
项目零星报错记录
1.href相对路径的使用
html页面经常有href相对路径的使用,例如:
<li><a href="/page/books?page={{ foo }}">{{ foo }}</a></li>
<li><a href="page/books?page={{ foo }}">{{ foo }}</a></li>
这里,
相对路径带斜杠时,表示该路径为当前资源路径的一个子路径,会在我们当前访问的路径后拼接这个href:http://127.0.0.1:8000/page/books/page/books/?page=10
相对路径带斜杠时,表示该路径根路径的一个子路径,所以就是:http://127.0.0.1:8000/page/books/?page=1
2.使用postman发送POST请求的时候报403 forbidden错
这节我遇到了一个错误,我使用postman发送POST请求的时候报403 forbidden错,参考了博客:Django CSRF cookie not set.错误 - 蜗牛findbug - 博客园 (cnblogs.com) ,代码里加上了红色框框部分,解决了这个问题:
|
1
2
|
from django.views.decorators.csrf import csrf_exempt@csrf_exempt |

这个问题是解决跨域请求,不建议使用这个注解绕过机制,我找了好久更好的解决方法也没有找到。
关于跨域问题可以参考:
Django Django中的@csrf_exempt是什么|极客教程 (geek-docs.com)
一招彻底解决Django跨域请求问题_django转发请求-CSDN博客
我觉得应该是我postman没有配置好出现了这个问题,但是postman发送get请求就没有这个问题。暂时我还没有找到postman改哪里可以不这样。
2023.12.20更新:
这个问题还可以有另一种解决方案,就是settings.py中有个中间件,对post请求做了一个拦截,注掉就可以了:

2023.12.26更新:更好的解决方法:
前端页面 {% csrf_token %}自动生成token
还有一个<input type="hidden"> 这个type除了text和password还可以是hidden,隐藏这个键值对。
3.Python3出现“No module named 'MySQLdb'“问题-以及使用PyMySQL连接数据库
Python3 与 Django 连接数据库,出现了报错:Error loading MySQLdb module: No module named 'MySQLdb'。原因如下: 在 python2 中,使用 pip install mysql-python 进行安装连接MySQL的库,使用时 import MySQLdb 进行使用; 在 python3 中,改变了连接库,改为了 pymysql 库,使用pip install pymysql 进行安装,直接导入即可使用; 但是在 Django 中, 连接数据库时使用的是 MySQLdb 库,这在与 python3 的合作中就会报以下错误了:
django.core.exceptions.ImproperlyConfigured: Error loading MySQLdb module: No module named 'MySQLdb'解决方法:在 __init__.py 文件中添加以下代码即可
import pymysql pymysql.install_as_MySQLdb()
参考:Python3出现“No module named 'MySQLdb'“问题-以及使用PyMySQL连接数据库-腾讯云开发者社区-腾讯云 (tencent.com)
4.Django3版本模型类中关于枚举类型的字段定义方法
class Status(models.TextChoices):
UNPUBLISHED = 'UN', 'Unpublished'
PUBLISHED = 'PB', 'Published'
class Book(models.Model):
status = models.CharField(
max_length=2,
choices=Status.choices,
default=Status.UNPUBLISHED,
)
class Pamphlet(models.Model):
status = models.CharField(
max_length=2,
choices=Status.choices,
default=Status.PUBLISHED,
)
参考:为什么Django 3后建议使用Field.choices枚举类型定义choices选项 - 知乎 (zhihu.com)
5. APIView.as_view() takes 1 positional argument but 2 were given
是路径写错,应该使用as_view()而不是as_view

6.Cannot call `.is_valid()` as no `data=` keyword argument was passed when ....
这个问题是出现在DRF组件反序列化的时候,在Django开发笔记(13)里也有提了一嘴在哪里出现的问题。原因是写这一句:serializer = self.get_serializer(data = request.data) ,不能写成serializer = self.get_serializer(request.data) 。
7.js调用函数加括号和不加括号的区别:
我是想做一个定时器案例,下面是正确的代码,有个关于加不加括号的思考,因为这个加了括号就跳不动了,不加括号才可以跳。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>定时器案例</title>
<script>
function setTime(){
var now = new Date();
var now_str = now.toLocaleString(); //toLocaleString() 根据本地时间把Date对象转换为字符串
console.log(now_str)
// 通过document获取标签
var element = document.getElementById("time_input");
console.log(element);
element.value = now_str; //这是属性不是方法,是给属性赋值
}
function start() {
setTime();
window.setInterval(setTime, 1000) //这里为什么不用setTime(),调用函数不用加括号吗,那上面那句为什么加括号
}
function end(){
}
</script>
</head>
<body>
<input type="text" value="" id="time_input"> <button onclick="start()">start</button><button onclick="end()">end</button>
</body>
</html>
带括号:只要是调用函数进行执行的,都带括号。返回的结果是返回值或者执行结果。当然,有些没有返回值,但已经执行了函数体内的行为,就是说,加括号的,就代表将会执行函数体代码
不带括号:不加括号的,都是把函数名称作为函数的指针,一个函数的名称就是这个函数的指针,此时不是得到函数的结果,因为不会运行函数体代码。它只是传递了函数体所在的地址位置,在需要的时候好找到函数体去执行。
function sayHello() {
alert('hello')
}
console.log(sayHello); //这样只会打印function sayHello() 空函数,不会弹出hello
function sayHello() {
alert('hello')
}
console.log(sayHello());// 这样就会弹出hello
8. AttributeError: module 'collections' has no attribute 'Callable' 【已解决】
项目环境是python3.11,深度学习的时候遇到的,
报错节选:
AttributeError: module 'collections' has no attribute 'Callable'
Process finished with exit code 1
Empty suite
我将最后一个报错文件中所有出现collections的地方都改成了collections.abc,就没事了。
参考:https://blog.csdn.net/weixin_44796285/article/details/127577058
9.AttributeError: module 'backend_interagg' has no attribute 'FigureCanvas'【已解决】
深度学习的时候遇到的,解决方式:
方法1 添加两行代码import matplotlib
matplotlib.use('TkAgg')
安装matplotlib3.5.0版本及其以下的
pip install matplotlib==3.5.0
参考:https://blog.csdn.net/qlkaicx/article/details/134068734
10.ValueError: not enough values to unpack【已解决】
出现在深度学习 函数返回值只有两个,却用三个变量接收。
x, y, coef = create_dataset()
11. plt.title函数设置中文标题,遇到中文不显示或者乱码问题【已解决】
出现在深度学习,绘制损失函数的时候。
解决方式1:(亲测好用)
修改matplotlib的rcParams:
可以通过修改matplotlib的rcParams来设置全局字体,确保中文能够正确显示。例如:
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置非中文字体为SimHei plt.rcParams['axes.unicode_minus'] = False # 解决保存图像时负号'-'显示为方块的问题
解决方式2:(没有尝试)
编辑matplotlibrc文件:
进入Python,找到matplotlib所在路径,然后编辑matplotlibrc文件,修改或添加字体设置。具体步骤包括找到font.family、font.sans-serif和axes.unicode_minus等选项,并进行相应的设置。最后,删除\~/.matplotlib目录下的两个文件并重启Python,以使更改生效。
12.Error: Django is not importable in this environment
这个问题是我电脑盘坏了重配所有东西后pycharm启动Django项目发现的。
解决方法:pycharm编译器,点file—>settings—>Project Interpreter,重新选择可用的python版本即可
13:使用JsonResponse时,报Object of type QuerySet is not JSON serializable。
需求背景:
ajax返回数据库所有数据,并用列表显示。
views.py中使用JsonResponse返回回调后的数据。总是会报错:
Object of type QuerySet is not JSON serializable。
查阅了一下JsonResponse需要的参数是字典,列表等。只需要将querySet转换为字典即可。
要将Queryset转换为字典,我们可以使用Django内置的方法values()或values_list()。values()返回一个包含字段和值的字典对象的Queryset列表,而values_list()返回一个包含元祖的Queryset列表。
如何将Queryset转换为字典:
def diffAnalysisResult(request):
print(request.POST) # <QueryDict: {'geneinput': ['AL078581.2']}>
symbol = request.POST.get("geneinput")
result = DiffAnalysisTable.objects.filter(symbol=symbol).values()
result_list = list(result)
print(JsonResponse(result_list))
return JsonResponse({'diff_return': result})
14.MIME 类型(“text/html”)不匹配(X-Content-Type-Options: nosniff
html里少加了一个form标签,加上就好了。全网这个报错我都没看明白,可能好多奇奇怪怪的都能报这个吧,不太懂。
15.
<script>
$("#tool1btn").click(function () {
if ($("#tool1select_gene").val() == "" && $("#tool1select_disease").val() == "") {
alert("Please select a dataset or gene name for analysis.")
} else {
$.ajax({
type: 'POST',
dataType: 'json',
data: {
symbol: $("#tool1select_gene").val(),
disease: $("#tool1select_disease").val()
},
url: '/cuDB/analysis/differential/result',
success: function (diff_return) {
const return_data = JSON.parse(JSON.stringify(diff_return));
$("#tool1table").bootstrapTable('destroy');
{#$("#tool1table").bootstrapTable('refresh'); //亲测重新刷新不可以,只能销毁 #}
$("#tool1table").bootstrapTable({
columns: [{
field: 'symbol',
title: 'Symbol',
sortable: true
}, {
field: 'disease',
title: 'Disease',
sortable: true
}, {
field: 'log_fc',
title: 'logFC',
sortable: true
}, {
field: 'p_value',
title: 'p value',
sortable: true
},
{
field: 'rid',
title: 'More<br>Details',
align: 'center',
{#formatter: detailFormatter,#}
},
],
data: return_data,
});
},
error: function () {
console.log("出问题咯error")
}
});
}
});
</script>
16:UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0xa1 in position 0: invalid start byte
在使用Python处理文本数据时,UnicodeDecodeError是一个相对常见的问题,它通常发生在尝试将字节序列解码为“utf-8”字符串时,但遇到了无法识别的字节。
参考:https://blog.csdn.net/FMC_WBL/article/details/136124112
解决方法
使用chardet库检测编码:chardet是一个非常有用的第三方库,可以帮助你检测未知编码的文本数据。首先安装chardet:
pip install chardet
然后使用chardet来检测文件编码:
import chardet
with open('example.txt', 'rb') as f:
result = chardet.detect(f.read())
encoding = result['encoding']
print("Detected encoding:", encoding)
使用检测到的编码重新读取文件:根据chardet检测到的编码来读取文件:
with open('example.txt', 'r', encoding=encoding) as f:
content = f.read()
print(content)
处理特定编码的数据:如果已知数据使用特定编码(例如GB2312、ISO-8859-1等),直接在读取数据时指定该编码:
with open('example.txt', 'r', encoding='gb2312') as f:
content = f.read()
17.URI is not registered (Settings | Languages & Frameworks | Schemas and DTDs)【已解决】

URI is not registered 错误通常是由于 IDEA 无法找到引用的 Schema 或 DTD,原因主要有二:
- 引用的 URI 有误,无法访问,建议仔细检查 URI。
- 引用的 URI 未在 IDEA 中注册。
如果是原因2.可以使用两种方式解决:
方式1:在 IDEA 打开 File --> Settings- -> Languages & Frameworks -->Schemas and DTDs,将标红的 URI 添加到 Ignored schemas and DTDs 中,保存即可完成注册。
方式2:借助IDEA快捷注册,将光标放到标红 URI 所在行,点击左侧出现的小红灯泡,选择 Fetch external resource 即可。
参考:https://blog.csdn.net/qq_45256357/article/details/140007538
18.项目调用其他接口生成一个svg文件,这个文件在外部其他接口直接运行生成就不报错,但是使用Python调用别人的接口生成的文件就报错。(未解决)
后来检查了两种方法生成的文件,发现可能是编码问题:

19.NotImplementedError:
Conversion rules for `rpy2.robjects` appear to be missing. Those rules are in a Python `contextvars.ContextVar`. This could be caused by multithreading code not passing context to the thread. Check rpy2's documentation about conversions.
NotImplementedError 的间歇性出现通常与以下因素有关:
-
多线程/异步环境:如果在多线程或异步代码中调用
generate_r_plot,可能导致上下文丢失,导致不一致的行为。 -
上下文管理:在某些情况下,未正确管理上下文会导致错误。例如,某些线程可能没有访问到正确的上下文变量。
-
R 和 rpy2 版本兼容性:不同版本之间的兼容性问题可能导致间歇性的错误。某些函数在不同版本下的实现可能不同。
-
变量的生命周期:确保在使用之前,所有传递给
globalenv的变量都是有效的。如果变量在某个线程中被修改或失效,可能会导致错误。 -
运行环境:在不同的环境(如 Jupyter Notebook 和标准 Python 脚本)中,行为可能会有所不同。
但是我尝试了使用上下文管理器,依然没有解决。
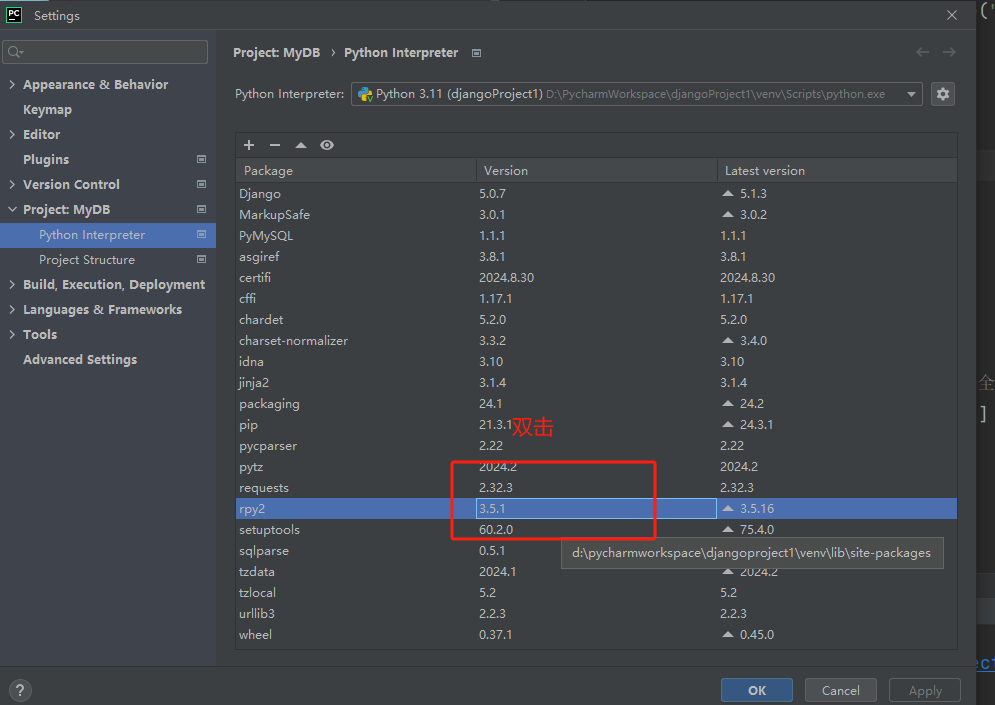
最终我将rpy2版本降级为3.5.1,解决了这个问题。
版本降级方法:
- 查看当前版本:
12
importrpy2print(rpy2.__version__) - 我的当前版本是3.5.16,我要降级为3.5.1。
-
打开 PyCharm,然后打开项目。
-
转到 "File" 菜单,选择 "Settings"(对于 macOS 用户,选择 "PyCharm" 菜单中的 "Preferences")。
-
在设置或首选项窗口中,选择 "Project: 项目名称",然后点击 "Project Interpreter" 下拉菜单。
-
在下拉菜单中,看到当前项目关联的解释器列表。选择想要从中改变版本
rpy2的解释器,双击。![]()
-
这个时候打开一个新窗口。选择特殊版本,选到3.5.1.
![]()
然后左下角install package。
- 依次ok。
注意:版本降级之后,可能还会出下面的错误16,再解决一下就好。
-

20.ztree和bootstraptable一起使用,导致bootstraptable无法正常显示问题
这里是引用比较混乱。要注意,每个js不要重复引用,我重复引用jquery,还导致了$table.bootstrapTable is not a function这个错。
这里,想要两个都显示正常,bootstraptable的js要在ztree的js之前加载。
最终我发现ztree和Datatable组合使用比和bootstraptable好解决,可能是datatable我用起来比较好用,我就把所有表格都换成datatable了。
21.pycharm下载包出现问题
终端pip下载requests包明明下载成功了,运行代码的时候还是显示‘’ModuleNotFoundError: No module named 'requests'”,最终参考 https://blog.csdn.net/qq_43267113/article/details/132913599
使用File-Setting,点击加号搜索要安装的包即可:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号