tesseract图片识别引擎
图片识别引擎
1 tesseract
OCR,即Optical Character Recognition,光学字符识别,是指通过扫描字符,然后通过其形状将其翻译成电子文本的过程。对于图形验证码来说,它们都是一些不规则的字符,这些字符确实是由字符稍加扭曲变换得到的内容。
tesseract下载地址1:https://digi.bib.uni-mannheim.de/tesseract/
tesseract下载地址2: https://github.com/tesseract-ocr/tesseract
Tesseract默认是不支持中文的,语言下载地址:https://github.com/tesseract-ocr/tessdata
2 tesseract安装
2.1 mac环境
执行以下命令进行安装:
brew install --with-training-tools tesseract
2.2 linux环境
执行以下命令进行安装:
sudo apt-get install tesseract-ocr
2.3 windows环境
点击下载地址会进入到下载列表页:
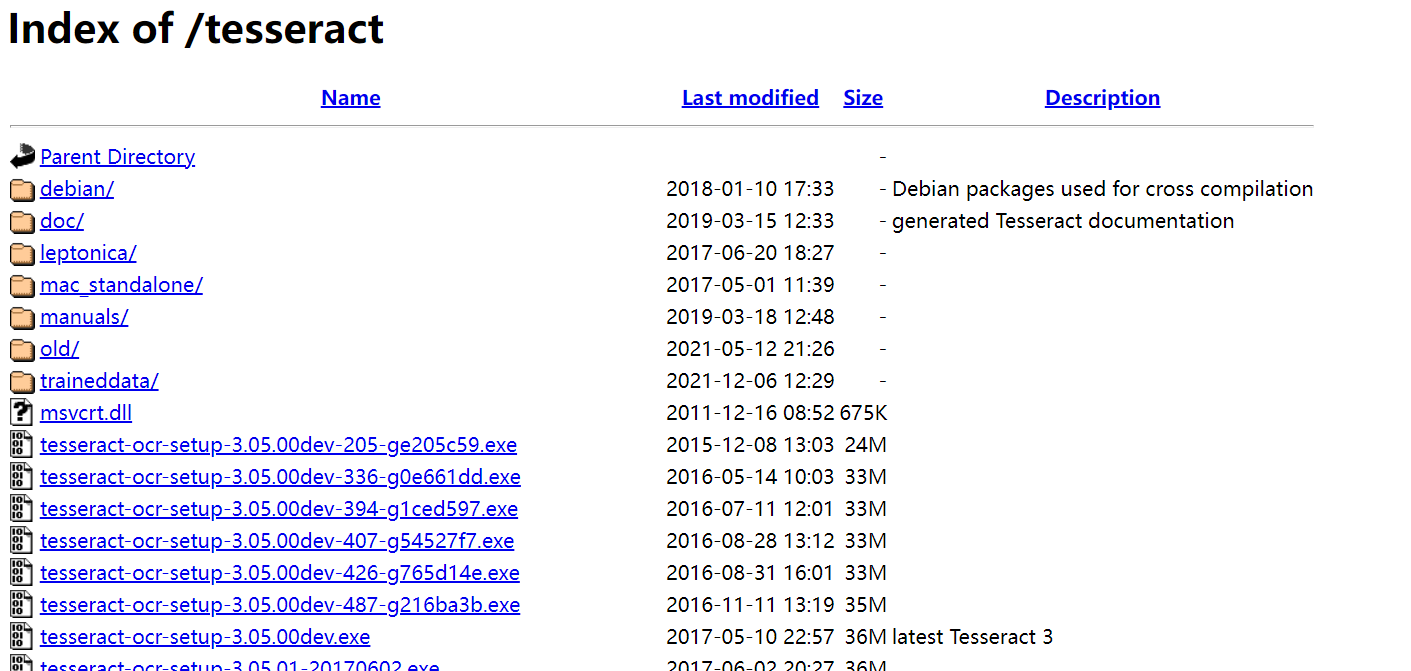
其中文件名中带有dev的为开发版本,不带dev的为稳定版本,可以选择下载不带dev的版本,例如可以选择下载tesseract-ocr-setup-3.05.02.exe。
下载完成后双击如下图:
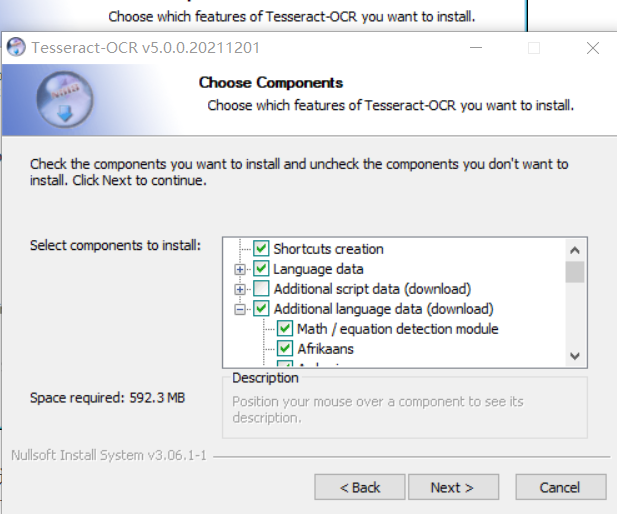
此时可以勾选Additional language data(download)选项来安装OCR识别支持的语言包,这样OCR便可以识别多国语言。然后一路点击Next按钮即可
3 配置tesseract环境变量
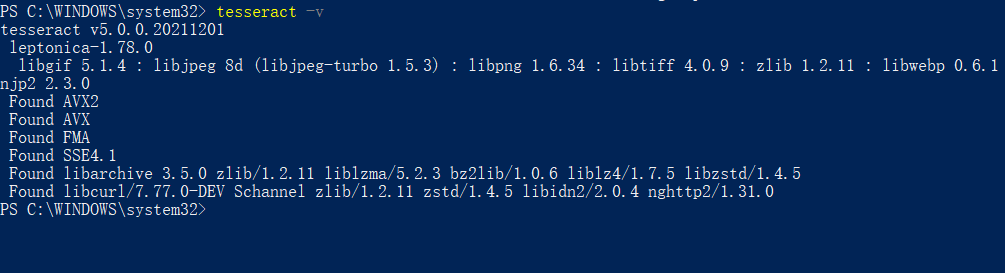
为了在全局使用方便,比如安装路径为D:\software\Tesseract-OCR,将该路径添加到环境变量的path中。
配置完成后在命令行输入tesseract -v,如果出现如下图所示,说明环境变量配置成功
4 python库的安装
pip install Pillow
pip install pytesseract
5 识别图片
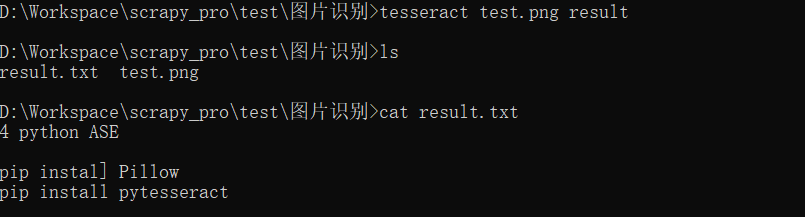
5.1 使用tesseract命令识别图片
- 使用命令:
tesseract imagename outputbaseimagename: 第一个参数为图片名称outputbase: 第二个参数result 为结果保存的目标文件名称
5.2 使用pytesseract库识别图片
然后还可以利用Python代码来测试,这里就需要借助于pytesseract库了,测试代码如下:
from PIL import Image
import pytesseract
text = pytesseract.image_to_string(Image.open(r'./test.png'))
print(text)
我们首先利用Image读取了图片文件,然后调用了pytesseract的image_to_string()方法,再将其识别结果输出。
执行报错解决方法:
报错信息如下图

找到安装的pytesseract.py文件,修改一行代码:
# tesseract_cmd = 'tesseract'
tesseract_cmd = r'D:\software\Tesseract-OCR\tesseract'
修改后保存,再去运行python代码,就可以成功了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号