IK分词器的安装与使用
分词器
什么是IK分词器?
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,Elasticsearch的标准分词器,会将中文分为一个一个的字,而不是词,比如:“石原美里”会被分为“石”、“原”、“美”、“里”,这显然是不符合要求的,所以我们需要安装中文分词器IK来解决这个问题。
IK提供了两个分词算法:ik_smart和ik_max_word,其中ik_smart为最少切分,ik_max_word为最细力度划分。
安装IK分词器
中文分词插件IK的网址是 https://github.com/medcl/elasticsearch-analysis-ik
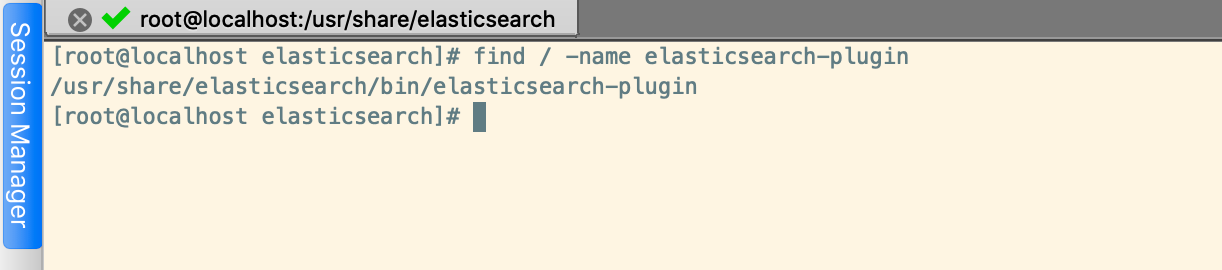
我们可以通过find / -name elasticsearch-plugin命令搜索elasticsearch-plugin在什么地方
安装IK时要注意将github上示例的版本改成自己的elasticsearch版本,我安装的是7.6.2,所以改成如下:
/usr/share/elasticsearch/bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.6.2/elasticsearch-analysis-ik-7.6.2.zip

安装后重启Elasticsearch服务
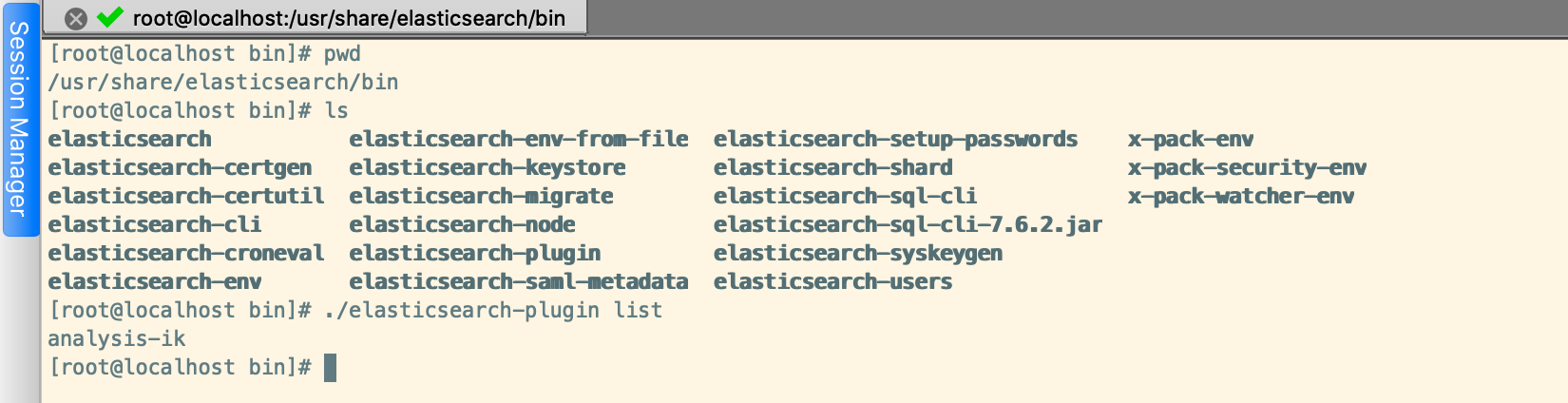
我们可以通过如下命令查看安装的Elasticsearch插件
/usr/share/elasticsearch/bin/elasticsearch-plugin list
使用IK分词器
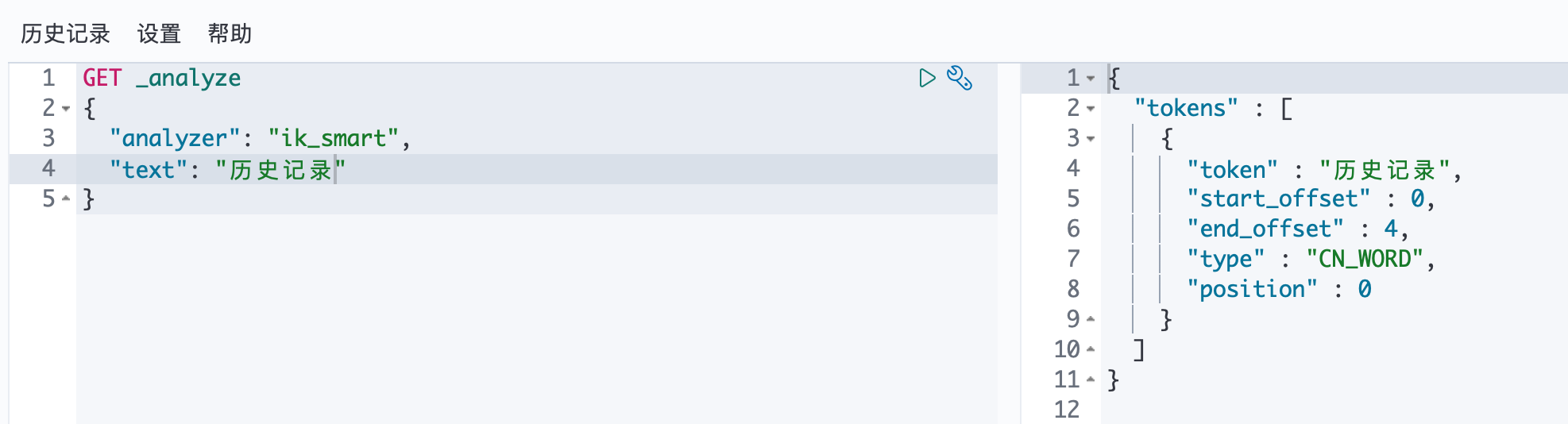
首先我们通过最ik_smart小切分来测试
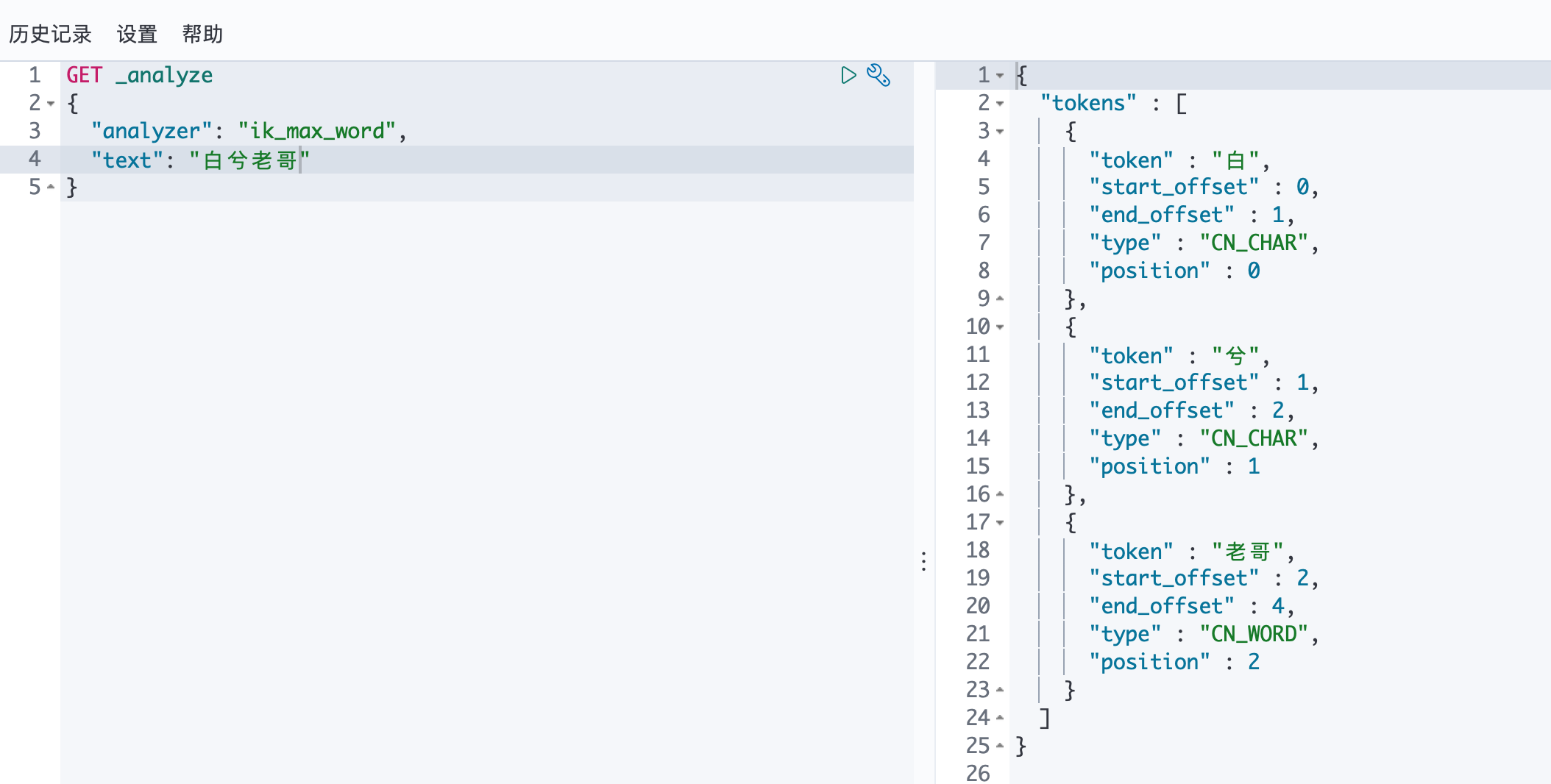
接着,我们通过ik_max_word最细力度切分来测试

但是有些我们自己造的词,分词器是无法识别的(比如:白兮会被识别为两个词:白和兮),这就需要我们自己加到分词器的字典中。
通过RPM方式安装的IK扩展配置文件地址如下
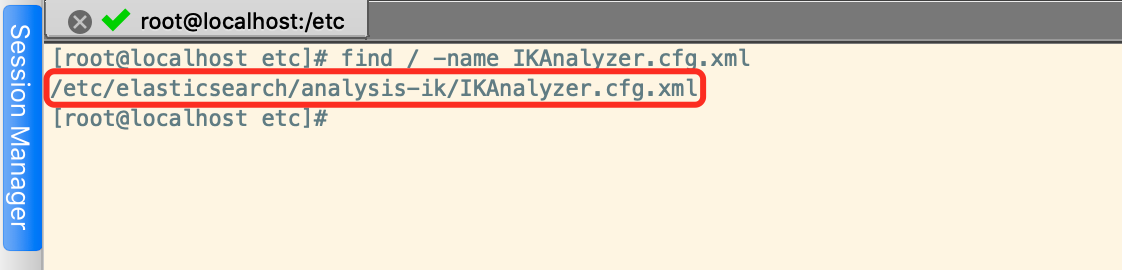
vim /etc/elasticsearch/analysis-ik/IKAnalyzer.cfg.xml
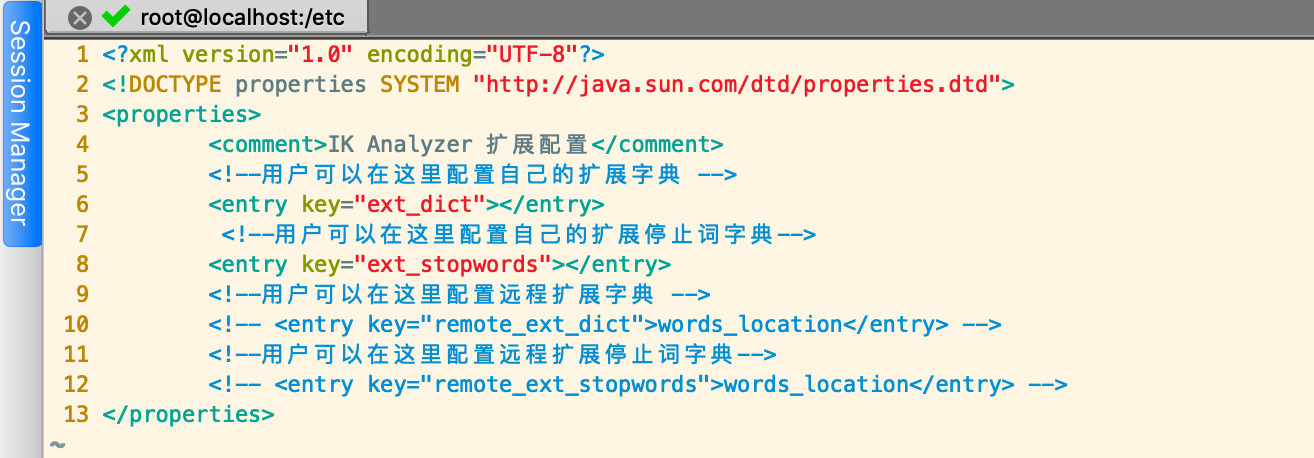
现在我们在/etc/elasticsearch/analysis-ik目录下创建一个自己的词典,例如:my.dic,并在其中添加"白兮"然后保存
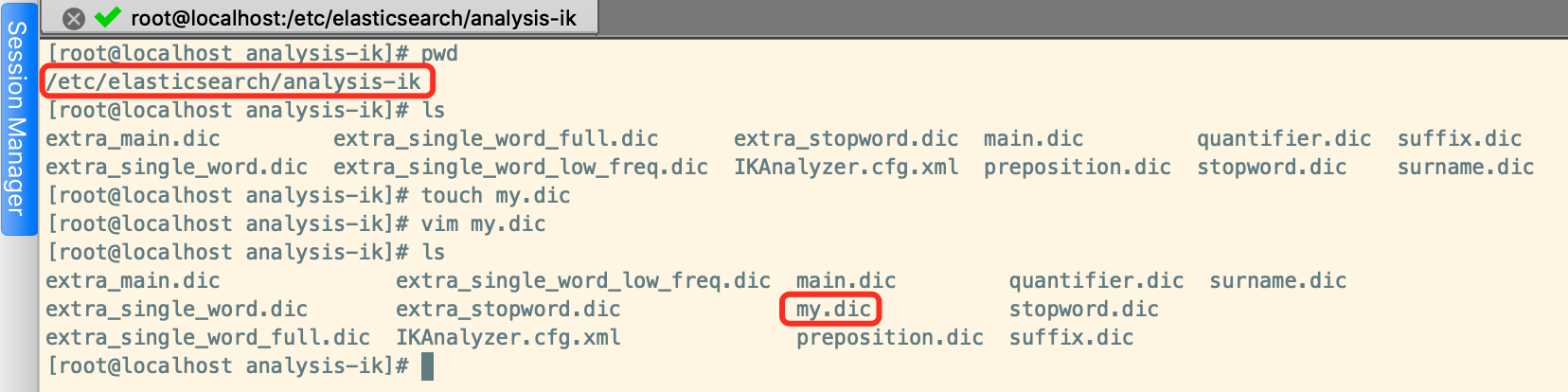
这里要记得将my.dic文件所属的用户和组分别改为root和elasticsearch,防止elasticsearch用户是无法读取该文件的内容的,我们可以看到默认的其它词典都是默认属于root用户和elasticsearch组的,我们把自定义的词典也改成这样
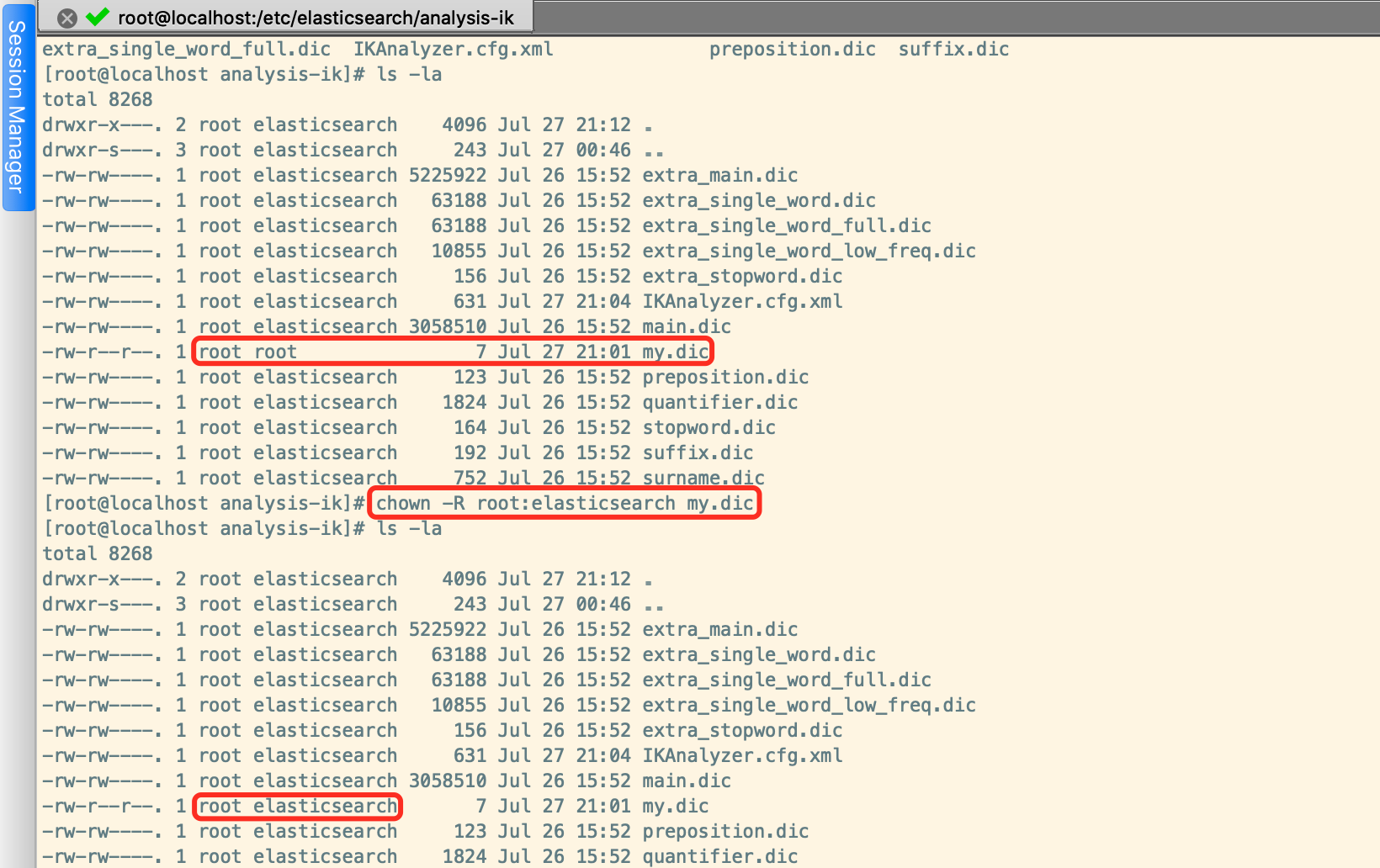
然后将我们新建的my.dic文件增加到IKAnalyzer.cfg.xml配置文件中
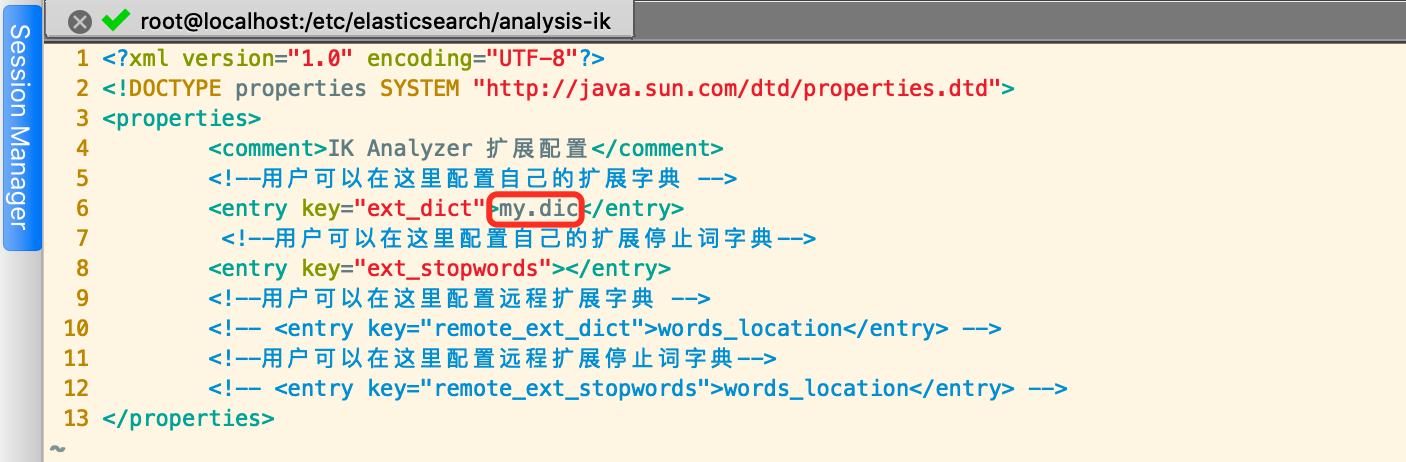
添加后重启Elasticsearch,然后通过kibana再重新测试,可以发现,白兮已经被识别为一个词了。
如果该文章对您有帮助,请您点个推荐,感谢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号