算法之除去递增有序单向链表中的重复元素
算法题:
某递增有序单向链表中有重复元素,编写算法去除去重复元素。例如
(7,11,11,15,21,21,27,39)去除重复元素后将变为(7,11,15,21,27,39).叙述算法思想并给出算法实现,分析算法复杂性。
算法思想:
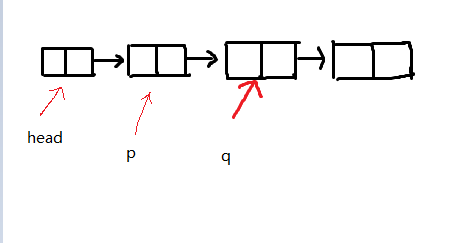
指针p指向单链表中第一个元素即head结点后一个结点,如果p后面存在结点,那么就将指针q指向p后面的结点。然后在判断p和q所指得结点的数据是否相同,如果相同则删除指针指向的元素。(此处不详细解释删除结点的操作)如果不相同则p指针继续向后遍历,直到遍历到p指针后没有结点遍历结束
代码实现:
//删除链表中重复元素 void deleteRepeat(struct Node* headNode){ struct Node* p=headNode->next;//将p指向头结点的下一个结点即第一个元素 struct Node* q;//用于指向p结点后面的结点 struct Node* r;//用于 if(!p) return; else{ while(p->next){//如果 p指针指向结点的下一个结点存在 q=p->next;//将q指向p后面一个元素; if(q->data==p->data){ p->next=q->next; free(q); }else{ p=p->next; } } } }
复杂性分析:
时间复杂度:O(1)
空间复杂度:O(1)
ps:如有错误请指正,谢谢!
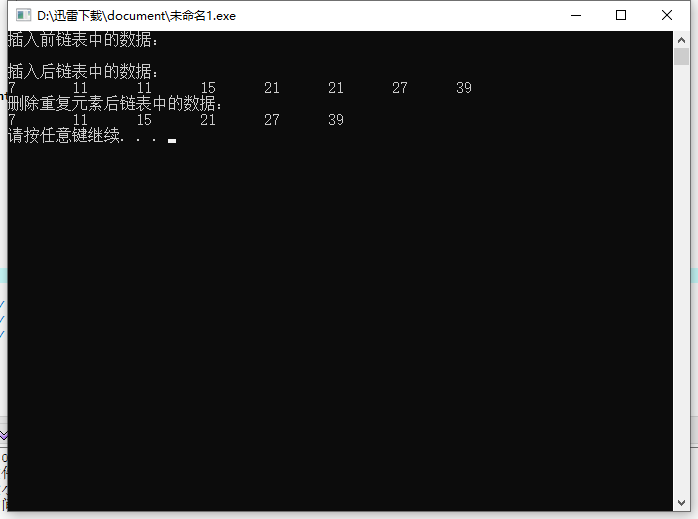
运行结果:
现在的努力只为将来遇见更好的你!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号