
【概率论与数理统计】小结5 - 随机变量的数字特征
https://www.cnblogs.com/Belter/p/7629105.html
注:如果说一个随机变量的分布函数(累计分布或概率密度分布)是对该随机变量最完整,最具体的描述,那么随机变量的数字特征就是对该随机变量的部分特征的描述。分布函数就像是一个人的全身像,而数字特征就像是一个人的局部特写。
0. 为什么要研究随机变量的数字特征
很多情况下,可能由于数据不完整或是采集数据的代价过高,我们只能得到一个随机变量的部分信息而无法得到具体的分布函数。这个时候,我们可以根据有限的数据,利用该随机变量的某些数字特征对其进行局部的研究。这样的研究,虽然无法从根本上解决数据有限的问题,但还是可以让我们对所研究的随机变量有一个概括的认识,了解它的一些基本性质。最常见的数字特征只要包括以下几种:
- 数学期望
- 方差
- 矩
- 协方差和相关系数
前面三个数字特征都是单个随机变量自身的特征,第四个数字特征则用来表示两个随机变量之间的关系。其他数字特征还有中位数,众数等。
1. 数学期望(Mathematical Expectation)
一个随机变量
的数学期望,简称期望,也叫作均值(Mean),记为
。常见随机变量的定义中,都直接或间接包含了“期望”这个参数,该参数一般与分布在坐标轴上的位置有关。期望与我们平时说的平均值差不多,体现的是随机变量中的“大多数”的取值情况或趋势。
在计算时,随机变量
的平均值并不等同于一个具体样本集 的均值 —— 计算一个具体样本集的均值时,是将所有的值求和然后除以样本个数,因为此时的 已经是一个具体的数列,而不再具有随机性 —— 随机变量
的均值 —— 计算一个具体样本集的均值时,是将所有的值求和然后除以样本个数,因为此时的 已经是一个具体的数列,而不再具有随机性 —— 随机变量
的均值是加权平均数。
例如,一个离散型随机变量
的概率质量分布列如下:

图1-1, 概率质量分布函数
那么根据定义,









;如果我们从该随机变量中取1个样本集



 ,那么
,那么

.
此外,正式定义中对期望存在与否给出了明确的判断。在求离散型随机变量的期望时,需要其和式构成的级数是收敛的;在连续型随机变量期望的定义中,也有类似的要求。一个典型的例外,连续型随机变量柯西分布因为不满足此条件,因此不具有均值,具体解释可以参考 Comparing the Cauchy and Gaussian (Normal) density functions 和 Why does the Cauchy distribution have no mean?.
1.1 期望的起源
期望这个名字听起来,并不是那么直白。但是如果知道这个名字的起源,那么就会觉得这个名字是名副其实的。


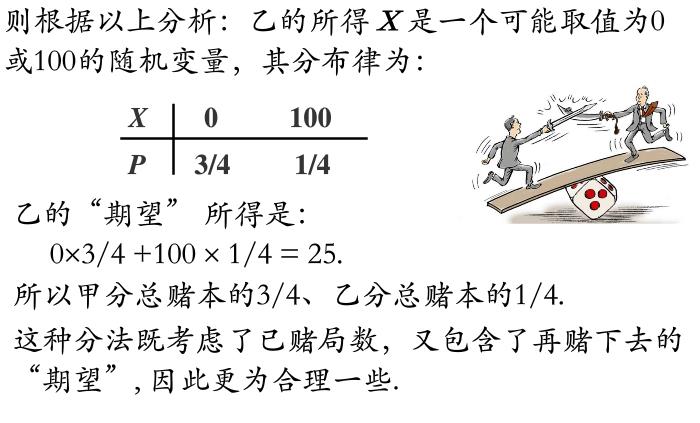
图1-2,“期望”的由来
1.2 数学期望的性质
(1). 设
是常数,则有
;
(2). 设
是一个随机变量,c是常数,则有
;
(3). 设
,  是两个随机变量,则有
是两个随机变量,则有
;
将上面三点结合起来,则有
,可以推广到任意有限个随机变量线性组合的情况;
(4). 设
, 是相互独立的两个随机变量,则有
,可以推广到任意有限个相互独立的随机变量之积的情况。
1.3 常见分布的期望
下面这些分布的期望指的是随机变量的期望,而不是某个随机变量抽样得到的样本集的期望。在离散型随机变量中,数学期望的物理意义是“一维离散质点系的重心坐标”;在连续型随机变量中,数学期望的物理意义是“一维连续质点系的重心坐标”,
- 0-1分布,
![]()


,则
- ;
- 二项分布,
![]()
- ;
- 泊松分布,
![]()

- ;
- 几何分布,
![]()

- ;
- 均匀分布,
![]()

- ;
- 正态分布,
![]()

- ;
- 指数分布,
![]()
- ;
1.4 样本均值的计算
在实际的应用中,我们一般都是已知某个分布的一组样本,需要求这组样本的均值。在计算时,定义中的平均值是算术平均值;还有一种计算平均值的方法是几何平均值,及所有样本值相乘后开N次方,N为样本数。
算术平均值和几何平均值最大的区别在于:如果样本中有
;如果样本中不包括
,通常算术平均值 ≥ 几何平均值。下面是Python实现的方法:

1 import numpy as np
2 from scipy import stats
3 import matplotlib.pyplot as plt
4
5 ## 计算平均值
6 x = np.arange(1, 11)
7 print(x) # [ 1 2 3 4 5 6 7 8 9 10]
8 mean = np.mean(x)
9 print(mean) # 5.5
10
11 # 对空值的处理,nan stands for 'Not-A-Number'
12 x_with_nan = np.hstack((x, np.nan))
13 print(x_with_nan) # [ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. nan]
14 mean2 = np.mean(x_with_nan)
15 print(mean2) # nan,直接计算没有结果
16 mean3 = np.nanmean(x_with_nan)
17 print(mean3) # 5.5
18
19 ## 计算几何平均值
20 x2 = np.arange(1, 11)
21 print(x2) # [ 1 2 3 4 5 6 7 8 9 10]
22 geometric_mean = stats.gmean(x2)
23 print(geometric_mean) # 4.52872868812,几何平均值小于等于算数平均值
2. 方差(Variance)
一个随机变量
取值的波动性,是衡量该随机变量取值分散程度的数字特征。方差越大,就表示该随机变量越分散;方差越小,就表示该随机变量越集中。在实际应用中,例如常见的关于“射击”的例子中,如果一个运动员打靶得分的方差大,就表示该运动员打在靶上的位置比较分散,成绩不稳定;相反则表示打在靶上的位置比较集中,成绩稳定。
定义:设
存在,就称其为的方差,记为
 或
或

,即
将

 ,称为
,称为
的标准差(Standard Deviation)或均方差(Mean Square Error)。
2.1 方差的性质
(1). 设

;
(2). 设
;
特例,
(3). 设
是两个随机变量,则有 ,其中,
,其中,



 . 特别,若, 相互独立,则有
. 特别,若, 相互独立,则有
;
将上面三点结合起来,设
相互独立,a, b, c是常数,则有
,可以推广到任意有限个独立随机变量线性组合的情况;
(4).
;
(5). 当
相互独立时,
.
还有一个常用的计算方差的公式:
2.2 常见分布的方差
- 0-1分布,
![]()
- ;
- 二项分布,
![]()
- ;
- 泊松分布,
![]()
,与
- 相同;
- 几何分布,
![]()
- ;
- 均匀分布,
![]()
- ;
- 正态分布,
![]()
- ;
- 指数分布,
![]()
,
- 的平方;
2.3 样本方差的计算
就像计算均值一样,通常我们计算的都是从某个分布中抽样得到的一组样本的方差,样本方差一般用
表示。按照方差的定义,
,
其中
,等同于使用样本的二阶中心距(矩的概念在下面介绍)。但是样本的二阶中心距并不是随机变量这个总体分布的无偏估计,将上式中的 换成
换成
就得到了样本方差的计算公式,这也是总体方差的无偏估计。
.
从直观上来理解,由于样本方差中多了一个约束条件 —— 样本的均值是固定的,
样本,那么根据均值可以直接计算出第
个样本的值,因此自由度比计算总体方差的时候减小了1个。具体的证明过程可以参考wiki,Sample variance。
下面是如何在Python中计算方差的实现,使用参数ddof(Delta Degrees of Freedom,自由度偏移量)来设置分母的大小。
1 import numpy as np
2
3 # 参考
4 # https://docs.scipy.org/doc/numpy/reference/generated/numpy.std.html
5 # https://docs.scipy.org/doc/numpy/reference/generated/numpy.var.html
6
7
8 data = np.arange(7, 14)
9 print(data) # [ 7 8 9 10 11 12 13]
10
11 ## 计算方差
12 # 直接使用样本二阶中心距计算方差,分母为n
13 var_n = np.var(data) # 默认,ddof=0
14 print(var_n) # 4.0
15 # 使用总体方差的无偏估计计算方差,分母为n-1
16 var_n_1 = np.var(data, ddof=1) # 使用ddof设置自由度的偏移量
17 print(var_n_1) # 4.67
18
19
20 ## 计算标准差
21 std_n = np.std(data, ddof=0)
22 std_n_minus_1 = np.std(data, ddof=1) # 使用ddof设置自由度的偏移量
23 print(std_n, std_n_minus_1) # 2.0, 2.16
24 print(std_n**2, std_n_minus_1**2) # 4.0, 4.67
3. 矩
矩是一个非常广泛的概念,期望和方差都是矩的特例。
定义:若
 为的k阶原点矩,记为
为的k阶原点矩,记为

;
若
为的k阶中心距,记为
根据定义,期望
是2阶中心距。需要注意的是,就像上面提到过的,样本的2阶中心矩并不是总体方差的无偏估计,样本方差的实际计算公式中分母为 ,而不是样本2阶中心距中的
。
符号说明:没有查到专门表示矩的符号(就像用
表示总体均值那样),参考的几个地方用的符号也不一致。 但是一般都用小写希腊字母表示总体矩,用大写字母表示样本矩。我就在这里约定一下,后面都统一使用以下符号。
- 总体k阶原点矩:
![]()
![]()
- ;
- 总体k阶中心矩:
![]()
- ;
- 样本k阶原点矩:
![]()
![]()
- ;
- 样本k阶中心矩:
![]()
![]()

- .
4. 协方差和相关系数
上面几种随机变量的数字特征都是描述单个随机变量局部性质的量,协方差和相关系数则是用来度量两个不同的随机变量之间的相关程度。
4.1 协方差
如上面介绍方差的性质时,第(3)条提到的那样:
设
是两个随机变量,则有,其中,. 特别,若, 相互独立,则有
;
若
相互独立,tail就等于0,那么tail不等于0时,就表示, 这两个随机变量不相互独立。tail就是与
的协方差。
定义:数值
与的协方差,记为


,即
此时,
反映了随机变量与
的线性相关性:
- 当
![]()
与
- 正相关;
- 当
![]()
与
- 负相关;
- 当
![]()
与
- 不相关;
协方差的计算公式可以化简为:
4.2 相关系数
协方差是有量纲的数字特征,为了消除其量纲的影响,引入了相关系数。在平时的数据分析中,协方差很少出现,相关系数出现的频率非常高。
定义:数值



称为随机变量
的相关系数。
相关系数的性质




- );
![]()
![]()
![]()
 . 特别的, 时,
. 特别的, 时,
 ; 时,
; 时,
- .
与协方差相同,相关系数也是用来表征两个随机变量之间线性关系密切程度的特征数,有时也称为“线性相关系数”。
5. 样本均值的期望和方差
设随机变量
,则样本的均值 

 。此时的样本 与样本均值 都是确定的数值,不具有随机性。但是,如果我们取了很多组样本:
。此时的样本 与样本均值 都是确定的数值,不具有随机性。但是,如果我们取了很多组样本: 


 ,那么这些样本的均值 就可以组成一个新的随机变量,可以记为
,那么这些样本的均值 就可以组成一个新的随机变量,可以记为
,每一个样本均值也可以看做是从该随机变量中抽样所得。
样本均值
的函数。根据期望和方差的定义,我们可以求出样本均值的期望和方差。
假设随机变量
和
- ,样本均值的期望与原随机变量的期望相同;
![]()
![]()
![]()


- 的随机性是在获取单组样本时体现出来的(即结果的不确定性),跟组数无关(当每组样本获得之后,数据就不再具有随机性了)。由此可见,每次采样的样本量越多,得到的样本均值的方差也越小也就表示更加准确,但是取样所用的时间和成本也同时增加了。这就需要在准确性和成本之间有一个权衡。
下面用程序做一个测试,测试的是样本均值的标准差随着样本量的变化而发生的变化,如果方差缩小

倍。
1 import numpy as np
2 from scipy import stats
3
4 def mean_and_std_of_sample_mean(ss=[], group_n=100):
5 """
6 不同大小样本均值的均值以及标准差
7 """
8 norm_dis = stats.norm(0, 2) # 定义一个均值为0,标准差为2的正态分布
9 for n in ss:
10 sample_mean = [] # 收集每次取样的样本均值
11 for i in range(group_n):
12 sample = norm_dis.rvs(n) # 取样本量为n的样本
13 sample_mean.append(np.mean(sample)) # 计算该组样本的均值
14 print(np.std(sample_mean), np.mean(sample_mean))
15
16 sample_size = [1, 4, 9, 16, 100] # 每组试验的样本量
17 group_num = 10000
18 mean_and_std_of_sample_mean(ss=sample_size, group_n=group_num)
输出结果:
2.00614271575 -0.00979778829056 0.996748016078 0.0047888141445 0.676831265367 0.00227958796225 0.506174086576 -8.2820165177e-05 0.199323757392 0.000441907648398
上面的测试中,从一个均值为0,标准差为2的正态分布中抽样。便于理解,可以将样本组数看做是参与试验的人数,这里固定为10000;可以将不同的样本量看做是每个人做实验时需要遵守的试验条件,这里的试验条件分别为1, 4, 9, 16, 100,即每次从总体中抽样的个数。整个试验流程是:1万个人都参与了5次不同试验条件的试验,每次做完试验每个人先计算自己所得样本集的均值,然后汇总1万个人的结果计算这10000个值的标准差和均值。
参考上面的输出结果:
第一次试验,每个人从总体中抽取1个样本,标准差近似等于2(只存在少量误差);
第二次试验,每个人从总体中抽取4个样本,标准差近似等于1,减少了
倍,与理论值相同;
第三次试验,每个人从总体中抽取9个样本,标准差近似等于2/3,减少了
倍,与理论值相同;
第四次试验,每个人从总体中抽取16个样本,标准差近似等于1/2,减少了
倍,与理论值相同;
第五次试验,每个人从总体中抽取100个样本,标准差近似等于1/5,减少了
倍,与理论值相同。
改变组数,即参与试验的人数,对试验结果影响不大。
具体的证明过程,可参考Mean and Variance of Sample Mean
欢迎阅读“概率论与数理统计及Python实现”系列文章
Reference
中国大学MOOC:浙江大学&哈工大,概率论与数理统计
http://web.ipac.caltech.edu/staff/fmasci/home/mystats/CauchyVsGaussian.pdf
https://stats.stackexchange.com/questions/36027/why-does-the-cauchy-distribution-have-no-mean
https://en.wikipedia.org/wiki/Bias_of_an_estimator#Sample_variance
https://onlinecourses.science.psu.edu/stat414/node/167

 浙公网安备 33010602011771号
浙公网安备 33010602011771号