关于字符编码和字符集的浅谈
首先介绍一些大家普遍都能理解的概念.
字符集是什么?
英文26个字母组成的字符集被称为英文字符集.
中文汉字组成的字符集被称为中文字符集
这些字符集中的文字或者符号, 放入计算机中, 需要转化成计算机的语言, 也就是二进制. 所以需要进行一个编码的过程. 编码的最大目的是为了传输和存储信息.
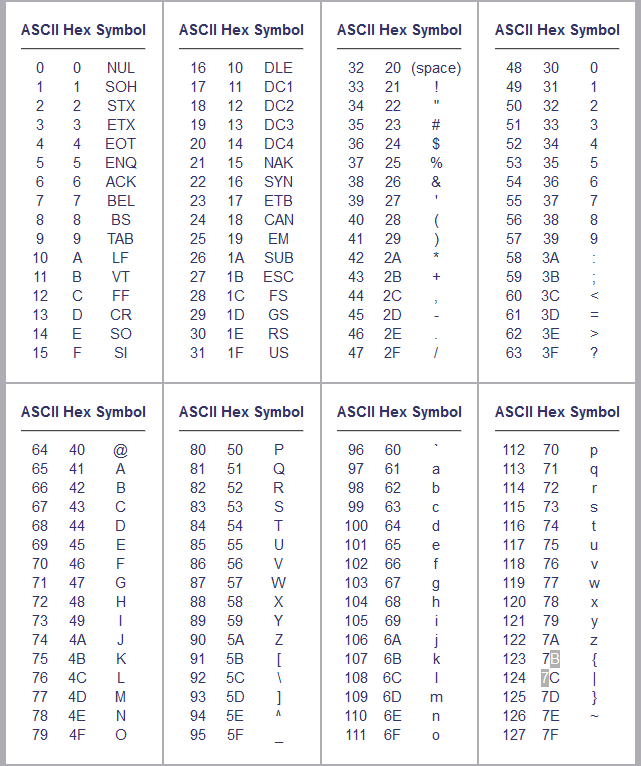
首先计算机要有一个字符库. 确定这些字符足够用. ASCII字符集表示英语. GB23112字符集表示中文
第一层编码, 给每个字符编个数字. 这就是ASCII编码
第二层编码, 确定表示字符的二进制位数(8位, 16位, 32位)
第三层编码, 确定字符二进制值的存储格式.
当我们想再次使用之前保存的这些信息的时候, 只需要使用当时编码的方式进行解码就可以获得当时的信息了.
如果对数据信息进行了错误的解码. 会造成数据无法正确恢复导致丢失信息.
UTF-8格式编码的字节流,按GBK字符集转换为字符串,会出现乱码,这很正常。但将其重新转为字节流,再用UTF-8字符集转为字符串,还是乱码。这就让我产生了疑惑,虽然使用错误的字符集必然导致乱码,但字节的信息并没有改变,因此再转为字节流,用正确的字符集解码,应该得到正常的字符串。但事实是,被错误字符集转换过的字符串,无法恢复到原来的字符集。
原因是由于在解码的时候如果遇到无法解析的字符时候, 会使用特殊字符进行代替. 这样就使得原有的字节信息丢失.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号