Redis—集群扩缩容
Redis 可以通过主从节点读写分离来扩展主节点读取能力,那么新增主节点也可以增强数据写入能力。
Redis Cluster
Redis 通过主从复制来扩展主节点的数据读取能力,但是当主节点的写入能力成为瓶颈时,集群就是增强 Redis 性能的解决方案之一。
Redis Cluster 通过主从复制实现读操作的高可用,通过 Gossip协议 实现集群状态数据及路由数据的管理,通过 法团协议 完成故障检测(至少 N/2+1 个哨兵节点均认为主节点故障,才客观认为该主节点故障),通过 RAFT协议 实现故障转移(Raft选举出主哨兵节点来主持新 Leader 的替换)。
集群原理
针对 Redis Master 集群扩展,我们需要关注以下问题:
- 新数据写入,应该写哪台机器;
- 查询时应该查哪台机器;
- 新节点加入,如何重新分配数据,让新节点对外提供服务;节点退出,如何把节点上存储的数据分配到其它机器;
- 有节点故障,如何保证外部仍然能够读取该节点上的数据,而不至于崩溃。
数据分布问题
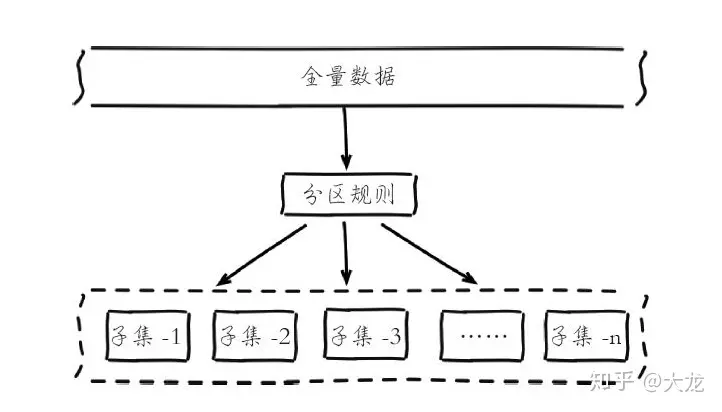
Redis 使用了虚拟桶分区,利用特定的哈希函数将数据分布到多个桶中。具体点,Redis 利用 CRC16 函数计算哈希值并将所有键打散到 16384 个桶中,每个桶只可以由一个 Master 节点存储,一个 Master 节点可以存储多个桶数据。
数据查询问题
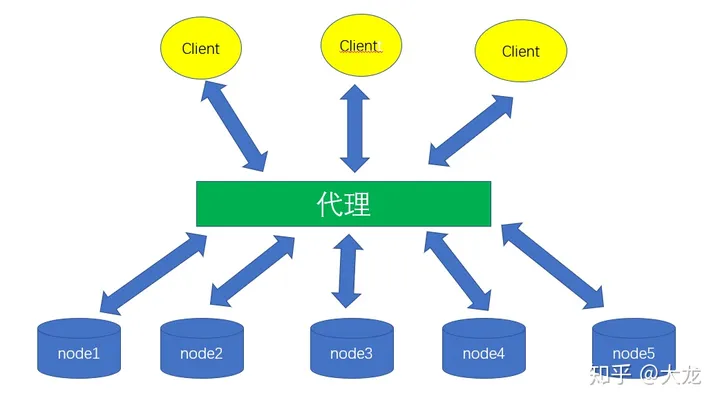
我们需要根据 Key 计算出具体的存储桶的位置,常规的方法是通过中间层代理。由一个中间节点(HDFS中 NameNode)管理所有元数据,但是中间层的单点性会导致高并发时瓶颈。
Redis 没有采用代理方法,而是客户端直练每个节点。每个节点存储着整个集群状态,该状态中包含了每个桶的负责节点。Redis 内部用一个大小固定的 CLUSTER_SLOTS 来保存每个桶的负责节点,Redis 接收关于某个 Key 的查询请求,先计算出桶的编号,如果桶由当前节点负责,直接查询,否则回复 MOVED 重定向错误,通知客户端真正的正确节点。
为了避免多次重定向查询,可以将桶的信息存储到客户端,这样客户端计算出桶就可以直接查询到,如果集群发生扩缩容导致桶存储位置变化,只需要在访问时 MOVED 重定向并更新缓存即可。
集群伸缩
通过上述讲解,我们知道 Redis 中数据是以 Slot 的形式存在,所以伸缩的本质就是 Slot 在不同节点间的迁移,那么有以下问题:如果A节点正在向B节点迁移 Slot1 的数据,未完成迁移时可能出现数据共存在 A、B 两个节点,该路由给哪个节点?
假设这样一个场景:原本有 6379、6380、6381、6382 四个节点,现在加入 6383 节点,那么其它节点需要向该节点迁移 slots ,Redis 并没有实现自动负载均衡工具,需要用户决定如何迁移。
设置迁入迁出状态
现在假设 6379 数据向 6383 迁移。
- 每个 Redis 集群节点都会保存
clusterState,它存储了整个集群中 slots 和其存储节点的对应关系。那么当 6379 迁移 slot1 时,首先标记当前处于IMGRATING状态,6382 同样标记自己处于IMPORTING,具体实现上就是分别设置migrating_slots_to、importing_slots_from两个数组的对应 index 值。在未完成迁移前,集群中所有节点都会将 slot1 的请求重定向到 6379 节点; - 6379 将 slot1 标记为
IMGRATING状态时,会接受所有 slot1 的请求,但只会处理桶在自己节点的请求,否则重定向到 6382 节点; - 6382 节点将 slot1 标记为
IMPORTING状态时,也可以接受 slot1 的请求,但前提是该请求中必须包含重定向命令(也就是说6379无法处理转发过来的),否则转发到 6379 节点处理。
如上过程就解决了以下问题:
- 迁移过程中,其它节点收到请求后都重定向到 6379 节点(
IMGTATING状态); - 6379 收到请求判断能否处理,不能处理重定向到 6382(
IMPORTING); - 6382 节点只接收并处理标记有重定向标志的请求,否则重定向到 6379。
桶迁移完毕后,广播更新 slot1桶所存储的节点信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号