
基于API+MQ消息双链路数据同步中间件技术方案
一、数据同步的背景及意义
随着公司业务的发展,业务系统也会变得越来越复杂繁多,业务数据或分散、或冗余于各个业务系统中,增加了数据的管理难度和维护成本。因此,中心化存储业务数据显得尤为重要,通过这种方式可以大大减少冗余数据,并能对数据进行清洗,提高数据质量,后续也便于在此服务基础上拓展更多的业务能力。基于API+MQ消息双链路数据同步中间件(oneId-sync),便是在这样的背景下应运而生(关于数据同步服务,行业内有一些框架例阿里DataX等,可以通过监听binlog等方式进行数据同步,但是对于复杂业务同步逻辑,复杂业务数据类型场景下,以及考虑到今后中心化服务具有更强的业务拓展能力,自己搭建一套数据同步中间件,比框架更有优势),数据同步中间件,屏蔽了业务系统同中心服务的对接细节,提供了通用的数据同步能力,并能通过一系列手段提高数据同步的一致性。
二、数据同步中间件面临的问题?
数据同步中间件,面临的最核心的两个问题:1.如何打通各个业务系统和oneId-sync服务?2.如何保障同步数据一致性保证?
比如说,跨境场景下,国内外应用如何通信?如何保证数据同步到中心服务的一致性?
针对第一个问题,我们设计了基于API+MQ消息的双数据同步链路,对于跨机房的业务系统,可以使用公网api,进行数据同步,同机房的业务系统,可以选择api或者mq消息进行数据同步,这里有几个注意事项:
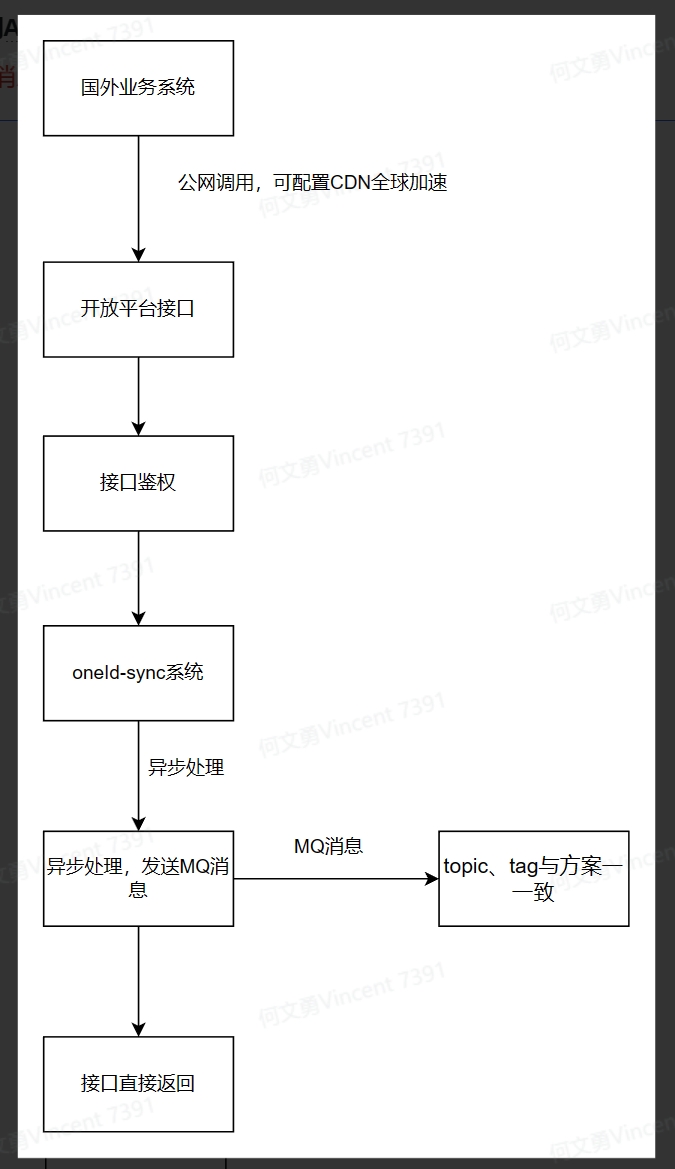
1)跨机房场景下,可以使用公网调用(跨国也行,需要加速),但服务暴露公网,有一定的风险,需要注意鉴权操作;
2)一般,数据同步逻辑都是发生在,业务系统对数据进行增删改操作之后,为了尽可能不影响原有业务逻辑,采用mq消息的方式进行解耦;
3)无法使用mq消息,只能使用api同步时,由于公网调用,一般网络延时较长,所以在中心化oneId-sync服务内,api同步数据,也会转成异步mq消息的方式,处理数据同步逻辑;
对于第二个问题,我们设计了定时任务失败重试+延时对账+多版本数据控制,保障同步数据一致性。
三、数据同步流程图
完整的数据同步链路是:业务系统——》oneId-sync数据同步中间件——》推送多个第三方系统(中心化存储系统)
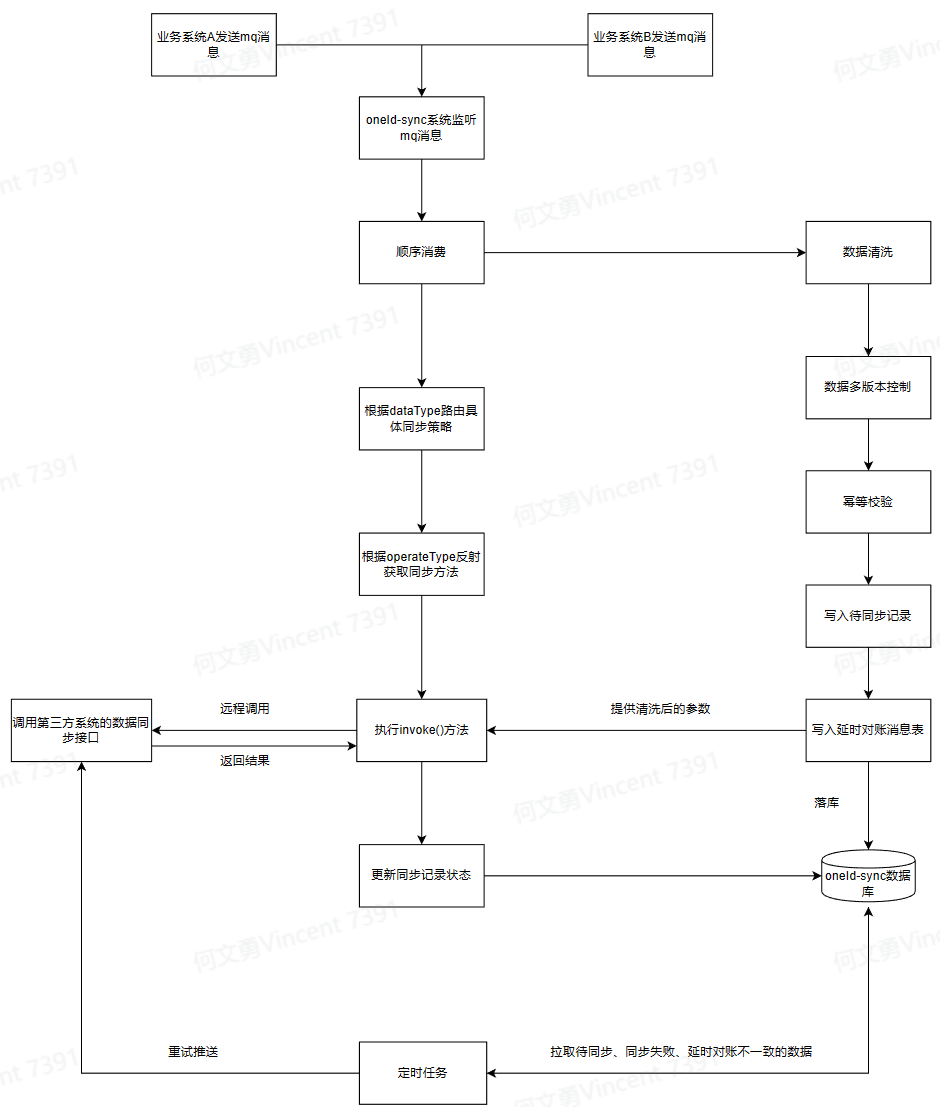
1.基于MQ消息链路数据同步流程图:
2.基于公网api同步链路流程图:
四、关键节点设计
1、设计api+mq消息双数据同步链路,可以方便跨机房/同机房的业务系统,推送数据至oneId-sync中间件;
2、采用MQ顺序消息,保证业务系统对同一数据的多次操作消息有序,避免因为消息乱序,导致脏数据覆盖;
3、MQ消息幂等处理方式,短时间内不允许相同内容数据(例客户数据)多次同步,避免重复提交,并且不允许一次Mq消息重复消费。为此采用了两个幂等设计,一是对消息内容进行MD5加密,作为redis锁的key,短时间内相同内容消息会因为获取不到锁而失败(不重试失败消息);二是将MQ消息key作为唯一索引保存至数据同步记录表中,防止重复消费mq消息;
4.数据一致性保证——定时任务失败重试,对于同步失败的数据,可能是推送中心服务环节异常,因而需要进行重试。数据同步记录表保存了所有的数据同步记录,对于待同步、同步失败、对账不一致的数据,都会定时重试;
5.数据一致性保证——延时对账模块,为了进一步提高同步数据的一致性,采用延时对账的方式,对中心库数据和推送数据进行对账。延时对账可以通过延时消息实现,但考虑结果记录以及实现复杂度、成本等因素,最终考虑延时对账消息表+定时任务扫描方式实现。数据推送中心服务之前,会在本地插入延时对账消息表记录(例30s后进行对账),定时任务扫描延时对账消息表,拉取到期记录,比对同步记录数据与中心服务数据,如果不一致,则修改数据同步状态为对账不一致。
6.数据一致性保证——多版本数据处理,由于引入了定时重试功能,并且业务数据可以多次同步,则很有可能会产生,数据第一次同步失败,但第二次业务修改数据后同步成功,而失败重试定时任务可能会将第一次的业务数据推送中心服务,导致历史数据覆盖掉中心服务的最新数据。为了解决这种case,在消费mq消息时,做了特殊处理,如果同一“客户数据”出现在多个mq消息中,以最新MQ中的数据为准,并将数据库中该客户待同步、同步失败以及对账不一致的数据设置为已失效状态,再生成新的同步记录。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号