nlp入门
nlp应用
分词、词性标注、命名实体识别
好评/差评判别、情感分析、舆情分析
快递单信息自动识别
搜索
智能问答和对话
机器同传
词向量
one-hot表示
把每个词表示为一个长向量。这个向量的维度是词表大小,向量中只有一个维度的值为1,其余维度为0,这个维度就代表了当前的词。 例如:苹果 [0,0,0,1,0,0,0,0,···] 。one-hot表示不能展示词与词之间的关系,且特征空间非常大。
分布式表示
word embedding指的是将词转化成一种分布式表示,又称词向量。分布式表示将词表示成一个定长的连续的稠密向量。
word2vec
CBOW:通过上下文的词向量推理中心词。
Skip-gram:根据中心词推理上下文。
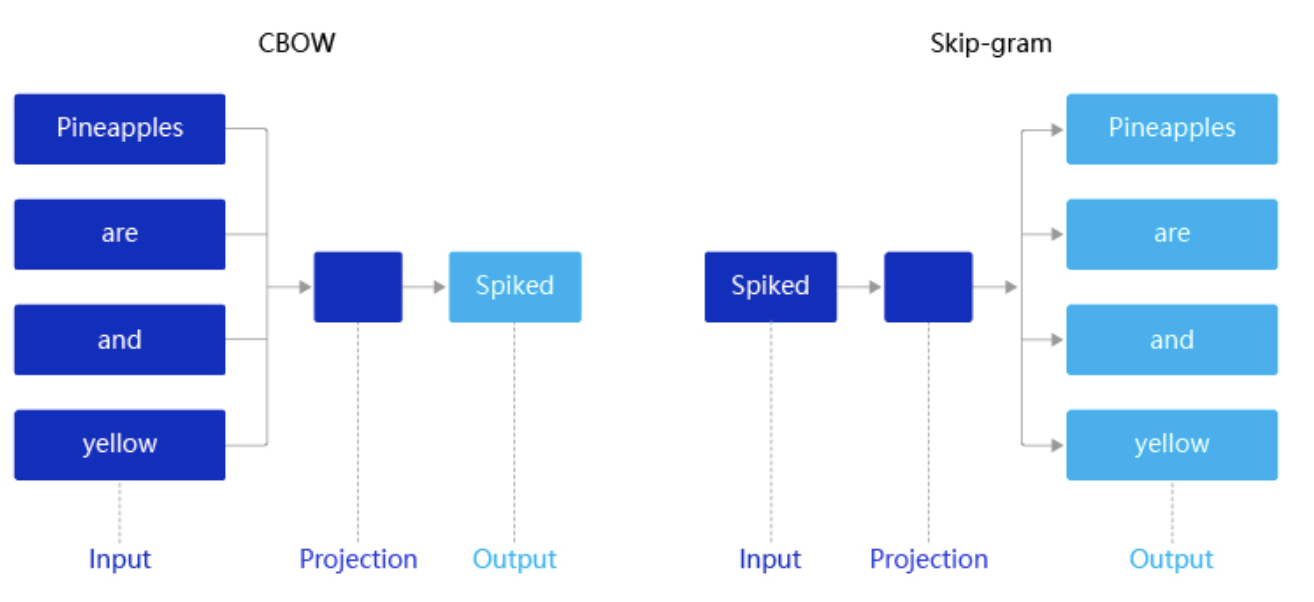
预训练词向量
word embedding:Glove、fasttext、ElMo
很多预训练完成的词向量,可直接调用使用,用来初始化,可提升简单网络的收敛速度、精度。
CNN&&RNN
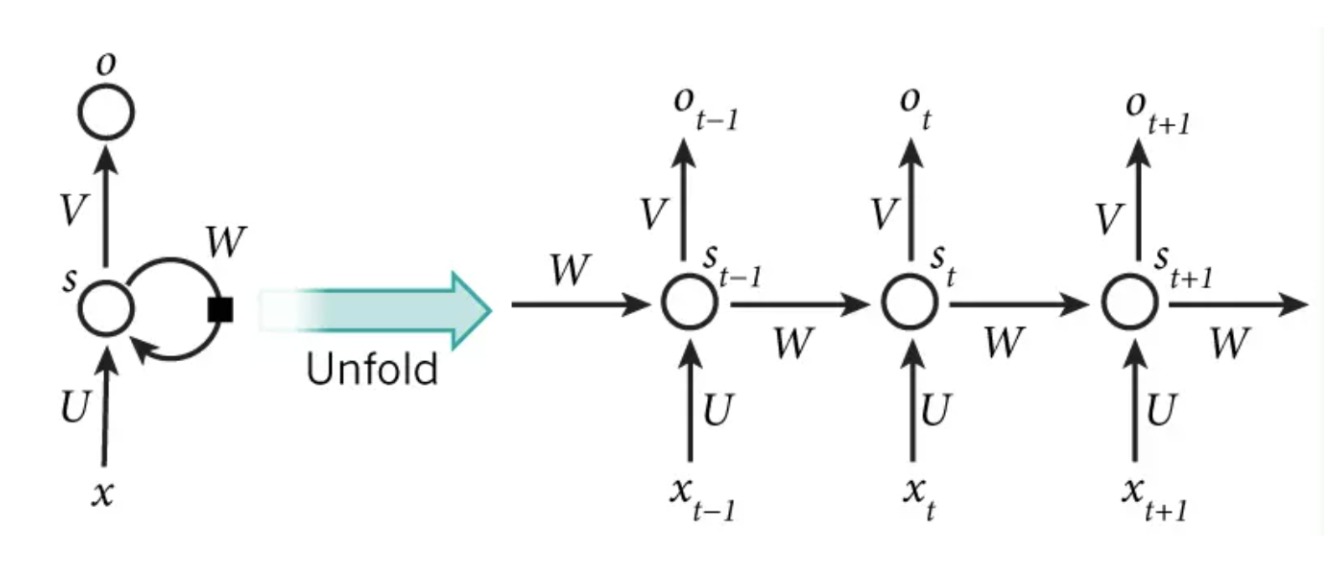
在RNN中,目前使用最广泛的模型便是LSTM(Long Short-Term Memory,长短时记忆模型)模型,该模型能够更好地建模长序列。
除RNN外,卷积神经网络(Convolutional Neural Networks,简称CNN)也被用来对文本进行建模。
Transformer
Transformer由且仅由Self-Attenion和Feed Forward Neural Network组成。
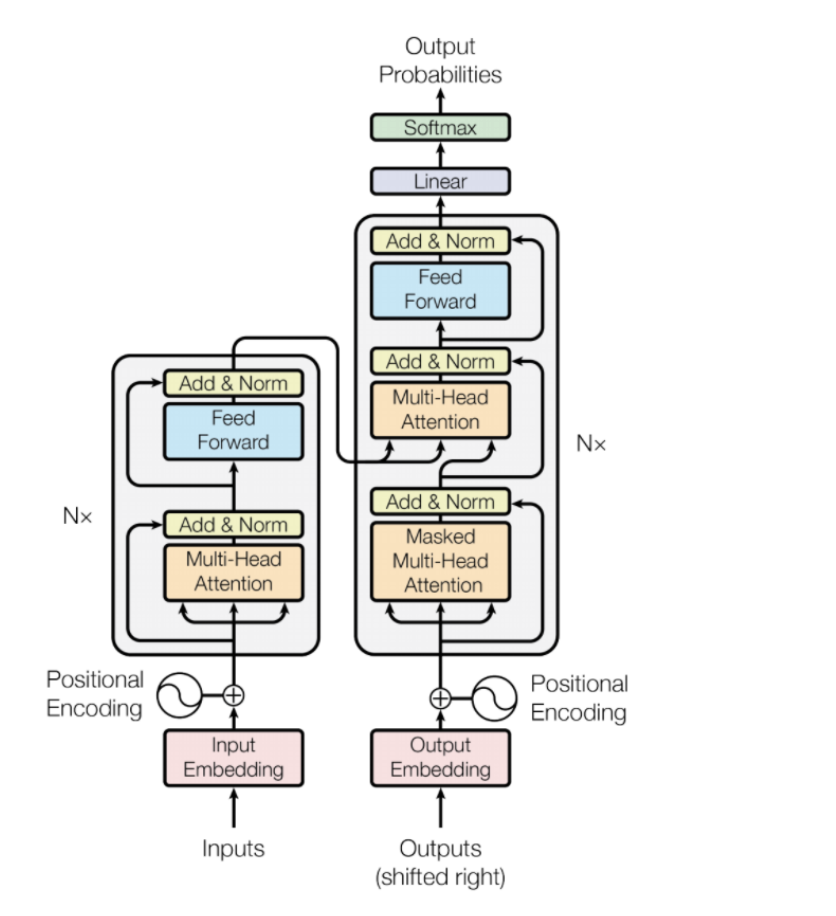
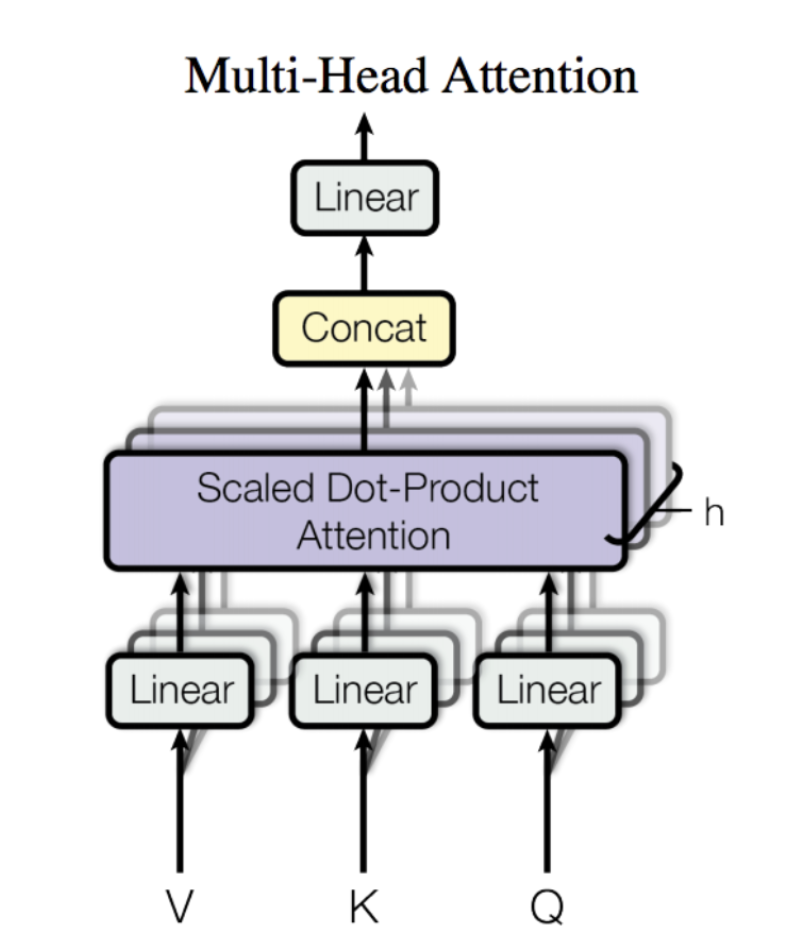
预训练模型
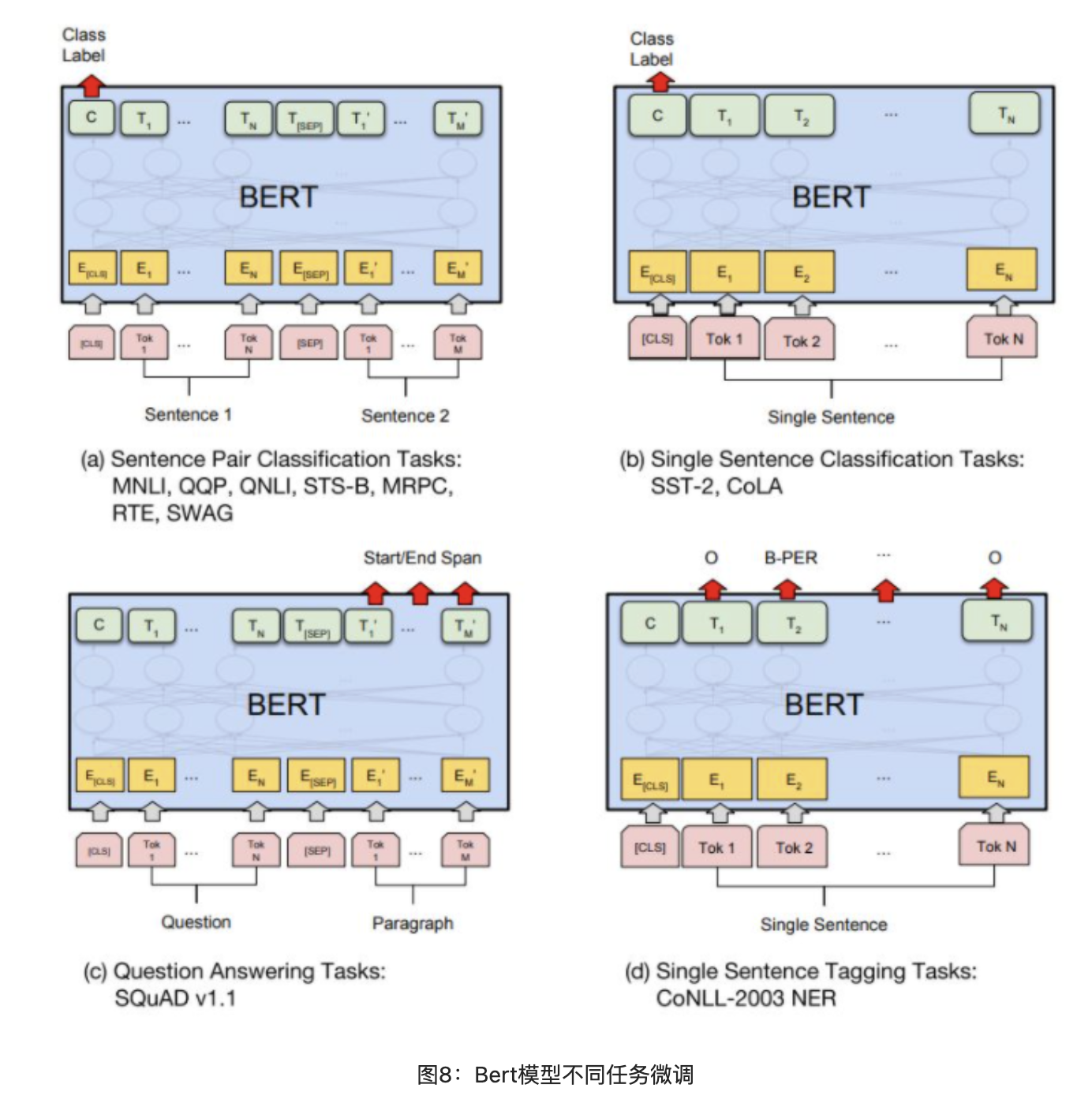
BERT
BERT,Bidirectional Encoder Representation from Transformers,其Encoder由双向Transformer构成。模型的主要创新点都在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
对比OpenAI GPT(Generative pre-trained transformer),BERT是双向的Transformer block连接,能更好的关注到上下文信息;对比ELMo,虽然都是双向的,但是Bert采用Transformer抽取特征效果要优于ELMo采用LSTM抽取特征。
Masked LM:
此任务预训练的目标就是语言模型,在训练过程中作者随机mask 15%的token,而不是把像cbow一样把每个词都预测一遍。最终的损失函数只计算被mask掉的那个token。
Next Sentence Prediction:
因为涉及到QA和NLI之类的任务,增加了第二个预训练任务,目的是让模型理解两个句子之间的联系。训练的输入是句子A和B,B有一半的几率是A的下一句,输入这两个句子,模型预测B是不是A的下一句。预训练的时候可以达到97-98%的准确度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号