Strimzi-Kafka-Operator外围小记
Strimzi-Kafka-Operator
从不同的角度看下Operator解决的问题
Kafka管理Operator-https://github.com/strimzi/strimzi-kafka-operator
部署安装Operator https://strimzi.io/downloads/
部署完成后生成一堆的CRD和一个Controller,基本Operator都是一样套路,strimzi-cluster-operator已具备了对各个CRD的操作监管
接下来就是部署Kafka集群了,当前是只能在内部访问的例子
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
spec:
kafka:
version: 3.4.0
replicas: 2
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: tls
port: 9093
type: internal
tls: true
config:
offsets.topic.replication.factor: 1
transaction.state.log.replication.factor: 1
transaction.state.log.min.isr: 1
default.replication.factor: 1
min.insync.replicas: 1
inter.broker.protocol.version: "3.4"
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 10Gi
class: disk
deleteClaim: true
zookeeper:
replicas: 1
storage:
type: persistent-claim
size: 10Gi
class: disk
deleteClaim: true
entityOperator:
topicOperator: {}
userOperator: {}
创建完之后等一会儿,将会看到zk以及若干的容器、服务被创建
如果需要通过Nodeport访问,listeners修改为以下配置,增加external相关配置
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: tls
port: 9093
type: internal
tls: true
- name: external
port: 9094
type: nodeport
tls: false
configuration:
bootstrap:
nodePort: 32094
可以统一看下各个资源的情况

这里看到已经生成了对应的Nodeport类型的服务
查看创建的Kafka对象状态,可以看到具体的状态信息
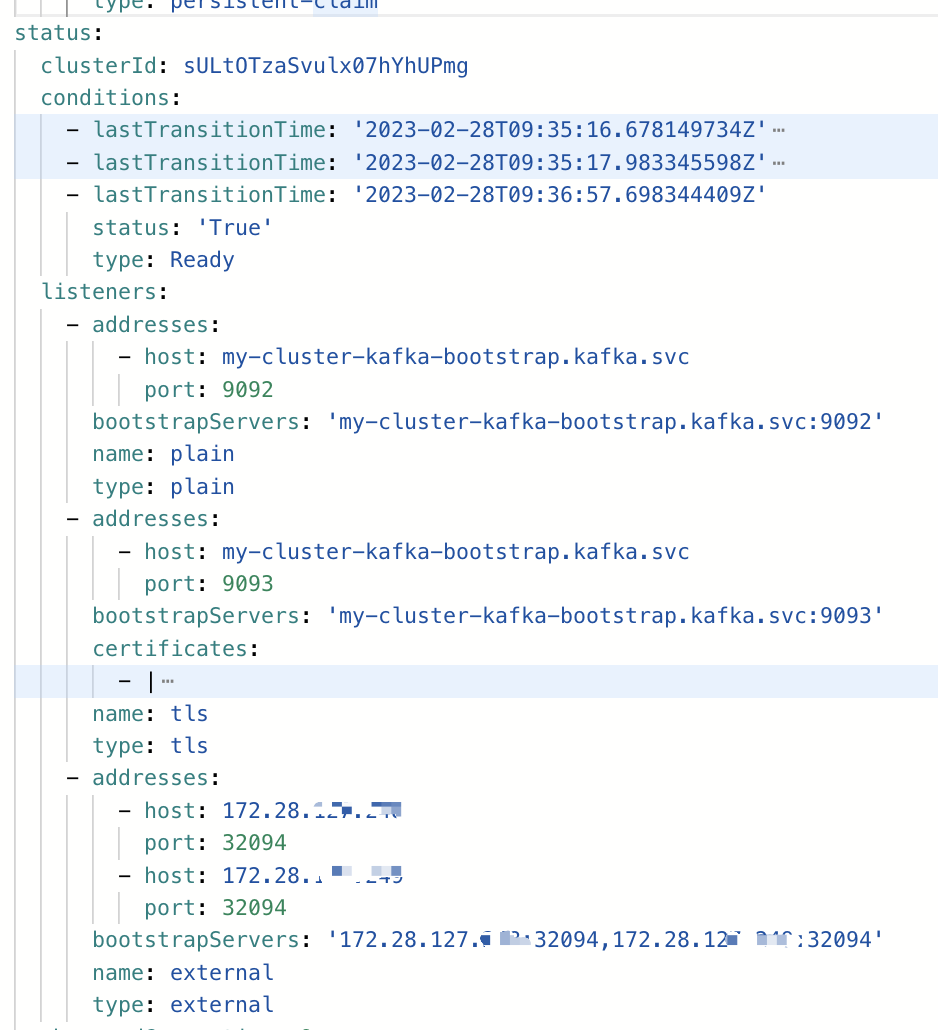
这里可以看到地址列表已经是NodeportIP地址了
如果Nodeport需要制定外部IP
listeners:
- name: plain
port: 9092
tls: false
type: internal
- name: tls
port: 9093
tls: true
type: internal
- configuration:
bootstrap:
nodePort: 32094
brokers:
- advertisedHost: 47.100.168.xxx
broker: 0
name: external
port: 9094
tls: false
type: nodeport
-------
切换到Kafka容器内部看下,cat custom-config/server.config

通过advertised.listeners配置对外开放地址端口,这里Nodeport类型对外开放默认地址就是Nodeip

./bin/kafka-run-class.sh org.apache.zookeeper.ZooKeeperMainWithTlsSupportForKafka -server localhost:12181
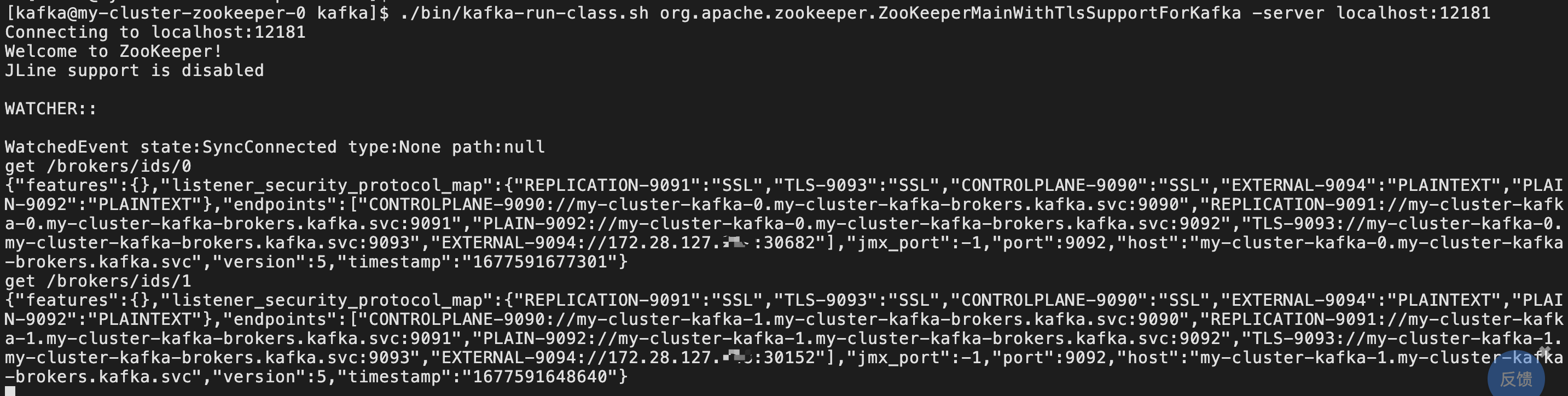
查看zk broker监听,可以看到external
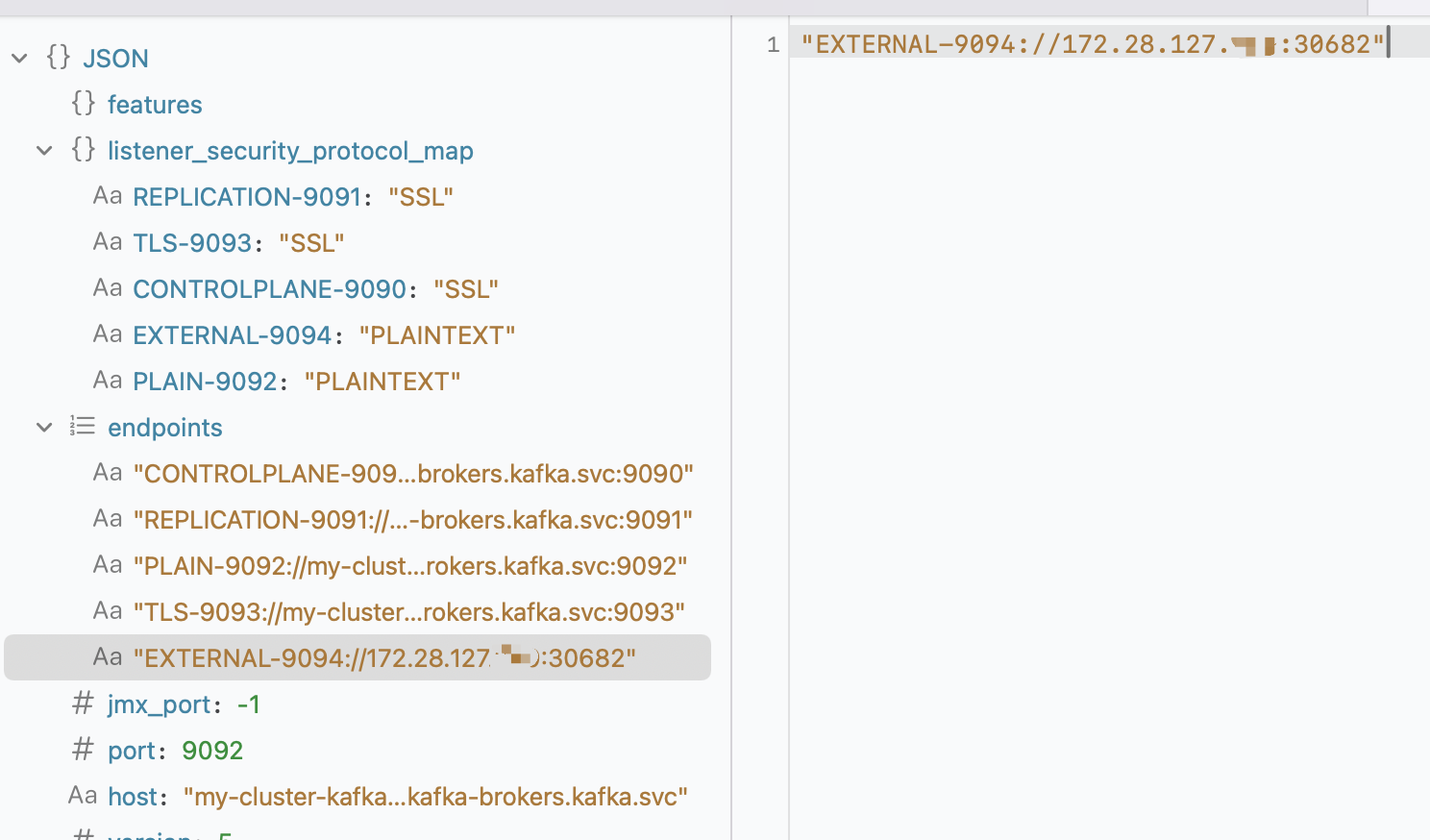
Nodeport访问IP是通过Operator+kafka自身的advertised.listeners实现的,与前文中redis集群逻辑不同,已经从自身解决了podIP外部不可访问的问题
下图参考自:https://blog.csdn.net/weixin_45505313/article/details/122155973#_2,这位网友画的很好
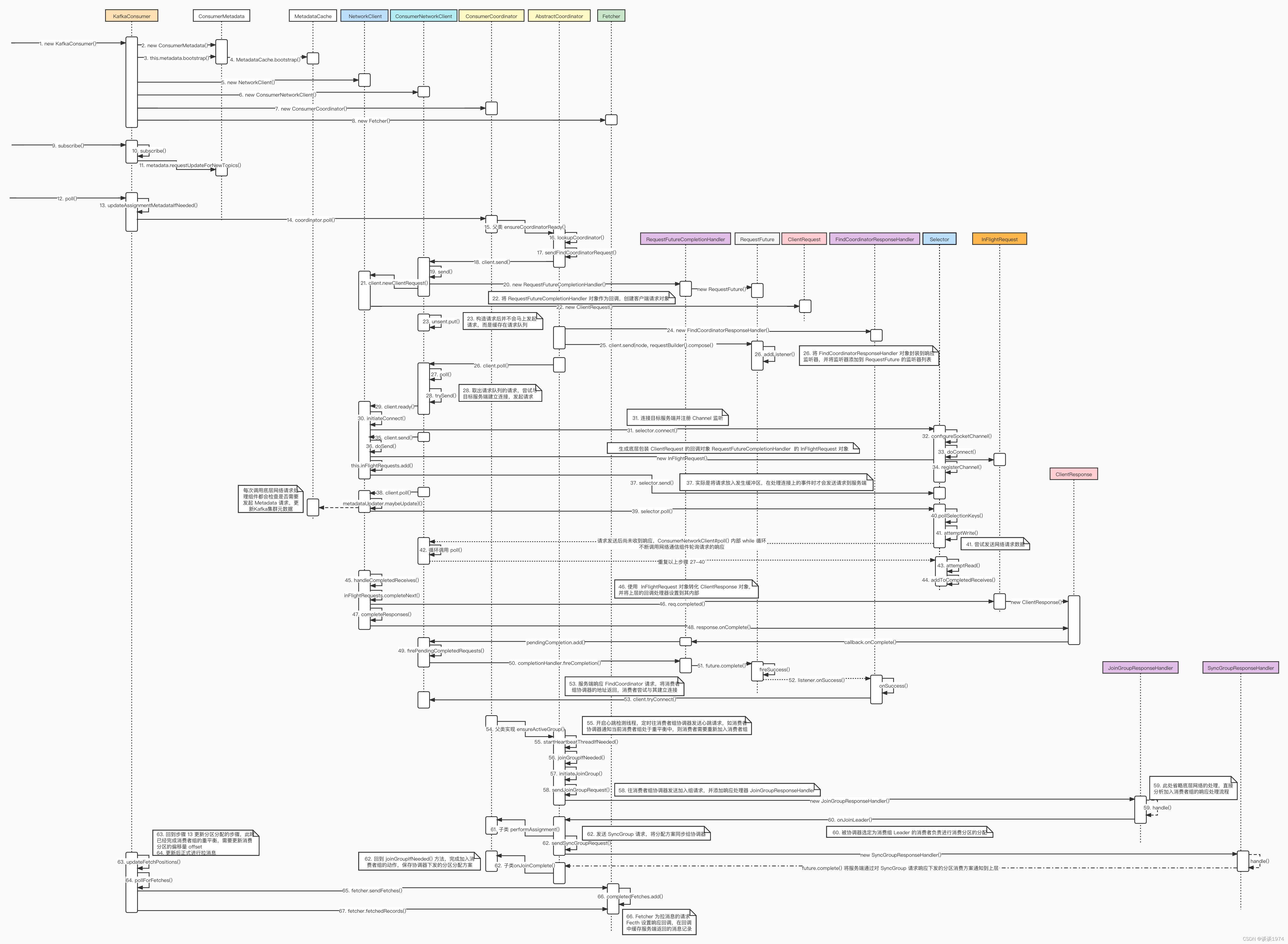
由于要有状态,所以需要先准备云盘,设置默认存储
kubectl patch storageclass alicloud-disk-ssd -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
-----
从Operator的角度,扫一眼代码,与功能相对应,逻辑主要是按包分成三块儿:cluster-operator(管理集群)/topic-operator(管理主题)/user-operator(管理用户)
都有一定的相似性,下面主要看下 cluster-operator(逻辑代码在cluster-operator,部署Yaml在install/cluster-operator)
cluster-operator部署模版在 060-Deployment-strimzi-cluster-operator.yaml 其中指定了启动脚本为cluster_operator_run.sh->launch_java.sh 启动Main
注册CRD,读取配置,启动监控采集相关组件,安装必要组件,启动operator
static { try { Crds.registerCustomKinds(); } catch (Error | RuntimeException t) { t.printStackTrace(); } } /** * The main method used to run the Cluster Operator * * @param args The command line arguments */ public static void main(String[] args) { final String strimziVersion = Main.class.getPackage().getImplementationVersion(); LOGGER.info("ClusterOperator {} is starting", strimziVersion); Util.printEnvInfo(); // Prints configured environment variables ClusterOperatorConfig config = ClusterOperatorConfig.fromMap(System.getenv()); LOGGER.info("Cluster Operator configuration is {}", config); // 启动采集、监控相关组件 KubernetesClient client = new OperatorKubernetesClientBuilder("strimzi-cluster-operator", strimziVersion).build(); maybeCreateClusterRoles(vertx, config, client) .compose(i -> startHealthServer(vertx, metricsProvider)) .compose(i -> leaderElection(client, config)) .compose(i -> createPlatformFeaturesAvailability(vertx, client)) .compose(pfa -> deployClusterOperatorVerticles(vertx, client, metricsProvider, pfa, config)) .onComplete(res -> { if (res.failed()) { LOGGER.error("Unable to start operator for 1 or more namespace", res.cause()); System.exit(1); } }); }
构建Operator,初始化ClusterOperator(extends AbstractVerticle)
/** * Deploys the ClusterOperator verticles responsible for the actual Cluster Operator functionality. One verticle is * started for each namespace the operator watched. In case of watching the whole cluster, only one verticle is started. * * @param vertx Vertx instance * @param client Kubernetes client instance * @param metricsProvider Metrics provider instance * @param pfa PlatformFeaturesAvailability instance describing the Kubernetes cluster * @param config Cluster Operator configuration * * @return Future which completes when all Cluster Operator verticles are started and running */ static CompositeFuture deployClusterOperatorVerticles(Vertx vertx, KubernetesClient client, MetricsProvider metricsProvider, PlatformFeaturesAvailability pfa, ClusterOperatorConfig config) { ResourceOperatorSupplier resourceOperatorSupplier = new ResourceOperatorSupplier( vertx, client, metricsProvider, pfa, config.getOperationTimeoutMs(), config.getOperatorName() ); // Initialize the PodSecurityProvider factory to provide the user configured provider PodSecurityProviderFactory.initialize(config.getPodSecurityProviderClass(), pfa); KafkaAssemblyOperator kafkaClusterOperations = null; KafkaConnectAssemblyOperator kafkaConnectClusterOperations = null; KafkaMirrorMaker2AssemblyOperator kafkaMirrorMaker2AssemblyOperator = null; KafkaMirrorMakerAssemblyOperator kafkaMirrorMakerAssemblyOperator = null; KafkaBridgeAssemblyOperator kafkaBridgeAssemblyOperator = null; KafkaRebalanceAssemblyOperator kafkaRebalanceAssemblyOperator = null; if (!config.isPodSetReconciliationOnly()) { OpenSslCertManager certManager = new OpenSslCertManager(); PasswordGenerator passwordGenerator = new PasswordGenerator(12, "abcdefghijklmnopqrstuvwxyz" + "ABCDEFGHIJKLMNOPQRSTUVWXYZ", "abcdefghijklmnopqrstuvwxyz" + "ABCDEFGHIJKLMNOPQRSTUVWXYZ" + "0123456789"); kafkaClusterOperations = new KafkaAssemblyOperator(vertx, pfa, certManager, passwordGenerator, resourceOperatorSupplier, config); kafkaConnectClusterOperations = new KafkaConnectAssemblyOperator(vertx, pfa, resourceOperatorSupplier, config); kafkaMirrorMaker2AssemblyOperator = new KafkaMirrorMaker2AssemblyOperator(vertx, pfa, resourceOperatorSupplier, config); kafkaMirrorMakerAssemblyOperator = new KafkaMirrorMakerAssemblyOperator(vertx, pfa, certManager, passwordGenerator, resourceOperatorSupplier, config); kafkaBridgeAssemblyOperator = new KafkaBridgeAssemblyOperator(vertx, pfa, certManager, passwordGenerator, resourceOperatorSupplier, config); kafkaRebalanceAssemblyOperator = new KafkaRebalanceAssemblyOperator(vertx, resourceOperatorSupplier, config); } @SuppressWarnings({ "rawtypes" }) List<Future> futures = new ArrayList<>(config.getNamespaces().size()); for (String namespace : config.getNamespaces()) { Promise<String> prom = Promise.promise(); futures.add(prom.future()); ClusterOperator operator = new ClusterOperator(namespace, config, client, kafkaClusterOperations, kafkaConnectClusterOperations, kafkaMirrorMakerAssemblyOperator, kafkaMirrorMaker2AssemblyOperator, kafkaBridgeAssemblyOperator, kafkaRebalanceAssemblyOperator, resourceOperatorSupplier); vertx.deployVerticle(operator, res -> { if (res.succeeded()) { if (config.getCustomResourceSelector() != null) { LOGGER.info("Cluster Operator verticle started in namespace {} with label selector {}", namespace, config.getCustomResourceSelector()); } else { LOGGER.info("Cluster Operator verticle started in namespace {} without label selector", namespace); } } else { LOGGER.error("Cluster Operator verticle in namespace {} failed to start", namespace, res.cause()); } prom.handle(res); }); } return CompositeFuture.join(futures); }
启动Operator
@Override public void start(Promise<Void> start) { LOGGER.info("Starting ClusterOperator for namespace {}", namespace); // Configure the executor here, but it is used only in other places sharedWorkerExecutor = getVertx().createSharedWorkerExecutor("kubernetes-ops-pool", config.getOperationsThreadPoolSize(), TimeUnit.SECONDS.toNanos(120)); @SuppressWarnings({ "rawtypes" }) List<Future> startFutures = new ArrayList<>(8); startFutures.add(maybeStartStrimziPodSetController()); if (!config.isPodSetReconciliationOnly()) { List<AbstractOperator<?, ?, ?, ?>> operators = new ArrayList<>(asList( kafkaAssemblyOperator, kafkaMirrorMakerAssemblyOperator, kafkaConnectAssemblyOperator, kafkaBridgeAssemblyOperator, kafkaMirrorMaker2AssemblyOperator)); for (AbstractOperator<?, ?, ?, ?> operator : operators) { startFutures.add(operator.createWatch(namespace, operator.recreateWatch(namespace)).compose(w -> { LOGGER.info("Opened watch for {} operator", operator.kind()); watchByKind.put(operator.kind(), w); return Future.succeededFuture(); })); } startFutures.add(AbstractConnectOperator.createConnectorWatch(kafkaConnectAssemblyOperator, namespace, config.getCustomResourceSelector())); startFutures.add(kafkaRebalanceAssemblyOperator.createRebalanceWatch(namespace)); } CompositeFuture.join(startFutures) .compose(f -> { LOGGER.info("Setting up periodic reconciliation for namespace {}", namespace); this.reconcileTimer = vertx.setPeriodic(this.config.getReconciliationIntervalMs(), res2 -> { if (!config.isPodSetReconciliationOnly()) { LOGGER.info("Triggering periodic reconciliation for namespace {}", namespace); reconcileAll("timer"); } }); return Future.succeededFuture((Void) null); }) .onComplete(start); }
监听器事件处理逻辑
@Override public void eventReceived(Action action, T resource) { String name = resource.getMetadata().getName(); String namespace = resource.getMetadata().getNamespace(); switch (action) { case ADDED: case DELETED: case MODIFIED: Reconciliation reconciliation = new Reconciliation("watch", operator.kind(), namespace, name); LOGGER.infoCr(reconciliation, "{} {} in namespace {} was {}", operator.kind(), name, namespace, action); operator.reconcile(reconciliation); break; case ERROR: LOGGER.errorCr(new Reconciliation("watch", operator.kind(), namespace, name), "Failed {} {} in namespace{} ", operator.kind(), name, namespace); operator.reconcileAll("watch error", namespace, ignored -> { }); break; default: LOGGER.errorCr(new Reconciliation("watch", operator.kind(), namespace, name), "Unknown action: {} in namespace {}", name, namespace); operator.reconcileAll("watch unknown", namespace, ignored -> { }); } }
定期处理reconcile,如注解描述~
/** Periodical reconciliation (in case we lost some event) */ private void reconcileAll(String trigger) { if (!config.isPodSetReconciliationOnly()) { Handler<AsyncResult<Void>> ignore = ignored -> { }; kafkaAssemblyOperator.reconcileAll(trigger, namespace, ignore); kafkaMirrorMakerAssemblyOperator.reconcileAll(trigger, namespace, ignore); kafkaConnectAssemblyOperator.reconcileAll(trigger, namespace, ignore); kafkaMirrorMaker2AssemblyOperator.reconcileAll(trigger, namespace, ignore); kafkaBridgeAssemblyOperator.reconcileAll(trigger, namespace, ignore); kafkaRebalanceAssemblyOperator.reconcileAll(trigger, namespace, ignore); } }
KafkaAssemblyOperator
/** * Run the reconciliation pipeline for Kafka * * @param clock The clock for supplying the reconciler with the time instant of each reconciliation cycle. * That time is used for checking maintenance windows * * @return Future with Reconciliation State */ Future<ReconciliationState> reconcileKafka(Clock clock) { return kafkaReconciler() .compose(reconciler -> reconciler.reconcile(kafkaStatus, clock)) .map(this); }
执行流
/** * The main reconciliation method which triggers the whole reconciliation pipeline. This is the method which is * expected to be called from the outside to trigger the reconciliation. * * @param kafkaStatus The Kafka Status class for adding conditions to it during the reconciliation * @param clock The clock for supplying the reconciler with the time instant of each reconciliation cycle. * That time is used for checking maintenance windows * * @return Future which completes when the reconciliation completes */ public Future<Void> reconcile(KafkaStatus kafkaStatus, Clock clock) { return modelWarnings(kafkaStatus) .compose(i -> manualPodCleaning()) .compose(i -> networkPolicy()) .compose(i -> manualRollingUpdate()) .compose(i -> pvcs()) .compose(i -> serviceAccount()) .compose(i -> initClusterRoleBinding()) .compose(i -> scaleDown()) .compose(i -> listeners()) .compose(i -> certificateSecret(clock)) .compose(i -> brokerConfigurationConfigMaps()) .compose(i -> jmxSecret()) .compose(i -> podDisruptionBudget()) .compose(i -> podDisruptionBudgetV1Beta1()) .compose(i -> migrateFromStatefulSetToPodSet()) .compose(i -> migrateFromPodSetToStatefulSet()) .compose(i -> statefulSet()) .compose(i -> podSet()) .compose(i -> rollToAddOrRemoveVolumes()) .compose(i -> rollingUpdate()) .compose(i -> scaleUp()) .compose(i -> podsReady()) .compose(i -> serviceEndpointsReady()) .compose(i -> headlessServiceEndpointsReady()) .compose(i -> clusterId(kafkaStatus)) .compose(i -> deletePersistentClaims()) .compose(i -> brokerConfigurationConfigMapsCleanup()) // This has to run after all possible rolling updates which might move the pods to different nodes .compose(i -> nodePortExternalListenerStatus()) .compose(i -> addListenersToKafkaStatus(kafkaStatus)); }
具体进去就是各种状态判断,协调最终一致
其中配置生成在KafkaBrokerConfigurationBuilder里
根据CR内容生成对应的配置文件;
在Reconcile后更新CR状态信息
/** * Updates the Status field of the Kafka CR. It diffs the desired status against the current status and calls * the update only when there is any difference in non-timestamp fields. * * @param desiredStatus The KafkaStatus which should be set * * @return Future which completes when the status subresource is updated */ Future<Void> updateStatus(KafkaStatus desiredStatus) { Promise<Void> updateStatusPromise = Promise.promise(); crdOperator.getAsync(namespace, name).onComplete(getRes -> { if (getRes.succeeded()) { Kafka kafka = getRes.result(); if (kafka != null) { if ((Constants.RESOURCE_GROUP_NAME + "/" + Constants.V1ALPHA1).equals(kafka.getApiVersion())) { LOGGER.warnCr(reconciliation, "The resource needs to be upgraded from version {} to 'v1beta1' to use the status field", kafka.getApiVersion()); updateStatusPromise.complete(); } else { KafkaStatus currentStatus = kafka.getStatus(); StatusDiff ksDiff = new StatusDiff(currentStatus, desiredStatus); if (!ksDiff.isEmpty()) { Kafka resourceWithNewStatus = new KafkaBuilder(kafka).withStatus(desiredStatus).build(); crdOperator.updateStatusAsync(reconciliation, resourceWithNewStatus).onComplete(updateRes -> { if (updateRes.succeeded()) { LOGGER.debugCr(reconciliation, "Completed status update"); updateStatusPromise.complete(); } else { LOGGER.errorCr(reconciliation, "Failed to update status", updateRes.cause()); updateStatusPromise.fail(updateRes.cause()); } }); } else { LOGGER.debugCr(reconciliation, "Status did not change"); updateStatusPromise.complete(); } } } else { LOGGER.errorCr(reconciliation, "Current Kafka resource not found"); updateStatusPromise.fail("Current Kafka resource not found"); } } else { LOGGER.errorCr(reconciliation, "Failed to get the current Kafka resource and its status", getRes.cause()); updateStatusPromise.fail(getRes.cause()); } }); return updateStatusPromise.future(); }
其他好文
http://www.javajun.net/posts/55588/
https://blog.csdn.net/weixin_39766667/article/details/128177436
https://blog.csdn.net/prefect_start/article/details/124183531

 浙公网安备 33010602011771号
浙公网安备 33010602011771号