
Spring Cloud Data Flow系列教程简介-1
简介
前言
-
Spring Cloud data flow 为基于微服务的分布式流处理和批处理数据通道提供了一系列模型和最佳实践。
-
Spring Cloud Data Flow 提供了为流和批处理数据管道创建复杂拓扑的工具。数据管道由使用Spring Cloud Stream或Spring Cloud Task微服务框架构建的Spring Boot应用程序组成。
-
Spring Cloud Data Flow 支持一系列数据处理用例,从 ETL 到导入/导出、事件流和预测分析。
基本概念
数据处理模式
数据处理有两种模式,分别是Streaming流式处理和Batch批次处理。Streaming是长时间一直存在的,你数据来了我就处理,没来我就等着,基于消息驱动。Batch是处理时间较短的,启动一次处理一次,处理完就退出任务,需要去触发任务。
一般地,我们会基于Spring Cloud Stream框架来开发Streaming应用,而基于Spring Cloud Task或Spring Batch框架来开发Batch应用。完成开发后,可以打包成两种形式:
- (1)
Springboot式的jar包,可以放在maven仓库、文件目录或HTTP服务上; - (2)
Docker镜像。
对于Stream,有三个概念是需要理解的:
- (1)
Source:消息生产者,负责把消息发送到某个目标; - (2)
Sink:消息消费者,负责从某个目标读取消息; - (3)
Processor:联合Source和Sink,它从某个目标消费消息,然后发送到另一个目标。
特性
Spring Cloud Data Flow有许多好的特性值得我们学去使用它:
- 基于云的架构,可部署在
Cloud Foundry、Kubernetes或OpenShift等。 - 有许多可选择的开箱即用的流处理和批处理应用组件。
- 可自定义应用组件,且是基于
Springboot风格的编程模型。 - 有简单灵活的
DSL(Domain Specific Language)去定义任务处理逻辑。 - 有美观的
Dashboard能可视化地定义处理逻辑、管理应用、管理任务等。 - 提供了
REST API,可以在shell命令行模式下进行交互。
服务端组件
服务端有两个重要的组件:Data Flow Server和Skipper Server。两者作用不同,互相协作。
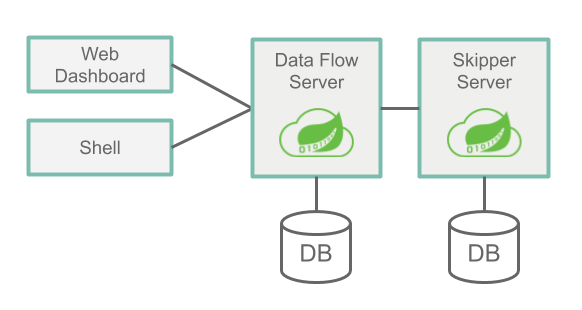
Data Flow Server的主要作用有:
- 解析
DSL; - 校验和持久化
Stream、Task和Batch的定义; - 注册应用如
jar包应用和docker应用; - 部署
Batch到一个或多个平台; - 查询
Job和Batch的历史执行记录; Stream的配置管理;- 分发
Stream部署到Skipper。
Skipper Server主要作用有:
- 部署
Stream到一个或多个平台; - 基于有灰度/绿色更新策略地更新或回滚
Stream; - 保存每一个
Stream的描述信息。
可以看出,如果不需要使用Stream,可以不用部署Skipper。两者都需要依赖关系型数据库(RDBMS),默认会使用内置的H2,支持的数据库有H2、HSQLDB、MYSQL、Oracle、PostgreSql、DB2和SqlServer。
运行环境
优秀的Spring的解耦能力总是特别强,Server和应用可以运行在不同的平台。我们可以把Data Flow Server和Skipper Server部署在Local、Cloud Foundry和Kuernetes,而Server又可以把应用部署在不同的平台。
- 服务端Local:应用Local/Cloud Foundry/Kuernetes;
- 服务端Cloud Foundry:应用Cloud Foundry/Kuernetes;
- 服务端Kuernetes:应用Cloud Foundry/Kuernetes。
一般情况下,我们会把Server和应用部署在同一平台上。对于生产环境,建议还是在Kuernetes上比较合适。
总结
本文使用的是官方提供的应用,我们可以自己开发应用并注册到Server上。Local模式适合开发环境适合,生产环境还是部署在Kubernetes比较靠谱
对比
Spring Cloud Data Flow更加倾向于传统ETL 数据处理的data pipeline设计,但是传统ETL数据处理有大量的现成的工具可用,可以拖拉拽的,可以跟数据库无缝连接,管理,运维等等。Spring Cloud Data Flow这种高代码实现工具显得不是好用。如果涉及到大数据处理,有很多其他工具可用入flink,spark,flume等等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号