriority(int xxx) 设置优先级
class PrintNum extends Thread{
public void run(){
for(int i = 1;i <= 100;i++){
System.out.println(Thread.currentThread().getName() + ":" + i);
}
}
public PrintNum(String name){
super(name);
}
}
public class TestThread {
public static void main(String[] args) {
PrintNum p1 = new PrintNum("线程1");
PrintNum p2 = new PrintNum("线程2");
//优先级高的获取CPU执行几率高
p1.setPriority(Thread.MAX_PRIORITY);//10
p2.setPriority(Thread.MIN_PRIORITY);//1
p1.start();
p2.start();
}
}
4.5 线程通信
Java提供了几个方法解决线程之间的通信问题。
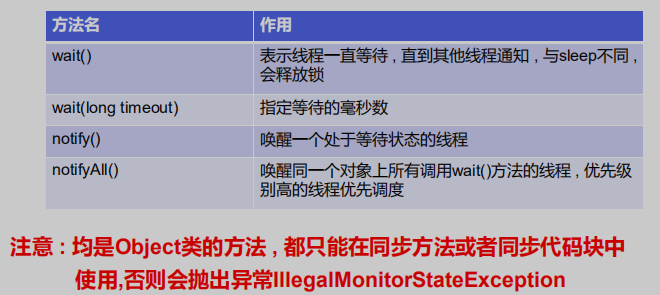
场景假设:
假设有生产者与消费者两个线程,他们同时去操作同一种商品,生产者负责生产商品,消费者负责消费商品。
在保证线程同步后,该场景下,可能还会出现一个问题。就是生产者还没生产出商品,消费者就要去消费商品。
线程通信:
就是解决上述问题的,用于让线程间进行通信,保证线程任务的协调进行,在生产者线程产出商品后,调用wait()方法让该线程处于等待状态,等消费者线程执行消费完商品后,消费者调用notify()方法唤醒等待的生产者线程。为此,Java在Object类中提供了如下方法用于解决线程间的通信问题:
-
wait()————>让当前线程放弃锁进入等待【进入阻塞状态】,直到其他线程获得锁后,调用notify()或notifyAll()方法将其唤醒【从阻塞状态变为就绪状态】。
-
wait(long time)————>让当前线程放弃锁进入等待【进入阻塞状态】,直到指定时间之后,会被自动唤醒。
-
notify()————>随机唤醒一个处于等待状态的线程
-
notifyAll()————>唤醒所有调用wait()方法的线程
注意:
- 上述方法的使用必须在加锁条件下【我们需要先有一个Object对象,配合synchronize使用】,否则会报 IllegalMonitorStateException 异常。
- 当想要调用上述方法时,必须要取得这个锁对象的控制权(当前被Cpu调度),一般是放到synchronized(obj)代码中。
5. 线程安全
5.1 什么是并发
并发:指在同一时间段内,多个任务或进程同时执行或交替执行的能力。
5.2 什么是线程安全
线程安全:多个线程同时操作一个共享资源时,要保证该资源不被出现“污染”等意外情况。
实现线程安全的本质:线程安全其实就是一种等待机制, 多个需要同时访问此对象的线程进入这个对象的等待池形成队列, 等待前面线程使用完毕, 下一个线程再使用。
5.3 实现线程安全的方式
- 同步方法
同步方法:使用synchronized修饰的方法,就叫同步方法。用于保证线程在执行该方法时,其他线程只能在外等着。
synchronized关键字也可以修饰静态方法,此时如果调用该静态方法,将会锁住整个类。
同步方法默认使用 " this " 或 " 当前类Class对象 " 作为锁。
public synchronized void method(){
}
class Window4 implements Runnable {
int ticket = 100;// 共享数据
public void run() {
while (true) {
show();
}
}
public synchronized void show() {
if (ticket > 0) {
try {
Thread.currentThread().sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "售票,票号为:" + ticket--);
}
}
}
public class TestWindow4 {
public static void main(String[] args) {
Window4 w = new Window4();
Thread t1 = new Thread(w);
Thread t2 = new Thread(w);
Thread t3 = new Thread(w);
t1.setName("窗口1");
t2.setName("窗口2");
t3.setName("窗口3");
t1.start();
t2.start();
t3.start();
}
}
窗口2售票,票号为:4
窗口2售票,票号为:3
窗口2售票,票号为:2
窗口2售票,票号为:1 // 没有出现超卖现象
- 同步代码块
同步代码块:用synchronized关键字修饰的语句块。被该关键字修饰的语句块会自动被加上内置锁,从而实现同步。
object[锁对象]可以是任何对象 , // 但是推荐使用共享资源作为同步监视器。
同步是一种高开销的操作,因此应该尽量减少同步的内容。 //通常没有必要同步整个方法,使用synchronized代码块同步关键代码即可。//
synchronized(object){
}
//模拟火车站售票窗口,开启三个窗口售票,总票数为100张
class Window2 implements Runnable {
int ticket = 100;// 共享数据
public void run() {
while (true) {
// this表示当前对象
synchronized (this) {
if (ticket > 0) {
try {
Thread.currentThread().sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "售票,票号为:" + ticket--);
}
}
}
public class TestWindow2 {
public static void main(String[] args) {
Window2 w = new Window2();
Thread t1 = new Thread(w);
Thread t2 = new Thread(w);
Thread t3 = new Thread(w);
t1.setName("窗口1");
t2.setName("窗口2");
t3.setName("窗口3");
t1.start();
t2.start();
t3.start();
}
}
// 为什么这里的锁对象是this? 如何正确的选择锁对象?
// 在这个程序中,锁对象选择使用 this 是因为 this 表示当前对象,即代表 Window2 的实例对象。每个线程都是针对同一个 Window2 实例对象的,因此使用 this 作为锁对象能够保证同步访问共享资源 ticket,避免多个线程同时修改 ticket 导致数据错误。
// 如果使用 ticket 作为锁对象,可能会出现以下情况:当线程A获取到锁之后,由于线程B和线程C同时需要获取锁并且等待线程A释放锁,线程A释放锁后,线程B和线程C会同时竞争锁。这样就有可能出现同时修改 ticket 导致数据错误的情况。因此,使用 this 作为锁对象能够保证同一时刻只有一个线程可以访问共享资源 ticket。
// 在本例中,如果使用 ticket 作为锁对象,那么不同的线程将会使用不同的锁对象,因为每个线程都有自己的 Window2 实例,它们的 ticket 属性都是不同的对象。因此,使用 ticket 作为锁对象不能达到同步访问的目的。
// 相反,使用 this 作为锁对象是合适的选择。因为 this 表示当前对象,即代表 Window2 的实例对象,每个线程都是针对同一个 Window2 实例对象的,因此使用 this 作为锁对象能够保证同步访问共享资源 ticket,避免多个线程同时修改 ticket 导致数据错误。
// 锁对象可以是任何对象,包括但不限于以下几种:
// 实例对象:如果共享资源是实例变量,那么可以使用实例对象作为锁对象,即synchronized(this)。
// 类对象:如果共享资源是静态变量,那么可以使用类对象作为锁对象,即synchronized(MyClass.class)。
// 其他对象:如果共享资源是其它对象,可以创建一个单独的对象作为锁对象。
// 选择正确的锁非常重要,不仅可以避免死锁、提高性能,还可以保证线程安全。下面是一些选择锁的建议:
// 确定共享资源类型:首先需要确定需要保护的共享资源是实例变量还是静态变量,这将决定使用synchronized(this)还是synchronized(MyClass.class)。
// 锁对象应该是私有的:为了避免在其它地方修改锁对象,最好将锁对象声明为私有的,然后提供公共的访问方法。
// 避免使用String作为锁对象:String对象是不可变的,因此如果多个线程使用相同的字符串作为锁对象,可能会导致意外的线程竞争问题。
// 使用final修饰锁对象:使用final关键字修饰锁对象,可以确保它的引用不会在运行时发生改变,从而避免死锁和其他并发问题。
代码示例:
package com.xhj.thread;
/**
* 线程同步的运用——————————————————————同步代码块与同步方法
*
* @author XIEHEJUN
*
*/
public class SynchronizedThread {
class Bank {
private int account = 100;
public int getAccount() {
return account;
}
/**
* 用同步方法实现////////////////////////////////////////////////////////////////
*
* @param money
*/
public synchronized void save(int money) {
account += money;
}
/**
* 用同步代码块实现////////////////////////////////////////////////////////////////
*
* @param money
*/
public void save1(int money) {
synchronized (this) {
account += money;
}
}
}
class NewThread implements Runnable {
private Bank bank;
public NewThread(Bank bank) {
this.bank = bank;
}
@Override
public void run() {
for (int i = 0; i < 10; i++) {
// bank.save1(10);
bank.save(10);
System.out.println(i + "账户余额为:" + bank.getAccount());
}
}
}
/**
* 建立线程,调用内部类
*/
public void useThread() {
Bank bank = new Bank();
NewThread new_thread = new NewThread(bank);
System.out.println("线程1");
Thread thread1 = new Thread(new_thread);
thread1.start();
System.out.println("线程2");
Thread thread2 = new Thread(new_thread);
thread2.start();
}
public static void main(String[] args) {
SynchronizedThread st = new SynchronizedThread();
st.useThread();
}
}
- Lock锁
从JDK1.5开始提供。Lock(锁)是一个接口,常用实现类ReentrantLock。
class A{
private final ReentrantLock lock = new ReenTrantLock();
public void m(){
lock.lock();
try{
//需保证线程安全的代码;
} finally{
lock.unlock();
//如果同步代码有异常,要将unlock()写入finally语句块
}
}
}
5.5 什么是死锁
死锁问题的发生:多个线程各自占有一些共享资源, 并且互相等待其他线程占有的资源才能运行 而导致两个或者多个线程都在等待对方释放资源, 都停止执行的情形。 某一个同步块 同时拥有 “ 两个以上对象的锁 ” 时 , 就可能会发生 “ 死锁 ” 的问题。
6. ThreadLocal
介绍:他是JDK提供的工具类,用来解决多线程共享资源并发的问题,给各个线程提供一个变量副本。将数据缓存到各个线程内部,各个线程可以在任意时刻,任意方法中获取缓存的数据。
使用:通过ThreadLocal.set() 将共享资源的引用保存到各个线程中的一个ThreadLocalMap去,每个线程都有自己的ThreadLocalMap,执行ThreadLocal.get()时,各个线程就从自己的ThreadLocal中取出来这个数据。
使用场景:
- 当一个变量是多个线程共享的,但需要各个线程互补影响,就可考虑使用。
- 存储一些线程不安全的工具对象,如simpleDateFormat。
- Spring事务管理的底层就用到了ThreadLocal。
原理:他底层维护了一个ThreadLocalMap(每个线程Thread都有一个自己的ThreadLocalMap),ThreadLocal.set(值)就是去操作各个线程ThreadThreadLocalMap对象,将ThreadLocal存入ThreadLocalMap的key,值就存入ThreadLocalMap的value。
注意事项:如果在线程池中使用ThreadLocal会造成内存泄漏,因为当ThreadLocal对象使用完之后,应该要把设置的key,value进行回收,但线程池不会!从而导致内存泄漏。
解决办法:在使用了ThreadLocal对象后,手动调用ThreadLocal的remove方法,手动清除。
ThreadLocal是除了加锁这种同步方式【同步方法,代码块,Lock锁】之外的一种保证一种规避多线程访问出现线程不安全的方法,当我们在创建一个变量后,如果每个线程对其进行访问的时候访问的都是线程自己的变量这样就不会存在线程不安全问题。
6.1 ThreadLocal的简单使用
常用方法:
void set(T value) 设置当前线程的线程局部变量的值。
T get() 该方法返回当前线程所对应的线程局部变量。
void remove() 将当前线程局部变量的值删除,目的是为了减少内存的占用。需要指出的是,当线程结束后,对应该线程的局部变量将自动被垃圾回收,所以显式调用该方法清除线程的局部变量并不是必须的操作,但它可以加快内存回收的速度。
T initialValue() 返回该线程局部变量的初始值,该方法是一个protected的方法,显然是为了让子类覆盖而设计的。这个方法是一个延迟调用方法,在线程第1次调用get()或set(Object)时才执行,并且仅执行1次。ThreadLocal中的缺省实现直接返回一个null。
////////////////////////////// 关于set方法的源码 //////////////////////////////
public void set(T value) {
//获取当前线程
Thread t = Thread.currentThread();
//实际存储的数据结构类型
ThreadLocalMap map = getMap(t); // 源码见下面
//如果存在map就直接set,没有则创建map并set
if (map != null)
map.set(this, value);
else
createMap(t, value); // 源码见下面
}
//getMap方法————————————源码
ThreadLocalMap getMap(Thread t) {
//thred中维护了一个ThreadLocalMap
return t.threadLocals;
}
//createMap方法————————————源码
void createMap(Thread t, T firstValue) {
//实例化一个新的ThreadLocalMap,并赋值给线程的成员变量threadLocals
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
//★★★★★★★★ 从上面代码可以看出每个线程持有一个ThreadLocalMap对象。每一个新的线程Thread都会实例化一个ThreadLocalMap并赋值给成员变量threadLocals,使用时若已经存在threadLocals则直接使用已经存在的对象。 ★★★★★★★★//
////////////////////////////// 关于get方法的源码 //////////////////////////////
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this); // 源码见下面
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
//getEntry方法————————————源码
private Entry getEntry(ThreadLocal<?> key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
return e;
else
return getEntryAfterMiss(key, i, e);
}
///////////////////////// ThreadLocal使用例子: /////////////////////////////
public class TicketSystem {
private static ThreadLocal<Integer> ticketCount = new ThreadLocal<Integer>() {
@Override
protected Integer initialValue() {
// 每个线程初始时售票数量为10
return 10;
}
};
public boolean sellTicket() {
// 从ThreadLocal中获取当前线程的售票数量计数器
int count = ticketCount.get();
if (count > 0) {
// 售出一张票
count--;
// 将售票数量更新到ThreadLocal中
ticketCount.set(count);
// 打印售票信息
System.out.println(Thread.currentThread().getName() + ":售出第 " + (10 - count) + " 张票");
return true;
} else {
// 没有票了,提示顾客
System.out.println(Thread.currentThread().getName() + ":票已售完");
return false;
}
}
public static void main(String[] args) {
TicketSystem ticketSystem = new TicketSystem();
for (int i = 1; i <= 5; i++) {
Thread t = new Thread(new Runnable() {
@Override
public void run() {
while (ticketSystem.sellTicket()) {
// 继续售票
}
}
}, "窗口" + i);
t.start();
}
}
/**
在这个例子中,我们修改了TicketSystem类的ticketCount静态成员变量的初始值为10,表示每个线程最初拥有10张票。
在sellTicket方法中,我们首先从ticketCount中获取当前线程的售票数量计数器,然后检查计数器是否大于0。如果大于0,就将售票数量减1,将更新后的售票数量存储回ticketCount中,并打印售票信息,并返回true。否则,就说明该线程已经没有票了,直接打印提示信息,并返回false。
在main方法中,我们创建了5个线程,每个线程代表一个售票窗口,每个窗口最初有10张票。当每个窗口调用ticketSystem.sellTicket()方法时,它会自动获取自己的售票数量计数器并进行售票操作,直到售票数量为0为止。因为每个窗口最初有10张票,所以每个窗口最多只能售出10张票。
在main方法中,我们使用一个while循环来反复调用ticketSystem.sellTicket()方法,直到售票数量为0为止。这样可以确保每个线程都能将自己的10张票全部售出。
**/
6.2 ThreadLocal和Synchronized区别
ThreadLocal和Synchronized都是为了解决多线程中相同变量的访问冲突问题,不同的是:
-
Synchronized是通过线程等待,牺牲时间来解决访问冲突
-
ThreadLocal的作用主要是做数据隔离,填充的数据只属于当前线程,变量的数据对别的线程而言是相对隔离的。
-
ThreadLocal是通过每个线程单独一份存储空间,牺牲空间来解决冲突,并且相比于Synchronized,ThreadLocal具有线程隔离的效果,只有在线程内才能获取到对应的值,线程外则不能访问到想要的值。
-
ThreadLocal是解决线程安全问题一个很好的思路,它通过为每个线程提供一个独立的变量副本解决了变量并发访问的冲突问题。在很多情况下,ThreadLocal比直接使用synchronized同步机制解决线程安全问题更简单,更方便,且结果程序拥有更高的并发性。
7. Volatile
volatile:是Java语言中的一种轻量级的同步机制,它可以确保共享变量的内存可见性,也就是当一个线程修改(在多线程环境下,不管你是否出现脏数据,只要修改,都能知道,因为它获取最新值的方式变了的,他跟JVM什么的主内存相关)了共享变量的值时,其他线程能够立即知道这个修改。跟synchronized一样都是同步机制,但是相比之下,synchronized属于重量级锁,volatile属于轻量级锁。
使用场景:让多个线程间都能拿到最新的数据。
比如:
有2个线程,他们有个共享资源 volatile boolean flag = false,A线程用while循环判断false的值,发现flag为false时,就什么都不做。
B线程用于去执行另一段逻辑,当执行成功后,就将false的值改为true,因为是用volatile修饰的flag,所以A线程能及时发现flag变为true,于是开始执行相关逻辑。
// 在多线程中,如果不使用Volatile修改共享资源,那么当共享资源被修改时,其他线程是不能知道资源被修改的。
// 所以,一般为了解决这个可见性问题需要加锁,可以用`synchrnoized`或`Volatile`来解决这个问题。
如何利用synchrnoized来解决可见性问题: https://www.bilibili.com/video/BV1Zb4y1J7He/?spm_id_from=333.337.search-card.all.click&vd_source=61b6fb4e547748656e36b17ee95125fb
Java内存模型(JVM):描述了Java程序中各种变量(线程共享变量)的访问规则,以及在JVM中将变量,存储到内存和从内存中读取变量这样的底层细节。它存在三个特性:可见性,原子性,有序性。
这里不具体介绍JVM里面那些概念,在此前提下,简单介绍什么是可见性。
可见性:是指线程之间的可见性,一个线程修改的状态对另一个线程是可见的。volatile能保证可见性。

原子性:原子性指的是某个线程正在执行某个操作时,要么整体成功,要么整体失败。不会被其他线程的操作所干扰,不会出现部分执行的情况。volatile不能保证原子性。
有序性:保证线程之间操作的有序性。Java 语言提供了 volatile 和 synchronized 两个关键字来保证线程之间操作的有序性。 volatile能保证有序性。
volatile 是因为其本身包含“禁止指令重排序”的语义。
synchronized 是由“一个变量在同一个时刻只允许一条线程对其进行锁操作”
```java
举例:视频多人同时点赞功能,程序是如何做到实时更新点赞量的。
获取点赞量:
1. 先去硬盘或数据库里面读取数据
2. 将读取到的数据加载到内存
3. 将内存中的数据加载到CPU缓冲区
4. 从CPU缓冲区得到点赞量
点赞:
1. 将点赞数+1保存到CPU缓冲区
注意:更新后的CPU缓冲区数据 不会 立即加载到内存中去
2. CPU在合适的时机,将CPU缓冲区的数据同步到内存
3. 将内存的数据同步到数据库或硬盘
// ☆☆☆☆☆☆☆☆☆ 注意这句话:不加volatile的,会走缓存区:所以:当多人同时点了赞,A同学点了赞,点赞数+1后,硬盘数据没有立即更新,B同学通过在它的CPU缓冲区看到的点赞量还是原来的数据。 ☆☆☆☆☆☆☆☆☆ //
// ☆☆☆☆☆☆☆☆☆Volatile:就能解决这个问题,它相当于是让CPU禁止了CPU缓冲区,只要某个线程更改了共享变量,就会立马更新硬盘或数据库的数据!! ☆☆☆☆☆☆☆☆☆ //
/////////////////////////////////// 可见性例子演示:不加volatile ///////////////////////////////////////
public class Vo {
static class Data{
// 不用 volatile 修饰
int number =0;
public void add() {
this.number = number +1;
}
}
private static void testVolatile() {
Data myData = new Data();
new Thread(() -> {
try {
TimeUnit.SECONDS.sleep(2);
myData.add();
System.out.println(Thread.currentThread().getName()+" 更新了 number 的值为 :"+myData.number);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "new_thread").start();
while (myData.number == 0){
// 主线程还在这里卡着,因为number虽然被另一个线程改了,但是主线程不知道
}
System.out.println("程序结束");
}
public static void main(String[] args) {
testVolatile();
}
}//PS:永远不会输出程序结束
/////////////////////////////////// 可见性例子演示:加volatile ///////////////////////////////////////
public class Vo {
static class Data{
// 用 volatile 修饰
volatile int number =0;
public void add() {
this.number = number +1;
}
}
private static void testVolatile() {
Data myData = new Data();
new Thread(() -> {
try {
TimeUnit.SECONDS.sleep(2);
myData.add();
System.out.println(Thread.currentThread().getName()+" 更新了 number 的值为 :"+myData.number);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "new_thread").start();
while (myData.number == 0){
//使用volatile修饰后, 主线程不在这里卡着,因为number被另一个线程改了就会立马更新number的值,体现了volatile的可见性
}
System.out.println("程序结束");
}
public static void main(String[] args) {
testVolatile();
}
}//PS:会输出程序结束
/////////////////////////////////// 可见性例子演示 ///////////////////////////////////////
// 示例2:
public class ControlVariableTest {
private static volatile boolean stop = false;
public static void main(String[] args) throws Exception {
Thread t = new Thread(() -> {
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
stop = true;
System.out.println("设置stop值为true");
});
t.start();
while (!stop) {
// 不加 volatile ,代码就会在这里卡着,因为当前主线程不知道 stop 的值 被另一个线程改为了true。也就无法执行后面的代码,输出:发现stop值被修改了,修改为:true
// 若加了 volatile ,代码就不会在这里卡着,会第一时间知道 stop 值被修改为了true,就可以执行后面的代码,输出:发现stop值被修改了,修改为:true
// 特别注意:☆☆☆☆☆☆☆☆☆☆ 本代码不能再 while (!stop) { } 里面写代码,若写了,由于idea的问题嘛,如果你在这里面写了代码,他就判断是死循环,它发现出现死循环后,为避免无限卡死,它会自动结束代码(跳出死循环,执行后面的代码),
}
System.out.println("发现stop值被修改了,修改为:"+stop);
}
}
/////////////////////////////////// 原子性例子演示:不加volatile ///////////////////////////////////////
public class Th {
// 不加volatile
private int num = 0;
public void addNum(){
num ++;
}
public int getNum(){
return num;
}
public static void main(String[] args) {
Th th = new Th();
for (int i = 0; i < 10; i++) { // 创建10个线程
new Thread(()->{
for (int j = 0; j < 100; j++) { // 每个线程执行100次 addNum()。 我们知道当多个线程同时去操作一个数据的时候,会出现线程安全问题。 这10个线程执行完毕后,肯定数据会出现脏数据
th.addNum();
try {
Thread.sleep(1L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
while (true) { // 主线程不断获取最新num值
System.out.println("当前最新的num值为:" + th.getNum()); // 发现输出的是:当前最新的num值为:841。表示确实出现了脏数据
try {
Thread.sleep(500L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
/////////////////////////////////// 原子性例子演示:加volatile ///////////////////////////////////////
public class Th {
// 不加volatile
private volatile int num = 0;
public void addNum(){
num ++;
}
public int getNum(){
return num;
}
public static void main(String[] args) {
Th th = new Th();
for (int i = 0; i < 10; i++) { // 创建10个线程
new Thread(()->{
for (int j = 0; j < 100; j++) { // 每个线程执行100次 addNum()。 我们知道当多个线程同时去操作一个数据的时候,会出现线程安全问题。 这10个线程执行完毕后,肯定数据会出现脏数据
th.addNum();
try {
Thread.sleep(1L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
while (true) { // 主线程不断获取最新num值
System.out.println("当前最新的num值为:" + th.getNum()); // 发现输出的是:当前最新的num值为:850。表明加了volatile也不能保证原子性。结论:volatile 不能保证原子性
try {
Thread.sleep(500L);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
8. Spring中的bean是线程安全的吗
结论:不安全。
Spring的Bean作用域(scpoe)类型:
singleton:单例,默认作用域。
prototype:原型,每次创建一个新对象。
request:请求,每次Http请求创建一个新对象,适用于WebApplicationContext环境下。
session:会话,同一个会话共享一个实例,不同会话使用不用的实例。
global-session:全局会话,所有会话共享一个实例。
@Scope("prototype")//多实例,IOC容器启动创建的时候,并不会创建对象放在容器在容器当中,当你需要的时候,需要从容器当中取该对象的时候,就会创建。
@Scope("singleton")//单实例 IOC容器启动的时候就会调用方法创建对象,以后每次获取都是从容器当中拿同一个对象(map当中)。
@Scope("request")//同一个请求创建一个实例
@Scope("session")//同一个session创建一个实例
8.1 单例Bean
每个线程都共享一个单例实例Bean,所以不安全。是Spring的默认作用域。
如果单例Bean,是一个无状态Bean【也就是线程中的操作不会对Bean的成员执行查询以外的操作,那么这个单例Bean是线程安全的。】
比如Spring mvc 的 Controller、Service、Dao等,这些Bean大多是无状态的,只关注于方法本身。
controller、service和dao层本身并不是线程安全的,只是如果只是调用里面的方法,而且多线程调用一个实例的方法,会在内存中复制变量,这是自己的线程的工作内存,是安全的。
8.2 原型Bean
每次都创建一个新对象,线程之间不存在Bean的共享,自然是不会有线程安全的问题。
8.3 @Scope注解
他是用于改变Bean的作用域的。
不加@Scope
@RestController
public class TestController {
private int var = 0;
@GetMapping(value = "/test_var")
public String test() {
System.out.println("普通变量var:" + (++var));
return "普通变量var:" + var ;
}
}
输出结果:
普通变量var:1
普通变量var:2
普通变量var:3
加@Scope(value = "prototype")
// 加上@Scope注解,他有多个取值:单例-singleton 多实例-prototype
@Scope(value = "prototype")
@RestController
public class TestController {
private int var = 0;
@GetMapping(value = "/test_var")
public String test() {
System.out.println("普通变量var:" + (++var));
return "普通变量var:" + var ;
}
}
这样一来,每个请求都单独创建一个Controller容器,所以各个请求之间是线程安全的,三次请求结果:
普通变量var:1
普通变量var:1
普通变量var:1
8.4 加@Scope(value = "prototype")注解是不是一定就线程安全
@RestController
@Scope(value = "prototype") // 加上@Scope注解,他有2个取值:单例-singleton 多实例-prototype
public class TestController {
private int var = 0;
private static int staticVar = 0;
@GetMapping(value = "/test_var")
public String test() {
System.out.println("普通变量var:" + (++var)+ "---静态变量staticVar:" + (++staticVar));
return "普通变量var:" + var + "静态变量staticVar:" + staticVar;
}
}
输出结果:
普通变量var:1---静态变量staticVar:1
普通变量var:1---静态变量staticVar:2
普通变量var:1---静态变量staticVar:3
★★ 虽然每次都是单独创建一个Controller,但如果这个变量本身是static的。则即便是加上@Scope注解也不一定能保证Controller 100%的线程安全。 ★★
9. 线程池
https://mp.weixin.qq.com/s/I_3GJfZgz21DnuXmrJEzgg
线程池,是一种线程的使用方式,它为了降低线程使用中频繁的创建和销毁所带来的资源消耗与代价。
通过创建一定数量的线程,让他们时刻准备就绪等待新任务的到达,而任务执行结束之后再重新回来继续待命。
9.1 为什么要使用线程池
不使用线程池的时候,当我们要使用多线程,就得去创建线程,用完释放销毁线程,每次用就得去创建,用完还得销毁。
使用线程池的时候,让线程时刻准备就绪等待新任务的到达,而任务执行结束之后再重新回来继续待命。
9.2 Java中线程池的使用
使用方式:
- ThreadPoolExecutor
- Executors(阿里不允许使用)
ThreadPoolExecutor:通常使用 ThreadPoolExecutor 来创建线程池。
其中 ScheduledThreadPoolExecutor:是实现了定时任务功能,能够使提交到线程池中的任务定时、定期执行的线程池。
线程池执行流程:
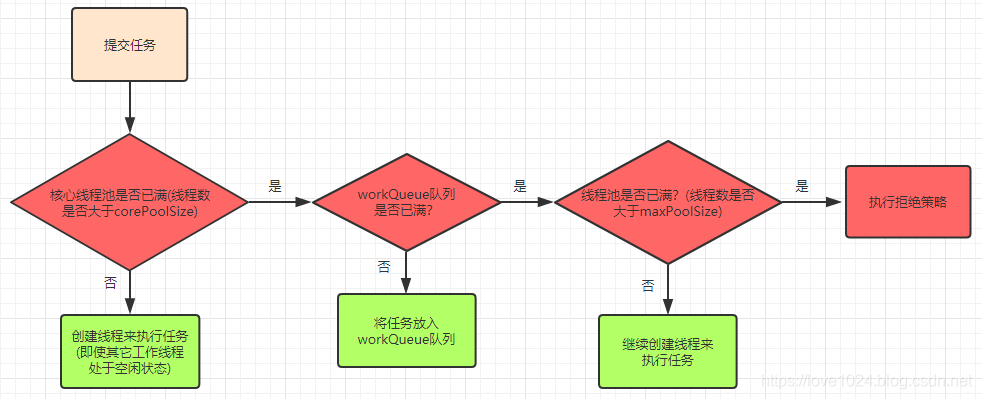
ThreadPoolExecutor并不是把每个新任务都直接放到等待队列中,而是有一套既定的规则来执行每个新任务:
情况1:线程提交任务后,在线程数没有达到核心线程数(corePoolSize)时,每个新任务都会创建一个新的线程来执行任务。
情况2:当线程数达到核心线程数时,每个新任务会被放入到等待队列(workQueue)中等待被执行。
情况3:当等待队列已经满了之后,如果线程数没有到达总的线程数上限,那么会创建一个非核心线程来执行任务。
情况4:当线程数已经到达总的线程数(maximumPoolSize)限制时,新的任务会被拒绝策略者处理(handler),线程池无法执行该任务。

// 关于ThreadPoolExecutor构造器:
public ThreadPoolExecutor(
int corePoolSize, // 线程池核心线程数量,在没有使用的时候,也会被销毁回收。
int maximumPoolSize, // 线程池最大线程数量,在核心线程数的基础上可能会额外增加一些非核心线程,需要注意的是只有当workQueue队列填满时才会创建多于corePoolSize的线程(线程池总线程数不超过maxPoolSize)
// 线程池最大线程数量=核心线层数+非核心线程数。当等待队列满了之后,新的任务会创建新的非核心线程来执行,直到线程数到达总数的上限。
// 线程池最大线程数量不包括队列中的线程数。
long keepAliveTime, // 非核心线程的空闲时间超过keepAliveTime就会被自动终止回收掉,注意当corePoolSize=maxPoolSize时,keepAliveTime参数也就不起作用了(因为不存在非核心线程)
// 线程空闲等待该时间后会被销毁。非核心线程默认会被销毁,而核心线程则需要开发者自己设定是否允许被销毁(通过allowCoreThreadTimeOut设置)。
TimeUnit unit, // keepAliveTime的时间单位
BlockingQueue<Runnable> workQueue, // 用于保存任务的队列,可以为无界、有界、同步移交三种队列类型之一,当池子里的工作线程数大于corePoolSize时,这时新进来的任务会被放到队列中
// 一般使用的队列有LinkedBlockingQueue、ArrayBlockingQueue、SychronizeQueue、PriorityBlockingQueue等,前两者是普通的阻塞队列,最后一个是优先阻塞队列,剩下的一个(SychronizeQueue)是没有容量的队列。
ThreadFactory threadFactory, // 创建线程的工厂类,默认使用Executors.defaultThreadFactory(),也可以使用guava库的ThreadFactoryBuilder来创建
RejectedExecutionHandler handler // 线程池无法继续接收任务(队列已满且线程数达到maximunPoolSize)时的饱和策略,取值有AbortPolicy、CallerRunsPolicy、DiscardOldestPolicy、DiscardPolicy
)
ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 10, 5000, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>());
// ThreadPoolExecutor方法:
// ☆☆☆☆☆☆☆☆☆☆ execute(Runnable command) :提交一个任务 ☆☆☆☆☆☆☆☆☆
// ☆☆☆☆☆☆☆☆☆☆ Future submit(Runnable/Callable):提交一个任务,这个任务拥有返回值。 ☆☆☆☆☆☆☆☆☆
// ☆☆☆☆☆☆☆☆☆☆ 二者区别:
// 1. submit方法可以接受Callable和Runnable类型的任务。execute方法只能接受Runnable类型的任务
// 2. submit方法返回一个Future对象,可以用来获取任务执行的结果或者取消任务的执行。
// 3. submit方法可以通过Future对象的get方法来获取任务执行过程中抛出的异常。execute方法无法直接获取任务执行过程中的异常,需要通过自定义的异常处理机制来处理异常。
isShutDown:线程池是否被关闭
// shutdown():关闭线程池,等待任务都执行完
// shutdownNow():关闭线程池,不等待任务执行完
getTaskCount():线程池已执行和未执行的任务总数
getCompletedTaskCount():已完成的任务数量
getPoolSize():线程池当前线程数量
getActiveCount():当前线程池中正在执行任务的线程数量
preStartAllCoreThread:提前启动所有的线程
// ThreadPoolExecutor如何设置参数
1、默认值
* corePoolSize=1
* queueCapacity=Integer.MAX_VALUE
* maxPoolSize=Integer.MAX_VALUE
* keepAliveTime=60s
* allowCoreThreadTimeout=false
* rejectedExecutionHandler=AbortPolicy()
2、如何来设置
* 需要根据几个值来决定
- tasks :每秒的任务数,假设为1000
- taskcost:每个任务花费时间,假设为0.1s
- responsetime:系统允许容忍的最大响应时间,假设为1s
* 做几个计算
- corePoolSize = 每秒需要多少个线程处理?
* 一颗CPU核心同一时刻只能执行一个线程,然后操作系统切换上下文,核心开始执行另一个线程的代码,以此类推,超过cpu核心数,就会放入队列,如果队列也满了,就另起一个新的线程执行,所有推荐:corePoolSize = ((cpu核心数 * 2) + 有效磁盘数),java可以使用Runtime.getRuntime().availableProcessors()获取cpu核心数
- queueCapacity = (coreSizePool/taskcost)*responsetime
* 计算可得 queueCapacity = corePoolSize/0.1*1。意思是队列里的线程可以等待1s,超过了的需要新开线程来执行
* 切记不能设置为Integer.MAX_VALUE,这样队列会很大,线程数只会保持在corePoolSize大小,当任务陡增时,不能新开线程来执行,响应时间会随之陡增。
- maxPoolSize = (max(tasks)- queueCapacity)/(1/taskcost)
* 计算可得 maxPoolSize = (1000-corePoolSize)/10,即(每秒并发数-corePoolSize大小) / 10
* (最大任务数-队列容量)/每个线程每秒处理能力 = 最大线程数
- rejectedExecutionHandler:根据具体情况来决定,任务不重要可丢弃,任务重要则要利用一些缓冲机制来处理
- keepAliveTime和allowCoreThreadTimeout采用默认通常能满足
// ThreadPoolExecutor中有很多参数可以提供我们参考线程池的运行情况:
largestPoolSize:线程池中曾经到达的最大线程数量
completedTaskCount:完成的任务个数
getAliveCount:获取当前正在执行任务的线程数
getTaskCount:获取当前任务个数
getPoolSize:获取当前线程数
// workQueue队列:
SynchronousQueue(同步移交队列):没有容量的队列,每一个插入到这个队列的任务必须马上找到可以执行的线程,如果没有则拒绝执行。
LinkedBlockingQueue(无界队列):队列长度不受限制,普通的阻塞队列,尾插头出
ArrayBlockintQueue(有界队列):队列长度受限,普通的阻塞队列,当队列满了就需要创建多余的线程来执行任务。创建的时候必须指定长度。
PriorityBlockingQueue(优先级队列):具有优先级的无界阻塞队列,优先级通过参数Comparator实现。
ArrayBlockingQueue和PriorityBlockingQueue使用较少,一般使用LinkedBlockingQueue和SynchronousQueue。
关于这几个队列:https://blog.csdn.net/FUTEROX/article/details/122893521
// handler拒绝策略:
AbortPolicy:直接抛出异常(RejectedExecutionException),这也是默认的策略。
CallerRunsPolicy:使用调用者所在的线程来执行任务(也就是主线程嘛),即:让提交任务的线程去执行任务
DiscardOldestPolicy:丢弃队列中最靠前的任务并执行当前任务,即:把最先进入队列的任务丢掉。
DiscardPolicy:直接丢弃当前任务,也不抛异常。
若要自定义拒绝策略:需要实现RejectedExecutionHandler接口,重写rejectedExecution方法。
// 等待队列的线程先执行还是非核心线程先执行?:
当等待队列满了的之后,线程池会创建非核心线程来执行,且执行优先级比等待队列高!!!
举个例:比如核心线程数10个满了,等待队列10个也满了,此时有其他任务来了,核心线程还没执行完,就创建非核心线程来执行。而不是放到等待队列去等着。
使用例子:
public class ThreadPool {
public static void main(String[] args) {
// 1. 创建线程池
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(
5,
8,
0L,
TimeUnit.SECONDS,
// ArrayBlockingQueue 有界,适合已知最大存储容量的场景
// LinkedBlockingQueue 可有界可以无界
new LinkedBlockingQueue<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy()
);
// 2. 模拟有8个线程任务
for (int i = 0; i < 8; i++) {
poolExecutor.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "===>办理业务");
}
});
}
}
}
执行结果:
pool-1-thread-3===>办理业务
pool-1-thread-3===>办理业务
pool-1-thread-4===>办理业务
pool-1-thread-1===>办理业务
pool-1-thread-2===>办理业务
pool-1-thread-3===>办理业务
pool-1-thread-5===>办理业务
pool-1-thread-4===>办理业务
流程逻辑分析:
1. 线程池定义了 5 个核心线程,最大线程数为8个,等待队列长度为3个(若不指定就是不限),拒绝策略为默认的直接拒绝。当来了8个任务的时候,其中5个任务会被交给核心线程去执行,另外3个就会到任务队列进行等待。
2. 当某个核心线程将任务执行完毕后,就开始执行任务队列的线程。
public class ThreadPool {
public static void main(String[] args) {
// 1. 创建线程池
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(
5,
8,
0L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy()
);
// 2. 模拟有13个线程任务
for (int i = 0; i < 13; i++) {
poolExecutor.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + "===>办理业务");
}
});
}
}
}
Exception in thread "main" pool-1-thread-1===>办理业务
pool-1-thread-5===>办理业务
pool-1-thread-5===>办理业务
pool-1-thread-5===>办理业务
pool-1-thread-3===>办理业务
pool-1-thread-1===>办理业务
pool-1-thread-6===>办理业务
pool-1-thread-4===>办理业务
pool-1-thread-2===>办理业务
pool-1-thread-7===>办理业务
pool-1-thread-8===>办理业务
java.util.concurrent.RejectedExecutionException: Task sut.edu.zyp.dormitory.manage.controller.ThreadPool$1@34c45dca rejected from java.util.concurrent.ThreadPoolExecutor@52cc8049[Running, pool size = 8, active threads = 8, queued tasks = 3, completed tasks = 0]
at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063)
at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830)
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379)
at sut.edu.zyp.dormitory.manage.controller.ThreadPool.main(ThreadPool.java:32)
Executors:线程池的工具类,也是创建线程池的一种方式,用于快速创建不同类型的线程池。阿里规范手册不允许这样创建

Executors可以创建的线程池类型:(不推荐以这种方式创建)
-
ExecutorService newCachedThreadPool()
说明:初始化一个可以缓存线程的线程池,默认缓存60s,线程池的线程数可达到Integer.MAX_VALUE,即2147483647,内部使用SynchronousQueue作为阻塞队列;
特点:在没有任务执行时,当线程的空闲时间超过keepAliveTime,会自动释放线程资源;当提交新任务时,如果没有空闲线程,则创建新线程执行任务,会导致一定的系统开销;
因此,使用时要注意控制并发的任务数,防止因创建大量的线程导致而降低性能。 -
ExecutorService newFixedThreadPool(int nThreads)
说明:初始化一个指定线程数的线程池,其中corePoolSize == maxiPoolSize,使用LinkedBlockingQuene作为阻塞队列
特点:即使当线程池没有可执行任务时,也不会释放线程。 -
ExecutorService newSingleThreadExecutor()
说明:初始化只有一个线程的线程池,内部使用LinkedBlockingQueue作为阻塞队列。
特点:保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。如果该线程异常结束,会重新创建一个新的线程继续执行任务,唯一的线程可以保证所提交任务的顺序执行 -
ScheduledExecutorService newScheduledThreadPool(int corePoolSize)
特定:初始化的线程池可以在指定的时间内周期性的执行所提交的任务,在实际的业务场景中可以使用该线程池定期的同步数据。
9.4 线程池使用案例

package com.itheima.demo05;
/**
* 任务类:
* 包含了商品数量,客户名称,送手机的行为
*
* @author Eric
* @create 2021-10-02 10:46
*/
public class MyTask implements Runnable{
//设计一个变量,用于表示商品的数量
private static int id = 10;
//表示客户名称变量
private String userName;
public MyTask(String userName) {
this.userName = userName;
}
@Override
public void run() {
String name = Thread.currentThread().getName();
System.out.println(userName + "正在使用" + name + "参与秒杀任务...");
try {
Thread.sleep(200);//为了逼真一点,休眠200毫秒
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (MyTask.class){
if(id > 0){
System.out.println(userName + "使用" + name + "秒杀:" + id-- + "号商品成功啦!");
}else {
System.out.println(userName + "使用" + name + "秒杀失败了!");
}
}
}
}
public class MyTest {
public static void main(String[] args) {
//1.创建一个线程池对象
ThreadPoolExecutor pool = new ThreadPoolExecutor(3,5,1, TimeUnit.MINUTES,new LinkedBlockingQueue<>(15));
//2.循环创建任务对象
for (int i = 0; i < 20; i++) {
MyTask myTask = new MyTask("客户" + i);
pool.submit(myTask);
}
//3.关闭线程池
pool.shutdown();
}
}
10. Springboot中线程池的使用
https://mp.weixin.qq.com/s/KvPJMGBzOxGbH98ed9QRpw
https://blog.csdn.net/boling_cavalry/article/details/79120268
注意:我发现使用方式可能有2中,一种就是使用注解的方式,另一种就是不使用注解。
使用注解那种方式:不能得到你异步处理的返回值。如果你想对异步处理的方法有返回值,就得采用不使用注解那种方法。
上述2个网址是使用注解的例子,这里配上一个网上的不使用注解的例子:(还有很多,真正用到的时候,百度搜一下。)https://blog.csdn.net/weixin_55850954/article/details/130308400
//Spring提供了多种线程池:
1. SimpleAsyncTaskExecutor:不是真的线程池,这个类不重用线程,每次调用都会创建一个新的线程。默认使用这个线程池
2. SyncTaskExecutor:这个类没有实现异步调用,只是一个同步操作。只适用于不需要多线程的地
3. ConcurrentTaskExecutor:Executor的适配类,不推荐使用。如果ThreadPoolTaskExecutor不满足要求时,才用考虑使用这个类
4. ThreadPoolTaskScheduler:可以使用cron表达式
5. ThreadPoolTaskExecutor :最常使用,//推荐。其实质是对java.util.concurrent.ThreadPoolExecutor的包装。
// 线程池配置类
@Configuration
@EnableAsync // 开启异步任务支持
public class ThreadPoolConfig {
@Bean("taskExecutor")
public Executor asyncServiceExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
// 设置核心线程数,默认值为 1,当线程池中的线程数小于 corePoolSize 时,新任务将创建一个新线程执行。
executor.setCorePoolSize(5);
// 设置最大线程数,默认值为 Integer.MAX_VALUE,当线程池中的线程数大于或等于 corePoolSize 且小于 maxPoolSize 时,新任务将被放入任务队列等待执行或新建线程执行。
executor.setMaxPoolSize(20);
// 设置线程池中任务队列的容量,默认值为 Integer.MAX_VALUE,当线程池中的线程数等于 maxPoolSize 且任务队列已满时,新任务将根据拒绝策略进行处理。
executor.setQueueCapacity(Integer.MAX_VALUE);
// 设置空闲线程的存活时间,默认为 60 秒。如果线程池中的线程数大于 corePoolSize,且线程空闲时间超过 keepAliveSeconds,则该线程将被销毁,直到线程池中的线程数不超过 corePoolSize。
executor.setKeepAliveSeconds(60);
// 设置线程名称前缀,threadNamePrefix:线程名前缀,默认为 "threadPool-"。
executor.setThreadNamePrefix("异步线程");
// 用于指定线程池在关闭时是否等待正在执行的任务完成
// true,则在调用 ThreadPoolTaskExecutor.shutdown() 方法关闭线程池时,线程池会等待所有正在执行的任务完成后再关闭。
// false,则在调用 ThreadPoolTaskExecutor.shutdown() 方法关闭线程池时,线程池会立即关闭,不会等待正在执行的任务完成。
// 通常情况下,如果希望保证所有任务都能被执行完毕并且不希望有任务被中断,可以将 setWaitForTasksToCompleteOnShutdown 属性设置为 true;如果希望尽快关闭线程池并且不关心任务的执行情况,可以将该属性设置为 false。
executor.setWaitForTasksToCompleteOnShutdown(true);
//执行初始化,手动初始化线程池,该方法在 Spring 容器启动时会自动调用,一般不需要手动调用。
executor.initialize();
return executor;
}
}
// 多线程执行任务类
@Component
public class ThreadServiceImpl {
// 关于这个注解,如果不指定value,将会自动提交到一个name为taskExecutor的线程池去执行。
// 如果你的项目有多个线程池,最好指定名称,表明要使用哪个线程池。
@Async("taskExecutor")
public void print() {
try {
Thread.sleep(8000);
System.out.println("222222");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
@GetMapping("/thread")
@ApiOperation("测试线程池")
public MsgResult threadTest() {
// 花费5秒
activityInfoService.threadTest();
// 多线程异步执行
threadService.print(); // 花费8秒
// 主线程执行完毕就会立即返回 不会管——>多线程是否执行完毕
return MsgResult.success("成功");
}
11. 总结线程池用法总结
https://www.bilibili.com/video/BV16g41177Pw?p=1
https://www.bilibili.com/video/BV11s4y1V776/?spm_id_from=333.788
前言:上面的内容有些已经展示过线程池的用法了,但是都不是特别详细,接下来详细演示一下用法。
线程池的submit方法与execute方法区别:
submit能异步执行有返回值或无返回值的线程。
execute只能执行无返回值的线程。
11.1 Java方式使用无返回值的线程池
public class ThreadPool {
public static void main(String[] args) {
// 1. 创建线程池
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(
5,
8,
0L,
TimeUnit.SECONDS,
// ArrayBlockingQueue 有界,适合已知最大存储容量的场景
// LinkedBlockingQueue 可有界可以无界
new ArrayBlockingQueue<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy()
);
poolExecutor.execute(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("邮件发送成功");
}
});
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("注册成功");
//关闭线程池
poolExecutor.shutdown();
}
}
11.2 Java方式使用有返回值的线程池
public class ThreadPool {
public static void main(String[] args) {
// 1. 创建线程池
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(
5,
8,
0L,
TimeUnit.SECONDS,
// ArrayBlockingQueue 有界,适合已知最大存储容量的场景
// LinkedBlockingQueue 可有界可以无界
new ArrayBlockingQueue<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy()
);
Future<Integer> future = poolExecutor.submit(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
return 666;
}
});
Integer integer = null;
try {
integer = future.get();
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("多线程callable返回的数据:"+integer);
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("注册成功");
//关闭线程池
poolExecutor.shutdown();
}
}
11.3 springboot整合线程池
请见 10. Springboot中线程池的使用
12. 如何合理的配置线程池
先回顾一下线程池的构造参数:发现最重要的的就是要去思考如何配置线城池的核心线程数。
// 关于ThreadPoolExecutor构造器:
public ThreadPoolExecutor(
int corePoolSize, // 线程池核心线程数量,在没有使用的时候,也会被销毁回收。
int maximumPoolSize, // 线程池最大线程数量,在核心线程数的基础上可能会额外增加一些非核心线程,需要注意的是只有当workQueue队列填满时才会创建多于corePoolSize的线程(线程池总线程数不超过maxPoolSize)
// 线程池最大线程数量=核心线层数+非核心线程数。当等待队列满了之后,新的任务会创建新的非核心线程来执行,直到线程数到达总数的上限。
// 线程池最大线程数量不包括队列中的线程数。
long keepAliveTime, // 非核心线程的空闲时间超过keepAliveTime就会被自动终止回收掉,注意当corePoolSize=maxPoolSize时,keepAliveTime参数也就不起作用了(因为不存在非核心线程)
// 线程空闲等待该时间后会被销毁。非核心线程默认会被销毁,而核心线程则需要开发者自己设定是否允许被销毁(通过allowCoreThreadTimeOut设置)。
TimeUnit unit, // keepAliveTime的时间单位
BlockingQueue<Runnable> workQueue, // 用于保存任务的队列,可以为无界、有界、同步移交三种队列类型之一,当池子里的工作线程数大于corePoolSize时,这时新进来的任务会被放到队列中
// 一般使用的队列有LinkedBlockingQueue、ArrayBlockingQueue、SychronizeQueue、PriorityBlockingQueue等,前两者是普通的阻塞队列,最后一个是优先阻塞队列,剩下的一个(SychronizeQueue)是没有容量的队列。
ThreadFactory threadFactory, // 创建线程的工厂类,默认使用Executors.defaultThreadFactory(),也可以使用guava库的ThreadFactoryBuilder来创建
RejectedExecutionHandler handler // 线程池无法继续接收任务(队列已满且线程数达到maximunPoolSize)时的饱和策略,取值有AbortPolicy、CallerRunsPolicy、DiscardOldestPolicy、DiscardPolicy
)
CPU密集型:指该任务需要大量的运算,比如图片的处理,视频的处理,密码加解密,正则运算。总之就是要做大量运算的。
建议:线程数 = (CPU核心数+1)。比如我的CPU是4核8线程,则括号里面的核心数是指这里的线程8,所以,建议设置的线程数为8+1。
+1是为了防止页缺失的情况。线程数为什么不是越多越好,因为CPU密集型主要是需要算力,设置太多线程,导致CPU要在多个线程间切换,反而影响算力。
IO密集型:指该任务需要大量的IO,比如读取文件,数据库连接,网络通讯。
建议:可以设置多一点,推荐线程数 = CPU核数 * 2。为啥推荐多一些点呢,因为IO密集型主要是需要操作,线程多一点,就能提升效率。
13. 如何选择使用JAVA自带的线程池还是Spring Boot提供的线程池
Java提供了自带的线程池实现,可以通过ThreadPoolExecutor类来创建和管理线程池。Java的线程池实现相对比较简单,可以满足大部分的使用需求,而且使用起来比较方便,可以自由地设置线程池的大小、工作队列、线程池关闭策略等等。
Spring Boot也提供了对线程池的整合支持,可以使用Spring Boot提供的ThreadPoolTaskExecutor类来创建和管理线程池。
注意:如果使用springboot那种注解的方式(@Async)来做,不能处理你想有返回值的异步处理。
14. 乐观锁与悲观锁
乐观锁:比较乐观,对于并发操作产生的线程安全问题持乐观状态,总是认为不会发生,所以每次操作都不上锁,其他线程也可以操作数据。当其要更新数据时,才判断数据是否被修改了,若是,则不进行数据更新,返回错误信息。
悲观锁:比较悲观,对于并发操作产生的线程安全问题持悲观状态,总是认为会发生,所以每次操作多上锁,其他线程不允许操作数据。就像synchronized,获取到资源就上锁,其他线程不准来操作。
如何选择乐观锁还是悲观锁:
乐观锁:适用于写比较少的情况。即冲突很少发生的时候,这样可以省去锁的开销,加大了系统的整个吞吐量。
悲观锁:适用于写比较多的情况,依赖于数据库锁,效率低,更新失败的概率比较低。
为什么需要锁:
在并发情况下,保证实现线程安全的数据更新。
数据库中的行锁,表锁,读锁(共享锁),写锁(排他锁),以及syncronized实现的锁均为悲观锁。
乐观锁的实现:
乐观锁的实现有 CAS机制 与 版本号机制 两种。
版本号机制:用的最多,就是利用mysql实现的,在数据中增加一个字段version,表示该数据的版本号,每当数据被修改,版本号加1。当某个线程查询数据时,将该数据的版本号一起查出来;当该线程更新数据时,判断当前版本号与之前读取的版本号是否一致,如果一致才进行操作。
CAS算法:是一种有名的无锁算法。 无锁编程,即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步。
悲观锁的实现:
悲观锁的实现,往往依靠数据库提供的锁机制。
1.加入当用户A对下单购买商品的时候,先去尝试对该数据加上悲观锁
2.加锁失败:说明商品(臭豆腐)正在被其他事务进行修改,当前查询需要等待或者抛出异常,具体返回的方式需要由开发者根据具体情况去定义
.
.
.
先关闭数据库的自动提交功能,悲观锁加锁sql语句: select num from t_goods where id = 2 for update
15. 分布式,高并发,多线程区别
高并发:指要求系统能同时并行处理很多请求。
分布式:指为解决单个物理服务器容量和性能瓶颈问题而采用的优化手段。【分布式技术就是可以去解决高并发带来的问题】
多线程:指用多个线程并发执行的技术。【解决的是CPU调度多个进程的问题,从而让这些进程看上去是同时执行的(实际是交替执行的)】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号