openseek-学习与复现记录
OpenSeek 致力于联合全球开源社区,推动算法、数据和系统方面的协作创新,目标是开发超越 DeepSeek 的下一代模型。
📌 项目概况
OpenSeek 是由北京人工智能研究院 (BAAI) 发起的开源项目,旨在联合全球开源社区,推动算法、数据和系统方面的协作创新,开发超越 DeepSeek 的下一代模型。该项目从 Bigscience 和 OPT 等大型模型计划中汲取灵感,致力于构建独立的开源算法创新系统。自 DeepSeek 模型开源以来,学术界已经看到了许多算法改进和突破,但这些创新往往缺乏完整的代码实现、必要的计算资源和高质量的数据支持。OpenSeek 项目旨在通过联合开源社区探索高质量的数据集构建机制,推动整个大型模型训练管道的开源,构建创新的训练和推理代码,以支持除 Nvidia 之外的各种 AI 芯片,并推动自主技术创新和应用开发。
Objectives of OpenSeek: OpenSeek 的目标:
-
高级数据技术 :应对获取高质量数据的挑战。
-
多种 AI 设备支持 :减少对特定芯片的依赖,提高模型的通用性和适应性。
-
标准化的 LLM 训练基线 :通过开源协作促进独立的算法创新和技术共享。
Project: https://github.com/orgs/FlagAI-Open/projects/1
项目名称:https://github.com/orgs/FlagAI-Open/projects/1
- datasets: https://huggingface.co/datasets/BAAI/OpenSeek-Pretrain-100B/
- frame:https://github.com/FlagAI-Open/OpenSeek
- training:https://github.com/FlagOpen/FlagScale
- other:https://github.com/FlagAI-Open/FlagAI
环境安装
安装Flagscale 环境(这里推荐使用 docker)
# Pull images
docker pull openseek2025/openseek:flagscale-20250527
# Clone the repository
git clone https://github.com/FlagOpen/FlagScale.git
进入docker image进行训练
docker_image=openseek2025/openseek:flagscale-20250527
docker run -it --gpus all --ipc=host --shm-size=8g -v /data2:/data2 $docker_image /bin/bash
运行baseline
openseek-baseline 作为 PAZHOU 算法竞赛的基线,也用于评估 openseek 中的 PR。Openseek-baseline 是一个标准化的 LLM 训练和评估管道,它由一个 100B 数据集 、 一个训练代码 、wandb、 检查点和评估结果组成。
数据准备
git lfs install
git clone https://huggingface.co/datasets/BAAI/OpenSeek-Pretrain-100B
如果网络不稳定,可以考虑使用 modelscope
pip install modelscope
modelscope download --dataset BAAI/OpenSeek-Pretrain-100B --local_dir ./dir
下载完成,文件大小约为413.57GB.
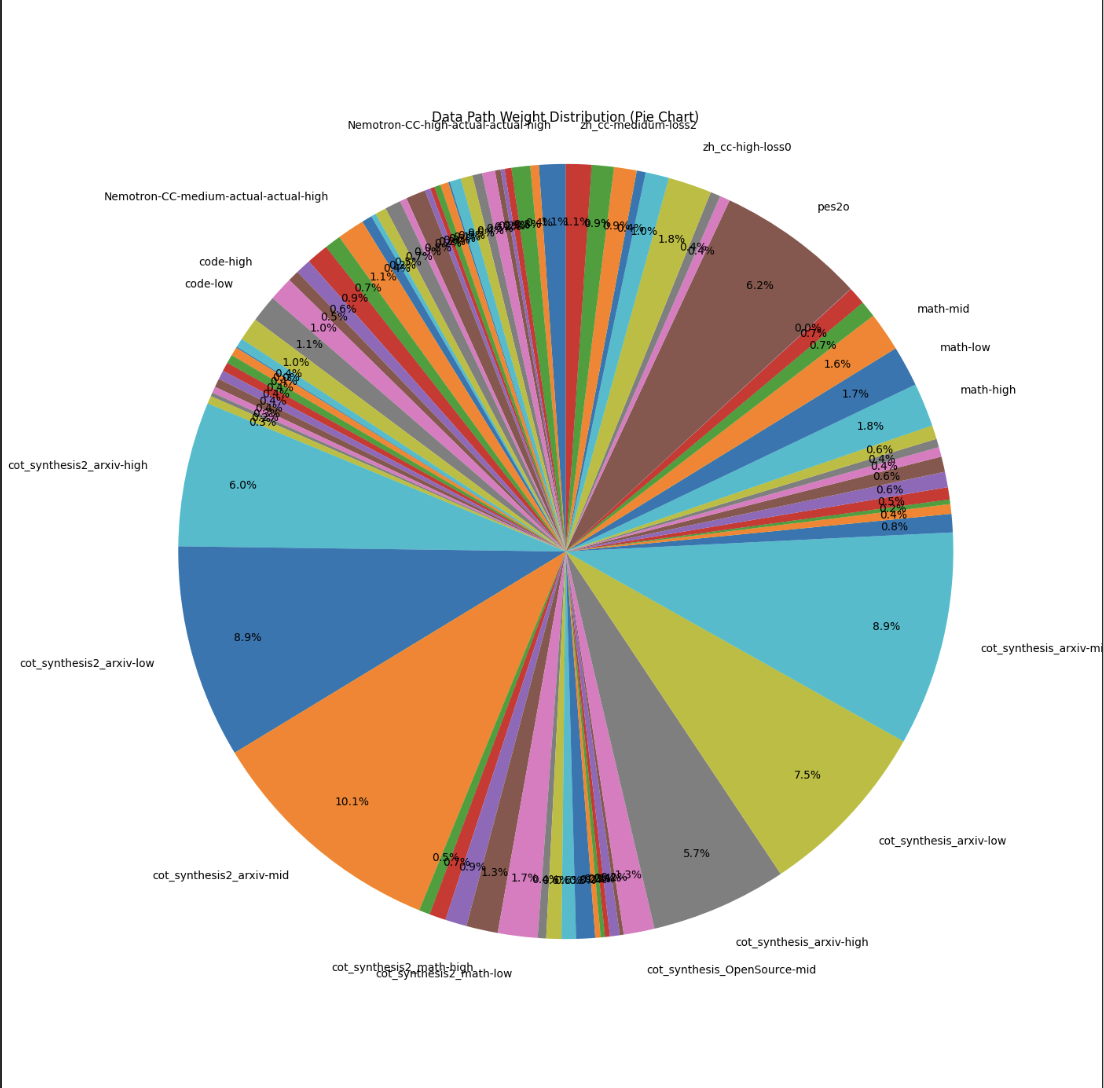
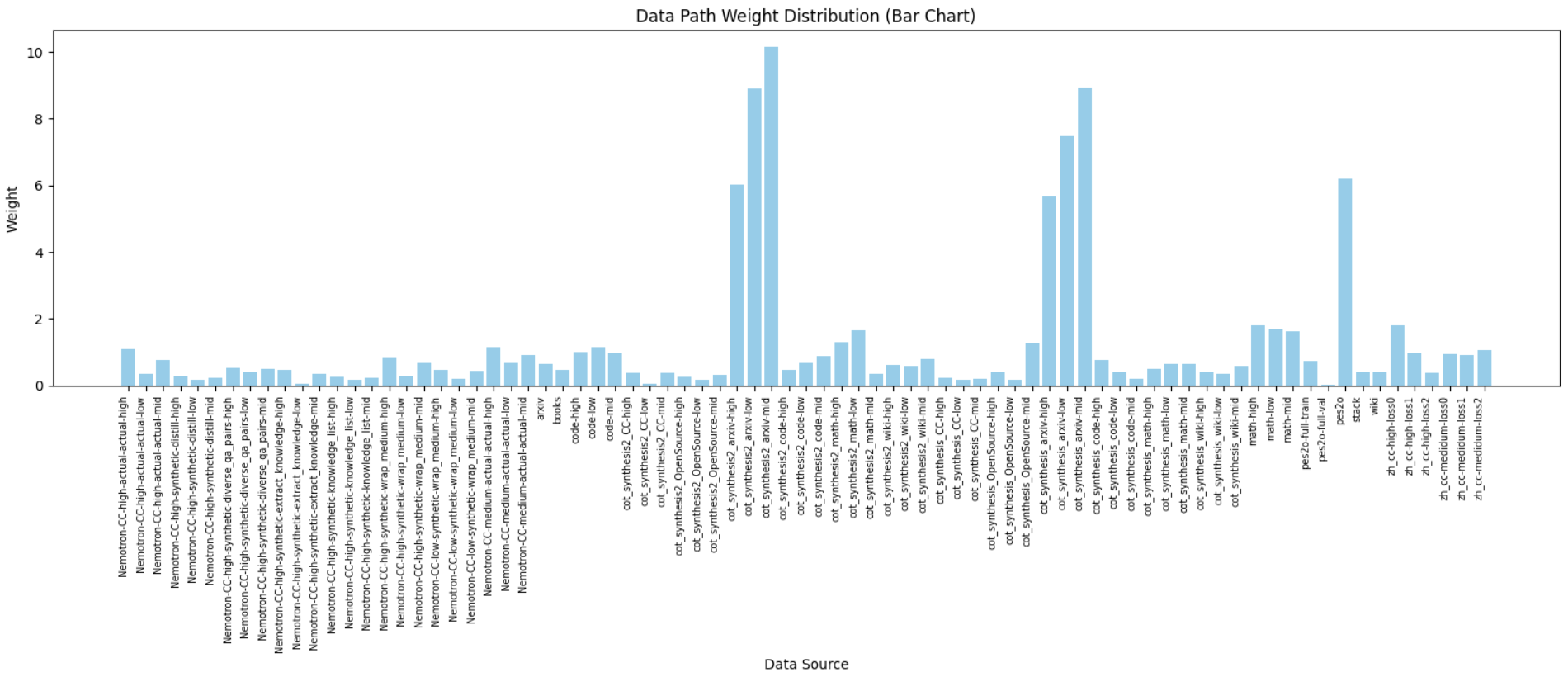
OpenSeek-Pretrain-100B 数据分布:
| Name | Tokens | Tokens(B) |
|---|---|---|
| Nemotron-CC-high-actual-actual-high | 1140543860 | 1.14 |
| Nemotron-CC-high-actual-actual-low | 368646238 | 0.37 |
| Nemotron-CC-high-actual-actual-mid | 801213010 | 0.80 |
| Nemotron-CC-high-synthetic-distill-high | 294569308 | 0.29 |
| Nemotron-CC-high-synthetic-distill-low | 172342068 | 0.17 |
| Nemotron-CC-high-synthetic-distill-mid | 240998642 | 0.24 |
| Nemotron-CC-high-synthetic-diverse_qa_pairs-high | 556137649 | 0.56 |
| Nemotron-CC-high-synthetic-diverse_qa_pairs-low | 418742390 | 0.42 |
| Nemotron-CC-high-synthetic-diverse_qa_pairs-mid | 515733187 | 0.52 |
| Nemotron-CC-high-synthetic-extract_knowledge-high | 475714119 | 0.48 |
| Nemotron-CC-high-synthetic-extract_knowledge-low | 68996838 | 0.07 |
| Nemotron-CC-high-synthetic-extract_knowledge-mid | 353316407 | 0.35 |
| Nemotron-CC-high-synthetic-knowledge_list-high | 268953064 | 0.27 |
| Nemotron-CC-high-synthetic-knowledge_list-low | 187973360 | 0.19 |
| Nemotron-CC-high-synthetic-knowledge_list-mid | 238373108 | 0.24 |
| Nemotron-CC-high-synthetic-wrap_medium-high | 848837296 | 0.85 |
| Nemotron-CC-high-synthetic-wrap_medium-low | 295324405 | 0.30 |
| Nemotron-CC-high-synthetic-wrap_medium-mid | 687328353 | 0.69 |
| Nemotron-CC-low-synthetic-wrap_medium-high | 479896420 | 0.48 |
| Nemotron-CC-low-synthetic-wrap_medium-low | 206574167 | 0.21 |
| Nemotron-CC-low-synthetic-wrap_medium-mid | 444865784 | 0.44 |
| Nemotron-CC-medium-actual-actual-high | 1174405205 | 1.17 |
| Nemotron-CC-medium-actual-actual-low | 698884310 | 0.70 |
| Nemotron-CC-medium-actual-actual-mid | 945401567 | 0.95 |
| arxiv | 660912931 | 0.66 |
| books | 483917796 | 0.48 |
| code-high | 1040945650 | 1.04 |
| code-low | 1175000655 | 1.18 |
| code-mid | 996826302 | 1.00 |
| cot_synthesis2_CC-high | 386941302 | 0.39 |
| cot_synthesis2_CC-low | 51390680 | 0.05 |
| cot_synthesis2_CC-mid | 1885475230 | 1.89 |
| cot_synthesis2_OpenSource-high | 265167656 | 0.27 |
| cot_synthesis2_OpenSource-low | 168830028 | 0.17 |
| cot_synthesis2_OpenSource-mid | 334976884 | 0.33 |
| cot_synthesis2_arxiv-high | 12894983685 | 12.89 |
| cot_synthesis2_arxiv-low | 9177670132 | 9.18 |
| cot_synthesis2_arxiv-mid | 10446468216 | 10.45 |
| cot_synthesis2_code-high | 473767419 | 0.47 |
| cot_synthesis2_code-low | 706636812 | 0.71 |
| cot_synthesis2_code-mid | 926436168 | 0.93 |
| cot_synthesis2_math-high | 1353517224 | 1.35 |
| cot_synthesis2_math-low | 1703361358 | 1.70 |
| cot_synthesis2_math-mid | 364330324 | 0.36 |
| cot_synthesis2_wiki-high | 650684154 | 0.65 |
| cot_synthesis2_wiki-low | 615978070 | 0.62 |
| cot_synthesis2_wiki-mid | 814947142 | 0.81 |
| cot_synthesis_CC-high | 229324269 | 0.23 |
| cot_synthesis_CC-low | 185148748 | 0.19 |
| cot_synthesis_CC-mid | 210471356 | 0.21 |
| cot_synthesis_OpenSource-high | 420505110 | 0.42 |
| cot_synthesis_OpenSource-low | 170987708 | 0.17 |
| cot_synthesis_OpenSource-mid | 1321855051 | 1.32 |
| cot_synthesis_arxiv-high | 5853027309 | 5.85 |
| cot_synthesis_arxiv-low | 7718911399 | 7.72 |
| cot_synthesis_arxiv-mid | 9208148090 | 9.21 |
| cot_synthesis_code-high | 789672525 | 0.79 |
| cot_synthesis_code-low | 417526994 | 0.42 |
| cot_synthesis_code-mid | 197436971 | 0.20 |
| cot_synthesis_math-high | 522900778 | 0.52 |
| cot_synthesis_math-low | 663320643 | 0.66 |
| cot_synthesis_math-mid | 660137084 | 0.66 |
| cot_synthesis_wiki-high | 412152225 | 0.41 |
| cot_synthesis_wiki-low | 367306600 | 0.37 |
| cot_synthesis_wiki-mid | 594421619 | 0.59 |
| math-high | 1871864190 | 1.87 |
| math-low | 1745580082 | 1.75 |
| math-mid | 1680811027 | 1.68 |
| pes2o | 6386997158 | 6.39 |
| pes2o-full-train | 1469110938 | 1.47 |
| pes2o-full-val | 14693152 | 0.01 |
| stack | 435813429 | 0.44 |
| wiki | 433002447 | 0.43 |
| zh_cc-high-loss0 | 1872431176 | 1.87 |
| zh_cc-high-loss1 | 1007405788 | 1.01 |
| zh_cc-high-loss2 | 383830893 | 0.38 |
| zh_cc-medidum-loss0 | 978118384 | 0.98 |
| zh_cc-medidum-loss1 | 951741139 | 0.95 |
| zh_cc-medidum-loss2 | 1096769115 | 1.10 |
根据 yaml 中的 radio 进行可视化
训练
确保您已完成上一节中所述的环境安装和配置,并且您的 OpenSeek 文件夹应如下所示:
OpenSeek
├── OpenSeek-Pretrain-100B (Dataset directory for downloaded datasets.)
├── FlagScale (FlagScale directory cloned from GitHub.)
├── OpenSeek-Small-v1-Baseline (Experiment directory will be created automatically and contains logs and model checkpoints etc.)
├── ...
接下来,您可以使用一个简单的命令运行基线:
bash openseek/baseline/run_exp.sh start
这个命令,主要是根据模型配置和数据配置来生成相应的训练cmds脚本。
其中,模型配置如下:
- 注意,envs 中默认使用单卡进行训练,如果需要修改为多卡,参照以下,修改 nnodes、nproc_per_node、VISIBLE_DEVICES、DEVICE_MAX_CONNECTIONS 即可。
- 对于训练cmds,如果默认使用的是docker-image,应该修改
before_start:source /root/miniconda3/bin/activate flagscale-train,通过这里配置,可以去修改 conda 的环境,以及进入的 conda 环境。
# DeepSeek 1_4B, 0_4A Model
defaults:
- _self_
- train: train_deepseek_v3_1_4b.yaml
experiment:
exp_name: OpenSeek-Small-v1-Baseline
dataset_base_dir: ../OpenSeek-Pretrain-100B
seed: 42
save_steps: 600
load: null
exp_dir: ${experiment.exp_name}
ckpt_format: torch
task:
type: train
backend: megatron
entrypoint: flagscale/train/train_gpt.py
runner:
no_shared_fs: false
backend: torchrun
rdzv_backend: static
ssh_port: 22
# nnodes: 1
nnodes: 8
# nproc_per_node: 1
nproc_per_node: 8
hostfile: null
cmds:
# before_start: "ulimit -n 1048576 && source /root/miniconda3/bin/activate flagscale"
before_start: "ulimit -n 1048576 && source /root/miniconda3/bin/activate flagscale-train"
# before_start: "ulimit -n 1048576 && source /data/anaconda3/bin/activate flagscale-train"
envs:
# VISIBLE_DEVICES: 0
# DEVICE_MAX_CONNECTIONS: 1
VISIBLE_DEVICES: 0,1,2,3,4,5,6,7
DEVICE_MAX_CONNECTIONS: 8
action: run
hydra:
run:
dir: ${experiment.exp_dir}/hydra
如何验证程序是否正常运行
执行 bash openseek/baseline/run_exp.sh start 后,您可以按照以下步骤确认您的程序是否按预期运行。
-
导航到 OpenSeek 根目录 。您会注意到,在此目录中创建了一个名为
OpenSeek-Small-v1-Baseline的新文件夹。这是 log 目录。 -
您可以通过使用文本编辑器(如
vim)打开OpenSeek-Small-v1-Baseline/logs/host_0_localhost.output来查看程序的日志和错误消息:vi OpenSeek-Small-v1-Baseline/logs/host_0_localhost.outputW0627 15:58:45.576000 4413 site-packages/torch/distributed/run.py:792] W0627 15:58:45.576000 4413 site-packages/torch/distributed/run.py:792] ***************************************** W0627 15:58:45.576000 4413 site-packages/torch/distributed/run.py:792] Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed. W0627 15:58:45.576000 4413 site-packages/torch/distributed/run.py:792] ***************************************** [default7]:/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/training/arguments.py:819: UserWarning: Disabling sequence parallelism because tensor model parallelism is disabled [default7]: warnings.warn("Disabling sequence parallelism because tensor model parallelism is disabled") [default1]:/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/training/arguments.py:819: UserWarning: Disabling sequence parallelism because tensor model parallelism is disabled [default1]: warnings.warn("Disabling sequence parallelism because tensor model parallelism is disabled") [default3]:/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/training/arguments.py:819: UserWarning: Disabling sequence parallelism because tensor model parallelism is disabled [default3]: warnings.warn("Disabling sequence parallelism because tensor model parallelism is disabled") [default2]:/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/training/arguments.py:819: UserWarning: Disabling sequence parallelism because tensor model parallelism is disabled [default2]: warnings.warn("Disabling sequence parallelism because tensor model parallelism is disabled") [default0]:/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/training/arguments.py:819: UserWarning: Disabling sequence parallelism because tensor model parallelism is disabled [default0]: warnings.warn("Disabling sequence parallelism because tensor model parallelism is disabled") [default6]:/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/training/arguments.py:819: UserWarning: Disabling sequence parallelism because tensor model parallelism is disabled [default6]: warnings.warn("Disabling sequence parallelism because tensor model parallelism is disabled") [default7]:[2025-06-27 15:58:51,700] [INFO] [real_accelerator.py:254:get_accelerator] Setting ds_accelerator to cuda (auto detect) [default3]:[2025-06-27 15:58:52,186] [INFO] [real_accelerator.py:254:get_accelerator] Setting ds_accelerator to cuda (auto detect) [default1]:[2025-06-27 15:58:52,148] [INFO] [real_accelerator.py:254:get_accelerator] Setting ds_accelerator to cuda (auto detect) [default6]:[2025-06-27 15:58:52,308] [INFO] [real_accelerator.py:254:get_accelerator] Setting ds_accelerator to cuda (auto detect) [default2]:[2025-06-27 15:58:52,318] [INFO] [real_accelerator.py:254:get_accelerator] Setting ds_accelerator to cuda (auto detect) [default5]:[2025-06-27 15:58:52,392] [INFO] [real_accelerator.py:254:get_accelerator] Setting ds_accelerator to cuda (auto detect) [default0]:[2025-06-27 15:58:52,401] [INFO] [real_accelerator.py:254:get_accelerator] Setting ds_accelerator to cuda (auto detect) [default4]:[2025-06-27 15:58:52,602] [INFO] [real_accelerator.py:254:get_accelerator] Setting ds_accelerator to cuda (auto detect) [default0]:using world size: 8, data-parallel size: 8, context-parallel size: 1, hierarchical context-parallel sizes: Nonetensor-model-parallel size: 1, encoder-tensor-model-parallel size: 0, pipeline-model-parallel size: 1, encoder-pipeline-model-parallel size: 0 [default0]:WARNING: overriding default arguments for tokenizer_type:GPT2BPETokenizer with tokenizer_type:QwenTokenizerFS [default0]:Number of virtual stages per pipeline stage: None [default0]:using torch.bfloat16 for parameters ... [default0]:------------------------ arguments ------------------------ [default0]: account_for_embedding_in_pipeline_split ......... False [default0]: account_for_loss_in_pipeline_split .............. False [default0]: accumulate_allreduce_grads_in_fp32 .............. True [default0]: adam_beta1 ...................................... 0.9 [default0]: adam_beta2 ...................................... 0.95 [default0]: adam_eps ........................................ 1e-08 [default0]: add_bias_linear ................................. False [default0]: add_position_embedding .......................... False [default0]: add_qkv_bias .................................... False [default0]: adlr_autoresume ................................. False [default0]: adlr_autoresume_interval ........................ 1000 [default0]: align_grad_reduce ............................... True [default0]: align_param_gather .............................. False [default0]: app_tag_run_name ................................ None [default0]: app_tag_run_version ............................. 0.0.0 [default0]: apply_layernorm_1p .............................. False [default0]: apply_query_key_layer_scaling ................... False [default0]: apply_residual_connection_post_layernorm ........ False [default0]: apply_rope_fusion ............................... False [default0]: apply_sft_dataset_separated_loss_mask_if_existed False [default0]: async_save ...................................... None [default0]: async_tensor_model_parallel_allreduce ........... True [default0]: attention_backend ............................... AttnBackend.auto [default0]: attention_dropout ............................... 0.0 [default0]: attention_softmax_in_fp32 ....................... True [default0]: auto_detect_ckpt_format ......................... False [default0]: auto_skip_spiky_loss ............................ False [default0]: auto_tune ....................................... False [default0]: barrier_with_L1_time ............................ True [default0]: bert_binary_head ................................ True [default0]: bert_embedder_type .............................. megatron [default0]: bert_load ....................................... None [default0]: bf16 ............................................ True [default0]: bias_dropout_fusion ............................. True [default0]: bias_gelu_fusion ................................ False [default0]: bias_swiglu_fusion .............................. True [default0]: biencoder_projection_dim ........................ 0 [default0]: biencoder_shared_query_context_model ............ False [default0]: block_data_path ................................. None [default0]: calc_ft_timeouts ................................ False [default0]: calculate_per_token_loss ........................ False [default0]: check_for_large_grads ........................... False [default0]: check_for_nan_in_loss_and_grad .................. True [default0]: check_for_spiky_loss ............................ False [default0]: check_weight_hash_across_dp_replicas_interval ... None [default0]: ckpt_assume_constant_structure .................. False [default0]: ckpt_convert_format ............................. None [default0]: ckpt_convert_save ............................... None [default0]: ckpt_convert_update_legacy_dist_opt_format ...... False [default0]: ckpt_format ..................................... torch [default0]: ckpt_fully_parallel_load ........................ False [default0]: ckpt_fully_parallel_save ........................ True [default0]: ckpt_fully_parallel_save_deprecated ............. False [default0]: ckpt_step ....................................... None [default0]: classes_fraction ................................ 1.0 [default0]: clip_grad ....................................... 1.0 [default0]: clone_scatter_output_in_embedding ............... True [default0]: config_logger_dir ............................... [default0]: consumed_train_samples .......................... 0 [default0]: consumed_valid_samples .......................... 0 [default0]: context_parallel_size ........................... 1 [default0]: cp_comm_type .................................... ['p2p'] [default0]: create_attention_mask_in_dataloader ............. True [default0]: cross_entropy_fusion_impl ....................... native [default0]: cross_entropy_loss_fusion ....................... False [default0]: cuda_graph_scope ................................ full [default0]: cuda_graph_warmup_steps ......................... 3 [default0]: data_args_path .................................. None [default0]: data_cache_path ................................. None [default0]: data_parallel_random_init ....................... False [default0]: data_parallel_sharding_strategy ................. no_shard [default0]: data_parallel_size .............................. 8 [default0]: data_path ....................................... ['1.1068', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-actual-actual-high/part_142_text_document', '0.3577', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-actual-actual-low/part_62_text_document', '0.7775', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-actual-actual-mid/part_189_text_document', '0.2859', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-distill-high/part_76_text_document', '0.1672', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-distill-low/part_124_text_document', '0.2339', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-distill-mid/part_29_text_document', '0.5397', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-diverse_qa_pairs-high/part_244_text_document', '0.4064', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-diverse_qa_pairs-low/part_150_text_document', '0.5005', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-diverse_qa_pairs-mid/part_444_text_document', '0.4616', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-extract_knowledge-high/part_498_text_document', '0.067', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-extract_knowledge-low/part_10_text_document', '0.3429', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-extract_knowledge-mid/part_144_text_document', '0.261', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-knowledge_list-high/part_86_text_document', '0.1824', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-knowledge_list-low/part_133_text_document', '0.2313', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-knowledge_list-mid/part_139_text_document', '0.8237', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-wrap_medium-high/part_47_text_document', '0.2866', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-wrap_medium-low/part_11_text_document', '0.667', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-wrap_medium-mid/part_97_text_document', '0.4657', '../OpenSeek-Pretrain-100B/Nemotron-CC-low-synthetic-wrap_medium-high/part_43_text_document', '0.2005', '../OpenSeek-Pretrain-100B/Nemotron-CC-low-synthetic-wrap_medium-low/part_10_text_document', '0.4317', '../OpenSeek-Pretrain-100B/Nemotron-CC-low-synthetic-wrap_medium-mid/part_164_text_document', '1.1397', '../OpenSeek-Pretrain-100B/Nemotron-CC-medium-actual-actual-high/part_92_text_document', '0.6782', '../OpenSeek-Pretrain-100B/Nemotron-CC-medium-actual-actual-low/part_113_text_document', '0.9175', '../OpenSeek-Pretrain-100B/Nemotron-CC-medium-actual-actual-mid/part_563_text_document', '0.6414', '../OpenSeek-Pretrain-100B/arxiv/007_00000_text_document', '0.4696', '../OpenSeek-Pretrain-100B/books/016_00007_text_document', '1.0102', '../OpenSeek-Pretrain-100B/code-high/part_13_text_document', '1.1403', '../OpenSeek-Pretrain-100B/code-low/part_36_text_document', '0.9674', '../OpenSeek-Pretrain-100B/code-mid/part_37_text_document', '0.3755', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-high/23_text_document', '0.0499', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-low/51_text_document', '0.3608', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/118_text_document', '0.3623', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/176_text_document', '0.3704', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/256_text_document', '0.3733', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/320_text_document', '0.3631', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/32_text_document', '0.2573', '../OpenSeek-Pretrain-100B/cot_synthesis2_OpenSource-high/1_text_document', '0.1638', '../OpenSeek-Pretrain-100B/cot_synthesis2_OpenSource-low/2_text_document', '0.3251', '../OpenSeek-Pretrain-100B/cot_synthesis2_OpenSource-mid/3_text_document', '6.0237', '../OpenSeek-Pretrain-100B/cot_synthesis2_arxiv-high/2_text_document', '8.9063', '../OpenSeek-Pretrain-100B/cot_synthesis2_arxiv-low/1_text_document', '10.1376', '../OpenSeek-Pretrain-100B/cot_synthesis2_arxiv-mid/2_text_document', '0.4598', '../OpenSeek-Pretrain-100B/cot_synthesis2_code-high/4_text_document', '0.6857', '../OpenSeek-Pretrain-100B/cot_synthesis2_code-low/6_text_document', '0.899', '../OpenSeek-Pretrain-100B/cot_synthesis2_code-mid/23_text_document', '1.3135', '../OpenSeek-Pretrain-100B/cot_synthesis2_math-high/12_text_document', '1.653', '../OpenSeek-Pretrain-100B/cot_synthesis2_math-low/3_text_document', '0.3536', '../OpenSeek-Pretrain-100B/cot_synthesis2_math-mid/5_text_document', '0.6314', '../OpenSeek-Pretrain-100B/cot_synthesis2_wiki-high/5_text_document', '0.5978', '../OpenSeek-Pretrain-100B/cot_synthesis2_wiki-low/5_text_document', '0.7909', '../OpenSeek-Pretrain-100B/cot_synthesis2_wiki-mid/4_text_document', '0.2225', '../OpenSeek-Pretrain-100B/cot_synthesis_CC-high/74_text_document', '0.1797', '../OpenSeek-Pretrain-100B/cot_synthesis_CC-low/54_text_document', '0.2042', '../OpenSeek-Pretrain-100B/cot_synthesis_CC-mid/275_text_document', '0.4081', '../OpenSeek-Pretrain-100B/cot_synthesis_OpenSource-high/4_text_document', '0.1659', '../OpenSeek-Pretrain-100B/cot_synthesis_OpenSource-low/2_text_document', '1.2828', '../OpenSeek-Pretrain-100B/cot_synthesis_OpenSource-mid/6_text_document', '5.68', '../OpenSeek-Pretrain-100B/cot_synthesis_arxiv-high/2_text_document', '7.4907', '../OpenSeek-Pretrain-100B/cot_synthesis_arxiv-low/1_text_document', '8.9359', '../OpenSeek-Pretrain-100B/cot_synthesis_arxiv-mid/1_text_document', '0.7663', '../OpenSeek-Pretrain-100B/cot_synthesis_code-high/13_text_document', '0.4052', '../OpenSeek-Pretrain-100B/cot_synthesis_code-low/9_text_document', '0.1916', '../OpenSeek-Pretrain-100B/cot_synthesis_code-mid/6_text_document', '0.5074', '../OpenSeek-Pretrain-100B/cot_synthesis_math-high/11_text_document', '0.6437', '../OpenSeek-Pretrain-100B/cot_synthesis_math-low/11_text_document', '0.6406', '../OpenSeek-Pretrain-100B/cot_synthesis_math-mid/29_text_document', '0.4', '../OpenSeek-Pretrain-100B/cot_synthesis_wiki-high/4_text_document', '0.3564', '../OpenSeek-Pretrain-100B/cot_synthesis_wiki-low/6_text_document', '0.5768', '../OpenSeek-Pretrain-100B/cot_synthesis_wiki-mid/3_text_document', '1.8165', '../OpenSeek-Pretrain-100B/math-high/part_04_text_document', '1.694', '../OpenSeek-Pretrain-100B/math-low/part_10_text_document', '1.6311', '../OpenSeek-Pretrain-100B/math-mid/part_07_text_document', '0.687', '../OpenSeek-Pretrain-100B/pes2o-full-train/train-0041-of-0136_text_document', '0.7387', '../OpenSeek-Pretrain-100B/pes2o-full-train/train-0125-of-0136_text_document', '0.0143', '../OpenSeek-Pretrain-100B/pes2o-full-val/valid-0034-of-0060_text_document', '6.1982', '../OpenSeek-Pretrain-100B/pes2o/pubmedcentral_3_text_document', '0.4229', '../OpenSeek-Pretrain-100B/stack/018_00000_text_document', '0.4202', '../OpenSeek-Pretrain-100B/wiki/012_00000_text_document', '1.8171', '../OpenSeek-Pretrain-100B/zh_cc-high-loss0/part_28_text_document', '0.9776', '../OpenSeek-Pretrain-100B/zh_cc-high-loss1/part_59_text_document', '0.3725', '../OpenSeek-Pretrain-100B/zh_cc-high-loss2/part_16_text_document', '0.9492', '../OpenSeek-Pretrain-100B/zh_cc-medidum-loss0/part_192_text_document', '0.9236', '../OpenSeek-Pretrain-100B/zh_cc-medidum-loss1/part_550_text_document', '1.0643', '../OpenSeek-Pretrain-100B/zh_cc-medidum-loss2/part_71_text_document'] [default0]: data_per_class_fraction ......................... 1.0 [default0]: data_sharding ................................... True [default0]: dataloader_type ................................. single [default0]: ddp_average_in_collective ....................... False [default0]: ddp_bucket_size ................................. None [default0]: ddp_num_buckets ................................. None [default0]: ddp_pad_buckets_for_high_nccl_busbw ............. False [default0]: decoder_first_pipeline_num_layers ............... None [default0]: decoder_last_pipeline_num_layers ................ None [default0]: decoder_num_layers .............................. None [default0]: decoder_seq_length .............................. None [default0]: decoupled_lr .................................... None [default0]: decoupled_min_lr ................................ None [default0]: decrease_batch_size_if_needed ................... False [default0]: defer_embedding_wgrad_compute ................... False [default0]: deprecated_use_mcore_models ..................... False [default0]: deterministic_mode .............................. False [default0]: dino_bottleneck_size ............................ 256 [default0]: dino_freeze_last_layer .......................... 1 [default0]: dino_head_hidden_size ........................... 2048 [default0]: dino_local_crops_number ......................... 10 [default0]: dino_local_img_size ............................. 96 [default0]: dino_norm_last_layer ............................ False [default0]: dino_teacher_temp ............................... 0.07 [default0]: dino_warmup_teacher_temp ........................ 0.04 [default0]: dino_warmup_teacher_temp_epochs ................. 30 [default0]: disable_bf16_reduced_precision_matmul ........... False [default0]: disable_mamba_mem_eff_path ...................... False [default0]: disable_straggler_on_startup .................... False [default0]: dist_ckpt_format_deprecated ..................... None [default0]: dist_ckpt_strictness ............................ assume_ok_unexpected [default0]: distribute_saved_activations .................... False [default0]: distributed_backend ............................. nccl [default0]: distributed_timeout_minutes ..................... 10 [default0]: embedding_path .................................. None [default0]: empty_unused_memory_level ....................... 0 [default0]: enable_cuda_graph ............................... False [default0]: enable_ft_package ............................... False [default0]: enable_gloo_process_groups ...................... True [default0]: enable_hetero ................................... False [default0]: enable_msc ...................................... True [default0]: enable_one_logger ............................... True [default0]: encoder_num_layers .............................. 6 [default0]: encoder_pipeline_model_parallel_size ............ 0 [default0]: encoder_seq_length .............................. 4096 [default0]: encoder_tensor_model_parallel_size .............. 0 [default0]: end_weight_decay ................................ 0.1 [default0]: eod_mask_loss ................................... False [default0]: error_injection_rate ............................ 0 [default0]: error_injection_type ............................ transient_error [default0]: eval_interval ................................... 1000 [default0]: eval_iters ...................................... 0 [default0]: evidence_data_path .............................. None [default0]: exit_duration_in_mins ........................... None [default0]: exit_interval ................................... None [default0]: exit_on_missing_checkpoint ...................... False [default0]: exit_signal_handler ............................. False [default0]: exp_avg_dtype ................................... torch.float32 [default0]: exp_avg_sq_dtype ................................ torch.float32 [default0]: expert_model_parallel_size ...................... 1 [default0]: expert_tensor_parallel_size ..................... 1 [default0]: expert_tensor_parallel_size_per_process_mesh .... None [default0]: external_cuda_graph ............................. False [default0]: extra_eval_interval ............................. None [default0]: extra_valid_data_path ........................... None [default0]: ffn_hidden_size ................................. 7168 [default0]: finetune ........................................ False [default0]: finetune_dataset_type ........................... None [default0]: first_last_layers_bf16 .......................... False [default0]: flash_decode .................................... False [default0]: fp16 ............................................ False [default0]: fp16_lm_cross_entropy ........................... False [default0]: fp32_residual_connection ........................ False [default0]: fp8 ............................................. None [default0]: fp8_amax_compute_algo ........................... most_recent [default0]: fp8_amax_history_len ............................ 1 [default0]: fp8_interval .................................... 1 [default0]: fp8_margin ...................................... 0 [default0]: fp8_param_gather ................................ False [default0]: fp8_recipe ...................................... delayed [default0]: fp8_wgrad ....................................... True [default0]: global_batch_size ............................... 1024 [default0]: grad_reduce_in_bf16 ............................. False [default0]: gradient_accumulation_fusion .................... True [default0]: gradient_reduce_div_fusion ...................... True [default0]: group_query_attention ........................... False [default0]: head_lr_mult .................................... 1.0 [default0]: hetero_current_device_type ...................... None [default0]: hetero_device_types ............................. None [default0]: hetero_pipeline_layer_split ..................... None [default0]: hetero_process_meshes ........................... None [default0]: hetero_use_cpu_communication .................... False [default0]: heterogeneous_layers_config_encoded_json ........ None [default0]: heterogeneous_layers_config_path ................ None [default0]: hidden_dim_multiplier ........................... None [default0]: hidden_dropout .................................. 0.0 [default0]: hidden_size ..................................... 1280 [default0]: hierarchical_context_parallel_sizes ............. None [default0]: hybrid_attention_ratio .......................... 0.0 [default0]: hybrid_mlp_ratio ................................ 0.0 [default0]: hybrid_override_pattern ......................... None [default0]: hysteresis ...................................... 2 [default0]: ict_head_size ................................... None [default0]: ict_load ........................................ None [default0]: img_h ........................................... 224 [default0]: img_w ........................................... 224 [default0]: indexer_batch_size .............................. 128 [default0]: indexer_log_interval ............................ 1000 [default0]: inference_batch_times_seqlen_threshold .......... -1 [default0]: inference_dynamic_batching ...................... False [default0]: inference_dynamic_batching_buffer_guaranteed_fraction 0.2 [default0]: inference_dynamic_batching_buffer_overflow_factor None [default0]: inference_dynamic_batching_buffer_size_gb ....... 40.0 [default0]: inference_dynamic_batching_chunk_size ........... 256 [default0]: inference_dynamic_batching_max_requests_override None [default0]: inference_dynamic_batching_max_tokens_override .. None [default0]: inference_max_batch_size ........................ 8 [default0]: inference_max_seq_length ........................ 2560 [default0]: inference_rng_tracker ........................... False [default0]: init_method_std ................................. 0.006 [default0]: init_method_xavier_uniform ...................... False [default0]: init_model_with_meta_device ..................... False [default0]: initial_loss_scale .............................. 4294967296 [default0]: is_hybrid_model ................................. False [default0]: iter_per_epoch .................................. 1250 [default0]: iterations_to_skip .............................. [] [default0]: keep_fp8_transpose_cache_when_using_custom_fsdp . False [default0]: kv_channels ..................................... 128 [default0]: kv_lora_rank .................................... 512 [default0]: lazy_mpu_init ................................... None [default0]: load ............................................ /data2/workspaces/FlagAI_OpenSeek/OpenSeek-Small-v1-Baseline/checkpoints [default0]: local_rank ...................................... 0 [default0]: log_interval .................................... 1 [default0]: log_loss_scale_to_tensorboard ................... True [default0]: log_memory_to_tensorboard ....................... True [default0]: log_num_zeros_in_grad ........................... True [default0]: log_params_norm ................................. True [default0]: log_progress .................................... False [default0]: log_straggler ................................... False [default0]: log_throughput .................................. True [default0]: log_timers_to_tensorboard ....................... True [default0]: log_validation_ppl_to_tensorboard ............... True [default0]: log_world_size_to_tensorboard ................... False [default0]: logging_level ................................... None [default0]: loss_scale ...................................... None [default0]: loss_scale_window ............................... 1000 [default0]: lr .............................................. 0.003 [default0]: lr_decay_iters .................................. None [default0]: lr_decay_samples ................................ None [default0]: lr_decay_stablelm2_alpha ........................ 1.0 [default0]: lr_decay_stablelm2_beta ......................... 0.0 [default0]: lr_decay_stablelm2_cosine_max_lr ................ None [default0]: lr_decay_stablelm2_cosine_period_samples ........ 0 [default0]: lr_decay_stablelm2_cosine_samples ............... 0 [default0]: lr_decay_stablelm2_decay_samples ................ 0 [default0]: lr_decay_stablelm2_rsqrt_samples ................ 0 [default0]: lr_decay_style .................................. cosine [default0]: lr_warmup_fraction .............................. None [default0]: lr_warmup_init .................................. 0.0 [default0]: lr_warmup_iters ................................. 0 [default0]: lr_warmup_samples ............................... 2048000 [default0]: lr_wsd_decay_iters .............................. None [default0]: lr_wsd_decay_samples ............................ None [default0]: lr_wsd_decay_style .............................. exponential [default0]: main_grads_dtype ................................ torch.float32 [default0]: main_params_dtype ............................... torch.float32 [default0]: make_vocab_size_divisible_by .................... 64 [default0]: mamba_head_dim .................................. 64 [default0]: mamba_num_groups ................................ 8 [default0]: mamba_num_heads ................................. None [default0]: mamba_state_dim ................................. 128 [default0]: manual_gc ....................................... False [default0]: manual_gc_eval .................................. True [default0]: manual_gc_interval .............................. 0 [default0]: mask_factor ..................................... 1.0 [default0]: mask_prob ....................................... 0.15 [default0]: mask_type ....................................... random [default0]: masked_softmax_fusion ........................... True [default0]: max_position_embeddings ......................... 4096 [default0]: max_tokens_to_oom ............................... 12000 [default0]: memory_snapshot_path ............................ snapshot.pickle [default0]: merge_file ...................................... None [default0]: micro_batch_size ................................ 1 [default0]: microbatch_group_size_per_vp_stage .............. None [default0]: mid_level_dataset_surplus ....................... 0.005 [default0]: min_loss_scale .................................. 1.0 [default0]: min_lr .......................................... 0.0003 [default0]: mlp_chunks_for_prefill .......................... 1 [default0]: mmap_bin_files .................................. False [default0]: mock_data ....................................... False [default0]: moe_aux_loss_coeff .............................. 0.0001 [default0]: moe_enable_deepep ............................... False [default0]: moe_expert_capacity_factor ...................... None [default0]: moe_extended_tp ................................. False [default0]: moe_ffn_hidden_size ............................. 896 [default0]: moe_grouped_gemm ................................ True [default0]: moe_input_jitter_eps ............................ None [default0]: moe_layer_freq .................................. [0, 1, 1, 1, 1, 1] [default0]: moe_layer_recompute ............................. False [default0]: moe_pad_expert_input_to_capacity ................ False [default0]: moe_per_layer_logging ........................... False [default0]: moe_permute_fusion .............................. False [default0]: moe_router_bias_update_rate ..................... 0.001 [default0]: moe_router_dtype ................................ fp32 [default0]: moe_router_enable_expert_bias ................... True [default0]: moe_router_group_topk ........................... 1 [default0]: moe_router_load_balancing_type .................. seq_aux_loss [default0]: moe_router_num_groups ........................... 1 [default0]: moe_router_pre_softmax .......................... False [default0]: moe_router_score_function ....................... sigmoid [default0]: moe_router_topk ................................. 6 [default0]: moe_router_topk_scaling_factor .................. 2.446 [default0]: moe_shared_expert_intermediate_size ............. 1792 [default0]: moe_shared_expert_overlap ....................... False [default0]: moe_token_dispatcher_type ....................... alltoall [default0]: moe_token_drop_policy ........................... probs [default0]: moe_use_legacy_grouped_gemm ..................... False [default0]: moe_use_upcycling ............................... False [default0]: moe_z_loss_coeff ................................ None [default0]: mrope_section ................................... None [default0]: mscale .......................................... 1.0 [default0]: mscale_all_dim .................................. 1.0 [default0]: mtp_loss_coeff .................................. 0.3 [default0]: mtp_loss_scaling_factor ......................... 0.1 [default0]: mtp_num_layers .................................. None [default0]: multi_latent_attention .......................... True [default0]: multiple_of ..................................... None [default0]: nccl_all_reduce_for_prefill ..................... False [default0]: nccl_communicator_config_path ................... None [default0]: no_load_optim ................................... None [default0]: no_load_rng ..................................... None [default0]: no_persist_layer_norm ........................... False [default0]: no_rope_freq .................................... None [default0]: no_save_optim ................................... None [default0]: no_save_rng ..................................... None [default0]: no_shared_fs .................................... False [default0]: non_persistent_ckpt_type ........................ None [default0]: non_persistent_global_ckpt_dir .................. None [default0]: non_persistent_local_ckpt_algo .................. fully_parallel [default0]: non_persistent_local_ckpt_dir ................... None [default0]: non_persistent_save_interval .................... None [default0]: norm_epsilon .................................... 1e-06 [default0]: norm_init_weight ................................ None [default0]: normalization ................................... RMSNorm [default0]: num_attention_heads ............................. 10 [default0]: num_channels .................................... 3 [default0]: num_classes ..................................... 1000 [default0]: num_dataset_builder_threads ..................... 1 [default0]: num_distributed_optimizer_instances ............. 1 [default0]: num_experts ..................................... 64 [default0]: num_layers ...................................... 6 [default0]: num_layers_at_end_in_bf16 ....................... 1 [default0]: num_layers_at_start_in_bf16 ..................... 1 [default0]: num_layers_per_virtual_pipeline_stage ........... None [default0]: num_mtp_predictor ............................... 0 [default0]: num_query_groups ................................ 10 [default0]: num_virtual_stages_per_pipeline_rank ............ None [default0]: num_workers ..................................... 4 [default0]: object_storage_cache_path ....................... None [default0]: one_logger_async ................................ False [default0]: one_logger_project .............................. megatron-lm [default0]: one_logger_run_name ............................. None [default0]: onnx_safe ....................................... None [default0]: openai_gelu ..................................... False [default0]: optimizer ....................................... adam [default0]: optimizer_cpu_offload ........................... False [default0]: optimizer_offload_fraction ...................... 1.0 [default0]: output_bert_embeddings .......................... False [default0]: overlap_cpu_optimizer_d2h_h2d ................... False [default0]: overlap_grad_reduce ............................. True [default0]: overlap_p2p_comm ................................ False [default0]: overlap_p2p_comm_warmup_flush ................... False [default0]: overlap_param_gather ............................ True [default0]: overlap_param_gather_with_optimizer_step ........ False [default0]: override_opt_param_scheduler .................... False [default0]: params_dtype .................................... torch.bfloat16 [default0]: patch_dim ....................................... 16 [default0]: per_split_data_args_path ........................ None [default0]: perform_initialization .......................... True [default0]: pin_cpu_grads ................................... True [default0]: pin_cpu_params .................................. True [default0]: pipeline_model_parallel_comm_backend ............ None [default0]: pipeline_model_parallel_size .................... 1 [default0]: pipeline_model_parallel_split_rank .............. None [default0]: position_embedding_type ......................... rope [default0]: pretrained_checkpoint ........................... None [default0]: profile ......................................... False [default0]: profile_ranks ................................... [0] [default0]: profile_step_end ................................ 12 [default0]: profile_step_start .............................. 10 [default0]: q_lora_rank ..................................... None [default0]: qk_head_dim ..................................... 128 [default0]: qk_layernorm .................................... True [default0]: qk_layernorm_hidden_dim ......................... False [default0]: qk_pos_emb_head_dim ............................. 64 [default0]: query_in_block_prob ............................. 0.1 [default0]: rampup_batch_size ............................... None [default0]: rampup_save_interval ............................ None [default0]: rank ............................................ 0 [default0]: recompute_granularity ........................... full [default0]: recompute_granularity_per_stage_micro_batch ..... None [default0]: recompute_method ................................ uniform [default0]: recompute_method_per_stage_micro_batch .......... None [default0]: recompute_modules ............................... None [default0]: recompute_num_layers ............................ 6 [default0]: recompute_num_layers_per_stage_micro_batch ...... None [default0]: record_memory_history ........................... False [default0]: relative_attention_max_distance ................. 128 [default0]: relative_attention_num_buckets .................. 32 [default0]: replication ..................................... False [default0]: replication_factor .............................. 2 [default0]: replication_jump ................................ None [default0]: rerun_mode ...................................... disabled [default0]: reset_attention_mask ............................ True [default0]: reset_position_ids .............................. True [default0]: result_rejected_tracker_filename ................ None [default0]: retriever_report_topk_accuracies ................ [] [default0]: retriever_score_scaling ......................... False [default0]: retriever_seq_length ............................ 256 [default0]: retro_add_retriever ............................. False [default0]: retro_attention_gate ............................ 1 [default0]: retro_cyclic_train_iters ........................ None [default0]: retro_encoder_attention_dropout ................. 0.1 [default0]: retro_encoder_hidden_dropout .................... 0.1 [default0]: retro_encoder_layers ............................ 2 [default0]: retro_num_neighbors ............................. 2 [default0]: retro_num_retrieved_chunks ...................... 2 [default0]: retro_project_dir ............................... None [default0]: retro_verify_neighbor_count ..................... True [default0]: rope_scaling_factor ............................. 8.0 [default0]: rotary_base ..................................... 1000000 [default0]: rotary_interleaved .............................. False [default0]: rotary_percent .................................. 1.0 [default0]: rotary_scaling_factor ........................... 1.0 [default0]: rotary_seq_len_interpolation_factor ............. None [default0]: run_workload_inspector_server ................... False [default0]: sample_rate ..................................... 1.0 [default0]: save ............................................ /data2/workspaces/FlagAI_OpenSeek/OpenSeek-Small-v1-Baseline/checkpoints [default0]: save_interval ................................... 600 [default0]: save_when_num_microbatches_change ............... False [default0]: scatter_gather_tensors_in_pipeline .............. True [default0]: seed ............................................ 42 [default0]: seq_length ...................................... 4096 [default0]: sequence_parallel ............................... False [default0]: sgd_momentum .................................... 0.9 [default0]: short_seq_prob .................................. 0.1 [default0]: skip_iters_range ................................ None [default0]: skip_samples_range .............................. None [default0]: skip_train ...................................... False [default0]: skipped_train_samples ........................... 0 [default0]: spec ............................................ None [default0]: special_tokens_file ............................. None [default0]: spiky_loss_threshold ............................ 0.2 [default0]: split ........................................... 1 [default0]: squared_relu .................................... False [default0]: standalone_embedding_stage ...................... False [default0]: start_weight_decay .............................. 0.1 [default0]: straggler_ctrlr_port ............................ 65535 [default0]: straggler_minmax_count .......................... 1 [default0]: suggested_communication_unit_size ............... None [default0]: swiglu .......................................... True [default5]:/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/training/arguments.py:819: UserWarning: Disabling sequence parallelism because tensor model parallelism is disabled [default5]: warnings.warn("Disabling sequence parallelism because tensor model parallelism is disabled") [default4]:/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/training/arguments.py:819: UserWarning: Disabling sequence parallelism because tensor model parallelism is disabled [default4]: warnings.warn("Disabling sequence parallelism because tensor model parallelism is disabled") [default1]:[rank1]:[W627 15:58:54.941583063 ProcessGroupNCCL.cpp:4561] [PG ID 0 PG GUID 0 Rank 1] using GPU 1 to perform barrier as devices used by this process are currently unknown. This can potentially cause a hang if this rank to GPU mapping is incorrect. Specify device_ids in barrier() to force use of a particular device, or call init_process_group() with a device_id. [default2]:[rank2]:[W627 15:58:54.982814058 ProcessGroupNCCL.cpp:4561] [PG ID 0 PG GUID 0 Rank 2] using GPU 2 to perform barrier as devices used by this process are currently unknown. This can potentially cause a hang if this rank to GPU mapping is incorrect. Specify device_ids in barrier() to force use of a particular device, or call init_process_group() with a device_id. [default4]:[rank4]:[W627 15:58:54.017065317 ProcessGroupNCCL.cpp:4561] [PG ID 0 PG GUID 0 Rank 4] using GPU 4 to perform barrier as devices used by this process are currently unknown. This can potentially cause a hang if this rank to GPU mapping is incorrect. Specify device_ids in barrier() to force use of a particular device, or call init_process_group() with a device_id. [default5]:[rank5]:[W627 15:58:54.981277710 ProcessGroupNCCL.cpp:4561] [PG ID 0 PG GUID 0 Rank 5] using GPU 5 to perform barrier as devices used by this process are currently unknown. This can potentially cause a hang if this rank to GPU mapping is incorrect. Specify device_ids in barrier() to force use of a particular device, or call init_process_group() with a device_id. [default3]:[rank3]:[W627 15:58:54.049300540 ProcessGroupNCCL.cpp:4561] [PG ID 0 PG GUID 0 Rank 3] using GPU 3 to perform barrier as devices used by this process are currently unknown. This can potentially cause a hang if this rank to GPU mapping is incorrect. Specify device_ids in barrier() to force use of a particular device, or call init_process_group() with a device_id. [default6]:[rank6]:[W627 15:58:54.050272654 ProcessGroupNCCL.cpp:4561] [PG ID 0 PG GUID 0 Rank 6] using GPU 6 to perform barrier as devices used by this process are currently unknown. This can potentially cause a hang if this rank to GPU mapping is incorrect. Specify device_ids in barrier() to force use of a particular device, or call init_process_group() with a device_id. [default7]:wandb: WARNING `resume` will be ignored since W&B syncing is set to `offline`. Starting a new run with run id OpenSeek-Small-v1-Baseline-rank-7. [default0]:wandb: WARNING `resume` will be ignored since W&B syncing is set to `offline`. Starting a new run with run id OpenSeek-Small-v1-Baseline-rank-0. [default7]:wandb: Tracking run with wandb version 0.19.11 [default7]:wandb: W&B syncing is set to `offline` in this directory. Run `wandb online` or set WANDB_MODE=online to enable cloud syncing. [default7]:[rank7]:[W627 15:58:55.174225256 ProcessGroupNCCL.cpp:4561] [PG ID 0 PG GUID 0 Rank 7] using GPU 7 to perform barrier as devices used by this process are currently unknown. This can potentially cause a hang if this rank to GPU mapping is incorrect. Specify device_ids in barrier() to force use of a particular device, or call init_process_group() with a device_id. [default0]:wandb: Tracking run with wandb version 0.19.11 [default0]:wandb: W&B syncing is set to `offline` in this directory. Run `wandb online` or set WANDB_MODE=online to enable cloud syncing. [default0]:[rank0]:[W627 15:58:55.391530592 ProcessGroupNCCL.cpp:4561] [PG ID 0 PG GUID 0 Rank 0] using GPU 0 to perform barrier as devices used by this process are currently unknown. This can potentially cause a hang if this rank to GPU mapping is incorrect. Specify device_ids in barrier() to force use of a particular device, or call init_process_group() with a device_id. [default0]: swin_backbone_type .............................. tiny [default0]: symmetric_ar_type ............................... None [default0]: te_rng_tracker .................................. False [default0]: tensor_model_parallel_size ...................... 1 [default0]: tensorboard_dir ................................. /data2/workspaces/FlagAI_OpenSeek/OpenSeek-Small-v1-Baseline/tensorboard [default0]: tensorboard_log_interval ........................ 1 [default0]: tensorboard_queue_size .......................... 1000 [default0]: test_data_path .................................. None [default0]: test_mode ....................................... False [default0]: tiktoken_num_special_tokens ..................... 1000 [default0]: tiktoken_pattern ................................ None [default0]: tiktoken_special_tokens ......................... None [default0]: timing_log_level ................................ 0 [default0]: timing_log_option ............................... minmax [default0]: titles_data_path ................................ None [default0]: tokenizer_model ................................. None [default0]: tokenizer_path .................................. ../hf_openseek/tokenizer [default0]: tokenizer_type .................................. QwenTokenizerFS [default0]: torch_fsdp2_reshard_after_forward ............... True [default0]: tp_comm_bootstrap_backend ....................... nccl [default0]: tp_comm_bulk_dgrad .............................. True [default0]: tp_comm_bulk_wgrad .............................. True [default0]: tp_comm_overlap ................................. False [default0]: tp_comm_overlap_ag .............................. True [default0]: tp_comm_overlap_cfg ............................. None [default0]: tp_comm_overlap_rs .............................. True [default0]: tp_comm_overlap_rs_dgrad ........................ False [default0]: tp_comm_split_ag ................................ True [default0]: tp_comm_split_rs ................................ True [default0]: train_data_path ................................. None [default0]: train_iters ..................................... None [default0]: train_samples ................................... 24576000 [default0]: train_sync_interval ............................. None [default0]: transformer_impl ................................ transformer_engine [default0]: transformer_pipeline_model_parallel_size ........ 1 [default0]: untie_embeddings_and_output_weights ............. False [default0]: use_checkpoint_args ............................. False [default0]: use_checkpoint_opt_param_scheduler .............. False [default0]: use_cpu_initialization .......................... None [default0]: use_custom_fsdp ................................. False [default0]: use_dist_ckpt ................................... False [default0]: use_dist_ckpt_deprecated ........................ False [default0]: use_distributed_optimizer ....................... True [default0]: use_flash_attn .................................. False [default0]: use_legacy_models ............................... False [default0]: use_mp_args_from_checkpoint_args ................ False [default0]: use_one_sent_docs ............................... False [default0]: use_partial_reduce_for_shared_embedding ......... False [default0]: use_persistent_ckpt_worker ...................... False [default0]: use_precision_aware_optimizer ................... False [default0]: use_pytorch_profiler ............................ False [default0]: use_ring_exchange_p2p ........................... False [default0]: use_rope_scaling ................................ False [default0]: use_rotary_position_embeddings .................. True [default0]: use_tokenizer_model_from_checkpoint_args ........ True [default0]: use_torch_fsdp2 ................................. False [default0]: use_torch_optimizer_for_cpu_offload ............. False [default0]: use_tp_pp_dp_mapping ............................ False [default0]: v_head_dim ...................................... 128 [default0]: valid_data_path ................................. None [default0]: variable_seq_lengths ............................ False [default0]: virtual_pipeline_model_parallel_size ............ None [default0]: vision_backbone_type ............................ vit [default0]: vision_pretraining .............................. False [default0]: vision_pretraining_type ......................... classify [default0]: vocab_extra_ids ................................. 0 [default0]: vocab_file ...................................... None [default0]: vocab_size ...................................... 151851 [default0]: wandb_api_key ................................... [default0]: wandb_exp_name .................................. OpenSeek-Small-v1-Baseline [default0]: wandb_log_model ................................. False [default0]: wandb_log_model_interval ........................ 1000 [default0]: wandb_mode ...................................... offline [default0]: wandb_project ................................... OpenSeek-Small-v1-Baseline [default0]: wandb_save_dir .................................. /data2/workspaces/FlagAI_OpenSeek/OpenSeek-Small-v1-Baseline/wandb [default0]: weight_decay .................................... 0.1 [default0]: weight_decay_incr_style ......................... constant [default0]: wgrad_deferral_limit ............................ 0 [default0]: world_size ...................................... 8 [default0]: yaml_cfg ........................................ None [default0]:-------------------- end of arguments --------------------- [default0]:INFO:megatron.core.num_microbatches_calculator:setting number of microbatches to constant 128 [default0]:> building QwenTokenizerFS tokenizer ... [default0]: > padded vocab (size: 151851) with 21 dummy tokens (new size: 151872) [default0]:WARNING:megatron.core.rerun_state_machine:RerunStateMachine initialized in mode RerunMode.DISABLED [default0]:> initializing torch distributed ... [default0]:> initialized tensor model parallel with size 1 [default0]:> initialized pipeline model parallel with size 1 [default0]:> setting random seeds to 42 ... [default7]:> setting tensorboard ... [default7]:WARNING: one_logger package is required to enable e2e metrics tracking. please go to https://confluence.nvidia.com/display/MLWFO/Package+Repositories for details to install it [default0]:> compiling dataset index builder ... [default0]:make: Entering directory '/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/core/datasets' [default0]:make: Nothing to be done for 'default'. [default0]:make: Leaving directory '/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/core/datasets' [default0]:>>> done with dataset index builder. Compilation time: 0.029 seconds [default0]:WARNING: constraints for invoking optimized fused softmax kernel are not met. We default back to unfused kernel invocations. [default0]:> compiling and loading fused kernels ... [default0]:>>> done with compiling and loading fused kernels. Compilation time: 1.923 seconds [default3]:> Number of attn parameters in a transformer block in billions: 0.01 [default3]:> Number of dense mlp parameters in a transformer block in billions: 0.03 [default3]:> Number of sparse mlp parameters in a transformer block in billions: 0.23 [default3]:> Number of parameters in transformer block in billions: 1.20 [default3]:> Number of parameters in mtp transformer block in billions: 0.00 [default3]:> Number of parameters in embedding layers in billions: 0.19 [default3]:> Total number of parameters in billions: 1.39 [default3]:> Number of parameters in most loaded shard in billions: 1.3946 [default3]:> Number of activated attn parameters in a transformer block in billions: 0.01 [default3]:> Number of activated dense mlp parameters in a transformer block in billions: 0.03 [default3]:> Number of activated sparse mlp parameters in a transformer block in billions: 0.03 [default3]:> Number of activated parameters in transformer block in billions: 0.20 [default1]:/root/miniconda3/envs/flagscale-train/lib/python3.12/site-packages/transformer_engine/pytorch/cpu_offload.py:593: DeprecationWarning: Offloading weights is deprecated. Using offload_weights=True does not have any effect. [default1]: warnings.warn( [default4]:/root/miniconda3/envs/flagscale-train/lib/python3.12/site-packages/transformer_engine/pytorch/cpu_offload.py:593: DeprecationWarning: Offloading weights is deprecated. Using offload_weights=True does not have any effect. [default4]: warnings.warn( [default7]:/root/miniconda3/envs/flagscale-train/lib/python3.12/site-packages/transformer_engine/pytorch/cpu_offload.py:593: DeprecationWarning: Offloading weights is deprecated. Using offload_weights=True does not have any effect. [default7]: warnings.warn( [default6]:/root/miniconda3/envs/flagscale-train/lib/python3.12/site-packages/transformer_engine/pytorch/cpu_offload.py:593: DeprecationWarning: Offloading weights is deprecated. Using offload_weights=True does not have any effect. [default6]: warnings.warn( [default3]:> Number of activated parameters in mtp transformer block in billions: 0.00 [default3]:> Number of activated parameters in embedding layers in billions: 0.19 [default3]:> Total number of activated parameters in billions: 0.40 [default3]:> Activation memory footprint per dense transformer layer: 276.0 MB [default3]:> Activation memory footprint per moe transformer layer: 346.0 MB [default3]:>>> [FS] Theoretical memory footprints: weight and optimizer=9975.26 MB, activation=2416.03 MB, total=12391.29 MB [default3]: [default6]:> Number of attn parameters in a transformer block in billions: 0.01 [default6]:> Number of dense mlp parameters in a transformer block in billions: 0.03 [default6]:> Number of sparse mlp parameters in a transformer block in billions: 0.23 [default6]:> Number of parameters in transformer block in billions: 1.20 [default6]:> Number of parameters in mtp transformer block in billions: 0.00 [default6]:> Number of parameters in embedding layers in billions: 0.19 [default6]:> Total number of parameters in billions: 1.39 [default6]:> Number of parameters in most loaded shard in billions: 1.3946 [default6]:> Number of activated attn parameters in a transformer block in billions: 0.01 [default6]:> Number of activated dense mlp parameters in a transformer block in billions: 0.03 [default6]:> Number of activated sparse mlp parameters in a transformer block in billions: 0.03 [default6]:> Number of activated parameters in transformer block in billions: 0.20 [default6]:> Number of activated parameters in mtp transformer block in billions: 0.00 [default6]:> Number of activated parameters in embedding layers in billions: 0.19 [default6]:> Total number of activated parameters in billions: 0.40 [default6]:> Activation memory footprint per dense transformer layer: 276.0 MB [default6]:> Activation memory footprint per moe transformer layer: 346.0 MB [default6]:>>> [FS] Theoretical memory footprints: weight and optimizer=9975.26 MB, activation=2416.03 MB, total=12391.29 MB [default6]: [default1]:> Number of attn parameters in a transformer block in billions: 0.01 [default1]:> Number of dense mlp parameters in a transformer block in billions: 0.03 [default1]:> Number of sparse mlp parameters in a transformer block in billions: 0.23 [default1]:> Number of parameters in transformer block in billions: 1.20 [default1]:> Number of parameters in mtp transformer block in billions: 0.00 [default1]:> Number of parameters in embedding layers in billions: 0.19 [default1]:> Total number of parameters in billions: 1.39 [default1]:> Number of parameters in most loaded shard in billions: 1.3946 [default1]:> Number of activated attn parameters in a transformer block in billions: 0.01 [default1]:> Number of activated dense mlp parameters in a transformer block in billions: 0.03 [default1]:> Number of activated sparse mlp parameters in a transformer block in billions: 0.03 [default1]:> Number of activated parameters in transformer block in billions: 0.20 [default1]:> Number of activated parameters in mtp transformer block in billions: 0.00 [default1]:> Number of activated parameters in embedding layers in billions: 0.19 [default1]:> Total number of activated parameters in billions: 0.40 [default1]:> Activation memory footprint per dense transformer layer: 276.0 MB [default1]:> Activation memory footprint per moe transformer layer: 346.0 MB [default1]:>>> [FS] Theoretical memory footprints: weight and optimizer=9975.26 MB, activation=2416.03 MB, total=12391.29 MB [default1]: [default2]:> Number of attn parameters in a transformer block in billions: 0.01 [default2]:> Number of dense mlp parameters in a transformer block in billions: 0.03 [default2]:> Number of sparse mlp parameters in a transformer block in billions: 0.23 [default2]:> Number of parameters in transformer block in billions: 1.20 [default2]:> Number of parameters in mtp transformer block in billions: 0.00 [default2]:> Number of parameters in embedding layers in billions: 0.19 [default2]:> Total number of parameters in billions: 1.39 [default2]:> Number of parameters in most loaded shard in billions: 1.3946 [default2]:> Number of activated attn parameters in a transformer block in billions: 0.01 [default2]:> Number of activated dense mlp parameters in a transformer block in billions: 0.03 [default2]:> Number of activated sparse mlp parameters in a transformer block in billions: 0.03 [default2]:> Number of activated parameters in transformer block in billions: 0.20 [default2]:> Number of activated parameters in mtp transformer block in billions: 0.00 [default2]:> Number of activated parameters in embedding layers in billions: 0.19 [default2]:> Total number of activated parameters in billions: 0.40 [default2]:> Activation memory footprint per dense transformer layer: 276.0 MB [default2]:> Activation memory footprint per moe transformer layer: 346.0 MB [default2]:>>> [FS] Theoretical memory footprints: weight and optimizer=9975.26 MB, activation=2416.03 MB, total=12391.29 MB [default2]: [default0]:time to initialize megatron (seconds): 9.606 [default0]:[after megatron is initialized] datetime: 2025-06-27 15:59:01 [default0]:> Number of attn parameters in a transformer block in billions: 0.01 [default0]:> Number of dense mlp parameters in a transformer block in billions: 0.03 [default0]:> Number of sparse mlp parameters in a transformer block in billions: 0.23 [default0]:> Number of parameters in transformer block in billions: 1.20 [default0]:> Number of parameters in mtp transformer block in billions: 0.00 [default0]:> Number of parameters in embedding layers in billions: 0.19 [default0]:> Total number of parameters in billions: 1.39 [default0]:> Number of parameters in most loaded shard in billions: 1.3946 [default0]:> Number of activated attn parameters in a transformer block in billions: 0.01 [default0]:> Number of activated dense mlp parameters in a transformer block in billions: 0.03 [default0]:> Number of activated sparse mlp parameters in a transformer block in billions: 0.03 [default0]:> Number of activated parameters in transformer block in billions: 0.20 [default0]:> Number of activated parameters in mtp transformer block in billions: 0.00 [default0]:> Number of activated parameters in embedding layers in billions: 0.19 [default0]:> Total number of activated parameters in billions: 0.40 [default0]:> Activation memory footprint per dense transformer layer: 276.0 MB [default0]:> Activation memory footprint per moe transformer layer: 346.0 MB [default0]:>>> [FS] Theoretical memory footprints: weight and optimizer=9975.26 MB, activation=2416.03 MB, total=12391.29 MB [default0]: [default0]:building GPT model ... [default4]:> Number of attn parameters in a transformer block in billions: 0.01 [default4]:> Number of dense mlp parameters in a transformer block in billions: 0.03 [default4]:> Number of sparse mlp parameters in a transformer block in billions: 0.23 [default4]:> Number of parameters in transformer block in billions: 1.20 [default4]:> Number of parameters in mtp transformer block in billions: 0.00 [default4]:> Number of parameters in embedding layers in billions: 0.19 [default4]:> Total number of parameters in billions: 1.39 [default4]:> Number of parameters in most loaded shard in billions: 1.3946 [default4]:> Number of activated attn parameters in a transformer block in billions: 0.01 [default4]:> Number of activated dense mlp parameters in a transformer block in billions: 0.03 [default4]:> Number of activated sparse mlp parameters in a transformer block in billions: 0.03 [default4]:> Number of activated parameters in transformer block in billions: 0.20 [default4]:> Number of activated parameters in mtp transformer block in billions: 0.00 [default4]:> Number of activated parameters in embedding layers in billions: 0.19 [default4]:> Total number of activated parameters in billions: 0.40 [default4]:> Activation memory footprint per dense transformer layer: 276.0 MB [default4]:> Activation memory footprint per moe transformer layer: 346.0 MB [default4]:>>> [FS] Theoretical memory footprints: weight and optimizer=9975.26 MB, activation=2416.03 MB, total=12391.29 MB [default5]:/root/miniconda3/envs/flagscale-train/lib/python3.12/site-packages/transformer_engine/pytorch/cpu_offload.py:593: DeprecationWarning: Offloading weights is deprecated. Using offload_weights=True does not have any effect. [default5]: warnings.warn( [default3]:/root/miniconda3/envs/flagscale-train/lib/python3.12/site-packages/transformer_engine/pytorch/cpu_offload.py:593: DeprecationWarning: Offloading weights is deprecated. Using offload_weights=True does not have any effect. [default3]: warnings.warn( [default0]:/root/miniconda3/envs/flagscale-train/lib/python3.12/site-packages/transformer_engine/pytorch/cpu_offload.py:593: DeprecationWarning: Offloading weights is deprecated. Using offload_weights=True does not have any effect. [default0]: warnings.warn( [default2]:/root/miniconda3/envs/flagscale-train/lib/python3.12/site-packages/transformer_engine/pytorch/cpu_offload.py:593: DeprecationWarning: Offloading weights is deprecated. Using offload_weights=True does not have any effect. [default2]: warnings.warn( [default1]:/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/core/extensions/transformer_engine.py:153: UserWarning: The user buffer name q_proj is not supported inTransformer Engine. Disabling TP communication overlap for this layer. [default1]: warnings.warn( [default1]:/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/core/extensions/transformer_engine.py:153: UserWarning: The user buffer name kv_down_proj is not supported inTransformer Engine. Disabling TP communication overlap for this layer. [default1]: warnings.warn( [default4]:/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/core/extensions/transformer_engine.py:153: UserWarning: The user buffer name q_proj is not supported inTransformer Engine. Disabling TP communication overlap for this layer. [default4]: warnings.warn( [default4]:/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/core/extensions/transformer_engine.py:153: UserWarning: The user buffer name kv_down_proj is not supported inTransformer Engine. Disabling TP communication overlap for this layer. [default4]: warnings.warn( [default7]:/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/core/extensions/transformer_engine.py:153: UserWarning: The user buffer name q_proj is not supported inTransformer Engine. Disabling TP communication overlap for this layer. [default7]: warnings.warn( [default7]:/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/core/extensions/transformer_engine.py:153: UserWarning: The user buffer name kv_down_proj is not supported inTransformer Engine. Disabling TP communication overlap for this layer. [default7]: warnings.warn( [default6]:/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/core/extensions/transformer_engine.py:153: UserWarning: The user buffer name q_proj is not supported inTransformer Engine. Disabling TP communication overlap for this layer. [default6]: warnings.warn( [default6]:/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/core/extensions/transformer_engine.py:153: UserWarning: The user buffer name kv_down_proj is not supported inTransformer Engine. Disabling TP communication overlap for this layer. [default6]: warnings.warn( [default5]:/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/core/extensions/transformer_engine.py:153: UserWarning: The user buffer name q_proj is not supported inTransformer Engine. Disabling TP communication overlap for this layer. [default5]: warnings.warn( [default5]:/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/core/extensions/transformer_engine.py:153: UserWarning: The user buffer name kv_down_proj is not supported inTransformer Engine. Disabling TP communication overlap for this layer. [default5]: warnings.warn( [default3]:/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/core/extensions/transformer_engine.py:153: UserWarning: The user buffer name q_proj is not supported inTransformer Engine. Disabling TP communication overlap for this layer. [default3]: warnings.warn( [default3]:/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/core/extensions/transformer_engine.py:153: UserWarning: The user buffer name kv_down_proj is not supported inTransformer Engine. Disabling TP communication overlap for this layer. [default3]: warnings.warn( [default0]:/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/core/extensions/transformer_engine.py:153: UserWarning: The user buffer name q_proj is not supported inTransformer Engine. Disabling TP communication overlap for this layer. [default0]: warnings.warn( [default0]:/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/core/extensions/transformer_engine.py:153: UserWarning: The user buffer name kv_down_proj is not supported inTransformer Engine. Disabling TP communication overlap for this layer. [default0]: warnings.warn( [default2]:/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/core/extensions/transformer_engine.py:153: UserWarning: The user buffer name q_proj is not supported inTransformer Engine. Disabling TP communication overlap for this layer. [default2]: warnings.warn( [default2]:/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/core/extensions/transformer_engine.py:153: UserWarning: The user buffer name kv_down_proj is not supported inTransformer Engine. Disabling TP communication overlap for this layer. [default2]: warnings.warn( [default4]: [default5]:> Number of attn parameters in a transformer block in billions: 0.01 [default5]:> Number of dense mlp parameters in a transformer block in billions: 0.03 [default5]:> Number of sparse mlp parameters in a transformer block in billions: 0.23 [default5]:> Number of parameters in transformer block in billions: 1.20 [default5]:> Number of parameters in mtp transformer block in billions: 0.00 [default5]:> Number of parameters in embedding layers in billions: 0.19 [default5]:> Total number of parameters in billions: 1.39 [default5]:> Number of parameters in most loaded shard in billions: 1.3946 [default5]:> Number of activated attn parameters in a transformer block in billions: 0.01 [default5]:> Number of activated dense mlp parameters in a transformer block in billions: 0.03 [default5]:> Number of activated sparse mlp parameters in a transformer block in billions: 0.03 [default5]:> Number of activated parameters in transformer block in billions: 0.20 [default5]:> Number of activated parameters in mtp transformer block in billions: 0.00 [default5]:> Number of activated parameters in embedding layers in billions: 0.19 [default5]:> Total number of activated parameters in billions: 0.40 [default5]:> Activation memory footprint per dense transformer layer: 276.0 MB [default5]:> Activation memory footprint per moe transformer layer: 346.0 MB [default5]:>>> [FS] Theoretical memory footprints: weight and optimizer=9975.26 MB, activation=2416.03 MB, total=12391.29 MB [default5]: [default7]:> Number of attn parameters in a transformer block in billions: 0.01 [default7]:> Number of dense mlp parameters in a transformer block in billions: 0.03 [default7]:> Number of sparse mlp parameters in a transformer block in billions: 0.23 [default7]:> Number of parameters in transformer block in billions: 1.20 [default7]:> Number of parameters in mtp transformer block in billions: 0.00 [default7]:> Number of parameters in embedding layers in billions: 0.19 [default7]:> Total number of parameters in billions: 1.39 [default7]:> Number of parameters in most loaded shard in billions: 1.3946 [default7]:> Number of activated attn parameters in a transformer block in billions: 0.01 [default7]:> Number of activated dense mlp parameters in a transformer block in billions: 0.03 [default7]:> Number of activated sparse mlp parameters in a transformer block in billions: 0.03 [default7]:> Number of activated parameters in transformer block in billions: 0.20 [default7]:> Number of activated parameters in mtp transformer block in billions: 0.00 [default7]:> Number of activated parameters in embedding layers in billions: 0.19 [default7]:> Total number of activated parameters in billions: 0.40 [default7]:> Activation memory footprint per dense transformer layer: 276.0 MB [default7]:> Activation memory footprint per moe transformer layer: 346.0 MB [default7]:>>> [FS] Theoretical memory footprints: weight and optimizer=9975.26 MB, activation=2416.03 MB, total=12391.29 MB [default7]: [default0]: > number of parameters on (tensor, pipeline) model parallel rank (0, 0): 1394625792 [default0]:INFO:megatron.core.distributed.distributed_data_parallel:Setting up DistributedDataParallel with config DistributedDataParallelConfig(grad_reduce_in_fp32=True, overlap_grad_reduce=True, overlap_param_gather=True, align_param_gather=False, use_distributed_optimizer=True, num_distributed_optimizer_instances=1, check_for_nan_in_grad=True, check_for_large_grads=False, bucket_size=40000000, pad_buckets_for_high_nccl_busbw=False, average_in_collective=False, fp8_param_gather=False, use_custom_fsdp=False, data_parallel_sharding_strategy='no_shard', gradient_reduce_div_fusion=True, suggested_communication_unit_size=None, preserve_fp32_weights=True, keep_fp8_transpose_cache_when_using_custom_fsdp=False) [default0]:INFO:megatron.core.distributed.param_and_grad_buffer:Number of buckets for gradient all-reduce / reduce-scatter: 30 [default0]:Params for bucket 1 (40142080 elements, 40142080 padded size): [default0]: module.decoder.layers.5.mlp.shared_experts.linear_fc1.weight [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight61 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight53 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight45 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight37 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight58 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight50 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight42 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight63 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight55 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight47 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight39 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight60 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight52 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight44 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight36 [default0]: module.decoder.layers.5.mlp.shared_experts.linear_fc2.weight [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight57 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight49 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight41 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight62 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight54 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight46 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight38 [default0]: module.decoder.final_layernorm.weight [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight59 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight51 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight43 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight35 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight56 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight48 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight40 [default0]:Params for bucket 2 (40140800 elements, 40140800 padded size): [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight29 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight21 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight13 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight5 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight34 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight26 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight18 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight10 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight0 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight31 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight23 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight15 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight7 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight28 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight20 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight12 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight4 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight33 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight25 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight17 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight9 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight1 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight30 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight22 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight14 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight6 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight27 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight19 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight11 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight3 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight32 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight24 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight16 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight8 [default0]: module.decoder.layers.5.mlp.experts.linear_fc2.weight2 [default0]:Params for bucket 3 (41287680 elements, 41287680 padded size): [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight63 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight59 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight61 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight57 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight55 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight53 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight51 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight49 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight47 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight62 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight60 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight58 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight56 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight54 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight52 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight50 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight48 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight46 [default0]:Params for bucket 4 (41287680 elements, 41287680 padded size): [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight45 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight43 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight41 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight39 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight37 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight35 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight33 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight31 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight29 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight42 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight44 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight40 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight38 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight36 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight34 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight32 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight30 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight28 [default0]:Params for bucket 5 (41287680 elements, 41287680 padded size): [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight27 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight23 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight25 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight21 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight19 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight17 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight15 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight13 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight11 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight26 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight24 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight22 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight20 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight18 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight16 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight14 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight12 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight10 [default0]:Params for bucket 6 (40635392 elements, 40635392 padded size): [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight1 [default0]: module.decoder.layers.5.mlp.router.weight [default0]: module.decoder.layers.5.pre_mlp_layernorm.weight [default0]: module.decoder.layers.5.self_attention.linear_kv_up_proj.weight [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight2 [default0]: module.decoder.layers.5.self_attention.linear_kv_up_proj.layer_norm_weight [default0]: module.decoder.layers.5.self_attention.linear_kv_down_proj.weight [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight61 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight9 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight5 [default0]: module.decoder.layers.5.self_attention.linear_q_proj.weight [default0]: module.decoder.layers.5.self_attention.linear_proj.weight [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight3 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight63 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight6 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight8 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight60 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight4 [default0]: module.decoder.layers.5.input_layernorm.weight [default0]: module.decoder.layers.4.mlp.shared_experts.linear_fc2.weight [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight0 [default0]: module.decoder.layers.4.mlp.shared_experts.linear_fc1.weight [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight62 [default0]: module.decoder.layers.5.mlp.experts.linear_fc1.weight7 [default0]:Params for bucket 7 (40140800 elements, 40140800 padded size): [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight56 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight48 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight40 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight32 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight53 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight45 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight37 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight29 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight58 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight50 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight42 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight34 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight26 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight55 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight47 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight39 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight31 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight52 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight44 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight36 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight28 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight57 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight49 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight41 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight33 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight25 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight54 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight46 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight38 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight30 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight59 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight51 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight43 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight35 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight27 [default0]:Params for bucket 8 (40140800 elements, 40140800 padded size): [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight24 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight16 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight8 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight2 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight62 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight21 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight13 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight5 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight59 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight18 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight10 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight23 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight15 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight7 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight61 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight20 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight12 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight4 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight0 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight17 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight9 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight1 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight63 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight22 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight14 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight6 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight60 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight19 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight11 [default0]: module.decoder.layers.4.mlp.experts.linear_fc2.weight3 [default0]:Params for bucket 9 (41287680 elements, 41287680 padded size): [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight58 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight54 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight56 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight52 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight50 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight48 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight46 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight44 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight42 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight55 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight57 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight53 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight51 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight49 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight47 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight45 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight43 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight41 [default0]:Params for bucket 10 (41287680 elements, 41287680 padded size): [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight40 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight38 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight36 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight34 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight32 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight30 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight28 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight26 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight24 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight39 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight37 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight35 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight33 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight31 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight29 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight27 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight25 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight23 [default0]:Params for bucket 11 (41287680 elements, 41287680 padded size): [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight22 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight20 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight18 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight16 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight14 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight12 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight10 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight8 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight6 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight19 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight21 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight17 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight15 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight13 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight11 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight9 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight7 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight5 [default0]:Params for bucket 12 (40635392 elements, 40635392 padded size): [default0]: module.decoder.layers.4.self_attention.linear_proj.weight [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight63 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight55 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight60 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight1 [default0]: module.decoder.layers.4.mlp.router.weight [default0]: module.decoder.layers.4.pre_mlp_layernorm.weight [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight52 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight2 [default0]: module.decoder.layers.3.mlp.shared_experts.linear_fc1.weight [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight57 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight62 [default0]: module.decoder.layers.4.self_attention.linear_kv_up_proj.weight [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight54 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight3 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight59 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight51 [default0]: module.decoder.layers.4.self_attention.linear_kv_up_proj.layer_norm_weight [default0]: module.decoder.layers.4.self_attention.linear_kv_down_proj.weight [default0]: module.decoder.layers.4.self_attention.linear_q_proj.weight [default0]: module.decoder.layers.4.input_layernorm.weight [default0]: module.decoder.layers.3.mlp.shared_experts.linear_fc2.weight [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight56 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight4 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight61 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight53 [default0]: module.decoder.layers.4.mlp.experts.linear_fc1.weight0 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight58 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight50 [default0]:Params for bucket 13 (40140800 elements, 40140800 padded size): [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight47 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight39 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight31 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight23 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight15 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight44 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight36 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight28 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight20 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight49 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight41 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight33 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight25 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight17 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight46 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight38 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight30 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight22 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight43 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight35 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight27 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight19 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight48 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight40 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight32 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight24 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight16 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight45 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight37 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight29 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight21 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight42 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight34 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight26 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight18 [default0]:Params for bucket 14 (40140800 elements, 40140800 padded size): [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight7 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight56 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight12 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight4 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight61 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight9 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight2 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight1 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight58 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight14 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight6 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight63 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight55 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight11 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight3 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight60 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight8 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight57 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight13 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight5 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight62 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight54 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight10 [default0]: module.decoder.layers.3.mlp.experts.linear_fc2.weight0 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight59 [default0]:Params for bucket 15 (41287680 elements, 41287680 padded size): [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight50 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight52 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight48 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight46 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight44 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight42 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight40 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight38 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight36 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight53 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight49 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight51 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight47 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight45 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight43 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight41 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight39 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight37 [default0]:Params for bucket 16 (41287680 elements, 41287680 padded size): [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight32 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight34 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight30 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight28 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight26 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight24 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight22 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight20 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight18 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight35 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight33 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight31 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight29 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight27 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight25 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight23 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight21 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight19 [default0]:Params for bucket 17 (41287680 elements, 41287680 padded size): [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight17 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight14 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight12 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight10 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight8 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight6 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight4 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight3 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight2 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight15 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight16 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight13 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight11 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight9 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight7 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight5 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight1 [default0]: module.decoder.layers.3.mlp.experts.linear_fc1.weight0 [default0]:Params for bucket 18 (40635392 elements, 40635392 padded size): [default0]: module.decoder.layers.3.mlp.router.weight [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight57 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight49 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight41 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight62 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight54 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight46 [default0]: module.decoder.layers.3.self_attention.linear_kv_up_proj.weight [default0]: module.decoder.layers.3.self_attention.linear_q_proj.weight [default0]: module.decoder.layers.2.mlp.shared_experts.linear_fc1.weight [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight59 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight51 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight43 [default0]: module.decoder.layers.3.pre_mlp_layernorm.weight [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight56 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight48 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight40 [default0]: module.decoder.layers.3.self_attention.linear_kv_up_proj.layer_norm_weight [default0]: module.decoder.layers.3.self_attention.linear_proj.weight [default0]: module.decoder.layers.2.mlp.shared_experts.linear_fc2.weight [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight61 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight53 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight45 [default0]: module.decoder.layers.3.self_attention.linear_kv_down_proj.weight [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight58 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight50 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight42 [default0]: module.decoder.layers.3.input_layernorm.weight [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight63 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight55 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight47 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight60 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight52 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight44 [default0]:Params for bucket 19 (40140800 elements, 40140800 padded size): [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight33 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight25 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight17 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight9 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight38 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight30 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight22 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight14 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight6 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight35 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight27 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight19 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight11 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight32 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight24 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight16 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight8 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight37 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight29 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight21 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight13 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight5 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight34 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight26 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight18 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight10 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight39 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight31 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight23 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight15 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight7 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight36 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight28 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight20 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight12 [default0]:Params for bucket 20 (40140800 elements, 40140800 padded size): [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight1 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight0 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight62 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight3 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight63 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight49 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight2 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight55 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight61 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight60 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight59 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight58 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight57 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight56 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight53 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight50 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight54 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight52 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight51 [default0]: module.decoder.layers.2.mlp.experts.linear_fc2.weight4 [default0]:Params for bucket 21 (41287680 elements, 41287680 padded size): [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight48 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight44 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight46 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight47 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight45 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight43 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight42 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight41 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight40 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight39 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight37 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight35 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight34 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight33 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight38 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight32 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight36 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight31 [default0]:Params for bucket 22 (41287680 elements, 41287680 padded size): [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight27 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight26 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight25 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight24 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight22 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight16 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight14 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight13 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight30 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight29 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight28 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight23 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight21 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight20 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight19 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight18 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight17 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight15 [default0]:Params for bucket 23 (42929152 elements, 42929152 padded size): [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight4 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight3 [default0]: module.decoder.layers.1.mlp.shared_experts.linear_fc2.weight [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight12 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight11 [default0]: module.decoder.layers.2.mlp.router.weight [default0]: module.decoder.layers.2.self_attention.linear_kv_up_proj.weight [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight5 [default0]: module.decoder.layers.2.pre_mlp_layernorm.weight [default0]: module.decoder.layers.2.self_attention.linear_kv_up_proj.layer_norm_weight [default0]: module.decoder.layers.2.self_attention.linear_kv_down_proj.weight [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight9 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight6 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight0 [default0]: module.decoder.layers.2.self_attention.linear_q_proj.weight [default0]: module.decoder.layers.2.self_attention.linear_proj.weight [default0]: module.decoder.layers.2.input_layernorm.weight [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight7 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight2 [default0]: module.decoder.layers.1.mlp.shared_experts.linear_fc1.weight [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight8 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight1 [default0]: module.decoder.layers.2.mlp.experts.linear_fc1.weight10 [default0]:Params for bucket 24 (40140800 elements, 40140800 padded size): [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight62 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight60 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight55 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight50 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight38 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight32 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight63 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight54 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight37 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight34 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight41 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight33 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight31 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight57 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight51 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight49 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight46 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight58 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight40 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight36 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight30 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight59 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight53 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight43 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight29 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight56 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight52 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight44 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight39 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight61 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight48 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight47 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight45 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight42 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight35 [default0]:Params for bucket 25 (40140800 elements, 40140800 padded size): [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight26 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight9 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight8 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight61 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight23 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight16 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight14 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight2 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight63 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight25 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight13 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight4 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight28 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight24 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight20 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight11 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight19 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight10 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight1 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight21 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight18 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight7 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight3 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight0 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight27 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight22 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight17 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight5 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight15 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight12 [default0]: module.decoder.layers.1.mlp.experts.linear_fc2.weight6 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight62 [default0]:Params for bucket 26 (41287680 elements, 41287680 padded size): [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight60 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight57 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight59 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight58 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight56 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight55 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight52 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight51 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight47 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight46 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight54 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight53 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight50 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight49 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight48 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight45 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight44 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight43 [default0]:Params for bucket 27 (41287680 elements, 41287680 padded size): [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight42 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight41 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight38 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight39 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight37 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight33 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight31 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight29 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight28 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight26 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight25 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight40 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight36 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight35 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight34 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight32 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight30 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight27 [default0]:Params for bucket 28 (41287680 elements, 41287680 padded size): [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight21 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight20 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight19 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight14 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight13 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight12 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight9 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight8 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight24 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight22 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight23 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight18 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight17 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight16 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight15 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight11 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight10 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight7 [default0]:Params for bucket 29 (49810432 elements, 49810432 padded size): [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight6 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight4 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight3 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight5 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight1 [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight0 [default0]: module.decoder.layers.1.mlp.router.weight [default0]: module.decoder.layers.1.self_attention.linear_kv_up_proj.weight [default0]: module.decoder.layers.1.self_attention.linear_proj.weight [default0]: module.decoder.layers.1.mlp.experts.linear_fc1.weight2 [default0]: module.decoder.layers.1.pre_mlp_layernorm.weight [default0]: module.decoder.layers.1.self_attention.linear_kv_up_proj.layer_norm_weight [default0]: module.decoder.layers.1.self_attention.linear_kv_down_proj.weight [default0]: module.decoder.layers.1.self_attention.linear_q_proj.weight [default0]: module.decoder.layers.1.input_layernorm.weight [default0]: module.decoder.layers.0.mlp.linear_fc2.weight [default0]: module.decoder.layers.0.mlp.linear_fc1.weight [default0]:Params for bucket 30 (200543232 elements, 200543232 padded size): [default0]: module.decoder.layers.0.mlp.linear_fc1.layer_norm_weight [default0]: module.decoder.layers.0.self_attention.linear_q_proj.weight [default0]: module.decoder.layers.0.self_attention.linear_kv_up_proj.weight [default0]: module.embedding.word_embeddings.weight [default0]: module.decoder.layers.0.self_attention.linear_kv_up_proj.layer_norm_weight [default0]: module.decoder.layers.0.self_attention.linear_kv_down_proj.weight [default0]: module.decoder.layers.0.self_attention.linear_proj.weight [default0]: module.decoder.layers.0.input_layernorm.weight [default0]:INFO:megatron.core.optimizer:Setting up optimizer with config OptimizerConfig(optimizer='adam', lr=0.003, min_lr=0.0003, decoupled_lr=None, decoupled_min_lr=None, weight_decay=0.1, fp16=False, bf16=True, params_dtype=torch.bfloat16, use_precision_aware_optimizer=False, store_param_remainders=True, main_grads_dtype=torch.float32, main_params_dtype=torch.float32, exp_avg_dtype=torch.float32, exp_avg_sq_dtype=torch.float32, loss_scale=None, initial_loss_scale=4294967296, min_loss_scale=1.0, loss_scale_window=1000, hysteresis=2, adam_beta1=0.9, adam_beta2=0.95, adam_eps=1e-08, sgd_momentum=0.9, use_distributed_optimizer=True, overlap_param_gather_with_optimizer_step=False, optimizer_cpu_offload=False, optimizer_offload_fraction=1.0, use_torch_optimizer_for_cpu_offload=False, overlap_cpu_optimizer_d2h_h2d=False, pin_cpu_grads=True, pin_cpu_params=True, clip_grad=1.0, log_num_zeros_in_grad=True, barrier_with_L1_time=True, timers=<megatron.core.timers.Timers object at 0x7fbf60962780>, config_logger_dir='') [default0]:setting training iterations to 24000 [default0]:INFO:megatron.core.optimizer_param_scheduler:> learning rate decay style: cosine [default0]:WARNING: could not find the metadata file /data2/workspaces/FlagAI_OpenSeek/OpenSeek-Small-v1-Baseline/checkpoints/latest_checkpointed_iteration.txt [default0]: will not load any checkpoints and will start from random [default0]:[after model, optimizer, and learning rate scheduler are built] datetime: 2025-06-27 15:59:02 [default0]:> building train, validation, and test datasets ... [default0]: > datasets target sizes (minimum size): [default0]: train: 24576000 [default0]: validation: 0 [default0]: test: 0 [default0]:INFO:megatron.core.datasets.blended_megatron_dataset_config:Let split_matrix = [(0, 1.0), None, None] [default0]:> building train, validation, and test datasets for GPT ... [default0]:INFO:megatron.core.datasets.blended_megatron_dataset_builder:Building GPTDataset splits with sizes=(24576000, 0, 0) and config=GPTDatasetConfig(random_seed=42, sequence_length=4096, blend=(['../OpenSeek-Pretrain-100B/Nemotron-CC-high-actual-actual-high/part_142_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-actual-actual-low/part_62_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-actual-actual-mid/part_189_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-distill-high/part_76_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-distill-low/part_124_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-distill-mid/part_29_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-diverse_qa_pairs-high/part_244_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-diverse_qa_pairs-low/part_150_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-diverse_qa_pairs-mid/part_444_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-extract_knowledge-high/part_498_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-extract_knowledge-low/part_10_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-extract_knowledge-mid/part_144_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-knowledge_list-high/part_86_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-knowledge_list-low/part_133_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-knowledge_list-mid/part_139_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-wrap_medium-high/part_47_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-wrap_medium-low/part_11_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-wrap_medium-mid/part_97_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-low-synthetic-wrap_medium-high/part_43_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-low-synthetic-wrap_medium-low/part_10_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-low-synthetic-wrap_medium-mid/part_164_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-medium-actual-actual-high/part_92_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-medium-actual-actual-low/part_113_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-medium-actual-actual-mid/part_563_text_document', '../OpenSeek-Pretrain-100B/arxiv/007_00000_text_document', '../OpenSeek-Pretrain-100B/books/016_00007_text_document', '../OpenSeek-Pretrain-100B/code-high/part_13_text_document', '../OpenSeek-Pretrain-100B/code-low/part_36_text_document', '../OpenSeek-Pretrain-100B/code-mid/part_37_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-high/23_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-low/51_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/118_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/176_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/256_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/320_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/32_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_OpenSource-high/1_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_OpenSource-low/2_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_OpenSource-mid/3_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_arxiv-high/2_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_arxiv-low/1_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_arxiv-mid/2_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_code-high/4_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_code-low/6_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_code-mid/23_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_math-high/12_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_math-low/3_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_math-mid/5_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_wiki-high/5_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_wiki-low/5_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_wiki-mid/4_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_CC-high/74_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_CC-low/54_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_CC-mid/275_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_OpenSource-high/4_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_OpenSource-low/2_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_OpenSource-mid/6_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_arxiv-high/2_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_arxiv-low/1_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_arxiv-mid/1_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_code-high/13_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_code-low/9_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_code-mid/6_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_math-high/11_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_math-low/11_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_math-mid/29_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_wiki-high/4_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_wiki-low/6_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_wiki-mid/3_text_document', '../OpenSeek-Pretrain-100B/math-high/part_04_text_document', '../OpenSeek-Pretrain-100B/math-low/part_10_text_document', '../OpenSeek-Pretrain-100B/math-mid/part_07_text_document', '../OpenSeek-Pretrain-100B/pes2o-full-train/train-0041-of-0136_text_document', '../OpenSeek-Pretrain-100B/pes2o-full-train/train-0125-of-0136_text_document', '../OpenSeek-Pretrain-100B/pes2o-full-val/valid-0034-of-0060_text_document', '../OpenSeek-Pretrain-100B/pes2o/pubmedcentral_3_text_document', '../OpenSeek-Pretrain-100B/stack/018_00000_text_document', '../OpenSeek-Pretrain-100B/wiki/012_00000_text_document', '../OpenSeek-Pretrain-100B/zh_cc-high-loss0/part_28_text_document', '../OpenSeek-Pretrain-100B/zh_cc-high-loss1/part_59_text_document', '../OpenSeek-Pretrain-100B/zh_cc-high-loss2/part_16_text_document', '../OpenSeek-Pretrain-100B/zh_cc-medidum-loss0/part_192_text_document', '../OpenSeek-Pretrain-100B/zh_cc-medidum-loss1/part_550_text_document', '../OpenSeek-Pretrain-100B/zh_cc-medidum-loss2/part_71_text_document'], [1.1068, 0.3577, 0.7775, 0.2859, 0.1672, 0.2339, 0.5397, 0.4064, 0.5005, 0.4616, 0.067, 0.3429, 0.261, 0.1824, 0.2313, 0.8237, 0.2866, 0.667, 0.4657, 0.2005, 0.4317, 1.1397, 0.6782, 0.9175, 0.6414, 0.4696, 1.0102, 1.1403, 0.9674, 0.3755, 0.0499, 0.3608, 0.3623, 0.3704, 0.3733, 0.3631, 0.2573, 0.1638, 0.3251, 6.0237, 8.9063, 10.1376, 0.4598, 0.6857, 0.899, 1.3135, 1.653, 0.3536, 0.6314, 0.5978, 0.7909, 0.2225, 0.1797, 0.2042, 0.4081, 0.1659, 1.2828, 5.68, 7.4907, 8.9359, 0.7663, 0.4052, 0.1916, 0.5074, 0.6437, 0.6406, 0.4, 0.3564, 0.5768, 1.8165, 1.694, 1.6311, 0.687, 0.7387, 0.0143, 6.1982, 0.4229, 0.4202, 1.8171, 0.9776, 0.3725, 0.9492, 0.9236, 1.0643]), blend_per_split=None, split='1', split_matrix=[(0, 1.0), None, None], num_dataset_builder_threads=1, path_to_cache=None, mmap_bin_files=False, mock=False, tokenizer=<megatron.training.tokenizer.tokenizer._QwenTokenizerFS object at 0x7fbf5fd3f380>, mid_level_dataset_surplus=0.005, reset_position_ids=True, reset_attention_mask=True, eod_mask_loss=False, create_attention_mask=True, drop_last_partial_validation_sequence=True, add_extra_token_to_sequence=True, object_storage_cache_path=None) [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-actual-actual-high/part_142_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 3bcf97bf902bc7c1b1bdfc6f43697d5c-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 3bcf97bf902bc7c1b1bdfc6f43697d5c-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 3bcf97bf902bc7c1b1bdfc6f43697d5c-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 278453 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-actual-actual-low/part_62_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 42edf795324f414dfcabdcfd7d860a40-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 42edf795324f414dfcabdcfd7d860a40-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 42edf795324f414dfcabdcfd7d860a40-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 90001 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-actual-actual-mid/part_189_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from fbd05c4b24607c4e84548924fc59cca2-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from fbd05c4b24607c4e84548924fc59cca2-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from fbd05c4b24607c4e84548924fc59cca2-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 195608 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-distill-high/part_76_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 93b91bf5fd05a6901f85ce49182a8582-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 93b91bf5fd05a6901f85ce49182a8582-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 93b91bf5fd05a6901f85ce49182a8582-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 71916 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-distill-low/part_124_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from c156036a9186aa56bd0f678fb3c80d3f-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from c156036a9186aa56bd0f678fb3c80d3f-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from c156036a9186aa56bd0f678fb3c80d3f-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 42075 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-distill-mid/part_29_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 38419ede70ce7c575159593f3a3fc94d-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 38419ede70ce7c575159593f3a3fc94d-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 38419ede70ce7c575159593f3a3fc94d-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 58837 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-diverse_qa_pairs-high/part_244_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 4762bb70c45a00a24c261d684e5ce4ff-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 4762bb70c45a00a24c261d684e5ce4ff-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 4762bb70c45a00a24c261d684e5ce4ff-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 135775 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-diverse_qa_pairs-low/part_150_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 421b3d6f3adf7fab7d6fa68067570d8f-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 421b3d6f3adf7fab7d6fa68067570d8f-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 421b3d6f3adf7fab7d6fa68067570d8f-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 102232 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-diverse_qa_pairs-mid/part_444_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from ba00e53917af4de1938c3e89a305da94-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from ba00e53917af4de1938c3e89a305da94-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from ba00e53917af4de1938c3e89a305da94-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 125911 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-extract_knowledge-high/part_498_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 91379f2ddcb832c61f886a23d6f26843-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 91379f2ddcb832c61f886a23d6f26843-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 91379f2ddcb832c61f886a23d6f26843-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 116141 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-extract_knowledge-low/part_10_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 325354 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 325354 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 49da887f9ea0fe93926b5194b3e73e64-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 49da887f9ea0fe93926b5194b3e73e64-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 49da887f9ea0fe93926b5194b3e73e64-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 16844 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-extract_knowledge-mid/part_144_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from f1a511b8258c5b2ef7cb0880677d5320-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from f1a511b8258c5b2ef7cb0880677d5320-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from f1a511b8258c5b2ef7cb0880677d5320-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 86258 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-knowledge_list-high/part_86_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from a52b401753534e6b0add72400982b06a-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from a52b401753534e6b0add72400982b06a-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from a52b401753534e6b0add72400982b06a-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 65662 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-knowledge_list-low/part_133_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 5519d9210b1853b80c89283c5b8219bd-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 5519d9210b1853b80c89283c5b8219bd-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 5519d9210b1853b80c89283c5b8219bd-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 45891 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-knowledge_list-mid/part_139_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from ecbf550b30bfc696b0d4912fd82d990f-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from ecbf550b30bfc696b0d4912fd82d990f-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from ecbf550b30bfc696b0d4912fd82d990f-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 58196 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-wrap_medium-high/part_47_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from e4aeb3128a4705d3c4b914a618670c60-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from e4aeb3128a4705d3c4b914a618670c60-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from e4aeb3128a4705d3c4b914a618670c60-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 207235 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-wrap_medium-low/part_11_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from a9f99f617847aa8f6179da4f53b838af-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from a9f99f617847aa8f6179da4f53b838af-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from a9f99f617847aa8f6179da4f53b838af-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 72100 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-wrap_medium-mid/part_97_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default7]:(min, max) time across ranks (ms): [default7]: load-checkpoint ................................: (3.48, 10.62) [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 063fab3df418ed000462f842ac8d49ea-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 063fab3df418ed000462f842ac8d49ea-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 063fab3df418ed000462f842ac8d49ea-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 167804 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-low-synthetic-wrap_medium-high/part_43_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 92c67007e7c71328e23b10f14bbdf0d9-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 92c67007e7c71328e23b10f14bbdf0d9-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 92c67007e7c71328e23b10f14bbdf0d9-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 117162 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-low-synthetic-wrap_medium-low/part_10_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 97123868ddd599ebe18baa058e80c79d-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 97123868ddd599ebe18baa058e80c79d-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 97123868ddd599ebe18baa058e80c79d-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 50433 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-low-synthetic-wrap_medium-mid/part_164_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 31933f6459e2d65890af1f316c530035-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 31933f6459e2d65890af1f316c530035-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 31933f6459e2d65890af1f316c530035-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 108609 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-medium-actual-actual-high/part_92_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from d1c63d01256da2dbfb9fc6012b0cf457-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from d1c63d01256da2dbfb9fc6012b0cf457-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from d1c63d01256da2dbfb9fc6012b0cf457-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 286720 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-medium-actual-actual-low/part_113_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 06a4931530206c4caa9999e2a116c216-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 06a4931530206c4caa9999e2a116c216-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 06a4931530206c4caa9999e2a116c216-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 170626 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-medium-actual-actual-mid/part_563_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from cea463b205f3d64bc57cd0bf402f517a-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from cea463b205f3d64bc57cd0bf402f517a-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from cea463b205f3d64bc57cd0bf402f517a-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 230810 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/arxiv/007_00000_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 36740 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 36740 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 6443055721fcb34913a77945da3c3a0e-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 6443055721fcb34913a77945da3c3a0e-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 6443055721fcb34913a77945da3c3a0e-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 161355 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/books/016_00007_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 4969 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 4969 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 10bf636698c127d1a24bbf6d2eda2aee-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 10bf636698c127d1a24bbf6d2eda2aee-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 10bf636698c127d1a24bbf6d2eda2aee-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 118143 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/code-high/part_13_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 21cd90b13a6517160b33ca8685f946a8-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 21cd90b13a6517160b33ca8685f946a8-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 21cd90b13a6517160b33ca8685f946a8-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 254137 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/code-low/part_36_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 499c6fff9032a79c988ab8063ce949e1-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 499c6fff9032a79c988ab8063ce949e1-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 499c6fff9032a79c988ab8063ce949e1-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 286865 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/code-mid/part_37_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 52e1e8829398a339b53880f97a35f5fd-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 52e1e8829398a339b53880f97a35f5fd-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 52e1e8829398a339b53880f97a35f5fd-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 243365 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_CC-high/23_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 78a0fcb91abd174d65bb6cc0d46e617d-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 78a0fcb91abd174d65bb6cc0d46e617d-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 78a0fcb91abd174d65bb6cc0d46e617d-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 94468 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_CC-low/51_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 73459 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 73459 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 82ad0782ac038979c9eaf5146ff201a9-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 82ad0782ac038979c9eaf5146ff201a9-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 82ad0782ac038979c9eaf5146ff201a9-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 12546 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/118_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 61ededc3c5fec8599ebac2c9268839d2-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 61ededc3c5fec8599ebac2c9268839d2-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 61ededc3c5fec8599ebac2c9268839d2-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 90757 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/176_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from f6f063fadb56f7471be6fd7c52d961a9-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from f6f063fadb56f7471be6fd7c52d961a9-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from f6f063fadb56f7471be6fd7c52d961a9-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 91135 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/256_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 0fac24c40f9207ba4e1c876f67ac890f-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 0fac24c40f9207ba4e1c876f67ac890f-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 0fac24c40f9207ba4e1c876f67ac890f-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 93182 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/320_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 6e257a563aa1f477457f9d5063f31c3f-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 6e257a563aa1f477457f9d5063f31c3f-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 6e257a563aa1f477457f9d5063f31c3f-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 93904 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/32_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from c8fceab04f7a896b8a87caea00adf17e-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from c8fceab04f7a896b8a87caea00adf17e-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from c8fceab04f7a896b8a87caea00adf17e-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 91340 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_OpenSource-high/1_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 6b309498174da0deb341abe9aa36a0e8-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 6b309498174da0deb341abe9aa36a0e8-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 6b309498174da0deb341abe9aa36a0e8-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 64738 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_OpenSource-low/2_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 398e9530d4c8410e322ac338179666ca-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 398e9530d4c8410e322ac338179666ca-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 398e9530d4c8410e322ac338179666ca-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 41218 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_OpenSource-mid/3_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from da0fb5525d01182e1daf66b4dbd842b4-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from da0fb5525d01182e1daf66b4dbd842b4-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from da0fb5525d01182e1daf66b4dbd842b4-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 81781 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_arxiv-high/2_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 256516 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 256516 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 5257e77c1f3591b9cf58683b58f3dcc3-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 5257e77c1f3591b9cf58683b58f3dcc3-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 5257e77c1f3591b9cf58683b58f3dcc3-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 1515440 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_arxiv-low/1_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 097db078c0fd21058b81a805201e1740-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 097db078c0fd21058b81a805201e1740-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 097db078c0fd21058b81a805201e1740-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 2240642 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_arxiv-mid/2_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from de2315b46c9e398c3e52816dce050a9a-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from de2315b46c9e398c3e52816dce050a9a-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from de2315b46c9e398c3e52816dce050a9a-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 2550407 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_code-high/4_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from c33b0b590a676cb05db1bdb9a99c5b2a-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from c33b0b590a676cb05db1bdb9a99c5b2a-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from c33b0b590a676cb05db1bdb9a99c5b2a-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 115665 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_code-low/6_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 0a144fd0007b87526df5be9acef24430-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 0a144fd0007b87526df5be9acef24430-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 0a144fd0007b87526df5be9acef24430-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 172518 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_code-mid/23_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from f79878c937ae3ea237f9aecc49b2185f-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from f79878c937ae3ea237f9aecc49b2185f-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from f79878c937ae3ea237f9aecc49b2185f-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 226180 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_math-high/12_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 5ece26b572b5dca7ffe7945c6c9226c7-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 5ece26b572b5dca7ffe7945c6c9226c7-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 5ece26b572b5dca7ffe7945c6c9226c7-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 330448 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_math-low/3_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 23783151274dfea0577aea5f996dc236-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 23783151274dfea0577aea5f996dc236-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 23783151274dfea0577aea5f996dc236-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 415859 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_math-mid/5_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 647d18ed6efe43a6a42bddfeabba04f1-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 647d18ed6efe43a6a42bddfeabba04f1-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 647d18ed6efe43a6a42bddfeabba04f1-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 88947 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_wiki-high/5_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 167169b90da1e60c19514db0924b1e20-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 167169b90da1e60c19514db0924b1e20-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 167169b90da1e60c19514db0924b1e20-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 158858 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_wiki-low/5_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from ce096f4bf7b8552c29fea089860705c4-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from ce096f4bf7b8552c29fea089860705c4-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from ce096f4bf7b8552c29fea089860705c4-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 150385 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_wiki-mid/4_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from b4c94e45cf9ca3107266571ad6b407e2-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from b4c94e45cf9ca3107266571ad6b407e2-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from b4c94e45cf9ca3107266571ad6b407e2-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 198961 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_CC-high/74_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from a8fa8dd8d69d1cd8935b3457875c39c4-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from a8fa8dd8d69d1cd8935b3457875c39c4-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from a8fa8dd8d69d1cd8935b3457875c39c4-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 55987 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_CC-low/54_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from f461ed8995dac3b75450c24fc74ccf40-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from f461ed8995dac3b75450c24fc74ccf40-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from f461ed8995dac3b75450c24fc74ccf40-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 45202 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_CC-mid/275_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 9a44f36019d65846dd82c700062bc27c-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 9a44f36019d65846dd82c700062bc27c-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 9a44f36019d65846dd82c700062bc27c-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 51384 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_OpenSource-high/4_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 05388d8ae2767f997f3a327b6162fa0c-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 05388d8ae2767f997f3a327b6162fa0c-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 05388d8ae2767f997f3a327b6162fa0c-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 102662 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_OpenSource-low/2_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 99d51016a10dfaaaf8aa11f19ca47eec-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 99d51016a10dfaaaf8aa11f19ca47eec-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 99d51016a10dfaaaf8aa11f19ca47eec-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 41745 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_OpenSource-mid/6_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 8376d733799a069256ae09b1bcd6dcab-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 8376d733799a069256ae09b1bcd6dcab-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 8376d733799a069256ae09b1bcd6dcab-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 322718 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_arxiv-high/2_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 256516 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 256516 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 3a33c9308a021d4054fa13c21cf4952f-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 3a33c9308a021d4054fa13c21cf4952f-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 3a33c9308a021d4054fa13c21cf4952f-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 1428961 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_arxiv-low/1_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 9efb6b5b415537b5bc066d9cc2c620b3-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 9efb6b5b415537b5bc066d9cc2c620b3-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 9efb6b5b415537b5bc066d9cc2c620b3-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 1884499 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_arxiv-mid/1_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 13f6793fe99fe92439722cddaf40727e-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 13f6793fe99fe92439722cddaf40727e-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 13f6793fe99fe92439722cddaf40727e-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 2248083 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_code-high/13_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 55f9b728813d421a6eda80c4e4386d81-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 55f9b728813d421a6eda80c4e4386d81-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 55f9b728813d421a6eda80c4e4386d81-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 192791 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_code-low/9_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from af2b2f630340e8986a7fa73fde612311-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from af2b2f630340e8986a7fa73fde612311-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from af2b2f630340e8986a7fa73fde612311-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 101935 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_code-mid/6_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from da5b6dc21e950c12d3ac425bfd1f091f-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from da5b6dc21e950c12d3ac425bfd1f091f-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from da5b6dc21e950c12d3ac425bfd1f091f-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 48202 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_math-high/11_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from ad21fc502df49664e479a402ec05d322-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from ad21fc502df49664e479a402ec05d322-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from ad21fc502df49664e479a402ec05d322-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 127661 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_math-low/11_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 26ec788a6472d7a4fc2abb1fd801bd83-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 26ec788a6472d7a4fc2abb1fd801bd83-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 26ec788a6472d7a4fc2abb1fd801bd83-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 161943 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_math-mid/29_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from a4ff47cc44a1bcd08f765fc5846d53fb-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from a4ff47cc44a1bcd08f765fc5846d53fb-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from a4ff47cc44a1bcd08f765fc5846d53fb-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 161166 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_wiki-high/4_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 9c88f9a84c38df50a45e7390a09215f0-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 9c88f9a84c38df50a45e7390a09215f0-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 9c88f9a84c38df50a45e7390a09215f0-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 100623 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_wiki-low/6_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from f7239aa9de74201060aed61b1cdf0c6b-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from f7239aa9de74201060aed61b1cdf0c6b-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from f7239aa9de74201060aed61b1cdf0c6b-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 89674 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_wiki-mid/3_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 75221ad5995f5e1b284e1451bc21e7ea-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 75221ad5995f5e1b284e1451bc21e7ea-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 75221ad5995f5e1b284e1451bc21e7ea-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 145122 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/math-high/part_04_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from ef51ee55d8f6603934f08ce635314fad-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from ef51ee55d8f6603934f08ce635314fad-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from ef51ee55d8f6603934f08ce635314fad-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 456998 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/math-low/part_10_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 183681f26924ef7e06ab027733f0490e-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 183681f26924ef7e06ab027733f0490e-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 183681f26924ef7e06ab027733f0490e-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 426167 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/math-mid/part_07_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 2c02a9a76de03db0d4cbd2b78a34e2e8-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 2c02a9a76de03db0d4cbd2b78a34e2e8-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 2c02a9a76de03db0d4cbd2b78a34e2e8-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 410354 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/pes2o-full-train/train-0041-of-0136_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 111715 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 111715 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 4bedbf63df1ea1c142930c7b58689315-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 4bedbf63df1ea1c142930c7b58689315-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 4bedbf63df1ea1c142930c7b58689315-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 172833 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/pes2o-full-train/train-0125-of-0136_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 120151 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 120151 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 8c143921153f51208327e9e6c80f3996-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 8c143921153f51208327e9e6c80f3996-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 8c143921153f51208327e9e6c80f3996-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 185836 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/pes2o-full-val/valid-0034-of-0060_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 2066 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 2066 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 17b24baded5fb547c2bdd1eca38d9e8d-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 17b24baded5fb547c2bdd1eca38d9e8d-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 17b24baded5fb547c2bdd1eca38d9e8d-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 3587 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/pes2o/pubmedcentral_3_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 817bacd90c33f000963995212597faeb-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 817bacd90c33f000963995212597faeb-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 817bacd90c33f000963995212597faeb-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 1559325 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/stack/018_00000_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 725493 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 725493 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 70fbfb40decd8fd580ba438c4fe3a326-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 70fbfb40decd8fd580ba438c4fe3a326-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 70fbfb40decd8fd580ba438c4fe3a326-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 106399 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/wiki/012_00000_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 952137 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 952137 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 0f1298d7bcb5257da1d1fed0af30cf27-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 0f1298d7bcb5257da1d1fed0af30cf27-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 0f1298d7bcb5257da1d1fed0af30cf27-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 105713 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/zh_cc-high-loss0/part_28_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1014022 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1014022 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 8a41ddce0a4e9446a2a38ecaf18b8319-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 8a41ddce0a4e9446a2a38ecaf18b8319-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 8a41ddce0a4e9446a2a38ecaf18b8319-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 457136 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/zh_cc-high-loss1/part_59_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1024772 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1024772 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 90b19f2d251220dc983bbbbee1bbaa16-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 90b19f2d251220dc983bbbbee1bbaa16-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 90b19f2d251220dc983bbbbee1bbaa16-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 245948 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/zh_cc-high-loss2/part_16_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1006257 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1006257 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the document index from 89ab9dff4a2d78068a6f282a80ae15d6-GPTDataset-train-document_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 89ab9dff4a2d78068a6f282a80ae15d6-GPTDataset-train-sample_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 89ab9dff4a2d78068a6f282a80ae15d6-GPTDataset-train-shuffle_index.npy [default0]:INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 93708 [default0]:INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/zh_cc-medidum-loss0/part_192_text_document.idx [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers [default0]:INFO:megatron.core.datasets.indexed_dataset: Extract the document indices [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1003089 [default0]:INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1003089 [default0]:INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices -
如果程序运行正常,大约 1-2 分钟后,您可以从 OpenSeek 根目录执行以下命令:
grep "iteration.*consumed samples" OpenSeek-Small-v1-Baseline/logs/host_0_localhost.output -
如果输出类似于以下示例,则表示您的程序已成功启动:
[default0]: [2025-05-27 15:23:07] iteration 1/ 24000 | consumed samples: 1024 | elapsed time per iteration (ms): 271607.0 | throughput per GPU (TFLOP/s/GPU): 40.4 | learning rate: 1.500000E-06 | global batch size: 1024 | lm loss: 1.192634E+01 | load_balancing_loss: 1.041994E+00 | loss scale: 1.0 | grad norm: 5.960 | num zeros: 0.0 | params norm: 238.330 | number of skipped iterations: 0 | number of nan iterations: 0 |
-
finished creating GPT datasets ...
[after dataloaders are built] datetime: 2025-06-27 12:23:34
done with setup ...
(min, max) time across ranks (ms):
model-and-optimizer-setup ......................: (320.15, 320.15)
train/valid/test-data-iterators-setup ..........: (3543.10, 3543.10)
training ...
Setting rerun_state_machine.current_iteration to 0...
[before the start of training step] datetime: 2025-06-27 12:23:34
[2025-06-27 12:27:53] iteration 1/ 24000 | consumed samples: 1024 | elapsed time per iteration (ms): 258947.6 | throughput per GPU (TFLOP/s/GPU): 42.3 | learning rate: 1.500000E-06 | global batch size: 1024 | lm loss: 1.192634E+01 | load_balancing_loss: 1.041995E+00 | loss scale: 1.0 | grad norm: 5.960 | num zeros: 0.0 | params norm: 238.330 | number of skipped iterations: 0 | number of nan iterations: 0 |
Number of parameters in transformer block in billions: 1.20
Number of parameters in embedding layers in billions: 0.19
Total number of parameters in billions: 1.39
Number of parameters in most loaded shard in billions: 1.3942
Theoretical memory footprints: weight and optimizer=23933.59 MB
[Rank 0] (after 1 iterations) memory (MB) | allocated: 24119.04443359375 | max allocated: 24119.55126953125 | reserved: 26416.0 | max reserved: 26416.0
cat
训练日志
[2025-06-27 12:23:26,305] [INFO] [real_accelerator.py:254:get_accelerator] Setting ds_accelerator to cuda (auto detect)
using world size: 1, data-parallel size: 1, context-parallel size: 1, hierarchical context-parallel sizes: Nonetensor-model-parallel size: 1, encoder-tensor-model-parallel size: 0, pipeline-model-parallel size: 1, encoder-pipeline-model-parallel size: 0
WARNING: overriding default arguments for tokenizer_type:GPT2BPETokenizer with tokenizer_type:QwenTokenizerFS
Number of virtual stages per pipeline stage: None
using torch.bfloat16 for parameters ...
------------------------ arguments ------------------------
account_for_embedding_in_pipeline_split ......... False
account_for_loss_in_pipeline_split .............. False
accumulate_allreduce_grads_in_fp32 .............. True
adam_beta1 ...................................... 0.9
adam_beta2 ...................................... 0.95
adam_eps ........................................ 1e-08
add_bias_linear ................................. False
add_position_embedding .......................... False
add_qkv_bias .................................... False
adlr_autoresume ................................. False
adlr_autoresume_interval ........................ 1000
align_grad_reduce ............................... True
align_param_gather .............................. False
app_tag_run_name ................................ None
app_tag_run_version ............................. 0.0.0
apply_layernorm_1p .............................. False
apply_query_key_layer_scaling ................... False
apply_residual_connection_post_layernorm ........ False
apply_rope_fusion ............................... False
apply_sft_dataset_separated_loss_mask_if_existed False
async_save ...................................... None
async_tensor_model_parallel_allreduce ........... True
attention_backend ............................... AttnBackend.auto
attention_dropout ............................... 0.0
attention_softmax_in_fp32 ....................... True
auto_detect_ckpt_format ......................... False
auto_skip_spiky_loss ............................ False
auto_tune ....................................... False
barrier_with_L1_time ............................ True
bert_binary_head ................................ True
bert_embedder_type .............................. megatron
bert_load ....................................... None
bf16 ............................................ True
bias_dropout_fusion ............................. True
bias_gelu_fusion ................................ False
bias_swiglu_fusion .............................. True
biencoder_projection_dim ........................ 0
biencoder_shared_query_context_model ............ False
block_data_path ................................. None
calc_ft_timeouts ................................ False
calculate_per_token_loss ........................ False
check_for_large_grads ........................... False
check_for_nan_in_loss_and_grad .................. True
check_for_spiky_loss ............................ False
check_weight_hash_across_dp_replicas_interval ... None
ckpt_assume_constant_structure .................. False
ckpt_convert_format ............................. None
ckpt_convert_save ............................... None
ckpt_convert_update_legacy_dist_opt_format ...... False
ckpt_format ..................................... torch
ckpt_fully_parallel_load ........................ False
ckpt_fully_parallel_save ........................ True
ckpt_fully_parallel_save_deprecated ............. False
ckpt_step ....................................... None
classes_fraction ................................ 1.0
clip_grad ....................................... 1.0
clone_scatter_output_in_embedding ............... True
config_logger_dir ...............................
consumed_train_samples .......................... 0
consumed_valid_samples .......................... 0
context_parallel_size ........................... 1
cp_comm_type .................................... ['p2p']
create_attention_mask_in_dataloader ............. True
cross_entropy_fusion_impl ....................... native
cross_entropy_loss_fusion ....................... False
cuda_graph_scope ................................ full
cuda_graph_warmup_steps ......................... 3
data_args_path .................................. None
data_cache_path ................................. None
data_parallel_random_init ....................... False
data_parallel_sharding_strategy ................. no_shard
data_parallel_size .............................. 1
data_path ....................................... ['1.1068', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-actual-actual-high/part_142_text_document', '0.3577', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-actual-actual-low/part_62_text_document', '0.7775', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-actual-actual-mid/part_189_text_document', '0.2859', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-distill-high/part_76_text_document', '0.1672', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-distill-low/part_124_text_document', '0.2339', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-distill-mid/part_29_text_document', '0.5397', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-diverse_qa_pairs-high/part_244_text_document', '0.4064', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-diverse_qa_pairs-low/part_150_text_document', '0.5005', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-diverse_qa_pairs-mid/part_444_text_document', '0.4616', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-extract_knowledge-high/part_498_text_document', '0.067', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-extract_knowledge-low/part_10_text_document', '0.3429', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-extract_knowledge-mid/part_144_text_document', '0.261', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-knowledge_list-high/part_86_text_document', '0.1824', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-knowledge_list-low/part_133_text_document', '0.2313', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-knowledge_list-mid/part_139_text_document', '0.8237', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-wrap_medium-high/part_47_text_document', '0.2866', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-wrap_medium-low/part_11_text_document', '0.667', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-wrap_medium-mid/part_97_text_document', '0.4657', '../OpenSeek-Pretrain-100B/Nemotron-CC-low-synthetic-wrap_medium-high/part_43_text_document', '0.2005', '../OpenSeek-Pretrain-100B/Nemotron-CC-low-synthetic-wrap_medium-low/part_10_text_document', '0.4317', '../OpenSeek-Pretrain-100B/Nemotron-CC-low-synthetic-wrap_medium-mid/part_164_text_document', '1.1397', '../OpenSeek-Pretrain-100B/Nemotron-CC-medium-actual-actual-high/part_92_text_document', '0.6782', '../OpenSeek-Pretrain-100B/Nemotron-CC-medium-actual-actual-low/part_113_text_document', '0.9175', '../OpenSeek-Pretrain-100B/Nemotron-CC-medium-actual-actual-mid/part_563_text_document', '0.6414', '../OpenSeek-Pretrain-100B/arxiv/007_00000_text_document', '0.4696', '../OpenSeek-Pretrain-100B/books/016_00007_text_document', '1.0102', '../OpenSeek-Pretrain-100B/code-high/part_13_text_document', '1.1403', '../OpenSeek-Pretrain-100B/code-low/part_36_text_document', '0.9674', '../OpenSeek-Pretrain-100B/code-mid/part_37_text_document', '0.3755', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-high/23_text_document', '0.0499', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-low/51_text_document', '0.3608', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/118_text_document', '0.3623', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/176_text_document', '0.3704', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/256_text_document', '0.3733', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/320_text_document', '0.3631', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/32_text_document', '0.2573', '../OpenSeek-Pretrain-100B/cot_synthesis2_OpenSource-high/1_text_document', '0.1638', '../OpenSeek-Pretrain-100B/cot_synthesis2_OpenSource-low/2_text_document', '0.3251', '../OpenSeek-Pretrain-100B/cot_synthesis2_OpenSource-mid/3_text_document', '6.0237', '../OpenSeek-Pretrain-100B/cot_synthesis2_arxiv-high/2_text_document', '8.9063', '../OpenSeek-Pretrain-100B/cot_synthesis2_arxiv-low/1_text_document', '10.1376', '../OpenSeek-Pretrain-100B/cot_synthesis2_arxiv-mid/2_text_document', '0.4598', '../OpenSeek-Pretrain-100B/cot_synthesis2_code-high/4_text_document', '0.6857', '../OpenSeek-Pretrain-100B/cot_synthesis2_code-low/6_text_document', '0.899', '../OpenSeek-Pretrain-100B/cot_synthesis2_code-mid/23_text_document', '1.3135', '../OpenSeek-Pretrain-100B/cot_synthesis2_math-high/12_text_document', '1.653', '../OpenSeek-Pretrain-100B/cot_synthesis2_math-low/3_text_document', '0.3536', '../OpenSeek-Pretrain-100B/cot_synthesis2_math-mid/5_text_document', '0.6314', '../OpenSeek-Pretrain-100B/cot_synthesis2_wiki-high/5_text_document', '0.5978', '../OpenSeek-Pretrain-100B/cot_synthesis2_wiki-low/5_text_document', '0.7909', '../OpenSeek-Pretrain-100B/cot_synthesis2_wiki-mid/4_text_document', '0.2225', '../OpenSeek-Pretrain-100B/cot_synthesis_CC-high/74_text_document', '0.1797', '../OpenSeek-Pretrain-100B/cot_synthesis_CC-low/54_text_document', '0.2042', '../OpenSeek-Pretrain-100B/cot_synthesis_CC-mid/275_text_document', '0.4081', '../OpenSeek-Pretrain-100B/cot_synthesis_OpenSource-high/4_text_document', '0.1659', '../OpenSeek-Pretrain-100B/cot_synthesis_OpenSource-low/2_text_document', '1.2828', '../OpenSeek-Pretrain-100B/cot_synthesis_OpenSource-mid/6_text_document', '5.68', '../OpenSeek-Pretrain-100B/cot_synthesis_arxiv-high/2_text_document', '7.4907', '../OpenSeek-Pretrain-100B/cot_synthesis_arxiv-low/1_text_document', '8.9359', '../OpenSeek-Pretrain-100B/cot_synthesis_arxiv-mid/1_text_document', '0.7663', '../OpenSeek-Pretrain-100B/cot_synthesis_code-high/13_text_document', '0.4052', '../OpenSeek-Pretrain-100B/cot_synthesis_code-low/9_text_document', '0.1916', '../OpenSeek-Pretrain-100B/cot_synthesis_code-mid/6_text_document', '0.5074', '../OpenSeek-Pretrain-100B/cot_synthesis_math-high/11_text_document', '0.6437', '../OpenSeek-Pretrain-100B/cot_synthesis_math-low/11_text_document', '0.6406', '../OpenSeek-Pretrain-100B/cot_synthesis_math-mid/29_text_document', '0.4', '../OpenSeek-Pretrain-100B/cot_synthesis_wiki-high/4_text_document', '0.3564', '../OpenSeek-Pretrain-100B/cot_synthesis_wiki-low/6_text_document', '0.5768', '../OpenSeek-Pretrain-100B/cot_synthesis_wiki-mid/3_text_document', '1.8165', '../OpenSeek-Pretrain-100B/math-high/part_04_text_document', '1.694', '../OpenSeek-Pretrain-100B/math-low/part_10_text_document', '1.6311', '../OpenSeek-Pretrain-100B/math-mid/part_07_text_document', '0.687', '../OpenSeek-Pretrain-100B/pes2o-full-train/train-0041-of-0136_text_document', '0.7387', '../OpenSeek-Pretrain-100B/pes2o-full-train/train-0125-of-0136_text_document', '0.0143', '../OpenSeek-Pretrain-100B/pes2o-full-val/valid-0034-of-0060_text_document', '6.1982', '../OpenSeek-Pretrain-100B/pes2o/pubmedcentral_3_text_document', '0.4229', '../OpenSeek-Pretrain-100B/stack/018_00000_text_document', '0.4202', '../OpenSeek-Pretrain-100B/wiki/012_00000_text_document', '1.8171', '../OpenSeek-Pretrain-100B/zh_cc-high-loss0/part_28_text_document', '0.9776', '../OpenSeek-Pretrain-100B/zh_cc-high-loss1/part_59_text_document', '0.3725', '../OpenSeek-Pretrain-100B/zh_cc-high-loss2/part_16_text_document', '0.9492', '../OpenSeek-Pretrain-100B/zh_cc-medidum-loss0/part_192_text_document', '0.9236', '../OpenSeek-Pretrain-100B/zh_cc-medidum-loss1/part_550_text_document', '1.0643', '../OpenSeek-Pretrain-100B/zh_cc-medidum-loss2/part_71_text_document']
data_per_class_fraction ......................... 1.0
data_sharding ................................... True
dataloader_type ................................. single
ddp_average_in_collective ....................... False
ddp_bucket_size ................................. None
ddp_num_buckets ................................. None
ddp_pad_buckets_for_high_nccl_busbw ............. False
decoder_first_pipeline_num_layers ............... None
decoder_last_pipeline_num_layers ................ None
decoder_num_layers .............................. None
decoder_seq_length .............................. None
decoupled_lr .................................... None
decoupled_min_lr ................................ None
decrease_batch_size_if_needed ................... False
defer_embedding_wgrad_compute ................... False
deprecated_use_mcore_models ..................... False
deterministic_mode .............................. False
dino_bottleneck_size ............................ 256
dino_freeze_last_layer .......................... 1
dino_head_hidden_size ........................... 2048
dino_local_crops_number ......................... 10
dino_local_img_size ............................. 96
dino_norm_last_layer ............................ False
dino_teacher_temp ............................... 0.07
dino_warmup_teacher_temp ........................ 0.04
dino_warmup_teacher_temp_epochs ................. 30
disable_bf16_reduced_precision_matmul ........... False
disable_mamba_mem_eff_path ...................... False
disable_straggler_on_startup .................... False
dist_ckpt_format_deprecated ..................... None
dist_ckpt_strictness ............................ assume_ok_unexpected
distribute_saved_activations .................... False
distributed_backend ............................. nccl
distributed_timeout_minutes ..................... 10
embedding_path .................................. None
empty_unused_memory_level ....................... 0
enable_cuda_graph ............................... False
enable_ft_package ............................... False
enable_gloo_process_groups ...................... True
enable_hetero ................................... False
enable_msc ...................................... True
enable_one_logger ............................... True
encoder_num_layers .............................. 6
encoder_pipeline_model_parallel_size ............ 0
encoder_seq_length .............................. 4096
encoder_tensor_model_parallel_size .............. 0
end_weight_decay ................................ 0.1
eod_mask_loss ................................... False
error_injection_rate ............................ 0
error_injection_type ............................ transient_error
eval_interval ................................... 1000
eval_iters ...................................... 0
evidence_data_path .............................. None
exit_duration_in_mins ........................... None
exit_interval ................................... None
exit_on_missing_checkpoint ...................... False
exit_signal_handler ............................. False
exp_avg_dtype ................................... torch.float32
exp_avg_sq_dtype ................................ torch.float32
expert_model_parallel_size ...................... 1
expert_tensor_parallel_size ..................... 1
expert_tensor_parallel_size_per_process_mesh .... None
external_cuda_graph ............................. False
extra_eval_interval ............................. None
extra_valid_data_path ........................... None
ffn_hidden_size ................................. 7168
finetune ........................................ False
finetune_dataset_type ........................... None
first_last_layers_bf16 .......................... False
flash_decode .................................... False
fp16 ............................................ False
fp16_lm_cross_entropy ........................... False
fp32_residual_connection ........................ False
fp8 ............................................. None
fp8_amax_compute_algo ........................... most_recent
fp8_amax_history_len ............................ 1
fp8_interval .................................... 1
fp8_margin ...................................... 0
fp8_param_gather ................................ False
fp8_recipe ...................................... delayed
fp8_wgrad ....................................... True
global_batch_size ............................... 1024
grad_reduce_in_bf16 ............................. False
gradient_accumulation_fusion .................... True
gradient_reduce_div_fusion ...................... True
group_query_attention ........................... False
head_lr_mult .................................... 1.0
hetero_current_device_type ...................... None
hetero_device_types ............................. None
hetero_pipeline_layer_split ..................... None
hetero_process_meshes ........................... None
hetero_use_cpu_communication .................... False
heterogeneous_layers_config_encoded_json ........ None
heterogeneous_layers_config_path ................ None
hidden_dim_multiplier ........................... None
hidden_dropout .................................. 0.0
hidden_size ..................................... 1280
hierarchical_context_parallel_sizes ............. None
hybrid_attention_ratio .......................... 0.0
hybrid_mlp_ratio ................................ 0.0
hybrid_override_pattern ......................... None
hysteresis ...................................... 2
ict_head_size ................................... None
ict_load ........................................ None
img_h ........................................... 224
img_w ........................................... 224
indexer_batch_size .............................. 128
indexer_log_interval ............................ 1000
inference_batch_times_seqlen_threshold .......... -1
inference_dynamic_batching ...................... False
inference_dynamic_batching_buffer_guaranteed_fraction 0.2
inference_dynamic_batching_buffer_overflow_factor None
inference_dynamic_batching_buffer_size_gb ....... 40.0
inference_dynamic_batching_chunk_size ........... 256
inference_dynamic_batching_max_requests_override None
inference_dynamic_batching_max_tokens_override .. None
inference_max_batch_size ........................ 8
inference_max_seq_length ........................ 2560
inference_rng_tracker ........................... False
init_method_std ................................. 0.006
init_method_xavier_uniform ...................... False
init_model_with_meta_device ..................... False
initial_loss_scale .............................. 4294967296
is_hybrid_model ................................. False
iter_per_epoch .................................. 1250
iterations_to_skip .............................. []
keep_fp8_transpose_cache_when_using_custom_fsdp . False
kv_channels ..................................... 128
kv_lora_rank .................................... 512
lazy_mpu_init ................................... None
load ............................................ /data2/workspaces/FlagAI_OpenSeek/OpenSeek-Small-v1-Baseline/checkpoints
local_rank ...................................... 0
log_interval .................................... 1
log_loss_scale_to_tensorboard ................... True
log_memory_to_tensorboard ....................... True
log_num_zeros_in_grad ........................... True
log_params_norm ................................. True
log_progress .................................... False
log_straggler ................................... False
log_throughput .................................. True
log_timers_to_tensorboard ....................... True
log_validation_ppl_to_tensorboard ............... True
log_world_size_to_tensorboard ................... False
logging_level ................................... None
loss_scale ...................................... None
loss_scale_window ............................... 1000
lr .............................................. 0.003
lr_decay_iters .................................. None
lr_decay_samples ................................ None
lr_decay_stablelm2_alpha ........................ 1.0
lr_decay_stablelm2_beta ......................... 0.0
lr_decay_stablelm2_cosine_max_lr ................ None
lr_decay_stablelm2_cosine_period_samples ........ 0
lr_decay_stablelm2_cosine_samples ............... 0
lr_decay_stablelm2_decay_samples ................ 0
lr_decay_stablelm2_rsqrt_samples ................ 0
lr_decay_style .................................. cosine
lr_warmup_fraction .............................. None
lr_warmup_init .................................. 0.0
lr_warmup_iters ................................. 0
lr_warmup_samples ............................... 2048000
lr_wsd_decay_iters .............................. None
lr_wsd_decay_samples ............................ None
lr_wsd_decay_style .............................. exponential
main_grads_dtype ................................ torch.float32
main_params_dtype ............................... torch.float32
make_vocab_size_divisible_by .................... 64
mamba_head_dim .................................. 64
mamba_num_groups ................................ 8
mamba_num_heads ................................. None
mamba_state_dim ................................. 128
manual_gc ....................................... False
manual_gc_eval .................................. True
manual_gc_interval .............................. 0
mask_factor ..................................... 1.0
mask_prob ....................................... 0.15
mask_type ....................................... random
masked_softmax_fusion ........................... True
max_position_embeddings ......................... 4096
max_tokens_to_oom ............................... 12000
memory_snapshot_path ............................ snapshot.pickle
merge_file ...................................... None
micro_batch_size ................................ 1
microbatch_group_size_per_vp_stage .............. None
mid_level_dataset_surplus ....................... 0.005
min_loss_scale .................................. 1.0
min_lr .......................................... 0.0003
mlp_chunks_for_prefill .......................... 1
mmap_bin_files .................................. False
mock_data ....................................... False
moe_aux_loss_coeff .............................. 0.0001
moe_enable_deepep ............................... False
moe_expert_capacity_factor ...................... None
moe_extended_tp ................................. False
moe_ffn_hidden_size ............................. 896
moe_grouped_gemm ................................ True
moe_input_jitter_eps ............................ None
moe_layer_freq .................................. [0, 1, 1, 1, 1, 1]
moe_layer_recompute ............................. False
moe_pad_expert_input_to_capacity ................ False
moe_per_layer_logging ........................... False
moe_permute_fusion .............................. False
moe_router_bias_update_rate ..................... 0.001
moe_router_dtype ................................ fp32
moe_router_enable_expert_bias ................... True
moe_router_group_topk ........................... 1
moe_router_load_balancing_type .................. seq_aux_loss
moe_router_num_groups ........................... 1
moe_router_pre_softmax .......................... False
moe_router_score_function ....................... sigmoid
moe_router_topk ................................. 6
moe_router_topk_scaling_factor .................. 2.446
moe_shared_expert_intermediate_size ............. 1792
moe_shared_expert_overlap ....................... False
moe_token_dispatcher_type ....................... alltoall
moe_token_drop_policy ........................... probs
moe_use_legacy_grouped_gemm ..................... False
moe_use_upcycling ............................... False
moe_z_loss_coeff ................................ None
mrope_section ................................... None
mscale .......................................... 1.0
mscale_all_dim .................................. 1.0
mtp_loss_coeff .................................. 0.3
mtp_loss_scaling_factor ......................... 0.1
mtp_num_layers .................................. None
multi_latent_attention .......................... True
multiple_of ..................................... None
nccl_all_reduce_for_prefill ..................... False
nccl_communicator_config_path ................... None
no_load_optim ................................... None
no_load_rng ..................................... None
no_persist_layer_norm ........................... False
no_rope_freq .................................... None
no_save_optim ................................... None
no_save_rng ..................................... None
no_shared_fs .................................... False
non_persistent_ckpt_type ........................ None
non_persistent_global_ckpt_dir .................. None
non_persistent_local_ckpt_algo .................. fully_parallel
non_persistent_local_ckpt_dir ................... None
non_persistent_save_interval .................... None
norm_epsilon .................................... 1e-06
norm_init_weight ................................ None
normalization ................................... RMSNorm
num_attention_heads ............................. 10
num_channels .................................... 3
num_classes ..................................... 1000
num_dataset_builder_threads ..................... 1
num_distributed_optimizer_instances ............. 1
num_experts ..................................... 64
num_layers ...................................... 6
num_layers_at_end_in_bf16 ....................... 1
num_layers_at_start_in_bf16 ..................... 1
num_layers_per_virtual_pipeline_stage ........... None
num_mtp_predictor ............................... 0
num_query_groups ................................ 10
num_virtual_stages_per_pipeline_rank ............ None
num_workers ..................................... 4
object_storage_cache_path ....................... None
one_logger_async ................................ False
one_logger_project .............................. megatron-lm
one_logger_run_name ............................. None
onnx_safe ....................................... None
openai_gelu ..................................... False
optimizer ....................................... adam
optimizer_cpu_offload ........................... False
optimizer_offload_fraction ...................... 1.0
output_bert_embeddings .......................... False
overlap_cpu_optimizer_d2h_h2d ................... False
overlap_grad_reduce ............................. True
overlap_p2p_comm ................................ False
overlap_p2p_comm_warmup_flush ................... False
overlap_param_gather ............................ True
overlap_param_gather_with_optimizer_step ........ False
override_opt_param_scheduler .................... False
params_dtype .................................... torch.bfloat16
patch_dim ....................................... 16
per_split_data_args_path ........................ None
perform_initialization .......................... True
pin_cpu_grads ................................... True
pin_cpu_params .................................. True
pipeline_model_parallel_comm_backend ............ None
pipeline_model_parallel_size .................... 1
pipeline_model_parallel_split_rank .............. None
position_embedding_type ......................... rope
pretrained_checkpoint ........................... None
profile ......................................... False
profile_ranks ................................... [0]
profile_step_end ................................ 12
profile_step_start .............................. 10
q_lora_rank ..................................... None
qk_head_dim ..................................... 128
qk_layernorm .................................... True
qk_layernorm_hidden_dim ......................... False
qk_pos_emb_head_dim ............................. 64
query_in_block_prob ............................. 0.1
rampup_batch_size ............................... None
rampup_save_interval ............................ None
rank ............................................ 0
recompute_granularity ........................... full
recompute_granularity_per_stage_micro_batch ..... None
recompute_method ................................ uniform
recompute_method_per_stage_micro_batch .......... None
recompute_modules ............................... None
recompute_num_layers ............................ 6
recompute_num_layers_per_stage_micro_batch ...... None
record_memory_history ........................... False
relative_attention_max_distance ................. 128
relative_attention_num_buckets .................. 32
replication ..................................... False
replication_factor .............................. 2
replication_jump ................................ None
rerun_mode ...................................... disabled
reset_attention_mask ............................ True
reset_position_ids .............................. True
result_rejected_tracker_filename ................ None
retriever_report_topk_accuracies ................ []
retriever_score_scaling ......................... False
retriever_seq_length ............................ 256
retro_add_retriever ............................. False
retro_attention_gate ............................ 1
retro_cyclic_train_iters ........................ None
retro_encoder_attention_dropout ................. 0.1
retro_encoder_hidden_dropout .................... 0.1
retro_encoder_layers ............................ 2
retro_num_neighbors ............................. 2
retro_num_retrieved_chunks ...................... 2
retro_project_dir ............................... None
retro_verify_neighbor_count ..................... True
rope_scaling_factor ............................. 8.0
rotary_base ..................................... 1000000
rotary_interleaved .............................. False
rotary_percent .................................. 1.0
rotary_scaling_factor ........................... 1.0
rotary_seq_len_interpolation_factor ............. None
run_workload_inspector_server ................... False
sample_rate ..................................... 1.0
save ............................................ /data2/workspaces/FlagAI_OpenSeek/OpenSeek-Small-v1-Baseline/checkpoints
save_interval ................................... 600
save_when_num_microbatches_change ............... False
scatter_gather_tensors_in_pipeline .............. True
seed ............................................ 42
seq_length ...................................... 4096
sequence_parallel ............................... False
sgd_momentum .................................... 0.9
short_seq_prob .................................. 0.1
skip_iters_range ................................ None
skip_samples_range .............................. None
skip_train ...................................... False
skipped_train_samples ........................... 0
spec ............................................ None
special_tokens_file ............................. None
spiky_loss_threshold ............................ 0.2
split ........................................... 1
squared_relu .................................... False
standalone_embedding_stage ...................... False
start_weight_decay .............................. 0.1
straggler_ctrlr_port ............................ 65535
straggler_minmax_count .......................... 1
suggested_communication_unit_size ............... None
swiglu .......................................... True
swin_backbone_type .............................. tiny
symmetric_ar_type ............................... None
te_rng_tracker .................................. False
tensor_model_parallel_size ...................... 1
tensorboard_dir ................................. /data2/workspaces/FlagAI_OpenSeek/OpenSeek-Small-v1-Baseline/tensorboard
tensorboard_log_interval ........................ 1
tensorboard_queue_size .......................... 1000
test_data_path .................................. None
test_mode ....................................... False
tiktoken_num_special_tokens ..................... 1000
tiktoken_pattern ................................ None
tiktoken_special_tokens ......................... None
timing_log_level ................................ 0
timing_log_option ............................... minmax
titles_data_path ................................ None
tokenizer_model ................................. None
tokenizer_path .................................. ../hf_openseek/tokenizer
tokenizer_type .................................. QwenTokenizerFS
torch_fsdp2_reshard_after_forward ............... True
tp_comm_bootstrap_backend ....................... nccl
tp_comm_bulk_dgrad .............................. True
tp_comm_bulk_wgrad .............................. True
tp_comm_overlap ................................. False
tp_comm_overlap_ag .............................. True
tp_comm_overlap_cfg ............................. None
tp_comm_overlap_rs .............................. True
tp_comm_overlap_rs_dgrad ........................ False
tp_comm_split_ag ................................ True
tp_comm_split_rs ................................ True
train_data_path ................................. None
train_iters ..................................... None
train_samples ................................... 24576000
train_sync_interval ............................. None
transformer_impl ................................ transformer_engine
transformer_pipeline_model_parallel_size ........ 1
untie_embeddings_and_output_weights ............. False
use_checkpoint_args ............................. False
use_checkpoint_opt_param_scheduler .............. False
use_cpu_initialization .......................... None
use_custom_fsdp ................................. False
use_dist_ckpt ................................... False
use_dist_ckpt_deprecated ........................ False
use_distributed_optimizer ....................... True
use_flash_attn .................................. False
use_legacy_models ............................... False
use_mp_args_from_checkpoint_args ................ False
use_one_sent_docs ............................... False
use_partial_reduce_for_shared_embedding ......... False
use_persistent_ckpt_worker ...................... False
use_precision_aware_optimizer ................... False
use_pytorch_profiler ............................ False
use_ring_exchange_p2p ........................... False
use_rope_scaling ................................ False
use_rotary_position_embeddings .................. True
use_tokenizer_model_from_checkpoint_args ........ True
use_torch_fsdp2 ................................. False
use_torch_optimizer_for_cpu_offload ............. False
use_tp_pp_dp_mapping ............................ False
v_head_dim ...................................... 128
valid_data_path ................................. None
variable_seq_lengths ............................ False
virtual_pipeline_model_parallel_size ............ None
vision_backbone_type ............................ vit
vision_pretraining .............................. False
vision_pretraining_type ......................... classify
vocab_extra_ids ................................. 0
vocab_file ...................................... None
vocab_size ...................................... 151851
wandb_api_key ...................................
wandb_exp_name .................................. OpenSeek-Small-v1-Baseline
wandb_log_model ................................. False
wandb_log_model_interval ........................ 1000
wandb_mode ...................................... offline
wandb_project ................................... OpenSeek-Small-v1-Baseline
wandb_save_dir .................................. /data2/workspaces/FlagAI_OpenSeek/OpenSeek-Small-v1-Baseline/wandb
weight_decay .................................... 0.1
weight_decay_incr_style ......................... constant
wgrad_deferral_limit ............................ 0
world_size ...................................... 1
yaml_cfg ........................................ None
-------------------- end of arguments ---------------------
INFO:megatron.core.num_microbatches_calculator:setting number of microbatches to constant 1024
> building QwenTokenizerFS tokenizer ...
> padded vocab (size: 151851) with 21 dummy tokens (new size: 151872)
WARNING:megatron.core.rerun_state_machine:RerunStateMachine initialized in mode RerunMode.DISABLED
> initializing torch distributed ...
> initialized tensor model parallel with size 1
> initialized pipeline model parallel with size 1
> setting random seeds to 42 ...
> setting tensorboard ...
WARNING: one_logger package is required to enable e2e metrics tracking. please go to https://confluence.nvidia.com/display/MLWFO/Package+Repositories for details to install it
> compiling dataset index builder ...
make: Entering directory '/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/core/datasets'
make: Nothing to be done for 'default'.
make: Leaving directory '/data2/workspaces/FlagAI_OpenSeek/FlagScale/third_party/Megatron-LM/megatron/core/datasets'
>>> done with dataset index builder. Compilation time: 0.028 seconds
WARNING: constraints for invoking optimized fused softmax kernel are not met. We default back to unfused kernel invocations.
> compiling and loading fused kernels ...
>>> done with compiling and loading fused kernels. Compilation time: 0.055 seconds
time to initialize megatron (seconds): 3.587
[after megatron is initialized] datetime: 2025-06-27 12:23:30
> Number of attn parameters in a transformer block in billions: 0.01
> Number of dense mlp parameters in a transformer block in billions: 0.03
> Number of sparse mlp parameters in a transformer block in billions: 0.23
> Number of parameters in transformer block in billions: 1.20
> Number of parameters in mtp transformer block in billions: 0.00
> Number of parameters in embedding layers in billions: 0.19
> Total number of parameters in billions: 1.39
> Number of parameters in most loaded shard in billions: 1.3946
> Number of activated attn parameters in a transformer block in billions: 0.01
> Number of activated dense mlp parameters in a transformer block in billions: 0.03
> Number of activated sparse mlp parameters in a transformer block in billions: 0.03
> Number of activated parameters in transformer block in billions: 0.20
> Number of activated parameters in mtp transformer block in billions: 0.00
> Number of activated parameters in embedding layers in billions: 0.19
> Total number of activated parameters in billions: 0.40
> Activation memory footprint per dense transformer layer: 276.0 MB
> Activation memory footprint per moe transformer layer: 346.0 MB
>>> [FS] Theoretical memory footprints: weight and optimizer=23940.62 MB, activation=2416.03 MB, total=26356.66 MB
building GPT model ...
> number of parameters on (tensor, pipeline) model parallel rank (0, 0): 1394625792
INFO:megatron.core.distributed.distributed_data_parallel:Setting up DistributedDataParallel with config DistributedDataParallelConfig(grad_reduce_in_fp32=True, overlap_grad_reduce=True, overlap_param_gather=True, align_param_gather=False, use_distributed_optimizer=True, num_distributed_optimizer_instances=1, check_for_nan_in_grad=True, check_for_large_grads=False, bucket_size=40000000, pad_buckets_for_high_nccl_busbw=False, average_in_collective=False, fp8_param_gather=False, use_custom_fsdp=False, data_parallel_sharding_strategy='no_shard', gradient_reduce_div_fusion=True, suggested_communication_unit_size=None, preserve_fp32_weights=True, keep_fp8_transpose_cache_when_using_custom_fsdp=False)
INFO:megatron.core.distributed.param_and_grad_buffer:Number of buckets for gradient all-reduce / reduce-scatter: 30
Params for bucket 1 (40142080 elements, 40142080 padded size):
module.decoder.layers.5.mlp.shared_experts.linear_fc1.weight
module.decoder.layers.5.mlp.experts.linear_fc2.weight60
module.decoder.layers.5.mlp.experts.linear_fc2.weight52
module.decoder.layers.5.mlp.experts.linear_fc2.weight44
module.decoder.layers.5.mlp.experts.linear_fc2.weight36
module.decoder.layers.5.mlp.experts.linear_fc2.weight57
module.decoder.layers.5.mlp.experts.linear_fc2.weight49
module.decoder.layers.5.mlp.experts.linear_fc2.weight41
module.decoder.layers.5.mlp.experts.linear_fc2.weight62
module.decoder.layers.5.mlp.experts.linear_fc2.weight54
module.decoder.layers.5.mlp.experts.linear_fc2.weight46
module.decoder.layers.5.mlp.experts.linear_fc2.weight38
module.decoder.layers.5.mlp.experts.linear_fc2.weight59
module.decoder.layers.5.mlp.experts.linear_fc2.weight51
module.decoder.layers.5.mlp.experts.linear_fc2.weight43
module.decoder.layers.5.mlp.experts.linear_fc2.weight35
module.decoder.layers.5.mlp.experts.linear_fc2.weight56
module.decoder.layers.5.mlp.experts.linear_fc2.weight48
module.decoder.layers.5.mlp.experts.linear_fc2.weight40
module.decoder.layers.5.mlp.shared_experts.linear_fc2.weight
module.decoder.layers.5.mlp.experts.linear_fc2.weight61
module.decoder.layers.5.mlp.experts.linear_fc2.weight53
module.decoder.layers.5.mlp.experts.linear_fc2.weight45
module.decoder.layers.5.mlp.experts.linear_fc2.weight37
module.decoder.layers.5.mlp.experts.linear_fc2.weight58
module.decoder.layers.5.mlp.experts.linear_fc2.weight50
module.decoder.layers.5.mlp.experts.linear_fc2.weight42
module.decoder.final_layernorm.weight
module.decoder.layers.5.mlp.experts.linear_fc2.weight63
module.decoder.layers.5.mlp.experts.linear_fc2.weight55
module.decoder.layers.5.mlp.experts.linear_fc2.weight47
module.decoder.layers.5.mlp.experts.linear_fc2.weight39
Params for bucket 2 (40140800 elements, 40140800 padded size):
module.decoder.layers.5.mlp.experts.linear_fc2.weight28
module.decoder.layers.5.mlp.experts.linear_fc2.weight20
module.decoder.layers.5.mlp.experts.linear_fc2.weight12
module.decoder.layers.5.mlp.experts.linear_fc2.weight4
module.decoder.layers.5.mlp.experts.linear_fc2.weight33
module.decoder.layers.5.mlp.experts.linear_fc2.weight25
module.decoder.layers.5.mlp.experts.linear_fc2.weight17
module.decoder.layers.5.mlp.experts.linear_fc2.weight9
module.decoder.layers.5.mlp.experts.linear_fc2.weight1
module.decoder.layers.5.mlp.experts.linear_fc2.weight30
module.decoder.layers.5.mlp.experts.linear_fc2.weight22
module.decoder.layers.5.mlp.experts.linear_fc2.weight14
module.decoder.layers.5.mlp.experts.linear_fc2.weight6
module.decoder.layers.5.mlp.experts.linear_fc2.weight27
module.decoder.layers.5.mlp.experts.linear_fc2.weight19
module.decoder.layers.5.mlp.experts.linear_fc2.weight11
module.decoder.layers.5.mlp.experts.linear_fc2.weight3
module.decoder.layers.5.mlp.experts.linear_fc2.weight32
module.decoder.layers.5.mlp.experts.linear_fc2.weight24
module.decoder.layers.5.mlp.experts.linear_fc2.weight16
module.decoder.layers.5.mlp.experts.linear_fc2.weight8
module.decoder.layers.5.mlp.experts.linear_fc2.weight2
module.decoder.layers.5.mlp.experts.linear_fc2.weight29
module.decoder.layers.5.mlp.experts.linear_fc2.weight21
module.decoder.layers.5.mlp.experts.linear_fc2.weight13
module.decoder.layers.5.mlp.experts.linear_fc2.weight5
module.decoder.layers.5.mlp.experts.linear_fc2.weight34
module.decoder.layers.5.mlp.experts.linear_fc2.weight26
module.decoder.layers.5.mlp.experts.linear_fc2.weight18
module.decoder.layers.5.mlp.experts.linear_fc2.weight10
module.decoder.layers.5.mlp.experts.linear_fc2.weight0
module.decoder.layers.5.mlp.experts.linear_fc2.weight31
module.decoder.layers.5.mlp.experts.linear_fc2.weight23
module.decoder.layers.5.mlp.experts.linear_fc2.weight15
module.decoder.layers.5.mlp.experts.linear_fc2.weight7
Params for bucket 3 (41287680 elements, 41287680 padded size):
module.decoder.layers.5.mlp.experts.linear_fc1.weight62
module.decoder.layers.5.mlp.experts.linear_fc1.weight60
module.decoder.layers.5.mlp.experts.linear_fc1.weight58
module.decoder.layers.5.mlp.experts.linear_fc1.weight56
module.decoder.layers.5.mlp.experts.linear_fc1.weight54
module.decoder.layers.5.mlp.experts.linear_fc1.weight52
module.decoder.layers.5.mlp.experts.linear_fc1.weight50
module.decoder.layers.5.mlp.experts.linear_fc1.weight48
module.decoder.layers.5.mlp.experts.linear_fc1.weight46
module.decoder.layers.5.mlp.experts.linear_fc1.weight63
module.decoder.layers.5.mlp.experts.linear_fc1.weight61
module.decoder.layers.5.mlp.experts.linear_fc1.weight59
module.decoder.layers.5.mlp.experts.linear_fc1.weight57
module.decoder.layers.5.mlp.experts.linear_fc1.weight55
module.decoder.layers.5.mlp.experts.linear_fc1.weight53
module.decoder.layers.5.mlp.experts.linear_fc1.weight51
module.decoder.layers.5.mlp.experts.linear_fc1.weight49
module.decoder.layers.5.mlp.experts.linear_fc1.weight47
Params for bucket 4 (41287680 elements, 41287680 padded size):
module.decoder.layers.5.mlp.experts.linear_fc1.weight44
module.decoder.layers.5.mlp.experts.linear_fc1.weight42
module.decoder.layers.5.mlp.experts.linear_fc1.weight40
module.decoder.layers.5.mlp.experts.linear_fc1.weight38
module.decoder.layers.5.mlp.experts.linear_fc1.weight36
module.decoder.layers.5.mlp.experts.linear_fc1.weight34
module.decoder.layers.5.mlp.experts.linear_fc1.weight32
module.decoder.layers.5.mlp.experts.linear_fc1.weight31
module.decoder.layers.5.mlp.experts.linear_fc1.weight28
module.decoder.layers.5.mlp.experts.linear_fc1.weight45
module.decoder.layers.5.mlp.experts.linear_fc1.weight43
module.decoder.layers.5.mlp.experts.linear_fc1.weight41
module.decoder.layers.5.mlp.experts.linear_fc1.weight39
module.decoder.layers.5.mlp.experts.linear_fc1.weight37
module.decoder.layers.5.mlp.experts.linear_fc1.weight35
module.decoder.layers.5.mlp.experts.linear_fc1.weight33
module.decoder.layers.5.mlp.experts.linear_fc1.weight30
module.decoder.layers.5.mlp.experts.linear_fc1.weight29
Params for bucket 5 (41287680 elements, 41287680 padded size):
module.decoder.layers.5.mlp.experts.linear_fc1.weight24
module.decoder.layers.5.mlp.experts.linear_fc1.weight26
module.decoder.layers.5.mlp.experts.linear_fc1.weight22
module.decoder.layers.5.mlp.experts.linear_fc1.weight20
module.decoder.layers.5.mlp.experts.linear_fc1.weight18
module.decoder.layers.5.mlp.experts.linear_fc1.weight16
module.decoder.layers.5.mlp.experts.linear_fc1.weight14
module.decoder.layers.5.mlp.experts.linear_fc1.weight12
module.decoder.layers.5.mlp.experts.linear_fc1.weight10
module.decoder.layers.5.mlp.experts.linear_fc1.weight27
module.decoder.layers.5.mlp.experts.linear_fc1.weight23
module.decoder.layers.5.mlp.experts.linear_fc1.weight25
module.decoder.layers.5.mlp.experts.linear_fc1.weight21
module.decoder.layers.5.mlp.experts.linear_fc1.weight19
module.decoder.layers.5.mlp.experts.linear_fc1.weight17
module.decoder.layers.5.mlp.experts.linear_fc1.weight15
module.decoder.layers.5.mlp.experts.linear_fc1.weight13
module.decoder.layers.5.mlp.experts.linear_fc1.weight11
Params for bucket 6 (40635392 elements, 40635392 padded size):
module.decoder.layers.5.mlp.experts.linear_fc1.weight3
module.decoder.layers.5.mlp.router.weight
module.decoder.layers.5.pre_mlp_layernorm.weight
module.decoder.layers.5.self_attention.linear_kv_up_proj.weight
module.decoder.layers.4.mlp.experts.linear_fc2.weight62
module.decoder.layers.5.mlp.experts.linear_fc1.weight7
module.decoder.layers.5.self_attention.linear_kv_up_proj.layer_norm_weight
module.decoder.layers.5.self_attention.linear_kv_down_proj.weight
module.decoder.layers.5.mlp.experts.linear_fc1.weight4
module.decoder.layers.5.self_attention.linear_q_proj.weight
module.decoder.layers.5.self_attention.linear_proj.weight
module.decoder.layers.5.mlp.experts.linear_fc1.weight9
module.decoder.layers.5.mlp.experts.linear_fc1.weight0
module.decoder.layers.4.mlp.experts.linear_fc2.weight61
module.decoder.layers.5.mlp.experts.linear_fc1.weight6
module.decoder.layers.5.mlp.experts.linear_fc1.weight1
module.decoder.layers.5.input_layernorm.weight
module.decoder.layers.4.mlp.shared_experts.linear_fc2.weight
module.decoder.layers.4.mlp.experts.linear_fc2.weight63
module.decoder.layers.5.mlp.experts.linear_fc1.weight8
module.decoder.layers.5.mlp.experts.linear_fc1.weight2
module.decoder.layers.4.mlp.shared_experts.linear_fc1.weight
module.decoder.layers.4.mlp.experts.linear_fc2.weight60
module.decoder.layers.5.mlp.experts.linear_fc1.weight5
Params for bucket 7 (40140800 elements, 40140800 padded size):
module.decoder.layers.4.mlp.experts.linear_fc2.weight54
module.decoder.layers.4.mlp.experts.linear_fc2.weight46
module.decoder.layers.4.mlp.experts.linear_fc2.weight38
module.decoder.layers.4.mlp.experts.linear_fc2.weight30
module.decoder.layers.4.mlp.experts.linear_fc2.weight59
module.decoder.layers.4.mlp.experts.linear_fc2.weight51
module.decoder.layers.4.mlp.experts.linear_fc2.weight43
module.decoder.layers.4.mlp.experts.linear_fc2.weight35
module.decoder.layers.4.mlp.experts.linear_fc2.weight27
module.decoder.layers.4.mlp.experts.linear_fc2.weight56
module.decoder.layers.4.mlp.experts.linear_fc2.weight48
module.decoder.layers.4.mlp.experts.linear_fc2.weight40
module.decoder.layers.4.mlp.experts.linear_fc2.weight32
module.decoder.layers.4.mlp.experts.linear_fc2.weight53
module.decoder.layers.4.mlp.experts.linear_fc2.weight45
module.decoder.layers.4.mlp.experts.linear_fc2.weight37
module.decoder.layers.4.mlp.experts.linear_fc2.weight29
module.decoder.layers.4.mlp.experts.linear_fc2.weight58
module.decoder.layers.4.mlp.experts.linear_fc2.weight50
module.decoder.layers.4.mlp.experts.linear_fc2.weight42
module.decoder.layers.4.mlp.experts.linear_fc2.weight34
module.decoder.layers.4.mlp.experts.linear_fc2.weight26
module.decoder.layers.4.mlp.experts.linear_fc2.weight55
module.decoder.layers.4.mlp.experts.linear_fc2.weight47
module.decoder.layers.4.mlp.experts.linear_fc2.weight39
module.decoder.layers.4.mlp.experts.linear_fc2.weight31
module.decoder.layers.4.mlp.experts.linear_fc2.weight52
module.decoder.layers.4.mlp.experts.linear_fc2.weight44
module.decoder.layers.4.mlp.experts.linear_fc2.weight36
module.decoder.layers.4.mlp.experts.linear_fc2.weight28
module.decoder.layers.4.mlp.experts.linear_fc2.weight57
module.decoder.layers.4.mlp.experts.linear_fc2.weight49
module.decoder.layers.4.mlp.experts.linear_fc2.weight41
module.decoder.layers.4.mlp.experts.linear_fc2.weight33
module.decoder.layers.4.mlp.experts.linear_fc2.weight25
Params for bucket 8 (40140800 elements, 40140800 padded size):
module.decoder.layers.4.mlp.experts.linear_fc2.weight22
module.decoder.layers.4.mlp.experts.linear_fc2.weight14
module.decoder.layers.4.mlp.experts.linear_fc2.weight0
module.decoder.layers.4.mlp.experts.linear_fc1.weight60
module.decoder.layers.4.mlp.experts.linear_fc2.weight19
module.decoder.layers.4.mlp.experts.linear_fc2.weight11
module.decoder.layers.4.mlp.experts.linear_fc2.weight24
module.decoder.layers.4.mlp.experts.linear_fc2.weight16
module.decoder.layers.4.mlp.experts.linear_fc2.weight8
module.decoder.layers.4.mlp.experts.linear_fc2.weight4
module.decoder.layers.4.mlp.experts.linear_fc1.weight62
module.decoder.layers.4.mlp.experts.linear_fc2.weight21
module.decoder.layers.4.mlp.experts.linear_fc2.weight13
module.decoder.layers.4.mlp.experts.linear_fc2.weight1
module.decoder.layers.4.mlp.experts.linear_fc1.weight59
module.decoder.layers.4.mlp.experts.linear_fc2.weight18
module.decoder.layers.4.mlp.experts.linear_fc2.weight10
module.decoder.layers.4.mlp.experts.linear_fc2.weight7
module.decoder.layers.4.mlp.experts.linear_fc2.weight23
module.decoder.layers.4.mlp.experts.linear_fc2.weight15
module.decoder.layers.4.mlp.experts.linear_fc2.weight3
module.decoder.layers.4.mlp.experts.linear_fc1.weight61
module.decoder.layers.4.mlp.experts.linear_fc2.weight20
module.decoder.layers.4.mlp.experts.linear_fc2.weight12
module.decoder.layers.4.mlp.experts.linear_fc2.weight5
module.decoder.layers.4.mlp.experts.linear_fc2.weight2
module.decoder.layers.4.mlp.experts.linear_fc2.weight17
module.decoder.layers.4.mlp.experts.linear_fc2.weight9
module.decoder.layers.4.mlp.experts.linear_fc2.weight6
module.decoder.layers.4.mlp.experts.linear_fc1.weight63
Params for bucket 9 (41287680 elements, 41287680 padded size):
module.decoder.layers.4.mlp.experts.linear_fc1.weight58
module.decoder.layers.4.mlp.experts.linear_fc1.weight54
module.decoder.layers.4.mlp.experts.linear_fc1.weight56
module.decoder.layers.4.mlp.experts.linear_fc1.weight52
module.decoder.layers.4.mlp.experts.linear_fc1.weight50
module.decoder.layers.4.mlp.experts.linear_fc1.weight48
module.decoder.layers.4.mlp.experts.linear_fc1.weight46
module.decoder.layers.4.mlp.experts.linear_fc1.weight44
module.decoder.layers.4.mlp.experts.linear_fc1.weight42
module.decoder.layers.4.mlp.experts.linear_fc1.weight57
module.decoder.layers.4.mlp.experts.linear_fc1.weight55
module.decoder.layers.4.mlp.experts.linear_fc1.weight53
module.decoder.layers.4.mlp.experts.linear_fc1.weight51
module.decoder.layers.4.mlp.experts.linear_fc1.weight49
module.decoder.layers.4.mlp.experts.linear_fc1.weight47
module.decoder.layers.4.mlp.experts.linear_fc1.weight45
module.decoder.layers.4.mlp.experts.linear_fc1.weight43
module.decoder.layers.4.mlp.experts.linear_fc1.weight41
Params for bucket 10 (41287680 elements, 41287680 padded size):
module.decoder.layers.4.mlp.experts.linear_fc1.weight40
module.decoder.layers.4.mlp.experts.linear_fc1.weight38
module.decoder.layers.4.mlp.experts.linear_fc1.weight36
module.decoder.layers.4.mlp.experts.linear_fc1.weight34
module.decoder.layers.4.mlp.experts.linear_fc1.weight32
module.decoder.layers.4.mlp.experts.linear_fc1.weight30
module.decoder.layers.4.mlp.experts.linear_fc1.weight28
module.decoder.layers.4.mlp.experts.linear_fc1.weight26
module.decoder.layers.4.mlp.experts.linear_fc1.weight24
module.decoder.layers.4.mlp.experts.linear_fc1.weight39
module.decoder.layers.4.mlp.experts.linear_fc1.weight37
module.decoder.layers.4.mlp.experts.linear_fc1.weight35
module.decoder.layers.4.mlp.experts.linear_fc1.weight33
module.decoder.layers.4.mlp.experts.linear_fc1.weight31
module.decoder.layers.4.mlp.experts.linear_fc1.weight29
module.decoder.layers.4.mlp.experts.linear_fc1.weight27
module.decoder.layers.4.mlp.experts.linear_fc1.weight25
module.decoder.layers.4.mlp.experts.linear_fc1.weight23
Params for bucket 11 (41287680 elements, 41287680 padded size):
module.decoder.layers.4.mlp.experts.linear_fc1.weight22
module.decoder.layers.4.mlp.experts.linear_fc1.weight18
module.decoder.layers.4.mlp.experts.linear_fc1.weight20
module.decoder.layers.4.mlp.experts.linear_fc1.weight16
module.decoder.layers.4.mlp.experts.linear_fc1.weight14
module.decoder.layers.4.mlp.experts.linear_fc1.weight12
module.decoder.layers.4.mlp.experts.linear_fc1.weight10
module.decoder.layers.4.mlp.experts.linear_fc1.weight8
module.decoder.layers.4.mlp.experts.linear_fc1.weight6
module.decoder.layers.4.mlp.experts.linear_fc1.weight19
module.decoder.layers.4.mlp.experts.linear_fc1.weight21
module.decoder.layers.4.mlp.experts.linear_fc1.weight17
module.decoder.layers.4.mlp.experts.linear_fc1.weight15
module.decoder.layers.4.mlp.experts.linear_fc1.weight13
module.decoder.layers.4.mlp.experts.linear_fc1.weight11
module.decoder.layers.4.mlp.experts.linear_fc1.weight9
module.decoder.layers.4.mlp.experts.linear_fc1.weight7
module.decoder.layers.4.mlp.experts.linear_fc1.weight5
Params for bucket 12 (40635392 elements, 40635392 padded size):
module.decoder.layers.4.mlp.experts.linear_fc1.weight4
module.decoder.layers.4.self_attention.linear_q_proj.weight
module.decoder.layers.4.self_attention.linear_proj.weight
module.decoder.layers.3.mlp.experts.linear_fc2.weight60
module.decoder.layers.3.mlp.experts.linear_fc2.weight52
module.decoder.layers.4.mlp.experts.linear_fc1.weight0
module.decoder.layers.3.mlp.experts.linear_fc2.weight57
module.decoder.layers.3.mlp.experts.linear_fc2.weight62
module.decoder.layers.3.mlp.experts.linear_fc2.weight54
module.decoder.layers.4.mlp.experts.linear_fc1.weight1
module.decoder.layers.3.mlp.experts.linear_fc2.weight59
module.decoder.layers.3.mlp.experts.linear_fc2.weight51
module.decoder.layers.4.mlp.experts.linear_fc1.weight2
module.decoder.layers.4.self_attention.linear_kv_up_proj.layer_norm_weight
module.decoder.layers.4.self_attention.linear_kv_down_proj.weight
module.decoder.layers.3.mlp.shared_experts.linear_fc2.weight
module.decoder.layers.3.mlp.experts.linear_fc2.weight56
module.decoder.layers.3.mlp.shared_experts.linear_fc1.weight
module.decoder.layers.3.mlp.experts.linear_fc2.weight61
module.decoder.layers.3.mlp.experts.linear_fc2.weight53
module.decoder.layers.4.mlp.experts.linear_fc1.weight3
module.decoder.layers.4.mlp.router.weight
module.decoder.layers.4.pre_mlp_layernorm.weight
module.decoder.layers.4.self_attention.linear_kv_up_proj.weight
module.decoder.layers.4.input_layernorm.weight
module.decoder.layers.3.mlp.experts.linear_fc2.weight58
module.decoder.layers.3.mlp.experts.linear_fc2.weight50
module.decoder.layers.3.mlp.experts.linear_fc2.weight63
module.decoder.layers.3.mlp.experts.linear_fc2.weight55
Params for bucket 13 (40140800 elements, 40140800 padded size):
module.decoder.layers.3.mlp.experts.linear_fc2.weight44
module.decoder.layers.3.mlp.experts.linear_fc2.weight36
module.decoder.layers.3.mlp.experts.linear_fc2.weight28
module.decoder.layers.3.mlp.experts.linear_fc2.weight20
module.decoder.layers.3.mlp.experts.linear_fc2.weight49
module.decoder.layers.3.mlp.experts.linear_fc2.weight41
module.decoder.layers.3.mlp.experts.linear_fc2.weight33
module.decoder.layers.3.mlp.experts.linear_fc2.weight25
module.decoder.layers.3.mlp.experts.linear_fc2.weight17
module.decoder.layers.3.mlp.experts.linear_fc2.weight46
module.decoder.layers.3.mlp.experts.linear_fc2.weight38
module.decoder.layers.3.mlp.experts.linear_fc2.weight30
module.decoder.layers.3.mlp.experts.linear_fc2.weight22
module.decoder.layers.3.mlp.experts.linear_fc2.weight43
module.decoder.layers.3.mlp.experts.linear_fc2.weight35
module.decoder.layers.3.mlp.experts.linear_fc2.weight27
module.decoder.layers.3.mlp.experts.linear_fc2.weight19
module.decoder.layers.3.mlp.experts.linear_fc2.weight48
module.decoder.layers.3.mlp.experts.linear_fc2.weight40
module.decoder.layers.3.mlp.experts.linear_fc2.weight32
module.decoder.layers.3.mlp.experts.linear_fc2.weight24
module.decoder.layers.3.mlp.experts.linear_fc2.weight16
module.decoder.layers.3.mlp.experts.linear_fc2.weight45
module.decoder.layers.3.mlp.experts.linear_fc2.weight37
module.decoder.layers.3.mlp.experts.linear_fc2.weight29
module.decoder.layers.3.mlp.experts.linear_fc2.weight21
module.decoder.layers.3.mlp.experts.linear_fc2.weight42
module.decoder.layers.3.mlp.experts.linear_fc2.weight34
module.decoder.layers.3.mlp.experts.linear_fc2.weight26
module.decoder.layers.3.mlp.experts.linear_fc2.weight18
module.decoder.layers.3.mlp.experts.linear_fc2.weight47
module.decoder.layers.3.mlp.experts.linear_fc2.weight39
module.decoder.layers.3.mlp.experts.linear_fc2.weight31
module.decoder.layers.3.mlp.experts.linear_fc2.weight23
module.decoder.layers.3.mlp.experts.linear_fc2.weight15
Params for bucket 14 (40140800 elements, 40140800 padded size):
module.decoder.layers.3.mlp.experts.linear_fc2.weight12
module.decoder.layers.3.mlp.experts.linear_fc2.weight4
module.decoder.layers.3.mlp.experts.linear_fc1.weight61
module.decoder.layers.3.mlp.experts.linear_fc2.weight9
module.decoder.layers.3.mlp.experts.linear_fc2.weight2
module.decoder.layers.3.mlp.experts.linear_fc2.weight1
module.decoder.layers.3.mlp.experts.linear_fc1.weight58
module.decoder.layers.3.mlp.experts.linear_fc2.weight14
module.decoder.layers.3.mlp.experts.linear_fc2.weight6
module.decoder.layers.3.mlp.experts.linear_fc1.weight63
module.decoder.layers.3.mlp.experts.linear_fc1.weight55
module.decoder.layers.3.mlp.experts.linear_fc2.weight11
module.decoder.layers.3.mlp.experts.linear_fc2.weight3
module.decoder.layers.3.mlp.experts.linear_fc1.weight60
module.decoder.layers.3.mlp.experts.linear_fc2.weight8
module.decoder.layers.3.mlp.experts.linear_fc1.weight57
module.decoder.layers.3.mlp.experts.linear_fc2.weight13
module.decoder.layers.3.mlp.experts.linear_fc2.weight5
module.decoder.layers.3.mlp.experts.linear_fc1.weight62
module.decoder.layers.3.mlp.experts.linear_fc1.weight54
module.decoder.layers.3.mlp.experts.linear_fc2.weight10
module.decoder.layers.3.mlp.experts.linear_fc2.weight0
module.decoder.layers.3.mlp.experts.linear_fc1.weight59
module.decoder.layers.3.mlp.experts.linear_fc2.weight7
module.decoder.layers.3.mlp.experts.linear_fc1.weight56
Params for bucket 15 (41287680 elements, 41287680 padded size):
module.decoder.layers.3.mlp.experts.linear_fc1.weight53
module.decoder.layers.3.mlp.experts.linear_fc1.weight51
module.decoder.layers.3.mlp.experts.linear_fc1.weight49
module.decoder.layers.3.mlp.experts.linear_fc1.weight47
module.decoder.layers.3.mlp.experts.linear_fc1.weight45
module.decoder.layers.3.mlp.experts.linear_fc1.weight43
module.decoder.layers.3.mlp.experts.linear_fc1.weight41
module.decoder.layers.3.mlp.experts.linear_fc1.weight39
module.decoder.layers.3.mlp.experts.linear_fc1.weight38
module.decoder.layers.3.mlp.experts.linear_fc1.weight36
module.decoder.layers.3.mlp.experts.linear_fc1.weight50
module.decoder.layers.3.mlp.experts.linear_fc1.weight52
module.decoder.layers.3.mlp.experts.linear_fc1.weight48
module.decoder.layers.3.mlp.experts.linear_fc1.weight46
module.decoder.layers.3.mlp.experts.linear_fc1.weight44
module.decoder.layers.3.mlp.experts.linear_fc1.weight42
module.decoder.layers.3.mlp.experts.linear_fc1.weight40
module.decoder.layers.3.mlp.experts.linear_fc1.weight37
Params for bucket 16 (41287680 elements, 41287680 padded size):
module.decoder.layers.3.mlp.experts.linear_fc1.weight35
module.decoder.layers.3.mlp.experts.linear_fc1.weight31
module.decoder.layers.3.mlp.experts.linear_fc1.weight33
module.decoder.layers.3.mlp.experts.linear_fc1.weight29
module.decoder.layers.3.mlp.experts.linear_fc1.weight27
module.decoder.layers.3.mlp.experts.linear_fc1.weight25
module.decoder.layers.3.mlp.experts.linear_fc1.weight23
module.decoder.layers.3.mlp.experts.linear_fc1.weight21
module.decoder.layers.3.mlp.experts.linear_fc1.weight19
module.decoder.layers.3.mlp.experts.linear_fc1.weight32
module.decoder.layers.3.mlp.experts.linear_fc1.weight34
module.decoder.layers.3.mlp.experts.linear_fc1.weight30
module.decoder.layers.3.mlp.experts.linear_fc1.weight28
module.decoder.layers.3.mlp.experts.linear_fc1.weight26
module.decoder.layers.3.mlp.experts.linear_fc1.weight24
module.decoder.layers.3.mlp.experts.linear_fc1.weight22
module.decoder.layers.3.mlp.experts.linear_fc1.weight20
module.decoder.layers.3.mlp.experts.linear_fc1.weight18
Params for bucket 17 (41287680 elements, 41287680 padded size):
module.decoder.layers.3.mlp.experts.linear_fc1.weight17
module.decoder.layers.3.mlp.experts.linear_fc1.weight13
module.decoder.layers.3.mlp.experts.linear_fc1.weight15
module.decoder.layers.3.mlp.experts.linear_fc1.weight11
module.decoder.layers.3.mlp.experts.linear_fc1.weight9
module.decoder.layers.3.mlp.experts.linear_fc1.weight7
module.decoder.layers.3.mlp.experts.linear_fc1.weight5
module.decoder.layers.3.mlp.experts.linear_fc1.weight1
module.decoder.layers.3.mlp.experts.linear_fc1.weight0
module.decoder.layers.3.mlp.experts.linear_fc1.weight16
module.decoder.layers.3.mlp.experts.linear_fc1.weight14
module.decoder.layers.3.mlp.experts.linear_fc1.weight12
module.decoder.layers.3.mlp.experts.linear_fc1.weight10
module.decoder.layers.3.mlp.experts.linear_fc1.weight8
module.decoder.layers.3.mlp.experts.linear_fc1.weight6
module.decoder.layers.3.mlp.experts.linear_fc1.weight4
module.decoder.layers.3.mlp.experts.linear_fc1.weight3
module.decoder.layers.3.mlp.experts.linear_fc1.weight2
Params for bucket 18 (40635392 elements, 40635392 padded size):
module.decoder.layers.3.self_attention.linear_kv_up_proj.weight
module.decoder.layers.3.self_attention.linear_kv_up_proj.layer_norm_weight
module.decoder.layers.2.mlp.experts.linear_fc2.weight62
module.decoder.layers.2.mlp.experts.linear_fc2.weight54
module.decoder.layers.2.mlp.experts.linear_fc2.weight46
module.decoder.layers.3.self_attention.linear_q_proj.weight
module.decoder.layers.3.self_attention.linear_proj.weight
module.decoder.layers.2.mlp.shared_experts.linear_fc1.weight
module.decoder.layers.2.mlp.experts.linear_fc2.weight59
module.decoder.layers.2.mlp.experts.linear_fc2.weight51
module.decoder.layers.2.mlp.experts.linear_fc2.weight43
module.decoder.layers.2.mlp.experts.linear_fc2.weight56
module.decoder.layers.2.mlp.experts.linear_fc2.weight48
module.decoder.layers.2.mlp.experts.linear_fc2.weight40
module.decoder.layers.3.mlp.router.weight
module.decoder.layers.3.self_attention.linear_kv_down_proj.weight
module.decoder.layers.2.mlp.experts.linear_fc2.weight61
module.decoder.layers.2.mlp.experts.linear_fc2.weight53
module.decoder.layers.2.mlp.experts.linear_fc2.weight45
module.decoder.layers.2.mlp.experts.linear_fc2.weight58
module.decoder.layers.2.mlp.experts.linear_fc2.weight50
module.decoder.layers.2.mlp.experts.linear_fc2.weight42
module.decoder.layers.2.mlp.experts.linear_fc2.weight55
module.decoder.layers.2.mlp.shared_experts.linear_fc2.weight
module.decoder.layers.2.mlp.experts.linear_fc2.weight63
module.decoder.layers.2.mlp.experts.linear_fc2.weight47
module.decoder.layers.3.pre_mlp_layernorm.weight
module.decoder.layers.3.input_layernorm.weight
module.decoder.layers.2.mlp.experts.linear_fc2.weight60
module.decoder.layers.2.mlp.experts.linear_fc2.weight52
module.decoder.layers.2.mlp.experts.linear_fc2.weight44
module.decoder.layers.2.mlp.experts.linear_fc2.weight57
module.decoder.layers.2.mlp.experts.linear_fc2.weight49
module.decoder.layers.2.mlp.experts.linear_fc2.weight41
Params for bucket 19 (40140800 elements, 40140800 padded size):
module.decoder.layers.2.mlp.experts.linear_fc2.weight38
module.decoder.layers.2.mlp.experts.linear_fc2.weight30
module.decoder.layers.2.mlp.experts.linear_fc2.weight22
module.decoder.layers.2.mlp.experts.linear_fc2.weight10
module.decoder.layers.2.mlp.experts.linear_fc2.weight35
module.decoder.layers.2.mlp.experts.linear_fc2.weight27
module.decoder.layers.2.mlp.experts.linear_fc2.weight19
module.decoder.layers.2.mlp.experts.linear_fc2.weight7
module.decoder.layers.2.mlp.experts.linear_fc2.weight32
module.decoder.layers.2.mlp.experts.linear_fc2.weight24
module.decoder.layers.2.mlp.experts.linear_fc2.weight16
module.decoder.layers.2.mlp.experts.linear_fc2.weight12
module.decoder.layers.2.mlp.experts.linear_fc2.weight37
module.decoder.layers.2.mlp.experts.linear_fc2.weight29
module.decoder.layers.2.mlp.experts.linear_fc2.weight21
module.decoder.layers.2.mlp.experts.linear_fc2.weight9
module.decoder.layers.2.mlp.experts.linear_fc2.weight34
module.decoder.layers.2.mlp.experts.linear_fc2.weight26
module.decoder.layers.2.mlp.experts.linear_fc2.weight18
module.decoder.layers.2.mlp.experts.linear_fc2.weight15
module.decoder.layers.2.mlp.experts.linear_fc2.weight6
module.decoder.layers.2.mlp.experts.linear_fc2.weight39
module.decoder.layers.2.mlp.experts.linear_fc2.weight31
module.decoder.layers.2.mlp.experts.linear_fc2.weight23
module.decoder.layers.2.mlp.experts.linear_fc2.weight11
module.decoder.layers.2.mlp.experts.linear_fc2.weight36
module.decoder.layers.2.mlp.experts.linear_fc2.weight28
module.decoder.layers.2.mlp.experts.linear_fc2.weight20
module.decoder.layers.2.mlp.experts.linear_fc2.weight13
module.decoder.layers.2.mlp.experts.linear_fc2.weight8
module.decoder.layers.2.mlp.experts.linear_fc2.weight33
module.decoder.layers.2.mlp.experts.linear_fc2.weight25
module.decoder.layers.2.mlp.experts.linear_fc2.weight17
module.decoder.layers.2.mlp.experts.linear_fc2.weight14
module.decoder.layers.2.mlp.experts.linear_fc2.weight5
Params for bucket 20 (40140800 elements, 40140800 padded size):
module.decoder.layers.2.mlp.experts.linear_fc2.weight0
module.decoder.layers.2.mlp.experts.linear_fc1.weight63
module.decoder.layers.2.mlp.experts.linear_fc1.weight60
module.decoder.layers.2.mlp.experts.linear_fc1.weight49
module.decoder.layers.2.mlp.experts.linear_fc1.weight54
module.decoder.layers.2.mlp.experts.linear_fc2.weight4
module.decoder.layers.2.mlp.experts.linear_fc2.weight2
module.decoder.layers.2.mlp.experts.linear_fc2.weight1
module.decoder.layers.2.mlp.experts.linear_fc1.weight61
module.decoder.layers.2.mlp.experts.linear_fc1.weight50
module.decoder.layers.2.mlp.experts.linear_fc1.weight56
module.decoder.layers.2.mlp.experts.linear_fc1.weight53
module.decoder.layers.2.mlp.experts.linear_fc1.weight51
module.decoder.layers.2.mlp.experts.linear_fc2.weight3
module.decoder.layers.2.mlp.experts.linear_fc1.weight62
module.decoder.layers.2.mlp.experts.linear_fc1.weight58
module.decoder.layers.2.mlp.experts.linear_fc1.weight57
module.decoder.layers.2.mlp.experts.linear_fc1.weight55
module.decoder.layers.2.mlp.experts.linear_fc1.weight52
module.decoder.layers.2.mlp.experts.linear_fc1.weight59
Params for bucket 21 (41287680 elements, 41287680 padded size):
module.decoder.layers.2.mlp.experts.linear_fc1.weight36
module.decoder.layers.2.mlp.experts.linear_fc1.weight31
module.decoder.layers.2.mlp.experts.linear_fc1.weight34
module.decoder.layers.2.mlp.experts.linear_fc1.weight37
module.decoder.layers.2.mlp.experts.linear_fc1.weight38
module.decoder.layers.2.mlp.experts.linear_fc1.weight48
module.decoder.layers.2.mlp.experts.linear_fc1.weight46
module.decoder.layers.2.mlp.experts.linear_fc1.weight45
module.decoder.layers.2.mlp.experts.linear_fc1.weight47
module.decoder.layers.2.mlp.experts.linear_fc1.weight44
module.decoder.layers.2.mlp.experts.linear_fc1.weight43
module.decoder.layers.2.mlp.experts.linear_fc1.weight42
module.decoder.layers.2.mlp.experts.linear_fc1.weight41
module.decoder.layers.2.mlp.experts.linear_fc1.weight40
module.decoder.layers.2.mlp.experts.linear_fc1.weight39
module.decoder.layers.2.mlp.experts.linear_fc1.weight35
module.decoder.layers.2.mlp.experts.linear_fc1.weight32
module.decoder.layers.2.mlp.experts.linear_fc1.weight33
Params for bucket 22 (41287680 elements, 41287680 padded size):
module.decoder.layers.2.mlp.experts.linear_fc1.weight30
module.decoder.layers.2.mlp.experts.linear_fc1.weight27
module.decoder.layers.2.mlp.experts.linear_fc1.weight28
module.decoder.layers.2.mlp.experts.linear_fc1.weight29
module.decoder.layers.2.mlp.experts.linear_fc1.weight25
module.decoder.layers.2.mlp.experts.linear_fc1.weight24
module.decoder.layers.2.mlp.experts.linear_fc1.weight20
module.decoder.layers.2.mlp.experts.linear_fc1.weight19
module.decoder.layers.2.mlp.experts.linear_fc1.weight16
module.decoder.layers.2.mlp.experts.linear_fc1.weight14
module.decoder.layers.2.mlp.experts.linear_fc1.weight26
module.decoder.layers.2.mlp.experts.linear_fc1.weight23
module.decoder.layers.2.mlp.experts.linear_fc1.weight22
module.decoder.layers.2.mlp.experts.linear_fc1.weight21
module.decoder.layers.2.mlp.experts.linear_fc1.weight18
module.decoder.layers.2.mlp.experts.linear_fc1.weight17
module.decoder.layers.2.mlp.experts.linear_fc1.weight15
module.decoder.layers.2.mlp.experts.linear_fc1.weight13
Params for bucket 23 (42929152 elements, 42929152 padded size):
module.decoder.layers.2.self_attention.linear_kv_up_proj.weight
module.decoder.layers.2.mlp.router.weight
module.decoder.layers.2.mlp.experts.linear_fc1.weight8
module.decoder.layers.2.mlp.experts.linear_fc1.weight6
module.decoder.layers.2.pre_mlp_layernorm.weight
module.decoder.layers.2.self_attention.linear_kv_up_proj.layer_norm_weight
module.decoder.layers.2.self_attention.linear_kv_down_proj.weight
module.decoder.layers.2.self_attention.linear_proj.weight
module.decoder.layers.2.self_attention.linear_q_proj.weight
module.decoder.layers.2.mlp.experts.linear_fc1.weight9
module.decoder.layers.2.mlp.experts.linear_fc1.weight5
module.decoder.layers.2.mlp.experts.linear_fc1.weight3
module.decoder.layers.2.mlp.experts.linear_fc1.weight11
module.decoder.layers.2.mlp.experts.linear_fc1.weight1
module.decoder.layers.2.mlp.experts.linear_fc1.weight10
module.decoder.layers.2.mlp.experts.linear_fc1.weight0
module.decoder.layers.1.mlp.shared_experts.linear_fc2.weight
module.decoder.layers.2.mlp.experts.linear_fc1.weight2
module.decoder.layers.2.input_layernorm.weight
module.decoder.layers.1.mlp.shared_experts.linear_fc1.weight
module.decoder.layers.2.mlp.experts.linear_fc1.weight12
module.decoder.layers.2.mlp.experts.linear_fc1.weight7
module.decoder.layers.2.mlp.experts.linear_fc1.weight4
Params for bucket 24 (40140800 elements, 40140800 padded size):
module.decoder.layers.1.mlp.experts.linear_fc2.weight49
module.decoder.layers.1.mlp.experts.linear_fc2.weight48
module.decoder.layers.1.mlp.experts.linear_fc2.weight59
module.decoder.layers.1.mlp.experts.linear_fc2.weight41
module.decoder.layers.1.mlp.experts.linear_fc2.weight34
module.decoder.layers.1.mlp.experts.linear_fc2.weight32
module.decoder.layers.1.mlp.experts.linear_fc2.weight29
module.decoder.layers.1.mlp.experts.linear_fc2.weight58
module.decoder.layers.1.mlp.experts.linear_fc2.weight55
module.decoder.layers.1.mlp.experts.linear_fc2.weight52
module.decoder.layers.1.mlp.experts.linear_fc2.weight51
module.decoder.layers.1.mlp.experts.linear_fc2.weight42
module.decoder.layers.1.mlp.experts.linear_fc2.weight45
module.decoder.layers.1.mlp.experts.linear_fc2.weight61
module.decoder.layers.1.mlp.experts.linear_fc2.weight44
module.decoder.layers.1.mlp.experts.linear_fc2.weight38
module.decoder.layers.1.mlp.experts.linear_fc2.weight36
module.decoder.layers.1.mlp.experts.linear_fc2.weight43
module.decoder.layers.1.mlp.experts.linear_fc2.weight35
module.decoder.layers.1.mlp.experts.linear_fc2.weight54
module.decoder.layers.1.mlp.experts.linear_fc2.weight53
module.decoder.layers.1.mlp.experts.linear_fc2.weight47
module.decoder.layers.1.mlp.experts.linear_fc2.weight46
module.decoder.layers.1.mlp.experts.linear_fc2.weight33
module.decoder.layers.1.mlp.experts.linear_fc2.weight31
module.decoder.layers.1.mlp.experts.linear_fc2.weight30
module.decoder.layers.1.mlp.experts.linear_fc2.weight63
module.decoder.layers.1.mlp.experts.linear_fc2.weight57
module.decoder.layers.1.mlp.experts.linear_fc2.weight40
module.decoder.layers.1.mlp.experts.linear_fc2.weight62
module.decoder.layers.1.mlp.experts.linear_fc2.weight60
module.decoder.layers.1.mlp.experts.linear_fc2.weight56
module.decoder.layers.1.mlp.experts.linear_fc2.weight50
module.decoder.layers.1.mlp.experts.linear_fc2.weight39
module.decoder.layers.1.mlp.experts.linear_fc2.weight37
Params for bucket 25 (40140800 elements, 40140800 padded size):
module.decoder.layers.1.mlp.experts.linear_fc2.weight20
module.decoder.layers.1.mlp.experts.linear_fc2.weight18
module.decoder.layers.1.mlp.experts.linear_fc1.weight63
module.decoder.layers.1.mlp.experts.linear_fc2.weight28
module.decoder.layers.1.mlp.experts.linear_fc2.weight17
module.decoder.layers.1.mlp.experts.linear_fc2.weight13
module.decoder.layers.1.mlp.experts.linear_fc1.weight61
module.decoder.layers.1.mlp.experts.linear_fc2.weight25
module.decoder.layers.1.mlp.experts.linear_fc2.weight14
module.decoder.layers.1.mlp.experts.linear_fc2.weight9
module.decoder.layers.1.mlp.experts.linear_fc2.weight8
module.decoder.layers.1.mlp.experts.linear_fc2.weight6
module.decoder.layers.1.mlp.experts.linear_fc2.weight24
module.decoder.layers.1.mlp.experts.linear_fc2.weight16
module.decoder.layers.1.mlp.experts.linear_fc2.weight26
module.decoder.layers.1.mlp.experts.linear_fc2.weight27
module.decoder.layers.1.mlp.experts.linear_fc2.weight22
module.decoder.layers.1.mlp.experts.linear_fc2.weight21
module.decoder.layers.1.mlp.experts.linear_fc2.weight15
module.decoder.layers.1.mlp.experts.linear_fc2.weight2
module.decoder.layers.1.mlp.experts.linear_fc2.weight19
module.decoder.layers.1.mlp.experts.linear_fc2.weight10
module.decoder.layers.1.mlp.experts.linear_fc2.weight7
module.decoder.layers.1.mlp.experts.linear_fc2.weight4
module.decoder.layers.1.mlp.experts.linear_fc2.weight1
module.decoder.layers.1.mlp.experts.linear_fc2.weight12
module.decoder.layers.1.mlp.experts.linear_fc2.weight3
module.decoder.layers.1.mlp.experts.linear_fc1.weight62
module.decoder.layers.1.mlp.experts.linear_fc2.weight23
module.decoder.layers.1.mlp.experts.linear_fc2.weight11
module.decoder.layers.1.mlp.experts.linear_fc2.weight5
module.decoder.layers.1.mlp.experts.linear_fc2.weight0
Params for bucket 26 (41287680 elements, 41287680 padded size):
module.decoder.layers.1.mlp.experts.linear_fc1.weight56
module.decoder.layers.1.mlp.experts.linear_fc1.weight57
module.decoder.layers.1.mlp.experts.linear_fc1.weight58
module.decoder.layers.1.mlp.experts.linear_fc1.weight53
module.decoder.layers.1.mlp.experts.linear_fc1.weight52
module.decoder.layers.1.mlp.experts.linear_fc1.weight50
module.decoder.layers.1.mlp.experts.linear_fc1.weight49
module.decoder.layers.1.mlp.experts.linear_fc1.weight45
module.decoder.layers.1.mlp.experts.linear_fc1.weight60
module.decoder.layers.1.mlp.experts.linear_fc1.weight59
module.decoder.layers.1.mlp.experts.linear_fc1.weight55
module.decoder.layers.1.mlp.experts.linear_fc1.weight54
module.decoder.layers.1.mlp.experts.linear_fc1.weight51
module.decoder.layers.1.mlp.experts.linear_fc1.weight48
module.decoder.layers.1.mlp.experts.linear_fc1.weight47
module.decoder.layers.1.mlp.experts.linear_fc1.weight46
module.decoder.layers.1.mlp.experts.linear_fc1.weight44
module.decoder.layers.1.mlp.experts.linear_fc1.weight43
Params for bucket 27 (41287680 elements, 41287680 padded size):
module.decoder.layers.1.mlp.experts.linear_fc1.weight41
module.decoder.layers.1.mlp.experts.linear_fc1.weight39
module.decoder.layers.1.mlp.experts.linear_fc1.weight40
module.decoder.layers.1.mlp.experts.linear_fc1.weight37
module.decoder.layers.1.mlp.experts.linear_fc1.weight31
module.decoder.layers.1.mlp.experts.linear_fc1.weight27
module.decoder.layers.1.mlp.experts.linear_fc1.weight26
module.decoder.layers.1.mlp.experts.linear_fc1.weight42
module.decoder.layers.1.mlp.experts.linear_fc1.weight38
module.decoder.layers.1.mlp.experts.linear_fc1.weight36
module.decoder.layers.1.mlp.experts.linear_fc1.weight35
module.decoder.layers.1.mlp.experts.linear_fc1.weight34
module.decoder.layers.1.mlp.experts.linear_fc1.weight33
module.decoder.layers.1.mlp.experts.linear_fc1.weight32
module.decoder.layers.1.mlp.experts.linear_fc1.weight30
module.decoder.layers.1.mlp.experts.linear_fc1.weight29
module.decoder.layers.1.mlp.experts.linear_fc1.weight28
module.decoder.layers.1.mlp.experts.linear_fc1.weight25
Params for bucket 28 (41287680 elements, 41287680 padded size):
module.decoder.layers.1.mlp.experts.linear_fc1.weight24
module.decoder.layers.1.mlp.experts.linear_fc1.weight20
module.decoder.layers.1.mlp.experts.linear_fc1.weight23
module.decoder.layers.1.mlp.experts.linear_fc1.weight21
module.decoder.layers.1.mlp.experts.linear_fc1.weight19
module.decoder.layers.1.mlp.experts.linear_fc1.weight17
module.decoder.layers.1.mlp.experts.linear_fc1.weight16
module.decoder.layers.1.mlp.experts.linear_fc1.weight15
module.decoder.layers.1.mlp.experts.linear_fc1.weight11
module.decoder.layers.1.mlp.experts.linear_fc1.weight10
module.decoder.layers.1.mlp.experts.linear_fc1.weight8
module.decoder.layers.1.mlp.experts.linear_fc1.weight7
module.decoder.layers.1.mlp.experts.linear_fc1.weight22
module.decoder.layers.1.mlp.experts.linear_fc1.weight18
module.decoder.layers.1.mlp.experts.linear_fc1.weight14
module.decoder.layers.1.mlp.experts.linear_fc1.weight13
module.decoder.layers.1.mlp.experts.linear_fc1.weight12
module.decoder.layers.1.mlp.experts.linear_fc1.weight9
Params for bucket 29 (49810432 elements, 49810432 padded size):
module.decoder.layers.1.mlp.experts.linear_fc1.weight6
module.decoder.layers.1.mlp.experts.linear_fc1.weight5
module.decoder.layers.1.mlp.experts.linear_fc1.weight3
module.decoder.layers.1.mlp.experts.linear_fc1.weight2
module.decoder.layers.1.mlp.experts.linear_fc1.weight1
module.decoder.layers.1.mlp.experts.linear_fc1.weight0
module.decoder.layers.1.mlp.router.weight
module.decoder.layers.1.pre_mlp_layernorm.weight
module.decoder.layers.1.self_attention.linear_kv_up_proj.layer_norm_weight
module.decoder.layers.1.self_attention.linear_kv_down_proj.weight
module.decoder.layers.0.mlp.linear_fc1.weight
module.decoder.layers.1.mlp.experts.linear_fc1.weight4
module.decoder.layers.1.self_attention.linear_kv_up_proj.weight
module.decoder.layers.1.input_layernorm.weight
module.decoder.layers.0.mlp.linear_fc2.weight
module.decoder.layers.1.self_attention.linear_proj.weight
module.decoder.layers.1.self_attention.linear_q_proj.weight
Params for bucket 30 (200543232 elements, 200543232 padded size):
module.decoder.layers.0.self_attention.linear_kv_up_proj.weight
module.decoder.layers.0.self_attention.linear_q_proj.weight
module.decoder.layers.0.self_attention.linear_proj.weight
module.decoder.layers.0.input_layernorm.weight
module.embedding.word_embeddings.weight
module.decoder.layers.0.mlp.linear_fc1.layer_norm_weight
module.decoder.layers.0.self_attention.linear_kv_up_proj.layer_norm_weight
module.decoder.layers.0.self_attention.linear_kv_down_proj.weight
INFO:megatron.core.optimizer:Setting up optimizer with config OptimizerConfig(optimizer='adam', lr=0.003, min_lr=0.0003, decoupled_lr=None, decoupled_min_lr=None, weight_decay=0.1, fp16=False, bf16=True, params_dtype=torch.bfloat16, use_precision_aware_optimizer=False, store_param_remainders=True, main_grads_dtype=torch.float32, main_params_dtype=torch.float32, exp_avg_dtype=torch.float32, exp_avg_sq_dtype=torch.float32, loss_scale=None, initial_loss_scale=4294967296, min_loss_scale=1.0, loss_scale_window=1000, hysteresis=2, adam_beta1=0.9, adam_beta2=0.95, adam_eps=1e-08, sgd_momentum=0.9, use_distributed_optimizer=True, overlap_param_gather_with_optimizer_step=False, optimizer_cpu_offload=False, optimizer_offload_fraction=1.0, use_torch_optimizer_for_cpu_offload=False, overlap_cpu_optimizer_d2h_h2d=False, pin_cpu_grads=True, pin_cpu_params=True, clip_grad=1.0, log_num_zeros_in_grad=True, barrier_with_L1_time=True, timers=<megatron.core.timers.Timers object at 0x7f6c8e993320>, config_logger_dir='')
setting training iterations to 24000
INFO:megatron.core.optimizer_param_scheduler:> learning rate decay style: cosine
WARNING: could not find the metadata file /data2/workspaces/FlagAI_OpenSeek/OpenSeek-Small-v1-Baseline/checkpoints/latest_checkpointed_iteration.txt
will not load any checkpoints and will start from random
(min, max) time across ranks (ms):
load-checkpoint ................................: (0.41, 0.41)
[after model, optimizer, and learning rate scheduler are built] datetime: 2025-06-27 12:23:30
> building train, validation, and test datasets ...
> datasets target sizes (minimum size):
train: 24576000
validation: 0
test: 0
INFO:megatron.core.datasets.blended_megatron_dataset_config:Let split_matrix = [(0, 1.0), None, None]
> building train, validation, and test datasets for GPT ...
INFO:megatron.core.datasets.blended_megatron_dataset_builder:Building GPTDataset splits with sizes=(24576000, 0, 0) and config=GPTDatasetConfig(random_seed=42, sequence_length=4096, blend=(['../OpenSeek-Pretrain-100B/Nemotron-CC-high-actual-actual-high/part_142_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-actual-actual-low/part_62_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-actual-actual-mid/part_189_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-distill-high/part_76_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-distill-low/part_124_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-distill-mid/part_29_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-diverse_qa_pairs-high/part_244_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-diverse_qa_pairs-low/part_150_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-diverse_qa_pairs-mid/part_444_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-extract_knowledge-high/part_498_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-extract_knowledge-low/part_10_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-extract_knowledge-mid/part_144_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-knowledge_list-high/part_86_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-knowledge_list-low/part_133_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-knowledge_list-mid/part_139_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-wrap_medium-high/part_47_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-wrap_medium-low/part_11_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-wrap_medium-mid/part_97_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-low-synthetic-wrap_medium-high/part_43_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-low-synthetic-wrap_medium-low/part_10_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-low-synthetic-wrap_medium-mid/part_164_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-medium-actual-actual-high/part_92_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-medium-actual-actual-low/part_113_text_document', '../OpenSeek-Pretrain-100B/Nemotron-CC-medium-actual-actual-mid/part_563_text_document', '../OpenSeek-Pretrain-100B/arxiv/007_00000_text_document', '../OpenSeek-Pretrain-100B/books/016_00007_text_document', '../OpenSeek-Pretrain-100B/code-high/part_13_text_document', '../OpenSeek-Pretrain-100B/code-low/part_36_text_document', '../OpenSeek-Pretrain-100B/code-mid/part_37_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-high/23_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-low/51_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/118_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/176_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/256_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/320_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/32_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_OpenSource-high/1_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_OpenSource-low/2_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_OpenSource-mid/3_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_arxiv-high/2_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_arxiv-low/1_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_arxiv-mid/2_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_code-high/4_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_code-low/6_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_code-mid/23_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_math-high/12_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_math-low/3_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_math-mid/5_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_wiki-high/5_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_wiki-low/5_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis2_wiki-mid/4_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_CC-high/74_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_CC-low/54_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_CC-mid/275_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_OpenSource-high/4_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_OpenSource-low/2_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_OpenSource-mid/6_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_arxiv-high/2_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_arxiv-low/1_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_arxiv-mid/1_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_code-high/13_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_code-low/9_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_code-mid/6_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_math-high/11_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_math-low/11_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_math-mid/29_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_wiki-high/4_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_wiki-low/6_text_document', '../OpenSeek-Pretrain-100B/cot_synthesis_wiki-mid/3_text_document', '../OpenSeek-Pretrain-100B/math-high/part_04_text_document', '../OpenSeek-Pretrain-100B/math-low/part_10_text_document', '../OpenSeek-Pretrain-100B/math-mid/part_07_text_document', '../OpenSeek-Pretrain-100B/pes2o-full-train/train-0041-of-0136_text_document', '../OpenSeek-Pretrain-100B/pes2o-full-train/train-0125-of-0136_text_document', '../OpenSeek-Pretrain-100B/pes2o-full-val/valid-0034-of-0060_text_document', '../OpenSeek-Pretrain-100B/pes2o/pubmedcentral_3_text_document', '../OpenSeek-Pretrain-100B/stack/018_00000_text_document', '../OpenSeek-Pretrain-100B/wiki/012_00000_text_document', '../OpenSeek-Pretrain-100B/zh_cc-high-loss0/part_28_text_document', '../OpenSeek-Pretrain-100B/zh_cc-high-loss1/part_59_text_document', '../OpenSeek-Pretrain-100B/zh_cc-high-loss2/part_16_text_document', '../OpenSeek-Pretrain-100B/zh_cc-medidum-loss0/part_192_text_document', '../OpenSeek-Pretrain-100B/zh_cc-medidum-loss1/part_550_text_document', '../OpenSeek-Pretrain-100B/zh_cc-medidum-loss2/part_71_text_document'], [1.1068, 0.3577, 0.7775, 0.2859, 0.1672, 0.2339, 0.5397, 0.4064, 0.5005, 0.4616, 0.067, 0.3429, 0.261, 0.1824, 0.2313, 0.8237, 0.2866, 0.667, 0.4657, 0.2005, 0.4317, 1.1397, 0.6782, 0.9175, 0.6414, 0.4696, 1.0102, 1.1403, 0.9674, 0.3755, 0.0499, 0.3608, 0.3623, 0.3704, 0.3733, 0.3631, 0.2573, 0.1638, 0.3251, 6.0237, 8.9063, 10.1376, 0.4598, 0.6857, 0.899, 1.3135, 1.653, 0.3536, 0.6314, 0.5978, 0.7909, 0.2225, 0.1797, 0.2042, 0.4081, 0.1659, 1.2828, 5.68, 7.4907, 8.9359, 0.7663, 0.4052, 0.1916, 0.5074, 0.6437, 0.6406, 0.4, 0.3564, 0.5768, 1.8165, 1.694, 1.6311, 0.687, 0.7387, 0.0143, 6.1982, 0.4229, 0.4202, 1.8171, 0.9776, 0.3725, 0.9492, 0.9236, 1.0643]), blend_per_split=None, split='1', split_matrix=[(0, 1.0), None, None], num_dataset_builder_threads=1, path_to_cache=None, mmap_bin_files=False, mock=False, tokenizer=<megatron.training.tokenizer.tokenizer._QwenTokenizerFS object at 0x7f6c8f08bcb0>, mid_level_dataset_surplus=0.005, reset_position_ids=True, reset_attention_mask=True, eod_mask_loss=False, create_attention_mask=True, drop_last_partial_validation_sequence=True, add_extra_token_to_sequence=True, object_storage_cache_path=None)
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-actual-actual-high/part_142_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 3bcf97bf902bc7c1b1bdfc6f43697d5c-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 3bcf97bf902bc7c1b1bdfc6f43697d5c-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 3bcf97bf902bc7c1b1bdfc6f43697d5c-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 278453
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-actual-actual-low/part_62_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 42edf795324f414dfcabdcfd7d860a40-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 42edf795324f414dfcabdcfd7d860a40-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 42edf795324f414dfcabdcfd7d860a40-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 90001
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-actual-actual-mid/part_189_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from fbd05c4b24607c4e84548924fc59cca2-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from fbd05c4b24607c4e84548924fc59cca2-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from fbd05c4b24607c4e84548924fc59cca2-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 195608
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-distill-high/part_76_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 93b91bf5fd05a6901f85ce49182a8582-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 93b91bf5fd05a6901f85ce49182a8582-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 93b91bf5fd05a6901f85ce49182a8582-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 71916
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-distill-low/part_124_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from c156036a9186aa56bd0f678fb3c80d3f-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from c156036a9186aa56bd0f678fb3c80d3f-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from c156036a9186aa56bd0f678fb3c80d3f-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 42075
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-distill-mid/part_29_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 38419ede70ce7c575159593f3a3fc94d-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 38419ede70ce7c575159593f3a3fc94d-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 38419ede70ce7c575159593f3a3fc94d-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 58837
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-diverse_qa_pairs-high/part_244_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 4762bb70c45a00a24c261d684e5ce4ff-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 4762bb70c45a00a24c261d684e5ce4ff-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 4762bb70c45a00a24c261d684e5ce4ff-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 135775
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-diverse_qa_pairs-low/part_150_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 421b3d6f3adf7fab7d6fa68067570d8f-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 421b3d6f3adf7fab7d6fa68067570d8f-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 421b3d6f3adf7fab7d6fa68067570d8f-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 102232
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-diverse_qa_pairs-mid/part_444_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from ba00e53917af4de1938c3e89a305da94-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from ba00e53917af4de1938c3e89a305da94-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from ba00e53917af4de1938c3e89a305da94-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 125911
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-extract_knowledge-high/part_498_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 91379f2ddcb832c61f886a23d6f26843-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 91379f2ddcb832c61f886a23d6f26843-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 91379f2ddcb832c61f886a23d6f26843-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 116141
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-extract_knowledge-low/part_10_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 325354
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 325354
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 49da887f9ea0fe93926b5194b3e73e64-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 49da887f9ea0fe93926b5194b3e73e64-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 49da887f9ea0fe93926b5194b3e73e64-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 16844
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-extract_knowledge-mid/part_144_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from f1a511b8258c5b2ef7cb0880677d5320-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from f1a511b8258c5b2ef7cb0880677d5320-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from f1a511b8258c5b2ef7cb0880677d5320-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 86258
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-knowledge_list-high/part_86_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from a52b401753534e6b0add72400982b06a-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from a52b401753534e6b0add72400982b06a-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from a52b401753534e6b0add72400982b06a-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 65662
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-knowledge_list-low/part_133_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 5519d9210b1853b80c89283c5b8219bd-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 5519d9210b1853b80c89283c5b8219bd-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 5519d9210b1853b80c89283c5b8219bd-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 45891
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-knowledge_list-mid/part_139_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from ecbf550b30bfc696b0d4912fd82d990f-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from ecbf550b30bfc696b0d4912fd82d990f-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from ecbf550b30bfc696b0d4912fd82d990f-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 58196
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-wrap_medium-high/part_47_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from e4aeb3128a4705d3c4b914a618670c60-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from e4aeb3128a4705d3c4b914a618670c60-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from e4aeb3128a4705d3c4b914a618670c60-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 207235
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-wrap_medium-low/part_11_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from a9f99f617847aa8f6179da4f53b838af-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from a9f99f617847aa8f6179da4f53b838af-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from a9f99f617847aa8f6179da4f53b838af-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 72100
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-high-synthetic-wrap_medium-mid/part_97_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 063fab3df418ed000462f842ac8d49ea-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 063fab3df418ed000462f842ac8d49ea-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 063fab3df418ed000462f842ac8d49ea-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 167804
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-low-synthetic-wrap_medium-high/part_43_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 92c67007e7c71328e23b10f14bbdf0d9-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 92c67007e7c71328e23b10f14bbdf0d9-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 92c67007e7c71328e23b10f14bbdf0d9-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 117162
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-low-synthetic-wrap_medium-low/part_10_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 97123868ddd599ebe18baa058e80c79d-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 97123868ddd599ebe18baa058e80c79d-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 97123868ddd599ebe18baa058e80c79d-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 50433
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-low-synthetic-wrap_medium-mid/part_164_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 31933f6459e2d65890af1f316c530035-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 31933f6459e2d65890af1f316c530035-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 31933f6459e2d65890af1f316c530035-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 108609
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-medium-actual-actual-high/part_92_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from d1c63d01256da2dbfb9fc6012b0cf457-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from d1c63d01256da2dbfb9fc6012b0cf457-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from d1c63d01256da2dbfb9fc6012b0cf457-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 286720
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-medium-actual-actual-low/part_113_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 06a4931530206c4caa9999e2a116c216-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 06a4931530206c4caa9999e2a116c216-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 06a4931530206c4caa9999e2a116c216-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 170626
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/Nemotron-CC-medium-actual-actual-mid/part_563_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from cea463b205f3d64bc57cd0bf402f517a-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from cea463b205f3d64bc57cd0bf402f517a-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from cea463b205f3d64bc57cd0bf402f517a-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 230810
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/arxiv/007_00000_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 36740
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 36740
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 6443055721fcb34913a77945da3c3a0e-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 6443055721fcb34913a77945da3c3a0e-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 6443055721fcb34913a77945da3c3a0e-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 161355
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/books/016_00007_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 4969
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 4969
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 10bf636698c127d1a24bbf6d2eda2aee-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 10bf636698c127d1a24bbf6d2eda2aee-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 10bf636698c127d1a24bbf6d2eda2aee-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 118143
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/code-high/part_13_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 21cd90b13a6517160b33ca8685f946a8-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 21cd90b13a6517160b33ca8685f946a8-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 21cd90b13a6517160b33ca8685f946a8-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 254137
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/code-low/part_36_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 499c6fff9032a79c988ab8063ce949e1-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 499c6fff9032a79c988ab8063ce949e1-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 499c6fff9032a79c988ab8063ce949e1-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 286865
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/code-mid/part_37_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 52e1e8829398a339b53880f97a35f5fd-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 52e1e8829398a339b53880f97a35f5fd-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 52e1e8829398a339b53880f97a35f5fd-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 243365
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_CC-high/23_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 78a0fcb91abd174d65bb6cc0d46e617d-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 78a0fcb91abd174d65bb6cc0d46e617d-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 78a0fcb91abd174d65bb6cc0d46e617d-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 94468
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_CC-low/51_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 73459
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 73459
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 82ad0782ac038979c9eaf5146ff201a9-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 82ad0782ac038979c9eaf5146ff201a9-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 82ad0782ac038979c9eaf5146ff201a9-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 12546
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/118_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 61ededc3c5fec8599ebac2c9268839d2-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 61ededc3c5fec8599ebac2c9268839d2-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 61ededc3c5fec8599ebac2c9268839d2-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 90757
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/176_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from f6f063fadb56f7471be6fd7c52d961a9-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from f6f063fadb56f7471be6fd7c52d961a9-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from f6f063fadb56f7471be6fd7c52d961a9-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 91135
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/256_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 0fac24c40f9207ba4e1c876f67ac890f-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 0fac24c40f9207ba4e1c876f67ac890f-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 0fac24c40f9207ba4e1c876f67ac890f-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 93182
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/320_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 6e257a563aa1f477457f9d5063f31c3f-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 6e257a563aa1f477457f9d5063f31c3f-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 6e257a563aa1f477457f9d5063f31c3f-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 93904
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_CC-mid/32_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from c8fceab04f7a896b8a87caea00adf17e-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from c8fceab04f7a896b8a87caea00adf17e-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from c8fceab04f7a896b8a87caea00adf17e-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 91340
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_OpenSource-high/1_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 6b309498174da0deb341abe9aa36a0e8-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 6b309498174da0deb341abe9aa36a0e8-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 6b309498174da0deb341abe9aa36a0e8-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 64738
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_OpenSource-low/2_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 398e9530d4c8410e322ac338179666ca-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 398e9530d4c8410e322ac338179666ca-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 398e9530d4c8410e322ac338179666ca-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 41218
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_OpenSource-mid/3_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from da0fb5525d01182e1daf66b4dbd842b4-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from da0fb5525d01182e1daf66b4dbd842b4-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from da0fb5525d01182e1daf66b4dbd842b4-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 81781
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_arxiv-high/2_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 256516
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 256516
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 5257e77c1f3591b9cf58683b58f3dcc3-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 5257e77c1f3591b9cf58683b58f3dcc3-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 5257e77c1f3591b9cf58683b58f3dcc3-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 1515440
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_arxiv-low/1_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 097db078c0fd21058b81a805201e1740-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 097db078c0fd21058b81a805201e1740-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 097db078c0fd21058b81a805201e1740-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 2240642
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_arxiv-mid/2_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from de2315b46c9e398c3e52816dce050a9a-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from de2315b46c9e398c3e52816dce050a9a-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from de2315b46c9e398c3e52816dce050a9a-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 2550407
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_code-high/4_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from c33b0b590a676cb05db1bdb9a99c5b2a-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from c33b0b590a676cb05db1bdb9a99c5b2a-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from c33b0b590a676cb05db1bdb9a99c5b2a-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 115665
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_code-low/6_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 0a144fd0007b87526df5be9acef24430-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 0a144fd0007b87526df5be9acef24430-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 0a144fd0007b87526df5be9acef24430-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 172518
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_code-mid/23_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from f79878c937ae3ea237f9aecc49b2185f-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from f79878c937ae3ea237f9aecc49b2185f-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from f79878c937ae3ea237f9aecc49b2185f-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 226180
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_math-high/12_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 5ece26b572b5dca7ffe7945c6c9226c7-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 5ece26b572b5dca7ffe7945c6c9226c7-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 5ece26b572b5dca7ffe7945c6c9226c7-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 330448
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_math-low/3_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 23783151274dfea0577aea5f996dc236-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 23783151274dfea0577aea5f996dc236-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 23783151274dfea0577aea5f996dc236-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 415859
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_math-mid/5_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 647d18ed6efe43a6a42bddfeabba04f1-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 647d18ed6efe43a6a42bddfeabba04f1-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 647d18ed6efe43a6a42bddfeabba04f1-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 88947
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_wiki-high/5_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 167169b90da1e60c19514db0924b1e20-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 167169b90da1e60c19514db0924b1e20-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 167169b90da1e60c19514db0924b1e20-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 158858
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_wiki-low/5_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from ce096f4bf7b8552c29fea089860705c4-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from ce096f4bf7b8552c29fea089860705c4-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from ce096f4bf7b8552c29fea089860705c4-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 150385
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis2_wiki-mid/4_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from b4c94e45cf9ca3107266571ad6b407e2-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from b4c94e45cf9ca3107266571ad6b407e2-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from b4c94e45cf9ca3107266571ad6b407e2-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 198961
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_CC-high/74_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from a8fa8dd8d69d1cd8935b3457875c39c4-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from a8fa8dd8d69d1cd8935b3457875c39c4-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from a8fa8dd8d69d1cd8935b3457875c39c4-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 55987
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_CC-low/54_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from f461ed8995dac3b75450c24fc74ccf40-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from f461ed8995dac3b75450c24fc74ccf40-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from f461ed8995dac3b75450c24fc74ccf40-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 45202
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_CC-mid/275_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 9a44f36019d65846dd82c700062bc27c-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 9a44f36019d65846dd82c700062bc27c-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 9a44f36019d65846dd82c700062bc27c-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 51384
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_OpenSource-high/4_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 05388d8ae2767f997f3a327b6162fa0c-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 05388d8ae2767f997f3a327b6162fa0c-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 05388d8ae2767f997f3a327b6162fa0c-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 102662
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_OpenSource-low/2_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 99d51016a10dfaaaf8aa11f19ca47eec-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 99d51016a10dfaaaf8aa11f19ca47eec-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 99d51016a10dfaaaf8aa11f19ca47eec-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 41745
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_OpenSource-mid/6_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 8376d733799a069256ae09b1bcd6dcab-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 8376d733799a069256ae09b1bcd6dcab-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 8376d733799a069256ae09b1bcd6dcab-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 322718
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_arxiv-high/2_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 256516
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 256516
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 3a33c9308a021d4054fa13c21cf4952f-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 3a33c9308a021d4054fa13c21cf4952f-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 3a33c9308a021d4054fa13c21cf4952f-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 1428961
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_arxiv-low/1_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 9efb6b5b415537b5bc066d9cc2c620b3-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 9efb6b5b415537b5bc066d9cc2c620b3-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 9efb6b5b415537b5bc066d9cc2c620b3-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 1884499
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_arxiv-mid/1_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 13f6793fe99fe92439722cddaf40727e-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 13f6793fe99fe92439722cddaf40727e-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 13f6793fe99fe92439722cddaf40727e-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 2248083
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_code-high/13_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 55f9b728813d421a6eda80c4e4386d81-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 55f9b728813d421a6eda80c4e4386d81-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 55f9b728813d421a6eda80c4e4386d81-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 192791
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_code-low/9_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from af2b2f630340e8986a7fa73fde612311-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from af2b2f630340e8986a7fa73fde612311-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from af2b2f630340e8986a7fa73fde612311-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 101935
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_code-mid/6_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from da5b6dc21e950c12d3ac425bfd1f091f-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from da5b6dc21e950c12d3ac425bfd1f091f-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from da5b6dc21e950c12d3ac425bfd1f091f-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 48202
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_math-high/11_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from ad21fc502df49664e479a402ec05d322-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from ad21fc502df49664e479a402ec05d322-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from ad21fc502df49664e479a402ec05d322-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 127661
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_math-low/11_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 26ec788a6472d7a4fc2abb1fd801bd83-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 26ec788a6472d7a4fc2abb1fd801bd83-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 26ec788a6472d7a4fc2abb1fd801bd83-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 161943
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_math-mid/29_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from a4ff47cc44a1bcd08f765fc5846d53fb-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from a4ff47cc44a1bcd08f765fc5846d53fb-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from a4ff47cc44a1bcd08f765fc5846d53fb-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 161166
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_wiki-high/4_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 9c88f9a84c38df50a45e7390a09215f0-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 9c88f9a84c38df50a45e7390a09215f0-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 9c88f9a84c38df50a45e7390a09215f0-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 100623
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_wiki-low/6_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from f7239aa9de74201060aed61b1cdf0c6b-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from f7239aa9de74201060aed61b1cdf0c6b-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from f7239aa9de74201060aed61b1cdf0c6b-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 89674
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/cot_synthesis_wiki-mid/3_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 500000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 500000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 75221ad5995f5e1b284e1451bc21e7ea-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 75221ad5995f5e1b284e1451bc21e7ea-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 75221ad5995f5e1b284e1451bc21e7ea-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 145122
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/math-high/part_04_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from ef51ee55d8f6603934f08ce635314fad-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from ef51ee55d8f6603934f08ce635314fad-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from ef51ee55d8f6603934f08ce635314fad-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 456998
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/math-low/part_10_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 183681f26924ef7e06ab027733f0490e-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 183681f26924ef7e06ab027733f0490e-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 183681f26924ef7e06ab027733f0490e-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 426167
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/math-mid/part_07_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 2c02a9a76de03db0d4cbd2b78a34e2e8-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 2c02a9a76de03db0d4cbd2b78a34e2e8-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 2c02a9a76de03db0d4cbd2b78a34e2e8-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 410354
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/pes2o-full-train/train-0041-of-0136_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 111715
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 111715
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 4bedbf63df1ea1c142930c7b58689315-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 4bedbf63df1ea1c142930c7b58689315-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 4bedbf63df1ea1c142930c7b58689315-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 172833
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/pes2o-full-train/train-0125-of-0136_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 120151
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 120151
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 8c143921153f51208327e9e6c80f3996-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 8c143921153f51208327e9e6c80f3996-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 8c143921153f51208327e9e6c80f3996-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 185836
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/pes2o-full-val/valid-0034-of-0060_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 2066
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 2066
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 17b24baded5fb547c2bdd1eca38d9e8d-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 17b24baded5fb547c2bdd1eca38d9e8d-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 17b24baded5fb547c2bdd1eca38d9e8d-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 3587
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/pes2o/pubmedcentral_3_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1000000
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1000000
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 817bacd90c33f000963995212597faeb-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 817bacd90c33f000963995212597faeb-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 817bacd90c33f000963995212597faeb-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 1559325
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/stack/018_00000_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 725493
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 725493
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 70fbfb40decd8fd580ba438c4fe3a326-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 70fbfb40decd8fd580ba438c4fe3a326-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 70fbfb40decd8fd580ba438c4fe3a326-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 106399
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/wiki/012_00000_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 952137
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 952137
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 0f1298d7bcb5257da1d1fed0af30cf27-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 0f1298d7bcb5257da1d1fed0af30cf27-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 0f1298d7bcb5257da1d1fed0af30cf27-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 105713
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/zh_cc-high-loss0/part_28_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1014022
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1014022
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 8a41ddce0a4e9446a2a38ecaf18b8319-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 8a41ddce0a4e9446a2a38ecaf18b8319-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 8a41ddce0a4e9446a2a38ecaf18b8319-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 457136
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/zh_cc-high-loss1/part_59_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1024772
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1024772
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 90b19f2d251220dc983bbbbee1bbaa16-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 90b19f2d251220dc983bbbbee1bbaa16-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 90b19f2d251220dc983bbbbee1bbaa16-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 245948
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/zh_cc-high-loss2/part_16_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1006257
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1006257
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 89ab9dff4a2d78068a6f282a80ae15d6-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 89ab9dff4a2d78068a6f282a80ae15d6-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 89ab9dff4a2d78068a6f282a80ae15d6-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 93708
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/zh_cc-medidum-loss0/part_192_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1003089
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1003089
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 3850bffbf498895bd2a9179e4d7dcea3-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 3850bffbf498895bd2a9179e4d7dcea3-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 3850bffbf498895bd2a9179e4d7dcea3-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 238798
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/zh_cc-medidum-loss1/part_550_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1012308
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1012308
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from acdca4be0c37ea582f652270b04903dd-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from acdca4be0c37ea582f652270b04903dd-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from acdca4be0c37ea582f652270b04903dd-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 232358
INFO:megatron.core.datasets.indexed_dataset:Load the _IndexReader from ../OpenSeek-Pretrain-100B/zh_cc-medidum-loss2/part_71_text_document.idx
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence lengths
INFO:megatron.core.datasets.indexed_dataset: Extract the sequence pointers
INFO:megatron.core.datasets.indexed_dataset: Extract the document indices
INFO:megatron.core.datasets.indexed_dataset:> total number of sequences: 1013689
INFO:megatron.core.datasets.indexed_dataset:> total number of documents: 1013689
INFO:megatron.core.datasets.gpt_dataset:Load the GPTDataset train indices
INFO:megatron.core.datasets.gpt_dataset: Load the document index from 7d71d34ab9676e73d600759f5bf29f96-GPTDataset-train-document_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the sample index from 7d71d34ab9676e73d600759f5bf29f96-GPTDataset-train-sample_index.npy
INFO:megatron.core.datasets.gpt_dataset: Load the shuffle index from 7d71d34ab9676e73d600759f5bf29f96-GPTDataset-train-shuffle_index.npy
INFO:megatron.core.datasets.gpt_dataset:> total number of samples: 267765
INFO:megatron.core.datasets.blended_dataset:Build and save the BlendedDataset indices
INFO:megatron.core.datasets.blended_dataset: Build and save the dataset and dataset sample indexes
WARNING:megatron.core.datasets.blended_dataset:Cannot save the BlendedDataset indexes because path_to_cache is None
> finished creating GPT datasets ...
[after dataloaders are built] datetime: 2025-06-27 12:23:34
done with setup ...
(min, max) time across ranks (ms):
model-and-optimizer-setup ......................: (320.15, 320.15)
train/valid/test-data-iterators-setup ..........: (3543.10, 3543.10)
training ...
Setting rerun_state_machine.current_iteration to 0...
[before the start of training step] datetime: 2025-06-27 12:23:34
[2025-06-27 12:27:53] iteration 1/ 24000 | consumed samples: 1024 | elapsed time per iteration (ms): 258947.6 | throughput per GPU (TFLOP/s/GPU): 42.3 | learning rate: 1.500000E-06 | global batch size: 1024 | lm loss: 1.192634E+01 | load_balancing_loss: 1.041995E+00 | loss scale: 1.0 | grad norm: 5.960 | num zeros: 0.0 | params norm: 238.330 | number of skipped iterations: 0 | number of nan iterations: 0 |
Number of parameters in transformer block in billions: 1.20
Number of parameters in embedding layers in billions: 0.19
Total number of parameters in billions: 1.39
Number of parameters in most loaded shard in billions: 1.3942
Theoretical memory footprints: weight and optimizer=23933.59 MB
[Rank 0] (after 1 iterations) memory (MB) | allocated: 24119.04443359375 | max allocated: 24119.55126953125 | reserved: 26416.0 | max reserved: 26416.0
[2025-06-27 12:32:13] iteration 2/ 24000 | consumed samples: 2048 | elapsed time per iteration (ms): 260283.7 | throughput per GPU (TFLOP/s/GPU): 42.1 | learning rate: 3.000000E-06 | global batch size: 1024 | lm loss: 1.192975E+01 | load_balancing_loss: 1.041399E+00 | loss scale: 1.0 | grad norm: 5.938 | num zeros: 0.0 | params norm: 238.330 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 12:36:33] iteration 3/ 24000 | consumed samples: 3072 | elapsed time per iteration (ms): 260541.1 | throughput per GPU (TFLOP/s/GPU): 42.1 | learning rate: 4.500000E-06 | global batch size: 1024 | lm loss: 1.191912E+01 | load_balancing_loss: 1.041041E+00 | loss scale: 1.0 | grad norm: 5.986 | num zeros: 0.0 | params norm: 238.330 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 12:40:53] iteration 4/ 24000 | consumed samples: 4096 | elapsed time per iteration (ms): 259756.9 | throughput per GPU (TFLOP/s/GPU): 42.2 | learning rate: 6.000000E-06 | global batch size: 1024 | lm loss: 1.184126E+01 | load_balancing_loss: 1.043573E+00 | loss scale: 1.0 | grad norm: 5.782 | num zeros: 0.0 | params norm: 238.330 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 12:45:14] iteration 5/ 24000 | consumed samples: 5120 | elapsed time per iteration (ms): 260413.5 | throughput per GPU (TFLOP/s/GPU): 42.1 | learning rate: 7.500000E-06 | global batch size: 1024 | lm loss: 1.174128E+01 | load_balancing_loss: 1.052462E+00 | loss scale: 1.0 | grad norm: 5.367 | num zeros: 1.0 | params norm: 238.330 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 12:49:34] iteration 6/ 24000 | consumed samples: 6144 | elapsed time per iteration (ms): 260808.5 | throughput per GPU (TFLOP/s/GPU): 42.0 | learning rate: 9.000000E-06 | global batch size: 1024 | lm loss: 1.167125E+01 | load_balancing_loss: 1.060444E+00 | loss scale: 1.0 | grad norm: 5.116 | num zeros: 0.0 | params norm: 238.330 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 12:53:54] iteration 7/ 24000 | consumed samples: 7168 | elapsed time per iteration (ms): 259943.4 | throughput per GPU (TFLOP/s/GPU): 42.2 | learning rate: 1.050000E-05 | global batch size: 1024 | lm loss: 1.156939E+01 | load_balancing_loss: 1.075724E+00 | loss scale: 1.0 | grad norm: 4.446 | num zeros: 1.0 | params norm: 238.330 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 12:58:14] iteration 8/ 24000 | consumed samples: 8192 | elapsed time per iteration (ms): 259467.8 | throughput per GPU (TFLOP/s/GPU): 42.3 | learning rate: 1.200000E-05 | global batch size: 1024 | lm loss: 1.149021E+01 | load_balancing_loss: 1.089425E+00 | loss scale: 1.0 | grad norm: 3.690 | num zeros: 1.0 | params norm: 238.331 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 13:02:32] iteration 9/ 24000 | consumed samples: 9216 | elapsed time per iteration (ms): 258421.4 | throughput per GPU (TFLOP/s/GPU): 42.4 | learning rate: 1.350000E-05 | global batch size: 1024 | lm loss: 1.142278E+01 | load_balancing_loss: 1.098188E+00 | loss scale: 1.0 | grad norm: 3.258 | num zeros: 0.0 | params norm: 238.333 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 13:06:50] iteration 10/ 24000 | consumed samples: 10240 | elapsed time per iteration (ms): 257502.7 | throughput per GPU (TFLOP/s/GPU): 42.6 | learning rate: 1.500000E-05 | global batch size: 1024 | lm loss: 1.135647E+01 | load_balancing_loss: 1.102417E+00 | loss scale: 1.0 | grad norm: 2.955 | num zeros: 0.0 | params norm: 238.335 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 13:11:08] iteration 11/ 24000 | consumed samples: 11264 | elapsed time per iteration (ms): 257793.8 | throughput per GPU (TFLOP/s/GPU): 42.5 | learning rate: 1.650000E-05 | global batch size: 1024 | lm loss: 1.131526E+01 | load_balancing_loss: 1.101932E+00 | loss scale: 1.0 | grad norm: 2.657 | num zeros: 1.0 | params norm: 238.338 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 13:15:26] iteration 12/ 24000 | consumed samples: 12288 | elapsed time per iteration (ms): 258544.5 | throughput per GPU (TFLOP/s/GPU): 42.4 | learning rate: 1.800000E-05 | global batch size: 1024 | lm loss: 1.128093E+01 | load_balancing_loss: 1.100040E+00 | loss scale: 1.0 | grad norm: 2.531 | num zeros: 0.0 | params norm: 238.341 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 13:19:47] iteration 13/ 24000 | consumed samples: 13312 | elapsed time per iteration (ms): 261221.8 | throughput per GPU (TFLOP/s/GPU): 42.0 | learning rate: 1.950000E-05 | global batch size: 1024 | lm loss: 1.122959E+01 | load_balancing_loss: 1.097064E+00 | loss scale: 1.0 | grad norm: 2.656 | num zeros: 1.0 | params norm: 238.346 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 13:24:08] iteration 14/ 24000 | consumed samples: 14336 | elapsed time per iteration (ms): 260648.7 | throughput per GPU (TFLOP/s/GPU): 42.1 | learning rate: 2.100000E-05 | global batch size: 1024 | lm loss: 1.117949E+01 | load_balancing_loss: 1.093009E+00 | loss scale: 1.0 | grad norm: 2.415 | num zeros: 0.0 | params norm: 238.351 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 13:28:29] iteration 15/ 24000 | consumed samples: 15360 | elapsed time per iteration (ms): 260931.1 | throughput per GPU (TFLOP/s/GPU): 42.0 | learning rate: 2.250000E-05 | global batch size: 1024 | lm loss: 1.112640E+01 | load_balancing_loss: 1.087326E+00 | loss scale: 1.0 | grad norm: 2.490 | num zeros: 0.0 | params norm: 238.358 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 13:32:50] iteration 16/ 24000 | consumed samples: 16384 | elapsed time per iteration (ms): 261004.3 | throughput per GPU (TFLOP/s/GPU): 42.0 | learning rate: 2.400000E-05 | global batch size: 1024 | lm loss: 1.107808E+01 | load_balancing_loss: 1.079241E+00 | loss scale: 1.0 | grad norm: 2.431 | num zeros: 0.0 | params norm: 238.366 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 13:37:12] iteration 17/ 24000 | consumed samples: 17408 | elapsed time per iteration (ms): 261991.3 | throughput per GPU (TFLOP/s/GPU): 41.9 | learning rate: 2.550000E-05 | global batch size: 1024 | lm loss: 1.101676E+01 | load_balancing_loss: 1.070701E+00 | loss scale: 1.0 | grad norm: 2.961 | num zeros: 0.0 | params norm: 238.376 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 13:41:35] iteration 18/ 24000 | consumed samples: 18432 | elapsed time per iteration (ms): 262600.2 | throughput per GPU (TFLOP/s/GPU): 41.8 | learning rate: 2.700000E-05 | global batch size: 1024 | lm loss: 1.093517E+01 | load_balancing_loss: 1.067473E+00 | loss scale: 1.0 | grad norm: 2.937 | num zeros: 2.0 | params norm: 238.388 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 13:45:57] iteration 19/ 24000 | consumed samples: 19456 | elapsed time per iteration (ms): 262636.4 | throughput per GPU (TFLOP/s/GPU): 41.8 | learning rate: 2.850000E-05 | global batch size: 1024 | lm loss: 1.086546E+01 | load_balancing_loss: 1.060247E+00 | loss scale: 1.0 | grad norm: 3.895 | num zeros: 0.0 | params norm: 238.401 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 13:50:20] iteration 20/ 24000 | consumed samples: 20480 | elapsed time per iteration (ms): 262766.2 | throughput per GPU (TFLOP/s/GPU): 41.7 | learning rate: 3.000000E-05 | global batch size: 1024 | lm loss: 1.081787E+01 | load_balancing_loss: 1.056373E+00 | loss scale: 1.0 | grad norm: 3.499 | num zeros: 1.0 | params norm: 238.416 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 13:54:44] iteration 21/ 24000 | consumed samples: 21504 | elapsed time per iteration (ms): 263680.6 | throughput per GPU (TFLOP/s/GPU): 41.6 | learning rate: 3.150000E-05 | global batch size: 1024 | lm loss: 1.073946E+01 | load_balancing_loss: 1.050537E+00 | loss scale: 1.0 | grad norm: 3.805 | num zeros: 1.0 | params norm: 238.432 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 13:59:07] iteration 22/ 24000 | consumed samples: 22528 | elapsed time per iteration (ms): 263207.2 | throughput per GPU (TFLOP/s/GPU): 41.7 | learning rate: 3.300000E-05 | global batch size: 1024 | lm loss: 1.066498E+01 | load_balancing_loss: 1.049672E+00 | loss scale: 1.0 | grad norm: 2.622 | num zeros: 0.0 | params norm: 238.451 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 14:03:30] iteration 23/ 24000 | consumed samples: 23552 | elapsed time per iteration (ms): 263641.7 | throughput per GPU (TFLOP/s/GPU): 41.6 | learning rate: 3.450000E-05 | global batch size: 1024 | lm loss: 1.060945E+01 | load_balancing_loss: 1.047704E+00 | loss scale: 1.0 | grad norm: 2.150 | num zeros: 0.0 | params norm: 238.471 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 14:07:53] iteration 24/ 24000 | consumed samples: 24576 | elapsed time per iteration (ms): 262820.3 | throughput per GPU (TFLOP/s/GPU): 41.7 | learning rate: 3.600000E-05 | global batch size: 1024 | lm loss: 1.054304E+01 | load_balancing_loss: 1.045879E+00 | loss scale: 1.0 | grad norm: 2.249 | num zeros: 0.0 | params norm: 238.495 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 14:12:17] iteration 25/ 24000 | consumed samples: 25600 | elapsed time per iteration (ms): 263325.3 | throughput per GPU (TFLOP/s/GPU): 41.6 | learning rate: 3.750000E-05 | global batch size: 1024 | lm loss: 1.048294E+01 | load_balancing_loss: 1.044638E+00 | loss scale: 1.0 | grad norm: 2.400 | num zeros: 0.0 | params norm: 238.520 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 14:16:40] iteration 26/ 24000 | consumed samples: 26624 | elapsed time per iteration (ms): 262943.7 | throughput per GPU (TFLOP/s/GPU): 41.7 | learning rate: 3.900000E-05 | global batch size: 1024 | lm loss: 1.042026E+01 | load_balancing_loss: 1.041865E+00 | loss scale: 1.0 | grad norm: 2.440 | num zeros: 0.0 | params norm: 238.548 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 14:21:03] iteration 27/ 24000 | consumed samples: 27648 | elapsed time per iteration (ms): 263056.6 | throughput per GPU (TFLOP/s/GPU): 41.7 | learning rate: 4.050000E-05 | global batch size: 1024 | lm loss: 1.033104E+01 | load_balancing_loss: 1.043118E+00 | loss scale: 1.0 | grad norm: 2.389 | num zeros: 0.0 | params norm: 238.579 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 14:25:26] iteration 28/ 24000 | consumed samples: 28672 | elapsed time per iteration (ms): 263034.5 | throughput per GPU (TFLOP/s/GPU): 41.7 | learning rate: 4.200000E-05 | global batch size: 1024 | lm loss: 1.026868E+01 | load_balancing_loss: 1.040587E+00 | loss scale: 1.0 | grad norm: 2.169 | num zeros: 0.0 | params norm: 238.612 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 14:29:48] iteration 29/ 24000 | consumed samples: 29696 | elapsed time per iteration (ms): 262752.9 | throughput per GPU (TFLOP/s/GPU): 41.7 | learning rate: 4.350000E-05 | global batch size: 1024 | lm loss: 1.018083E+01 | load_balancing_loss: 1.041168E+00 | loss scale: 1.0 | grad norm: 2.247 | num zeros: 0.0 | params norm: 238.648 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 14:34:12] iteration 30/ 24000 | consumed samples: 30720 | elapsed time per iteration (ms): 263202.5 | throughput per GPU (TFLOP/s/GPU): 41.7 | learning rate: 4.500000E-05 | global batch size: 1024 | lm loss: 1.011347E+01 | load_balancing_loss: 1.042428E+00 | loss scale: 1.0 | grad norm: 2.255 | num zeros: 1.0 | params norm: 238.686 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 14:38:34] iteration 31/ 24000 | consumed samples: 31744 | elapsed time per iteration (ms): 262553.6 | throughput per GPU (TFLOP/s/GPU): 41.8 | learning rate: 4.650000E-05 | global batch size: 1024 | lm loss: 1.002936E+01 | load_balancing_loss: 1.040154E+00 | loss scale: 1.0 | grad norm: 2.140 | num zeros: 1.0 | params norm: 238.728 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 14:42:57] iteration 32/ 24000 | consumed samples: 32768 | elapsed time per iteration (ms): 263258.3 | throughput per GPU (TFLOP/s/GPU): 41.7 | learning rate: 4.800000E-05 | global batch size: 1024 | lm loss: 9.967064E+00 | load_balancing_loss: 1.039624E+00 | loss scale: 1.0 | grad norm: 2.145 | num zeros: 1.0 | params norm: 238.773 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 14:47:20] iteration 33/ 24000 | consumed samples: 33792 | elapsed time per iteration (ms): 263033.7 | throughput per GPU (TFLOP/s/GPU): 41.7 | learning rate: 4.950000E-05 | global batch size: 1024 | lm loss: 9.870680E+00 | load_balancing_loss: 1.039607E+00 | loss scale: 1.0 | grad norm: 2.177 | num zeros: 0.0 | params norm: 238.821 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 14:51:44] iteration 34/ 24000 | consumed samples: 34816 | elapsed time per iteration (ms): 263226.2 | throughput per GPU (TFLOP/s/GPU): 41.7 | learning rate: 5.100000E-05 | global batch size: 1024 | lm loss: 9.804967E+00 | load_balancing_loss: 1.039294E+00 | loss scale: 1.0 | grad norm: 2.142 | num zeros: 0.0 | params norm: 238.873 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 14:56:07] iteration 35/ 24000 | consumed samples: 35840 | elapsed time per iteration (ms): 263583.5 | throughput per GPU (TFLOP/s/GPU): 41.6 | learning rate: 5.250000E-05 | global batch size: 1024 | lm loss: 9.716209E+00 | load_balancing_loss: 1.039907E+00 | loss scale: 1.0 | grad norm: 2.205 | num zeros: 1.0 | params norm: 238.928 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 15:00:31] iteration 36/ 24000 | consumed samples: 36864 | elapsed time per iteration (ms): 263716.8 | throughput per GPU (TFLOP/s/GPU): 41.6 | learning rate: 5.400000E-05 | global batch size: 1024 | lm loss: 9.629738E+00 | load_balancing_loss: 1.041594E+00 | loss scale: 1.0 | grad norm: 2.289 | num zeros: 0.0 | params norm: 238.986 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 15:04:54] iteration 37/ 24000 | consumed samples: 37888 | elapsed time per iteration (ms): 263006.7 | throughput per GPU (TFLOP/s/GPU): 41.7 | learning rate: 5.550000E-05 | global batch size: 1024 | lm loss: 9.566217E+00 | load_balancing_loss: 1.042442E+00 | loss scale: 1.0 | grad norm: 2.398 | num zeros: 0.0 | params norm: 239.047 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 15:09:17] iteration 38/ 24000 | consumed samples: 38912 | elapsed time per iteration (ms): 262926.5 | throughput per GPU (TFLOP/s/GPU): 41.7 | learning rate: 5.700000E-05 | global batch size: 1024 | lm loss: 9.475837E+00 | load_balancing_loss: 1.043912E+00 | loss scale: 1.0 | grad norm: 2.430 | num zeros: 0.0 | params norm: 239.111 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 15:13:40] iteration 39/ 24000 | consumed samples: 39936 | elapsed time per iteration (ms): 263264.4 | throughput per GPU (TFLOP/s/GPU): 41.7 | learning rate: 5.850000E-05 | global batch size: 1024 | lm loss: 9.383533E+00 | load_balancing_loss: 1.048713E+00 | loss scale: 1.0 | grad norm: 2.290 | num zeros: 0.0 | params norm: 239.179 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 15:18:03] iteration 40/ 24000 | consumed samples: 40960 | elapsed time per iteration (ms): 263157.9 | throughput per GPU (TFLOP/s/GPU): 41.7 | learning rate: 6.000000E-05 | global batch size: 1024 | lm loss: 9.300698E+00 | load_balancing_loss: 1.049337E+00 | loss scale: 1.0 | grad norm: 2.338 | num zeros: 1.0 | params norm: 239.249 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 15:22:26] iteration 41/ 24000 | consumed samples: 41984 | elapsed time per iteration (ms): 263029.2 | throughput per GPU (TFLOP/s/GPU): 41.7 | learning rate: 6.150000E-05 | global batch size: 1024 | lm loss: 9.214035E+00 | load_balancing_loss: 1.049348E+00 | loss scale: 1.0 | grad norm: 2.173 | num zeros: 1.0 | params norm: 239.323 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 15:26:49] iteration 42/ 24000 | consumed samples: 43008 | elapsed time per iteration (ms): 262970.9 | throughput per GPU (TFLOP/s/GPU): 41.7 | learning rate: 6.300000E-05 | global batch size: 1024 | lm loss: 9.111977E+00 | load_balancing_loss: 1.052316E+00 | loss scale: 1.0 | grad norm: 2.166 | num zeros: 0.0 | params norm: 239.401 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 15:31:13] iteration 43/ 24000 | consumed samples: 44032 | elapsed time per iteration (ms): 263657.2 | throughput per GPU (TFLOP/s/GPU): 41.6 | learning rate: 6.450000E-05 | global batch size: 1024 | lm loss: 9.048386E+00 | load_balancing_loss: 1.053344E+00 | loss scale: 1.0 | grad norm: 2.191 | num zeros: 0.0 | params norm: 239.483 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 15:35:35] iteration 44/ 24000 | consumed samples: 45056 | elapsed time per iteration (ms): 262466.2 | throughput per GPU (TFLOP/s/GPU): 41.8 | learning rate: 6.600000E-05 | global batch size: 1024 | lm loss: 8.968973E+00 | load_balancing_loss: 1.054048E+00 | loss scale: 1.0 | grad norm: 2.190 | num zeros: 1.0 | params norm: 239.568 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 15:39:59] iteration 45/ 24000 | consumed samples: 46080 | elapsed time per iteration (ms): 263089.7 | throughput per GPU (TFLOP/s/GPU): 41.7 | learning rate: 6.750000E-05 | global batch size: 1024 | lm loss: 8.847938E+00 | load_balancing_loss: 1.059039E+00 | loss scale: 1.0 | grad norm: 2.177 | num zeros: 39.0 | params norm: 239.657 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 15:44:22] iteration 46/ 24000 | consumed samples: 47104 | elapsed time per iteration (ms): 263084.5 | throughput per GPU (TFLOP/s/GPU): 41.7 | learning rate: 6.900000E-05 | global batch size: 1024 | lm loss: 8.766063E+00 | load_balancing_loss: 1.055782E+00 | loss scale: 1.0 | grad norm: 2.152 | num zeros: 1.0 | params norm: 239.750 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 15:48:46] iteration 47/ 24000 | consumed samples: 48128 | elapsed time per iteration (ms): 263952.4 | throughput per GPU (TFLOP/s/GPU): 41.5 | learning rate: 7.050000E-05 | global batch size: 1024 | lm loss: 8.684135E+00 | load_balancing_loss: 1.057991E+00 | loss scale: 1.0 | grad norm: 2.165 | num zeros: 0.0 | params norm: 239.846 | number of skipped iterations: 0 | number of nan iterations: 0 |
[2025-06-27 15:53:09] iteration 48/ 24000 | consumed samples: 49152 | elapsed time per iteration (ms): 263581.7 | throughput per GPU (TFLOP/s/GPU): 41.6 | learning rate: 7.200000E-05 | global batch size: 1024 | lm loss: 8.595925E+00 | load_balancing_loss: 1.059975E+00 | loss scale: 1.0 | grad norm: 2.102 | num zeros: 0.0 | params norm: 239.948 | number of skipped iterations: 0 | number of nan iterations: 0 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号