06_sparkStreaming
SparkStreaming
sparkStreaming 用于处理流式数据,其中输入数据源包括 Kafka、Flume、HDFS 等;结果输出目的地址包括 HDFS、数据库。
SparkCore 对应 RDD;SparkSQL 对应 DataFrame/DataSet;SparkStreaming 对应 DStream(离散化数据流),DStream 是对 RDD 在实时数据处理场景的一种封装。
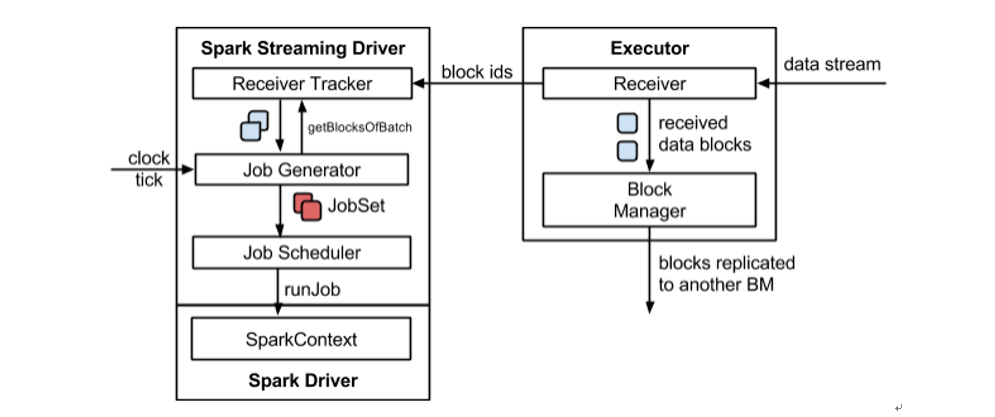
SparkStreaming 主要由以下几个部分组成:
Receiver
数据源接收器,负责接收数据的 Executor 组件,负责接收 Executor 并转发给其它 Executor 做计算;
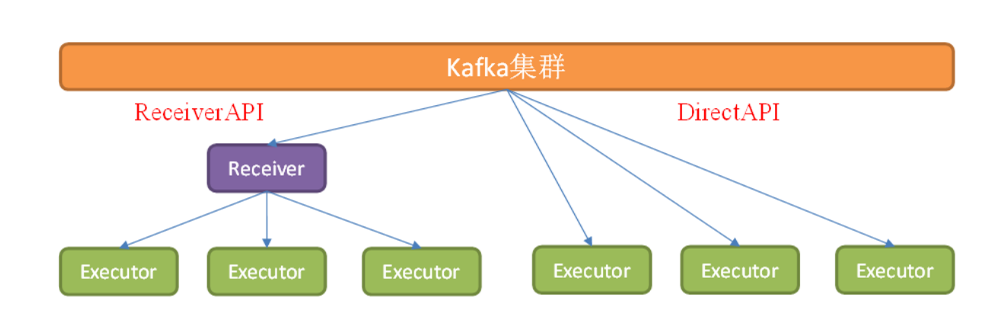
- ReceiverAPI:专门用于接收数据的 Executor,但是接收速率和消费速率可能不匹配,导致计算节点内存溢出;
- DirectAPI:由计算 Executor 直接主动消费 Kafka 等数据源数据,速度可由自身控制。
Micro-batch Generator
微批次生成器,将接收到的数据划分为小的微批次,每个批次包含一段时间范围内的数据,它可以控制生成速率。

DStream
离散化流,每个微批次数据可以转化为 DStream 对象。简单来说 DStream 就是对 RDD 在实时数据处理场景的一种抽象。

Transformations
转换操作,在 DStream 上执行一系列的转换操作(映射、过滤、聚合等);
转换操作是在微批次级别上进行的,对每个微批次的数据执行相同的转换操作。
RDD Generator
转换操作生成的 DStream 会被转化为相应 RDD 等待处理;
RDD 为分布式弹性数据集,可以由 Spark 并行处理。
Compute Engine
Spark引擎会根据RDD的依赖关系和转换操作构建执行计划,并将计算任务分配给集群中的工作节点执行。
Output Operations
计算执行完毕后,结果写入外部系统或者存储介质中;
输出可以是保存到文件系统、数据库、消息队列等组件;
Fault Tolerance
SparkStreaming 内置容错处理机制,可以处理节点故障或者数据丢失情况;
DStream 创建
RDD 队列
为了模拟测试,可以使用 RDD 队列接收 RDD 来模拟 DStream 创建。
def test01(): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
val ssc = new StreamingContext(conf, Seconds(3))
// 创建RDD队列
val rddQueue = new mutable.Queue[RDD[Int]]
// 获取 QueueInputStream
val inputDStream = ssc.queueStream(rddQueue, oneAtATime = false)
val sumDStream = inputDStream.reduce(_ + _)
sumDStream.print()
ssc.start()
// 循环向 RDD 放入数据
for (i <- 1 to 5) {
rddQueue += ssc.sparkContext.makeRDD(1 to 5)
Thread.sleep(2000)
}
ssc.awaitTermination()
}
自定义数据源接收器
同样可以自定义数据源,实现接收数据,数据传递到 Spark 等待处理。
继承 Receiver,实现onStart、onStop方法实现数据接收方法,单独启动一个线程负责接收数据并保存到 Spark 内存。
def test02(): Unit = {
//1.初始化Spark配置信息
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkstreaming")
//2.初始化SparkStreamingContext
val ssc = new StreamingContext(sparkConf, Seconds(5))
//3.创建自定义receiver的Streaming
val lineDStream = ssc.receiverStream(new CustomerReceiver("192.168.56.153", 9999))
//4.将每一行数据做切分,形成一个个单词
val wordDStream = lineDStream.flatMap(_.split(" "))
//5.将单词映射成元组(word,1)
val wordToOneDStream = wordDStream.map((_, 1))
//6.将相同的单词次数做统计
val wordToSumDStream = wordToOneDStream.reduceByKey(_ + _)
//7.打印
wordToSumDStream.print()
//8.启动SparkStreamingContext
ssc.start()
ssc.awaitTermination()
}
/**
* @param host : 主机名称
* @param port : 端口号
* Receiver[String] :返回值类型:String
* StorageLevel.MEMORY_ONLY: 返回值存储级别
*/
class CustomerReceiver(host: String, port: Int) extends Receiver[String](StorageLevel.MEMORY_ONLY) {
// receiver刚启动的时候,调用该方法,作用为:读数据并将数据发送给Spark
override def onStart(): Unit = {
//在onStart方法里面创建一个线程,专门用来接收数据
new Thread("Socket Receiver") {
override def run() {
receive()
}
}.start()
}
// 读数据并将数据发送给Spark
def receive(): Unit = {
// 创建一个Socket
var socket: Socket = new Socket(host, port)
// 字节流读取数据不方便,转换成字符流buffer,方便整行读取
val reader = new BufferedReader(new InputStreamReader(socket.getInputStream, StandardCharsets.UTF_8))
// 读取数据
var input: String = reader.readLine()
//当receiver没有关闭并且输入数据不为空,就循环发送数据给Spark
while (!isStopped() && input != null) {
store(input)
input = reader.readLine()
}
// 如果循环结束,则关闭资源
reader.close()
socket.close()
//重启接收任务
restart("restart")
}
override def onStop(): Unit = {}
}
Kafka 数据源
Kafka 或者 Flume 作为流式数据源,将数据发送到 SparkStreaming 进行计算,可以实现简单的流计算过程。
object KafkaWordCount{
def main(args:Array[String]){
// 初始化 Spark 环境配置
val sparkConf = new SparkConf().setAppName("KafkaWordCount").setMaster("local[2]")
val sc = new SparkContext(sparkConf)
sc.setLogLevel("ERROR")
val ssc = new StreamingContext(sc,Seconds(10))
// 对于 Kafka/Flume 流式数据,可能会发生丢失,需要通过 ssc.checkPoint() 建立检查点机制
ssc.checkpoint("file:///usr/local/spark/mycode/kafka/checkpoint") //设置检查点,如果存放在HDFS上面,则写成类似ssc.checkpoint("/user/hadoop/checkpoint")这种形式,但是,要启动Hadoop
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "localhost:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "use_a_separate_group_id_for_each_stream",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (true: java.lang.Boolean)
)
val topics = Array("wordsender")
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
stream.foreachRDD(rdd => {
val offsetRange = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
val maped: RDD[(String, String)] = rdd.map(record => (record.key,record.value))
val lines = maped.map(_._2)
val words = lines.flatMap(_.split(" "))
val pair = words.map(x => (x,1))
val wordCounts = pair.reduceByKey(_+_)
wordCounts.foreach(println)
})
ssc.start
ssc.awaitTermination
}
}
DStream 转换
DStream 的操作与 RDD 类似,分为转化操作、输出操作,此外转换操作还有一些比较特殊的方法:updateStateByKey、transform。
DStream 的转换操作可以分为有状态转换操作、无状态转换操作两种:
无状态转换操作
将 RDD 操作运用到 DStream 的每个批次上,每个批次相互独立。常见的 RDD 操作比如
map、flatMap、filter、repartition、reduceByKey、groupByKey等。

// 以黑名单过滤为例
def method02(): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("transform")
val ssc = new StreamingContext(conf, Seconds(8))
ssc.sparkContext.setLogLevel("WARN")
// 构建黑名单数据
val blackList = Array(("spark", true), ("scala", true))
val blackListRDD = ssc.sparkContext.makeRDD(blackList)
// 生成测试 DStream,zipWithIndex 转换字符串为 (word, index) 元组格式数据
val strArray = ("Spark java scala hadoop kafka hive hbase zookeeper").split("\\s+").zipWithIndex.map { case (word, idx) => s"$idx $word" }
val rdd = ssc.sparkContext.makeRDD((strArray))
val clickStream = new ConstantInputDStream(ssc, rdd)
// 流式数据处理
val clickStreamFormatted = clickStream.map(value => (value.split(" ")(1), value))
clickStreamFormatted.transform(clickRDD => {
val jointedBlackListRdd = clickRDD.leftOuterJoin(blackListRDD)
jointedBlackListRdd.filter{
case (word, (streamingLine, flag)) =>
if (flag.getOrElse(false)) false
else true
}.map {case (word, (streamingLine, flag)) => streamingLine}
}).print()
// 启动流式作业
ssc.start()
ssc.awaitTermination()
}
或者直接过滤,考虑到 Driver 端数据在多个 Executor 间重复使用,设置为广播变量:
def method03(): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("transform")
val ssc = new StreamingContext(conf, Seconds(8))
ssc.sparkContext.setLogLevel("WARN")
// 构建黑名单数据,构建广播变量
val blackList = Array(("spark", true), ("scala", true))
val blackListBC = ssc.sparkContext.broadcast(blackList.filter(_._2).map(_._1))
// 生成测试 DStream,zipWithIndex 转换字符串为 (word, index) 元组格式数据
val strArray = ("Spark java scala hadoop kafka hive hbase zookeeper").split("\\s+").zipWithIndex.map { case (word, idx) => s"$idx $word" }
val rdd = ssc.sparkContext.makeRDD((strArray))
val clickStream = new ConstantInputDStream(ssc, rdd)
// 流式数据处理
clickStream.map(value => (value.split(" ")(1), value))
.filter { case (word, _) =>
!blackListBC.value.contains(word)
}
.map(_._2)
.print()
// 启动流式作业
ssc.start()
ssc.awaitTermination()
}
有状态转换操作
各个批次数据间存在关联性,包括基于滑动窗口的转化操作、追踪状态变化的转换操作。
窗口操作
可以设置当前窗口大小和滑动窗口间隔来动态获取当前 Streaming 的状态。
基于窗口的操作会比StreamingContext的批次间隔更长的时间范围内,通过整合多个批次结果来计算出整个窗口的结果。
窗口依赖于两个参数:窗口长度(控制每次计算最近的多少个批次数据)、滑动步长(控制对新的 DStream 的计算间隔),注意这两个参数都必须为采集批次大小的整数倍。
核心窗口函数:
window(windowLength, slideInterval): 基于对源DStream窗口的批次进行计算返回一个新的DStream;reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]):在一个(K,V)对的 DStream 上调用此函数,返回一个新的(K,V)DStream,并且统计窗口中批次数据的总和;countByWindow(windowLength, slideInterval): 返回一个滑动窗口计数流中的元素个数;reduceByWindow(func, windowLength, slideInterval): 通过使用自定义函数整合滑动区间流元素来创建一个新的离散化数据流;
例如下面的例子,采集批次时间间隔为5s,采集时间窗口大小为 20s,采集窗口间隔为 10s.
def window_demo01(): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("transform")
// 每 5s 生成一个 RDD
val ssc = new StreamingContext(conf, Seconds(5))
ssc.sparkContext.setLogLevel("WARN")
val lines = ssc.socketTextStream("localhost", 1521)
lines.foreachRDD { (rdd, time) =>
println(s"rdd = ${rdd.id}; time = $time")
rdd.foreach(value => println(value))
}
// 设置 20s 窗口长度、10s 滑动间隔
val res1 = lines.reduceByWindow(_ + " " + _, Seconds(20), Seconds(10))
res1.print()
val res2 = lines.window(Seconds(20), Seconds(10))
res2.print()
// 窗口元素求和
val res3 = lines.map(_.toInt).reduceByWindow(_ + _, Seconds(20), Seconds(10))
res3.print()
val res4 = res2.map(_.toInt).reduce(_ + _)
res4.print()
ssc.start()
ssc.awaitTermination()
}
updateStateByKey 状态跟踪操作
该函数为每一个 Key 维护了一份 state 状态,并且定义了更新函数来对该 Key 的状态不断更新;
对于每个新的 batch 而言, Spark Streaming 会在使用 updateStateByKey 的时候为已经存在的 key 进行 state 的状态更新;
使用 updateStateByKey 时要注意开启 checkpoint 功能。
这里演示一个对流式数据源的 wordCount 累计求和,并分批次保存结果:
def window_demo03(): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("transform")
val ssc = new StreamingContext(conf, Seconds(3))
ssc.sparkContext.setLogLevel("ERROR")
ssc.checkpoint("datas/checkpoint/")
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val wordStream = words.map((_, 1))
// 定义状态更新函数
val updateFunc = (values :Seq[Int], state:Option[Int])=> {
// 计算当前批次总和
val currentSum = values.sum
// 计算历史状态总和
val previousSum = state.getOrElse(0)
// 计算当前+历史状态的总和
Some(currentSum + previousSum)
}
val stateStream = wordStream.updateStateByKey(updateFunc)
stateStream.print()
stateStream.repartition(1).saveAsTextFiles("datas/output")
ssc.start()
ssc.awaitTermination()
}
DStream 输出
DStream 支持的输出操作API包括:
saveAsTextFiles(prefix, [suffix]):以文本文件格式存储该 DStream 的内容;saveAsObjectFiles(prefix, [suffix]):以 Java 对象序列化的方式将 DStream 中数据保存为序列化文件数据;print():简单输出到控制台,但只打印批次的最开始10个元素;foreachRDD(func):将函数 func 作用到 DStream 的每一个 RDD。其中函数 func 可以执行任意复杂的逻辑,例如写入数据库、发送消息到消息队列、保存到文件系统等。
def dstream_output(): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("transform")
val ssc = new StreamingContext(conf, Seconds(3))
val lineDStream = ssc.socketTextStream("192.168.56.153", 9999)
val wordToOneStream = lineDStream.flatMap(_.split(" ")).map((_, 1))
wordToOneStream.foreachRDD(
rdd => {
// Driver 端执行
println("222222:" + Thread.currentThread().getName)
rdd.foreachPartition(
// Executor 端执行
iter => iter.foreach(println)
// 这里获取连接
// 操作数据写数据库
// 关闭连接....
)
}
)
ssc.start()
ssc.awaitTermination()
}
注意如果 DStream 数据写入到数据库,获取连接的操作必须实现在 Executor 端,而不是 Driver 层面。
DStream 优雅停机
在 HDFS 中根据配置决定当前 SparkStreaming 的生命周期。
def stop_gracefully(): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("transform")
conf.set("spark.streaming.stopGracefullyOnShutdown", "true")
val ssc = new StreamingContext(conf, Seconds(3))
val lineDStream = ssc.socketTextStream("192.168.56.151", 9999)
lineDStream.flatMap(_.split(" "))
.map((_, 1))
.print()
// 开启监控程序
new Thread(new MonitorStop(ssc)).start()
ssc.start()
ssc.awaitTermination()
}
// 定时监控 hdfs 文件状态
class MonitorStop(ssc : StreamingContext) extends Runnable {
override def run(): Unit = {
val fs = FileSystem.get(new URI("hdfs://192.168.56.151:9000"), new Configuration(), "root")
while (true) {
Thread.sleep(5000)
val result = fs.exists(new Path("hdfs://192.168.56.151:9000/stopSpark"))
if (result) {
val state = ssc.getState()
if (state == StreamingContextState.ACTIVE) {
ssc.stop(true, true)
System.exit(0)
}
}
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号