课程 | AI 编译器(三)
图优化
主要看笔记和讲义 | 图优化 | 非图级别的优化,这里记录一些重点。
ONNX Simplify
ONNX 模型优化工具,用于减少 ONNX 模型大小和计算复杂度。提供常量折叠、冗余节点消除等优化。
数据布局
一些特殊的张量格式,如 Ascend NC1HWC0

关于推理框架
推理框架存在的必要性。TensorRT 比 JIT 快一些,以及本课程前置课程也提及,LLMs 已有部分不满足传统 AI 编译器遵循的计算图规约,如 KV-Cache 等。但也存在问题,如 TensorRT 对动态图和 flash att 等算子支持不好。
图优化整体流程总结
- 启动时会构建一个图优化 Pass 名字和功能代码映射的表;
- 计算图构建完成后在下沉到运行时图之前,会将仓库中的图优化 Pass 中执行一遍;
- 如果满足特定的图转换机制会跳转到对应的代码中完成图替换;
- 重复步骤 3 直到仓库中的图优化 Pass 没有可以执行的 Pass;
- 输出得到新的计算图并下沉到运行时图;
非图级别的优化
内存优化
InfiniTensor 采用了两种实现,分别为常规的 NaiveAllocator 和 LazyAllocator. 后者通过模拟计算图执行和动态内存重用,将预先分配的内存大小从 Tensor 压缩到 Peak. 课设题目 TinyInfiniTensor 简化了部分实现,可以先学习 InfiniTensor 代码再完成课设。
Allocator 采用红黑树管理内存。参考☞
算子的硬件无关优化
以 Transpose 算子为例,通过 perm 属性确定转置前后维度的对应关系。实现为大循环或使用新索引直接计算旧索引,本质上类似。

Transpose 是访存算子,需要进行访存优化。
去除形状大小为 1 的维度
同时更新 shape 和 perm.
// 去除形状里的 1 维度
{
shape.reserve(rank);
std::vector<ddim_t> mapDim(rank, 0);
for (dim_t sub = 0; auto i : range0_(rank)) {
if (auto l = shape_[i]; l != 1) {
shape.push_back(l);
mapDim[i] = i - sub;
} else {
++sub;
mapDim[i] = -1;
}
}
合并连续维度
// 合并连续的维度
{
std::vector<ddim_t> mapDim(rank, 0);
std::iota(mapDim.begin(), mapDim.end(), 0);
for (auto past = perm[0]; auto dim : std::span(perm.begin() + 1, perm.end())) {
if (dim == past + 1) {
mapDim[dim] = -1;
for (auto j : range<dim_t>(dim + 1, rank)) {
--mapDim[j];
}
}
past = dim;
}
auto j = 0;
for (auto i : range(1ul, rank)) {
if (mapDim[i] >= 0) {
shape[++j] = shape[i];
} else {
shape[j] *= shape[i];
}
}
shape.resize(rank = j + 1);
for (auto i = 0; auto from : perm) {
if (auto to = mapDim[from]; to >= 0) {
perm[i++] = to;
}
}
perm.resize(rank);
}
合并末尾连续访存
这里尚存在一些优化空间。
// 合并末尾连续访存
if (perm.back() == rank - 1) {
blockSize *= shape.back();
blockCount /= shape.back();
shape.pop_back();
perm.pop_back();
--rank;
}
参考链接
- Transpose - ONNX 1.18.0 documentation
- 如何实现比PyTorch快6倍的Permute/Transpose算子? - 知乎
- RefactorGraph/src/04kernel/src/attributes/transpose_info.cc at master · InfiniTensor/RefactorGraph
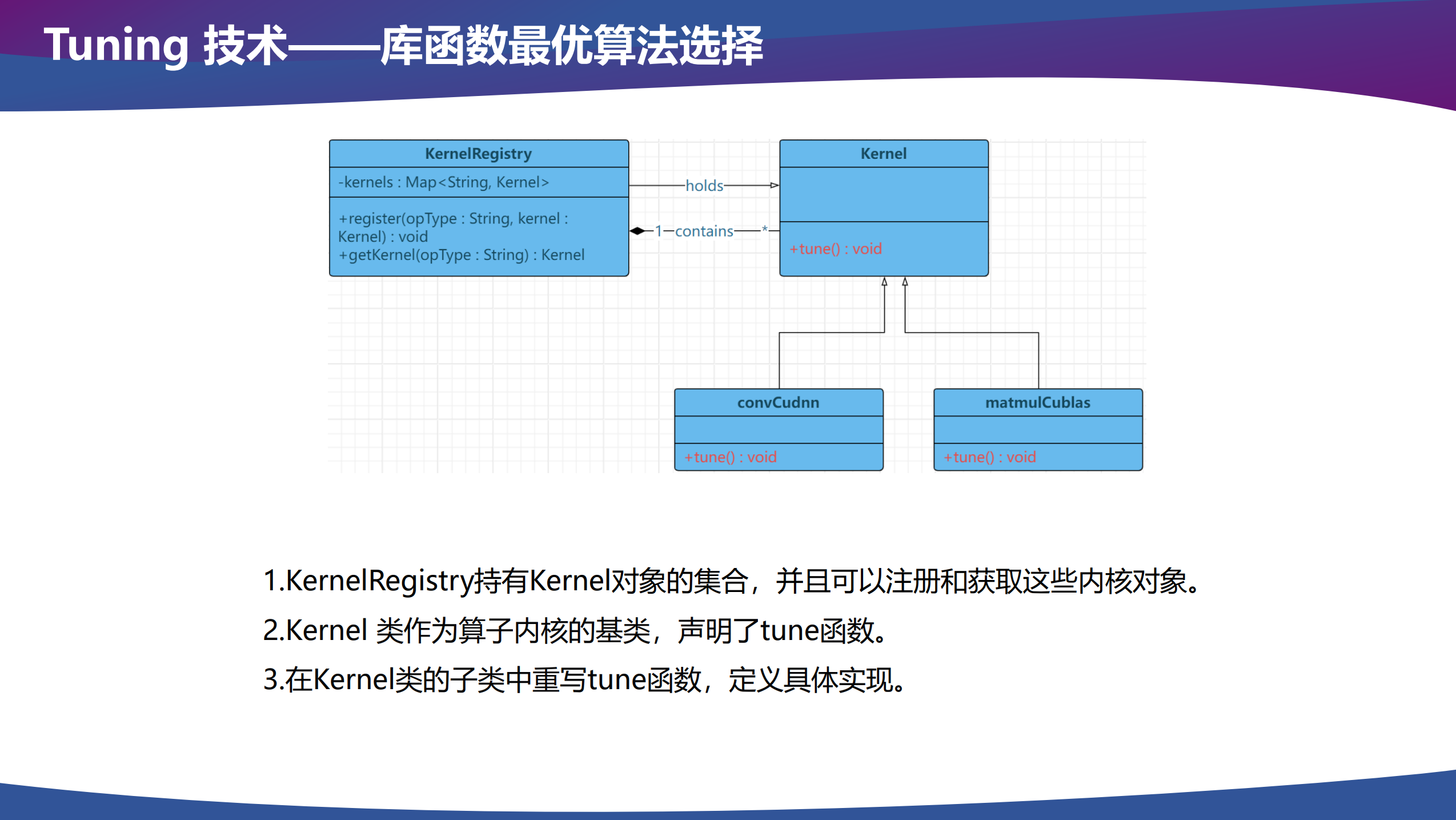
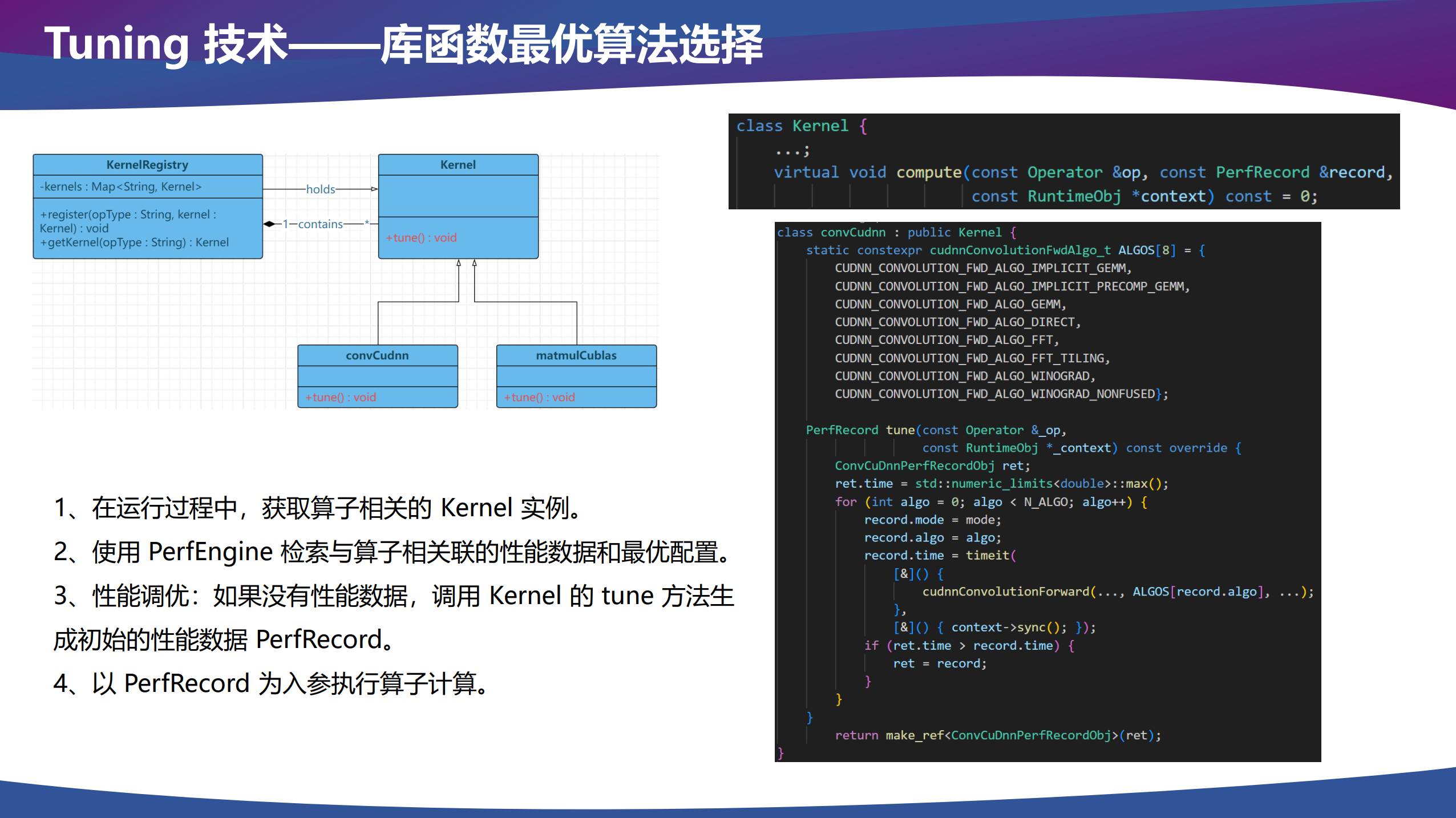
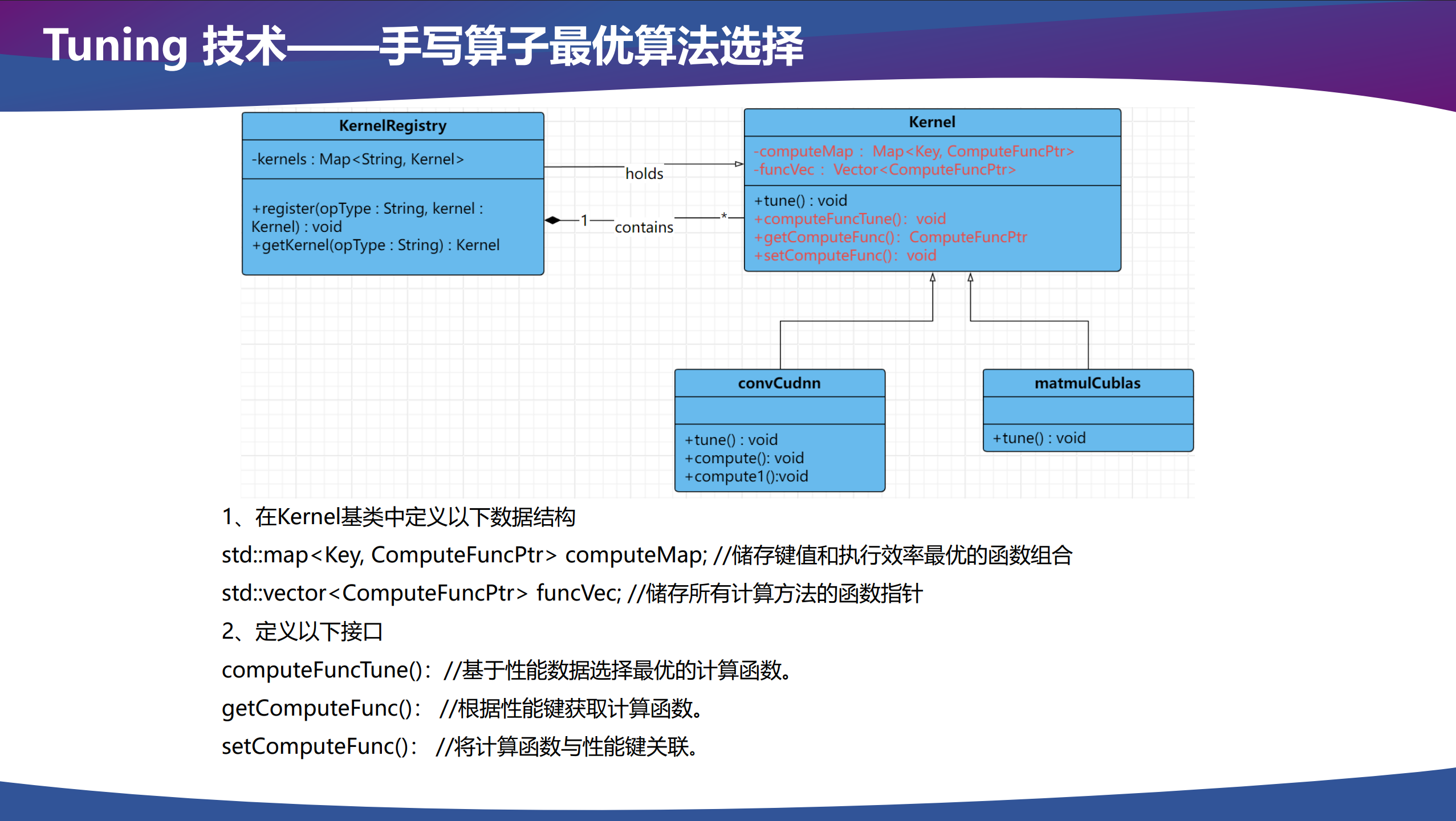
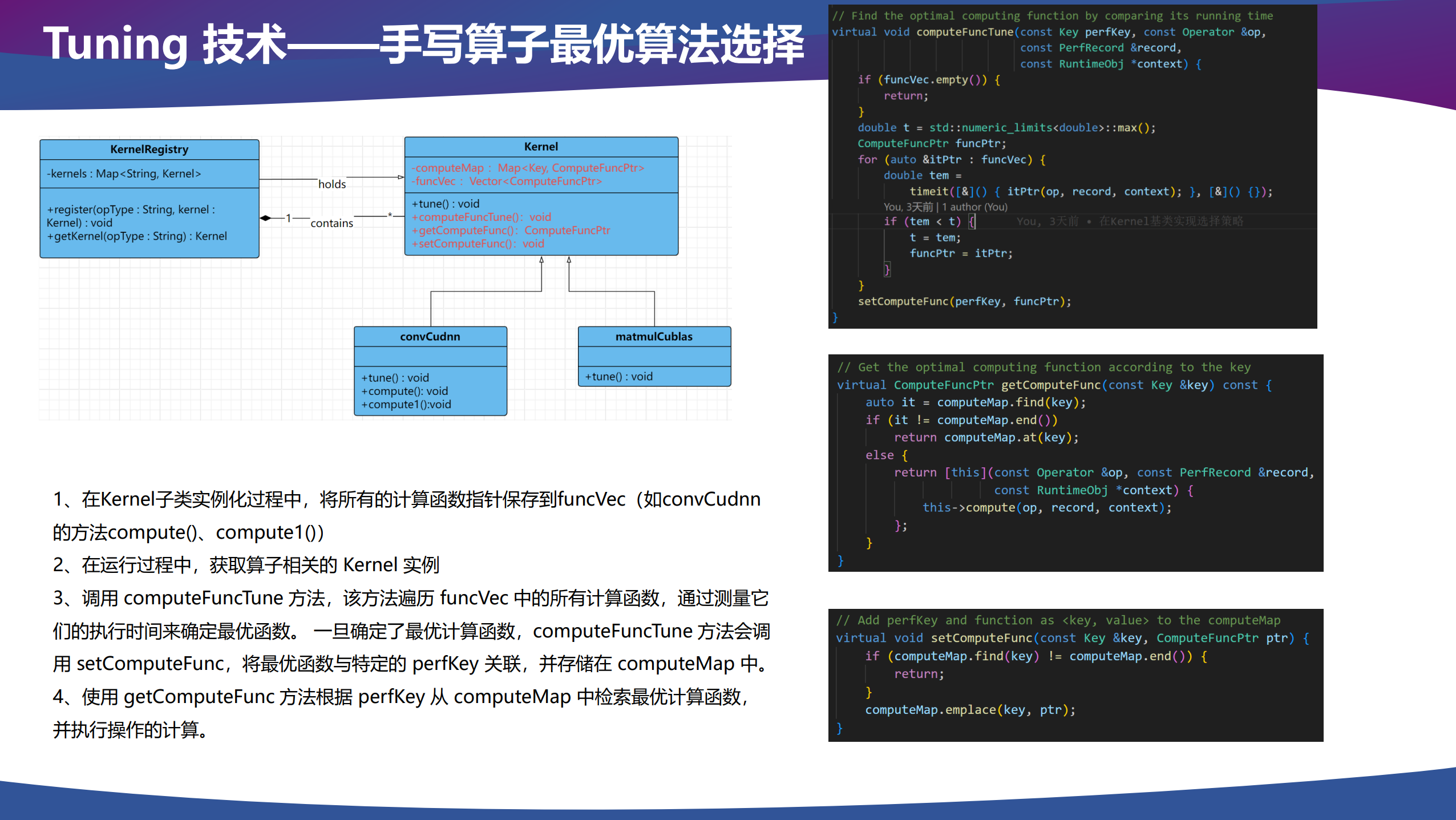
Tuning
推理框架后端可能会有多种 kernel 实现,例如调用算子库的 kernel、手写的 kernel、Triton 生成的 kernel 和代码生成的 kernel 等。在调用算子进行推理计算时,我们需要选择一个性能最好的 kernel 作为我们实际调用的 kernel,由于每个 kernel 自己可能也有多种实现,所以对于每个 kernel 来说,也需要选择自己最优的算法配置。
关系为 Tuning → Kernel 选择 → 算法选择。
生成和执行任务图 - 运行时优化
问题描述。在使用 NVIDIA Nsight Systems 进行 profile 时发现,kernel 与 kernel 之间存在大量间隙。这是因为 kernel 放入流中时,主机驱动程序进行一系列操作,如实例化等,对一些执行时间较短的 kernel,这些操作可能占到整个端到端推理的大部分时间。
解决方案。以 CUDA Graph 为例,将「生成和执行任务图」分为三个阶段:定义(definition),实例化(instantiation)和执行(execution)。一次实例化后的可执行图可以在流中被启动,类似于任何其他的 cuda 任务。它可以被启动任意多次,而无需重复实例化。最终消除 kernel launch 开销。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号