如何选择合适的估算器(estimator)
https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
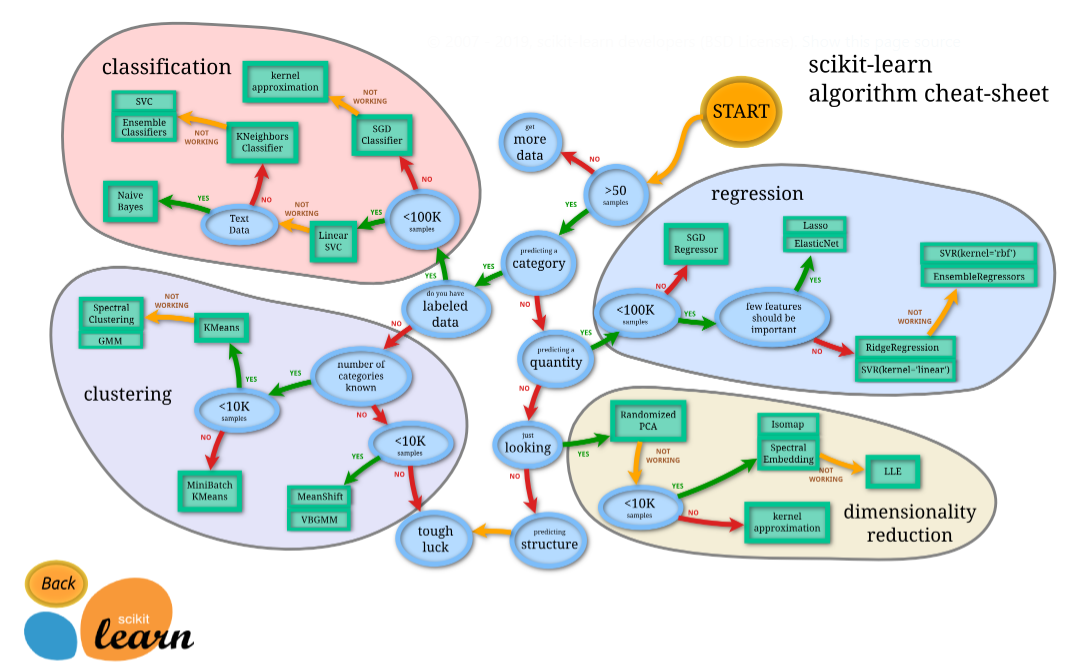
模型跑分,选个高分的:
import pandas as pd from sklearn.preprocessing import LabelEncoder from collections import defaultdict from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier as DTC from sklearn.linear_model import LinearRegression as LR from sklearn.neighbors import KNeighborsClassifier as KNN from sklearn.ensemble import AdaBoostClassifier as ADA from sklearn.ensemble import BaggingClassifier as BC from sklearn.ensemble import GradientBoostingClassifier as GDBC from sklearn.ensemble import RandomForestClassifier as RFC from sklearn.naive_bayes import BernoulliNB as BLNB from sklearn.naive_bayes import GaussianNB as GNB from sklearn.svm import SVC from sklearn.metrics import accuracy_score #获得训练集和测试集 data=pd.read_csv(r'E:\workspaces\python\sklearn\data\loans.csv') X=data.drop('safe_loans',axis=1) y=data.safe_loans d=defaultdict(LabelEncoder) X_trans = X.apply(lambda x: d[x.name].fit_transform(x)) x_train,x_test,y_train,y_test=train_test_split(X_trans,y,test_size=0.2,random_state=1) #训练数据获得得分 def func(clf): clf.fit(x_train, y_train) score = clf.score(x_test, y_test) return score #决策树 print('决策树结果为:{}'.format(func(DTC()))) #线性回归 print('线性回归结果为:{}'.format(func(LR()))) #KNN print('KNN结果为:{}'.format(func(KNN()))) #随机森林 print('随机森林结果为:{}'.format(func(RFC(n_estimators=20)))) #ADAboost print('Adaboost结果为:{}'.format(func(ADA(n_estimators=20)))) #GDBC print('GDBT结果为:{}'.format(func(GDBC(n_estimators=20)))) #Bagging print('Bagging结果为:{}'.format(func(BC(n_estimators=20)))) #伯努利贝叶斯 print('伯努利贝叶斯结果为:{}'.format(func(BLNB()))) #高斯贝叶斯 print('高斯贝叶斯结果为:{}'.format(func(GNB())))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号