爬虫数据提取
请求响应数据提取
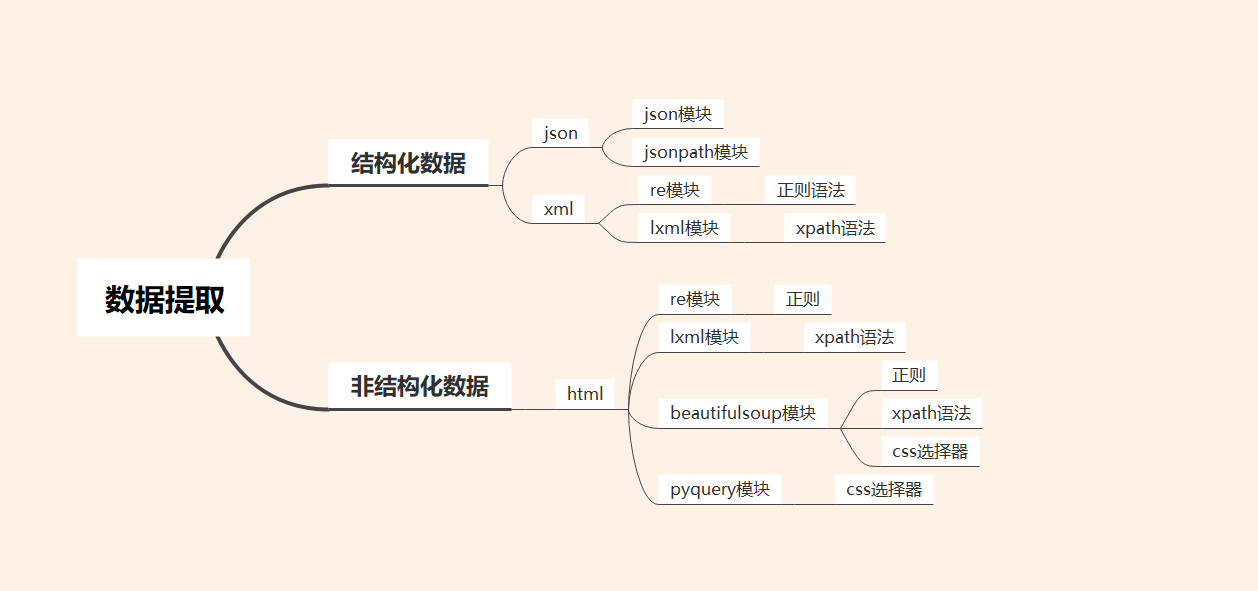
1 响应分类
1.1 结构化数据
1.1.1 json数据
josn格式数据出现比较高频,使用json,re,jsonpath等模块提取数据。
1.1.2 xml数据
xml是一种可扩展标识语言,功能更加专注于存储和传输数据。
xml格式数据低频出现,使用re, lxml等模块提取数据。
1.2 非结构化数据
html是一种超文本标记语言,为了更好的显示数据。
以html格式数据响应返回给浏览器,使用re, lxml等模块提取数据。
2 常用的数据提取方法
2.1 jsonpath模块
jsonpath 是第三方多层嵌套的json数据信息提取库, 可以从json信息文档当提取所需要的数据
2.1.1 安装
$ pip install jsonpath
2.1.2 使用方法
from jsonpath import jsonpath
res=jsonpath.jsonpath(json_dict,'jsonpath语法匹配字符串')
2.1.3 jsonpath语法
| JSONPath | 描述 |
|---|---|
| $ | 跟节点 |
| @ | 现行节点 |
| . or [] | 取子节点 |
| n/a | 就是不管位置,选择所有符合条件的条件 |
| * | 通配符, 匹配满足节点条件的的所用元素(所有的key) |
| .. | 匹配任意节点位置 |
| [] | 迭代器标示(可以在里面做简单的迭代操作,如数组下标,根据内容选值等) |
| [,] | 支持迭代器中做多选 |
| ?() | 支持过滤操作 |
| () | 支持表达式计算 |
示例
常用的语法:
- $ 根节点
- . 子节点
- .. 任意节点
- * 通配符,匹配所有key
from jsonpath import jsonpath
data = {
'key1': {
'key': {
'key': {
'key': {
'class': 'python'
}
}
}
},
'key2': {
'key': {
'key': {
'key': {
'class': 'json'
}
}
}
}
}
# 返回的是列表数据
# 返回根节点下的第一个(子)节点处的所有数据列表
res1 = jsonpath(data, '$.*')
print(res1)
# [{'key': {'key': {'key': {'class': 'python'}}}}, {'key': {'key': {'key': {'class': 'json'}}}}]
# 返回根节点下的第一个(子)节点处的键值='key1'的数据列表
res2 = jsonpath(data, '$.key1')
print(res2)
# [{'key': {'key': {'key': {'class': 'python'}}}}]
# 返回根节点下的第五个(子)节点处的键值='class'的数据列表
res3 = jsonpath(data, '$.key1.key.key.key.class')
print(res3)
# ['python']
# 返回根节点下的任意节点位置的键值='class'的数据列表
res4 = jsonpath(data, '$..class')
print(res4)
# ['python', 'json']
2.2 lxml模块
- XML 指可扩展标记语言(EXtensible Markup Language)
- XML 是一种标记语言,很类似 HTML
- XML 的设计宗旨是传输数据,而非显示数据
- XML 的标签需要我们自行定义。
- XML 被设计为具有自我描述性。
- XML 是 W3C 的推荐标准
2.2.1 安装
$ pip install lxml
2.2.2 xpath语法
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。
下面列出了最常用的路径表达式:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
示例表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position() < 3 ] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=’eng’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| html/node()/meta/@* | 选择html下面任意节点下的meta节点的所有属性 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
XPath的运算符
下面列出了可用在 XPath 表达式中的运算符:

2.2.3 使用
# -*- coding: UTF-8 -*-
from lxml import etree
html = etree.HTML("""
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
""")
result = html.xpath("//li")
for el in result:
print(el.find("a").text)
result = html.xpath("//li/a[@href]/text()")
print(result)
# ['first item', 'second item', 'fourth item', 'fifth item']
result = html.xpath("//a/text()")
print(result)
# ['first item', 'second item', 'fourth item', 'fifth item']
result = html.xpath("//text()")
print(result)
# ['\n ', 'first item', '\n ', 'second item', '\n ',
# 'third item', '\n ', 'fourth item', '\n ', 'fifth item', '\n ', '\n']

 浙公网安备 33010602011771号
浙公网安备 33010602011771号