实验设计 | Gem5 模拟器
Gem5 体系结构实验设计

By. Miya | 2024
前言
笔者在学习 Gem5 时,苦于没有适合的入门教材,后担任体系结构课程助教,设计了此实验。整理于此,供参考交流。
环境搭建
实验平台
- Windows 11
- Docker Desktop
- Gem5 Ubuntu 24.04_all_dependencies 镜像
推荐使用 Docker 进行实验,基础镜像为 Ubuntu 24.04,并带 gem5 编译所需全部依赖。
配置
请参考 gem5 官方手册[1]进行下载编译。
拉取镜像
docker pull ghcr.io/gem5/ubuntu-24.04_all-dependencies:latest@sha256:9059624b21b7c6fef297ed60f3eb323047bb217ac5165d306f6a2aca8072782e
下载 gem5 源码
git clone https://github.com/gem5/gem5
挂载 gem5 目录并启动镜像
docker run
--volume <GEM5_PATH>:/gem5
-it
--name mygem5
ghcr.io/gem5/ubuntu-24.04_all-dependencies
编译 gem5
cd /gem5 && scons build/X86/gem5.opt
实验背景与目的
Gem5 模拟器
计算机体系结构课程实验教学中,常常采用 RTL 代码编写+计算机硬件实验平台、实验箱、开发板验证方式,了解体系结构知识。然而,硬件平台验证困难,RTL 代码编写速度慢、调试成本高,同学在有限时间内无法对体系结构建立完整的概念。
Gem5 模拟器是一款体系结构模拟器,有着高度可配置、集成多种指令集和多种 CPU 模型的特点。它是集 M5 模拟器和 GEMS 模拟器中最优秀的部分而形成的。其中,GEMS 是密歇根大学开发的模拟器,主要用于多种指令集和多种 CPU 模型的模拟;M5 模拟器由威斯康星大学开发,能够灵活、详细地模拟存储器的层次结构,包括缓存一致性协议和片上网络等。
通过使用模拟器,可以规避繁琐的实现细节,而快速高效地建立体系结构的量化设计概念。通过 Gem5 模拟器进行实验设计,可在相同的实验课时内设计更加复杂的实验,并能够快速探索设计空间,为体系结构方向的进一步深造打下基础。
Gem5 优势
Gem5 支持多种 ISA,可选择合适架构设计实验。在 Alpha、ARM、SPARC 和 X86 上,可进行全系统模拟。Gem5 还可以加载操作系统,具备模拟乱序执行、分支预测等现代微架构的能力,支持 classic 和 Ruby 存储模型,支持 AtomicSimple、Timing Simple、InOrder 和 O3 CPU 等多种处理器模型。同时,Gem5 的源代码遵循 BSD 开源协议,便于设计与分发实验。
本实验基于 X86 ISA,并主要基于 two_level 脚本运行测试负载。
BPU 实验概述
BiMode[2] 预测器模型直接继承自 BranchPredictor 类,带跳转预测、方向预测两个基本的预测单元和一个选择预测器。基本 BiMode 预测器使用一个预测位作为 Choice。
请仿照 BiModeBP 实现一个 MyBP 预测器模型,是微调 BiMode 预测器得到。并练习完成一个完整的 Gem5 SimObject 实现,在该过程中加深对 Predictor 和 Gem5 的理解。同时,通过分析 Gem5 输出,建立基本的量化设计概念。
Cache 实验概述
缓存是 Mem 性能优化的重要一环。通过实验,可以理解并评估不同缓存策略对系统性能的影响,针对负载找出最优配置,提高数据访问速度。
可通过命令行参数直接配置 gem5 的缓存架构。通过尝试不同的缓存配置(如相联度等),加深对 CPU Cache 理解。
与传统实验对比
传统缓存实验基于 RTL 代码进行,设计时间长,且产物相对简单。以 Cache 实验为例,受限于硬件平台资源,大多只能设计 L1 Cache,对负载的运行性能优化失真。
本实验可与 RTL Cache 实验形成搭配。Gem5 实验帮助建立缓存体系结构的整体概念;通过简单的参数配置,可快速获得不同缓存配置下的性能参数,进而可进行数据分析等。
BPU 实验流程
熟悉 BranchPredictor.py
Gem5 SimObject 分为三部分。
- Scons 描述
- Python 描述
- C++ 实现
首先仿照 BiMode,编写 MyBP(在 BiMode 基础上微调)的 Python 描述。文件路径为 /gem5/src/cpu/pred/BranchPredictor.py,在其中添加:
Class MyBP(BranchPredictor):
# 实验目的:微调 BiMode 得到 MyBP,使用饱和计数器代替预测位,过滤分支波动。
# 请复制以下内容
type = "MyBP"
cxx_class = "gem5::branch_prediction::MyBP"
cxx_header = "cpu/pred/my_bp.hh"
# 以下内容仿照 Class BiModeBP,但请修改多种 choiceCtrBits 配置 (红字部分),尝试不同深度的饱和计数器。
globalPredictorSize = Param.Unsigned(8192, "Size of global predictor")
globalCtrBits = Param.Unsigned(2, "Bits per counter")
choicePredictorSize = Param.Unsigned(8192, "Size of choice predictor")
choiceCtrBits = Param.Unsigned(3, "Bits of choice counters")
然后添加 C++ 实现和头文件实现,请取附件中的 my_bp.cc 和 my_bp.hh,放置在 /gem5/src/cpu/pred/ 目录下。
最后进行 Scons 描述。文件路径为 /gem5/src/cpu/pred/SConscript,在其中添加:
SimObject(BranchPredictor.py, sim_objects=[
...
+ ‘MyBP’
])
...
+ # 并在末尾添加
+ Source(‘my_bp.cc’)
+ DebugFlag(‘MyBP’)
入口脚本
在 ./configs/learning_gem5/part1/ 新建 run_mybp.py,其内容可复制自同一目录下的 two_level.py,为了带前一节实现的预测器运行,做如下修改:
- System.cpu = X86TimingSimpleCPU()
+ System.cpu = DerivO3CPU( branchPred=MyBP() )
Benchmark 见实验附件,请新建目录 ./benchmarks/ 并放置其中。在 1.2 中,学习了 gem5.opt 的编译。现在由于文件改动,请重新编译,然后方可运行 run_mybp 脚本。
进 Benchmark 目录并编译测试集,然后回上级目录
gcc ./spectre.c -o ./spectre
Gem5,启动
./build/X86/gem5.opt ./configs/learning_gem5/part1/run_mybp.py ./benchmarks/spectre
见到如下输出即为运行成功:
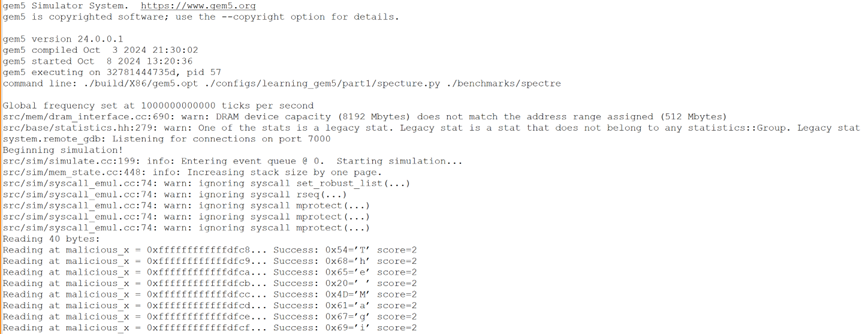
Cache 实验流程
带 Cache 运行 gem5
使用 ./configs/learning_gem5/part1/two_level.py 作为入口脚本,并统一修改 TimingSimpleCPU 模型为 O3CPU 模型(即 system.cpu = DerivO3CPU(),参考 3.2)
为了配置缓存,请在同级目录下的 caches.py 中进行配置,通过修改模型类的属性(如 L2Cache 类的 size 属性)即可完成配置。运行时这些配置(包括 L1i,L1d,L2 等)将自动生效。caches.py 默认为 256kB + 8-way.
./build/X86/gem5.opt ./configs/learning_gem5/part1/two_level.py ./benchmarks/spectre
Gem5 内容补充
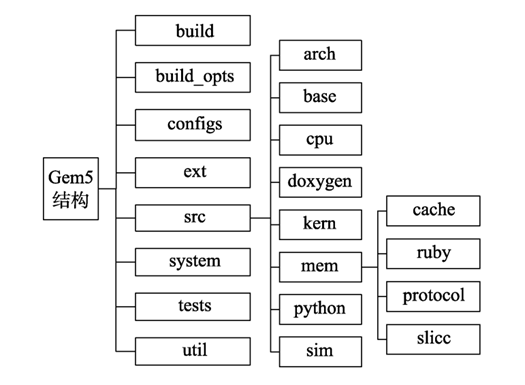
Gem5 的补充知识点可关注下图。
其中
- build_opts 定义了 ARM、X86 和 RISC-V 等体系结构的默认设置,无需关心。
- configs 包含一系类模拟器配置脚本文件,主要用 Python 编写,是修改模拟器配置文件参数的关键部分。
- src 是 Gem5 源代码的关键部分,包含体系结构各部分的详细代码。
- system 描述模拟系统的固件和引导信息。
实验说明
数据分析
Stats.txt 是 Gem5 的输出文件,位于 ./m5out/ 目录,通过分析该文件可以获得不同模拟配置下的性能。
对于 BPU 实验,应至少分析程序执行时间、IPC、BTB 命中率、BTBMisPrediction 四个指标,并进行可视化。其对应的条目分别为:
- simseconds
- system.cpu.ipc
- system.cpu.branchPred.BTBHitRatio
- system.cpu.branchPred.BTBMispredicted
对于 Cache 实验,应至少分析 L2Hits、L2Miss、L2HitRate 三个指标,并进行可视化。其对应的条目分别为:
- system.l2cache.overallMisses::total
- system.l2cache.overallHits::total
- 1 - system.l2cache.overallMissRate::total
实验要求
对于 BPU 实验,应运行 BiMode、LTAGE 两种基本现代预测器模型[3],并自行微调 MyBP 的 Choice 计数器,至少实现阈值为 3 (22 - 1,即 choiceCtrBits = Param.Unsigned(3, …)) 和 7 (23 - 1,即 choiceCtrBits = Param.Unsigned(4, …)) 两种饱和计数器深度。观察性能变化。
对于 Cache 实验,请运行以下配置:
| 配置 | L1 | L1-assoc | L2 | L2-assoc |
|---|---|---|---|---|
| 1 | 64kB L1d, 16kB L1i | 2 | 256kB | 4 |
| 2 | 64kB L1d, 16kB L1i | 2 | 256kB | 8 |
| 3 | 64kB L1d, 16kB L1i | 2 | 512kB | 8 |
| 4 | 64kB L1d, 16kB L1i | 2 | 512kB | 16 |
结合数据分析性能。当前的缓存配置偏小,因此命中率低,可以继续调大 Cache Size,并记录性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号