一、爬虫简介
一、爬虫入门:
1.1 http协议:
概念: 就是服务器和客户端进行数据交互的一种形式。
常用的请求头信息:
- User-Agent:当前请求载体的身份标识 (浏览器等信息)
- Connection:请求完毕后,是断开连接还是保持连接
常用的响应头信息:
- Content-Type:服务器响应回客户端的数据类型
Https协议:
- 安全的超文本传输协议
数据加密方式:
- 对称密钥加密:客户端将信息数据加密后,同时将密钥和密文发送给客户端
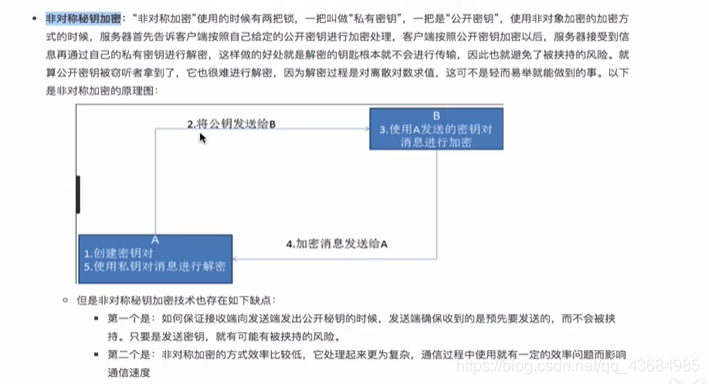
- 非对称密钥加密:服务器端制定加密方式(公钥),然后将公钥发送给客户端;客户端拿到公钥后将数据加密(秘钥),然后将私钥发送给客户端。
- 证书密钥加密:
非对称密钥仍然存在不足,比如秘钥被劫持然后篡改,导致服务器不能正确解析;或者是公钥被劫持,导致客户端进行错误的加密。
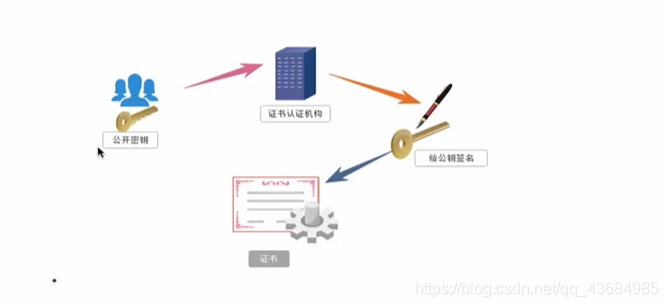
证书秘钥加密加入了证书认证机构,服务器端会首先将产生的公钥发送给证书认证机构,证书认证机构对公钥进行了签名然后转交给客户端,客户端只有在接收到签了名的公钥后才会进行加密。
1.2 Request模块:
python中原生的一款基于网络请求的模块,功能非常强大,简单便捷,效率极高。
作用:模拟浏览器发送请求
(1)如何使用[requests模块的编码流程]:
① 指定 url;
② 发送请求;
③ 获取响应数据;
④ 持久化存储(响应数据);
(2) 环境安装:
打开pycharm的settings中的interpreter,搜索requests下载
(3)实战编码:
关于python中使用 with open() as 进行文件读写的操作:
# 需求:爬取搜狗首页的页面数据
import requests
if __name__ == "__main__":
#1.指定url
url='https://www.sogou.com/'
#2.发送请求
response=requests.get(url=url);
#3.获取响应的数据 .text返回的是字符串形式的响应数据
page_text=response.text
print(page_text)
#4.持久化存储
with open("./sogou.html","w",encoding="utf-8") as fp:
fp.write(page_text)
print("爬取数据结束!")
1.3 Request模块巩固深入案例(聚焦爬虫):
(1). 案例一. 网页采集器:
UA检测:(User-Agent)
门户网站的服务器会检测对应请求的身份标识,如果检测到请求的载体身份标识为某一款浏览器,说明该请求是一个正常的请求。但是如果检测到请求的身份标识不是某一款浏览器的,则表示为不正常的亲求(爬虫),则服务器很有可能会拒绝此次请求。
UA伪装:让爬虫对应的请求载体身份标识伪装成一款浏览器.
# 制作一个简易的网络请求器
import requests
if __name__ == "__main__":
# 1.设置请求 url
url='https://www.sogou.com/web'
value=input('请输入请求的参数:')
# 设置请求参数
params={'query':value}
# 设置请求头信息---UA伪装
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'}
# 2.发起request请求
responses=requests.get(url=url,params=params,headers=headers)
# 3.打印结果数据
page_text=responses.text
print(page_text)
# 4.持久化数据
fileName=value+'.html'
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(page_text)
print("爬取数据结束!")
(2). 案例二. 百度翻译破解:
# requests实战破解百度翻译----json字符格式
import requests
import json
if __name__ == '__main__':
# 1.指定url
post_url='https://fanyi.baidu.com/sug'
# 2.指定请求数据、UA伪装
params=input('请输入待翻译的数据:')
data={
'kw':params
}
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
responses=requests.post(url=post_url,data=data,headers=headers)
# 3.解析responses中的数据为json对象(注意不是字符文件)----只有返回的Content-type是json的才行
dic_obj=responses.json()
# 4.持久化存储
fileName=params+'.json'
fp=open(fileName,'w',encoding='utf-8')
json.dump(obj=dic_obj,fp=fp,ensure_ascii=False)
print("爬取结束!")
有关 json.dump() 的相关知识: https://www.cnblogs.com/autobyme/p/11011451.html
json.dumps(data,ensure_ascii=False) : 将python数据结构转化为JSON字符串,不使用ascii编码;
json.loads(json_str) : 将JSON字符串转化为python数据结构;
json.dump(data,fp,ensure_ascii=False) : 与文件相关,将python对象转化为字符串并且写入文件;
(3).案例三.爬取豆瓣电影数据:
# 爬取豆瓣电影数据
import requests
import json
if __name__ == '__main__':
# 1.定义Url
url='https://movie.douban.com/j/new_search_subjects'
params={
'sort':'U',
'range':'0,10',
'tags':'',
'start':'40',
'genres':'喜剧'
}
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
# 3.发送request请求
responses=requests.get(url=url,params=params,headers=headers)
# 4.存储打印json格式数据
dict_obj=responses.json()
# 5.持久化存储
fp=open('./douban_movie.json','w',encoding='utf-8')
json.dump(dict_obj,fp,ensure_ascii=False)
print('爬取数据完毕!')
(4).案例四. 爬取坑德基官网数据:
# 爬取肯德基官网数据
import requests
import json
if __name__ == "__main__":
url='http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
data={
'cname':'',
'pid':'',
'keyword':'武汉',
'pageIndex':'1',
'pageSize':'10'
}
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
responses=requests.post(url=url,data=data,headers=headers)
page_text=responses.json()
print(page_text)
fp=open('./kfc.json','w',encoding='utf-8')
json.dump(page_text,fp,ensure_ascii=False)
print("爬取数据完毕!")
注意当页面发送请求后但是网址不变时就说明该请求是ajax请求,那么此时就需要关注response的Content-Type。

(5).案例五. 爬取药品监管局生产许可证数据:
当通过请求地址栏获取到的数据中不包含某些部分的信息,那么这些数据可能就是 ajax动态请求获取到的。多用抓包工具来分析----

从首页的ajax请求中获取出企业ID,然后根据每个企业ID到详情页中再次发送ajax请求获取数据。
如果我们能够批量获取多家企业的ID,就可以将id和url形成一个完整的详情页请求
# 需求:爬取药物监督管理总局的数据----升级版(可以自由指定页数)
import requests
import json
if __name__ == '__main__':
start_page=input('请输入需要爬取的初始页码:')
page_numbers=input('请输入需要爬取的页数:')
pages=list(range(int(start_page),int(start_page)+int(page_numbers)))
# 1.获取ajax请求中各个公司的id
url_id='http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
# 存储公司的ID
list_id = []
for page in pages:
datas_id={
'on':'true',
'page':page,
'pageSize':'15',
'productName':'',
'conditionType':'1',
'applyname':'',
'applysn':''
}
company_data=requests.post(url=url_id,data=datas_id,headers=headers).json()
for id in company_data['list']:
list_id.append(id['ID'])
# 2.根据ID去发送ajax请求获取每个公司的数据
# 存储公司数据
list_data=[]
for id in list_id:
url_data='http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById'
datas={
'id':id
}
responses=requests.post(url=url_data,data=datas,headers=headers).json()
list_data.append(responses)
# 3.数据持久化
fp=open('./medicine.json','w',encoding='utf-8')
json.dump(list_data,fp,ensure_ascii=False)
1.4 Python数据持久化之json数据以json格式写入txt文件:
json.dumps中indent参数是设置json缩进量的
举例:
tmp = {
"aaa" : "111",
"bbb" : '222'
}
import json
with open("tmp.txt", "w") as fp:
fp.write(json.dumps(tmp,indent=4))
json.dump(list_data,fp,ensure_ascii=False)
### 1.4 Python数据持久化之json数据以json格式写入txt文件:
json.dumps中indent参数是设置json缩进量的
举例:
```python
tmp = {
"aaa" : "111",
"bbb" : '222'
}
import json
with open("tmp.txt", "w") as fp:
fp.write(json.dumps(tmp,indent=4))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号