
白话深度学习与Tensorflow(一)
首先,相信很多人都还不知道tensor是什么,百度翻译出来的是张量,张肌,其实,这里的tensor就是向量的意思,tensorflow就是向量流、数据流的意思。
tensorflow是谷歌的深度学习开源框架,用于训练神经网络的。
Cap1:机器学习
*思路:
一个分类器区分普通邮件和垃圾邮件。通过给分类器输入很多垃圾邮件让分类器自身提取特征进行统计归纳,因此得以区分。在这个训练过程中,垃圾邮件被称为训练样本。总结出的判断标准称为分类模型。
*监督学习(有人参与训练机器):
①回归:(可称为解题方法也可说为学习方法)“由果朔因”。可分为线性回归(y=wx+b)与非线性回归(逻辑回归,输出是或否)
②分类:一个贴标签的过程
分类的训练过程和回归的训练过程一样,都是极为套路化的程序:
第一,输入样本和分类标签。
第二,建立映射假说的某个y=f{x) 的模型。
第三,求解出全局的损失函数 Loss 和待定系数 w 的映射关系, Loss=g(w)。
第四,通过迭代优化逐步降低 Loss,最终找到一个 w 能使召回率和精确率满足当前场 景需要。 注意,这里尤其指在验证数据集上的表现。(此过程在多个模型中会出现)
*非监督学习:
聚类:比较常用的聚类算法有 K-Means、DBSCAN等几种, 基本思路是利用每个向量之间的“距离”一一空间中的欧氏距离或者曼哈顿距离,从远近判断是否从属于同一类别。
**思考:聚类和分类的区别:
①聚类是非监督学习过程,分类是需要训练的监督学习过程
②聚类偏向运用算法将一堆数据进行分类,例如三个一维样本,180,179与150,会将180与179放为一类,150再放为一类。而分类是本身就是一种算法,经过训练后,输入一个样本,输出一个标签。
*综合应用:
①用卷积神经网络对图像进行风格处理
②无人驾驶汽车(训练量大才能保证万无一失)
Cap2:深度学习
*神经网络
*神经元
如果神经元要用y=wx+b来表示,
这种方式也是神经元最核心部分对 x 所做的线性处理,其中 x 是一个 1 x n 的矩阵,而 w 是一个 n x 1 的权重矩阵, b 是偏置项。(什么玩意儿。。)


以上操作简单来说,就是神经元里面包含了一个运算式子y=wx+b
我可以建立n维输入项,不再仅仅只是一维,即我可以输入多个x,x在实际问题中可代表不同的内容,w是权重,可以理解为比例。
输入五个样本向量数据,最后输出一个值代表客户评价分数。
🔺在上述例子中,w和x是已知的。那么问题来了,x是客观存在的数据,那权重是由谁规定的呢?
如果公式真的存在,十有八九也是“逆推”出来的。也就是此时,客户评价分数是已知的。

神经元通常由两个部分组成,一个是“线性模型”,另一个是“激励函数”。激励函数在一个神经元当中跟随在y=wx+b 函数之后,用来加入一些非线性的因素。
*激励函数
当完整的神经元被定义的时候,它在神经网络中的工作状态应该是这样的。
x输入经过一个线性模型后出来f(x),再经过激励函数的运算得出结果
下面介绍一些“激励函数”
1.Sigmoid函数
定义: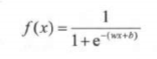
或者也可以写成: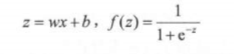
**思考:
为什么要用“激励函数”来加入一些非线性元素?
是为了防止严重欠拟合的现象出现,只有线性关系会导致严重欠拟合的情况出现
2.Tanh函数:在循环神经网络RNN处有所涉及
3.ReLU函数:是目前大部分卷积神经网络CNN中喜欢使用的激励函数
4.Linear函数
*神经网络
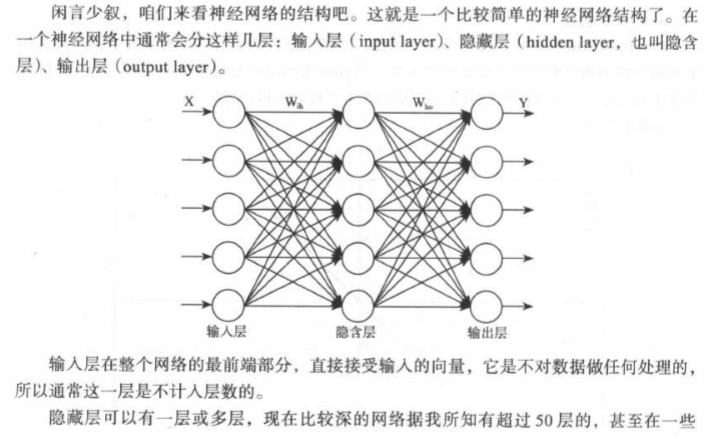

*深度神经网络
这里所谓的深度学习其实就是基于深度神经网络的学习
深度学习的优势:
①不用再提取特征
②处理线性不可分问题
深度学习的应用:
①围棋机器人——AlphaGo
②被教坏的女孩——Tai.ai

 浙公网安备 33010602011771号
浙公网安备 33010602011771号