【启智社区】【大语言模型原理与实践】1.大语言模型的发展
大语言模型(Large Language Models,LLM)是一种由包含数百亿以上权重的深度神经网络构建的语言模型,使用自监督学习方法通过大量无标记文本进行训练。自2018年以来,包含Google、OpenAI、Meta、百度、华为等公司和研究机构都纷纷发布了包括BERT、GPT等在内多种模型,并在几乎所有自然语言处理任务中都表现出色。2019年开始大模型呈现爆发式的增长,一个比较重要的标志性事件是2021年Open AI发布了包含1750亿参数的生成式大规模预训练语言模型GPT3,正式开启了大语言模型的时代。
尤其是2022年11月ChatGPT发布后,更是引起了全世界的广泛关注,自此掀起了一股人工智能大语言模型的热潮。大语言模型在人机多轮对话、上下文理解、图像理解等各方面的能力表现非常突出,已经非常逼近通用人工智能。用户可以使用自然语言与系统交互,从而实现包括问答、分类、摘要、翻译、聊天等从理解到生成的各种任务,大型语言模型展现出了强大的对世界知识掌握和对语言的理解。
下面是大语言模型发展的一张时间路线图:
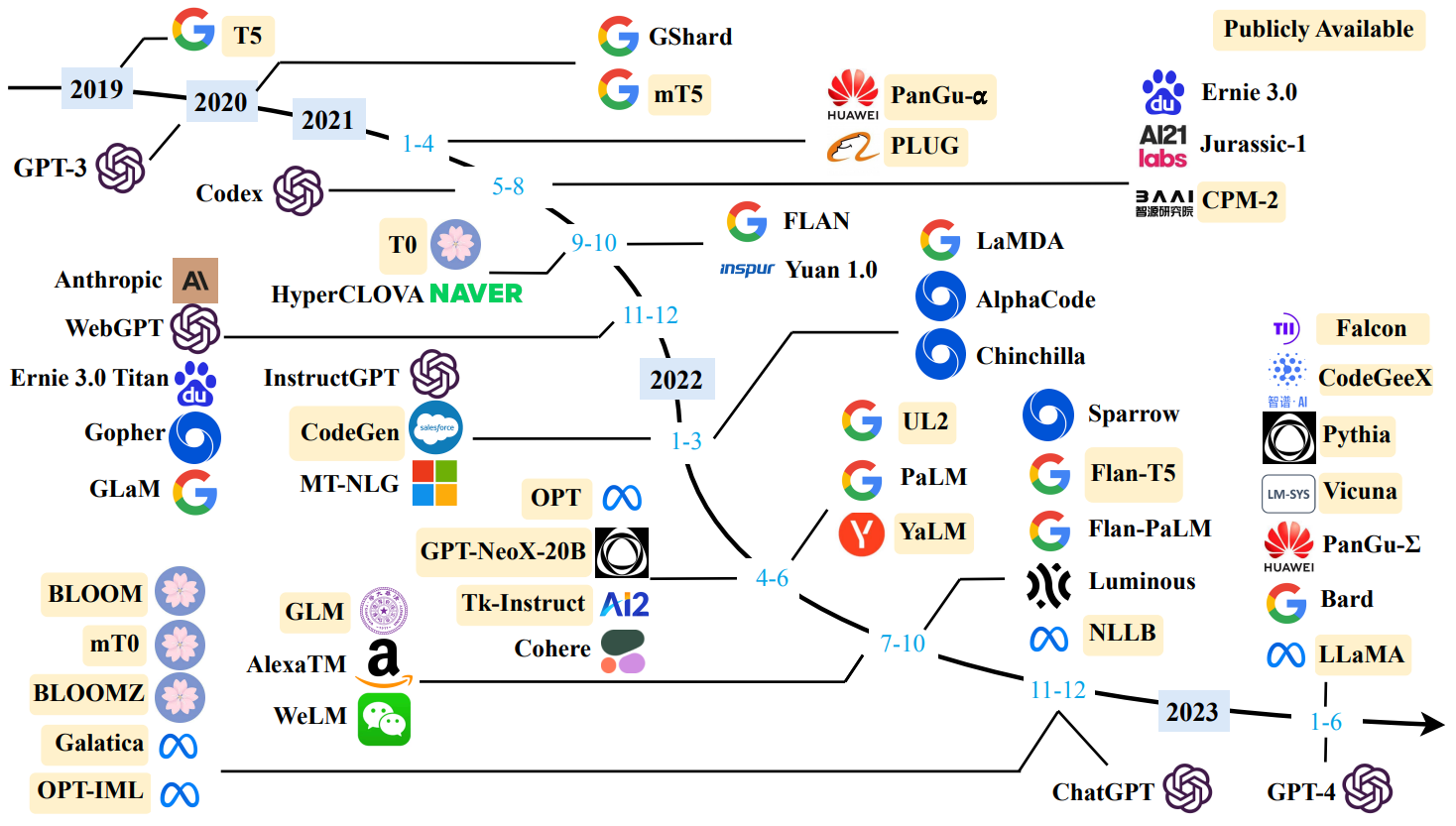
由于大语言模型的参数量巨大,在不同任务上进行微调需要消耗大量的计算资源,预训练微调范式不再适用于大语言模型,因此一些新的技术和方法出现,比如通过上下文语境学习(In-Context Learning)方法,大语言模型可以在很多任务的少样本场景下取得很好的效果,此外提示学习(Prompt Learnig)、模型即服务范式(Model as a Service,MaaS)、指令微调(Instruction Fine-tuning)等方法都在不同任务上都取得了很好的效果。
大语言模型一般需要经过预训练、SFT(Supervised Fine-Tuning)监督微调、奖励模型(Reword Model)训练、PPO强化学习模型训练四个阶段。在预训练阶段模型在大量无标注文本数据上进行训练,学习到语言的基本知识和潜在规律,使模型具有一定程度的通用语言理解能力;在SFT监督微调阶段是通过使用大量的人工标注数据,根据特定任务需求,进一步优化模型的性能;在奖励模型训练阶段是通过为强化学习任务设计奖励函数,引导智能体在学习过程中采取正确的行动,指导模型生成更好的回答;在强化学习阶段,是通过PPO强化学习算法优化模型的策略来提高模型性能。经过预训练、监督微调、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback) 等方式的训练,大语言模型具备了理解人类指令意图的能力,并且能够与人类价值观对齐,生成相当符合人类偏好的回答。
本课程从大语言模型的发展历程,到大语言模型使用的一些技术,再到大语言模型的训练和微调原理进行详细介绍,再结合开源的大语言模型进行综合实践,让大家能够既能学到原理性知识,又能进行大语言模型实践,达到学以致用的目的。
语言模型的发展经历了从传统经典的语言模型(如N-gram、TF-IDF),到基于神经网络的语言模型(如RNN、LSTM),再到预训练的语言模型(如ELMo、GPT、Bert),以及现在百亿级参数以上的大语言模型(如GPT3、GPT3.5、GPT4)几个发展阶段,本章节就这些语言模型的原理进行详细的介绍。
1.1.1 N-gram&TF-IDF
N-gram语言模型是一种常见的统计语言模型。
TF-IDF 算法是一种基于统计的计算方法,常用于评估在一个文档集中一个词对某份文档的重要程度。
本实训重点介绍N-gram和TF-IDF 算法相关知识、实现过程。通过本实训,掌握和运用N-gram和TF-IDF 算法。
N-gram模型
N-Gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。
每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。
该模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。常用的是二元的Bi-Gram和三元的Tri-Gram。
当n=1时,一个一元模型为:
当n=2时,一个二元模型为:
当n=3时,一个三元模型为:
一个 n-gram 是 n 个词的序列:
一个 2-gram(bigram 或二元)是两个词的序列,例如 “I love”;
一个 3-gram(trigram 或三元)是三个词的序列,例如“I love you”。
需要注意的是,通常 n-gram 即表示词序列,也表示预测这个词序列概率的模型。假设给定一个词序列(w1,w2,···,wm),根据概率的链式法则,可得公式(1.1):
P( $ w_ {1} $ , $ w_ {2} $ , $ \cdots $ , $ w_ {m} $ )=P( $ w_ {1} $ )*P( $ w_ {2} $ $ |w_ {1} $ ) $ \cdots $ P( $ w_ {m} $ $ |w_ {1} $ , $ \cdots $ , $ w_ {m-1} $ )=
$ Ⅱ_ {i=1}^ {m} $ P( $ w_ {i} $ $ |w_ {i-2} $ , $ w_ {i-1} $ )
公式(1.1)右边的 \(P(w_i|w_1,w_2,..., w_{i-1})\)表示某个词\(w_i\)在已知句子\(w_1,w_2,..., w_{i-1}\)后面一个词出现的概率
马尔科夫假设
在实践中,如果文本的长度较长时,公式(1.1)右边的\(P(w_i|w_1,w_2,..., w_{i-1})\)的估算会非常困难,因此需要引入马尔科夫假设。
马尔科夫假设是指,每个词出现的概率只跟它前面的少数几个词有关。比如,二阶马尔科夫假设只考虑前面两个词,相应的语言模型是三元(trigram)模型。应用了这个假设表明当前这个词仅仅跟前面几个有限的词有关,因此也就不必追溯到最开始的那个词,这样便可以大幅缩减上述算式的长度。
基于马尔科夫假设,可得公式(1.2):
P( $ w_ {i} $ $ |w_ {1} $ , $ \cdots $ , $ w_ {i-1} $ ) $ \approx $ P( $ w_ {i} $ $ |w_ {i-n+1} $ , $ \cdots $ ,wi-1
当 n = 1时称为一元模型(unigram model),公式(1.2)右边会演变成\(P(w_i)\),此时,整个句子的概率为:
P( $ w_ {1} $ , $ w_ {2} $ , $ \cdots $ , $ w_ {m} $ )=P( $ w_ {1} $ )*P( $ w_ {2} $ ) $ \cdots $ P( $ w_ {m} $ )= $ Ⅱ_ {i=1}^ {m} $ P( $ w_ {i} $ )
当 n = 2时称为二元模型(bigram model),公式(1.2)右边会演变成\(P(w_i|w_{i-1})\),此时,整个句子的概率为:
P( $ w_ {1} $ , $ w_ {2} $ , $ \cdots $ , $ w_ {m} $ )=P( $ w_ {1} $ )*P( $ w_ {2} $ $ |w_ {1} $ ) $ \cdots $ P( $ w_ {m} $ $ |w_ {m-1} $ )= $ Ⅱ_ {i=1}^ {m} $ P( $ w_ {i} $ $ |w_ {i-1} $ )
当 n = 3时称为三元模型(trigram model),公式(1.2)右边会演变成\(P(w_i|w_{i-2}, w_{i-1})\),此时,整个句子的概率为:
P( $ w_ {1} $ , $ w_ {2} $ , $ \cdots $ , $ w_ {m} $ )=P( $ w_ {1} $ )*P( $ w_ {2} $ $ |w_ {1} $ ) $ \cdots $ P( $ w_ {m} $ $ |w_ {m-2} $ , $ \cdots $ , $ w_ {m-1} $ )= $ T_ {i=1}^ {m} $ P( $ w_ {i} $ $ |w_ {i-2} $ , $ w_ {i-1} $ )
估计n-gram模型概率采用极大似然估计(maximum likelihood estimation,MLE)。即通过从语料库中获取计数,并将计数归一化到(0,1),从而得到n-gram模型参数的极大似然估计。即:
P( $ w_ {i} $ $ |w_ {i-n+1} $ , $ \cdots $ , $ w_ {i-1} $ )= $ \frac {count(w_ {i-n+1},\cdots ,w_ {i})}{\sum _ {wiount(wi-n+1},\cdots ,w_ {i-1},w_ {i})} $ = $ \frac {count(w_ {i-n+1},\cdots ,wi)}{count(wi-n+1,\cdots ,wi-1)} $
其中\(count(w_{i-n+1},..., w_i)\)表示文本序列\((w_{i-n+1}, ..., w_i)\),在语料库中出现的次数。
n-gram模型优缺点
总结下基于统计的 n-gram 语言模型的优缺点:
优点:
- 采用极大似然估计,参数易训练;
- 完全包含了前n-1个词的全部信息;
- 可解释性强,直观易理解;
缺点:
- 缺乏长期依赖,只能建模到前n-1个词;
- 随着n的增大,参数空间呈指数增长;
- 数据稀疏,难免会出现OOV词(out of vocabulary)的问题;
- 单纯的基于统计频次,泛化能力差
TF-IDF
TF-IDF(term frequency-inverse document frequency,词频-逆向文件频率) 是一种用于信息检索(information retrieval))与文本挖掘(text mining)的常用加权技术。它是一种统计方法,用以评估一个字或词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
在信息检索(Information Retrieval)、文本挖掘(Text Mining)以及自然语言处理(Natural Language Processing)领域,TF-IDF算法都可以说是鼎鼎有名。虽然在这些领域中,目前也出现了不少以深度学习为基础的新的文本表达和算分(Weighting)方法,但是TF-IDF作为一个最基础的方法,依然在很多应用中发挥着不可替代的作用。
TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF(全称TermFrequency),中文含义词频,即关键词出现在网页当中的频次。
IDF(全称InverseDocumentFrequency),中文含义逆文档频率,即该关键词出现在所有文档里面的一种数据集合。
TF-IDF的计算过程为:
第一步,计算词频。
词频(TF)=文章的总词数某个词在文章中的出现次数
或者
词频(TF)=该文出现次数最多的词出现的次数某个词在文章中的出现次数
第二步,计算逆文档频率。
逆文档频率(IDF)=log(包含该词的文档数+1语料库的文档总数)
如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
第三步,计算TF-IDF。
TF−IDF=词频(TF)×逆文档频率(IDF)
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
TF-IDF算法总结
TF-IDF算法是一种常用的文本特征表示方法,用于评估一个词对于一个文档集或语料库中某个文档的重要程度,常用于以下领域:
(1)搜索引擎;
(2)关键词提取;
(3)文本相似性;
(4)文本摘要。
TF-IDF算法优点:
-
简单有效:TF-IDF算法简单易实现,计算速度快,并且在很多文本相关任务中表现良好。
-
考虑词频和文档频率:TF-IDF综合考虑了词频和文档频率两个因素,可以准确表示词语在文档中的重要性。
-
强调关键词:TF-IDF算法倾向于给予在文档中频繁出现但在整个语料库中较少见的词更高的权重,从而能够突出关键词。
-
适用性广泛:TF-IDF算法可以应用于各种文本相关任务,如信息检索、文本分类、关键词提取等。
TF-IDF算法缺点:
-
无法捕捉语义信息:TF-IDF算法仅根据词频和文档频率进行计算,无法捕捉到词语之间的语义关系,因此在处理一些复杂的语义任务时可能效果有限。
-
忽略词序信息:TF-IDF算法将文本表示为词语的集合,并忽略了词语之间的顺序信息,因此无法捕捉到词语顺序对于文本含义的影响。
-
对文档长度敏感:TF-IDF算法受文档长度的影响较大,较长的文档可能会有较高的词频,从而影响到特征权重的计算结果。
-
词汇表限制:TF-IDF算法需要构建词汇表来对文本进行表示,词汇表的大小会对算法的性能和计算开销产生影响,同时也可能存在未登录词的问题。
-
主题混杂问题:在包含多个主题的文档中,TF-IDF算法可能会给予一些频繁出现的词较高的权重,导致提取的关键词并不完全与文档主题相关。
词频(TF)指的是某个词在一篇文档中出现的次数,但是从计算来看却不符合,计算中除以总数成为比例,再次数而不是次数比例来定义不妥。
在N-gram模型中,N表示每次取出的单词数量。
N-gram模型可以用于文本分类、语音识别和机器翻译等自然语言处理任务。
N-gram模型的主要优点是可以捕捉上下文信息,但缺点是无法处理未知的单词。
在TF-IDF模型中,IDF值越大代表该词对文本内容的区分度越高。
在TF-IDF模型中,词频(TF)指的是某个词在一篇文档中出现的次数。
1.1.2 基于神经网络的语言模型
基于神经网络的语言模型
鉴于n-gram存在的问题,人们开始尝试用神经网络来建立语言模型,提出了如下图所示的前馈神经网络模型(FFNN Language Model,FFNNLM):
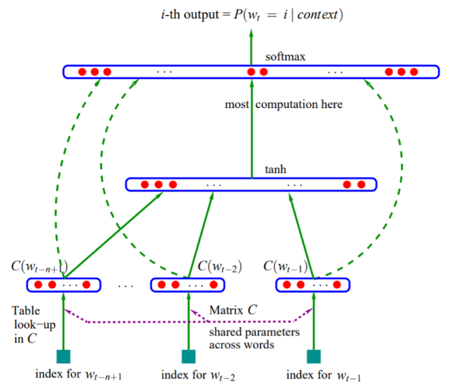
它通过学习词的分布式表示来解决维度灾难,使得一个词能够使用一个低维向量(称之为embedding)表示。从整体上看,上述模型属于比较简单而传统的神经网络模型,主要由输入层-隐藏层-输出层组成,经过前向传播和反向传播来进行训练。
数据预处理
基于神经网络的语言模型的输入层为词向量,词语转化为数字的最简单的形式就是One-hot(独热编码),简单来说就是假设有一个大小为V的固定排序的词表,里边包含V个词,假设第二个词是“电视”,那么用一个维度为V 的特征向量表达就是[0,1,0,0,⋯ ,0],即该词语在词表中的位置对应在特征向量中的位置的值为1,其他位置都为0。
但One-hot编码有一个最大的问题就是数据稀疏问题,当词表很大(比如现在有一个含80000个词的词表)时,数据稀疏会让整个计算量都变得很大,且词语之间的关联关系得不到表达。
词向量(Word Embedding)因此应运而生,它不用One-hot的稀疏向量来表征这个词,而是用一个低维度的向量来表征这个词,给定一个词表征的矩阵C,矩阵C的维度是V∗m,即V行,m列。V是词表的大小,即每一行代表了词表里的一个词;m是自己定的词向量的维度,比如说对于一个80000个词的词表,One-hot向量要用80000维来表征“电视”这个词,而词向量用一个100维的向量来表征,m就是100。
用“电视”的One-hot向量[0,1,0,0,⋯,0]乘上面说的矩阵C,将得到一个m维的向量,即词向量,下图为这个计算过程:

得到上面单个词向量之后,将n − 1个词向量做一个全连接,即把这n − 1个词向量首尾相接地拼起来得到最终的输入x:
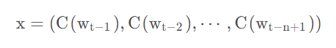
正向传播
从输入层到隐藏层:词向量x作为输入,权重H乘以输入加上偏置d,再加tanh函数作激活函数,就得到了隐藏层:tanh(d+Hx)。
从隐藏层到输出层:先计算由隐藏层到输出层未归一化的输出值y1,这里是一个简单的线性变化:y1 = Utanh(d+Hx)+b1。这里的U是隐藏层到输出层的参数,b1代表这一部分的偏置项。
从输入层到输出层:从输入层到输出层的直连,也是一个线性变换。这一部分的输出值y2可以表示为: y2=Wx+b2。W和b2分别是这一部分的权重和偏置项。
输出层:由上面的两部分输出值可以得到最终的y:y = y1+y2 = b+Wx+Utanh(d+Hx)
再将y经过一个softmax函数做概率归一化,便能得到一个维度为V的概率向量。
模型训练的目标是最大化以下似然函数:

其中θ=(b,d,W,U,H,C),是模型的所有参数,R是正则化项。
反向传播是根据loss值更新参数的过程,这里不再赘述。
模型评价
神经网络语言模型(NNLM)通过构建神经网络的方式来探索和建模自然语言内在的依赖关系。优缺点如下:
优点:
- 词向量是可以自定义维度的,维度并不会因为新扩展词而发生改变,词向量能够很好的根据特征距离度量词与词之间的相似性;
- 好的词向量能够提高模型泛化能力;
- 相比于n-gram,通过词向量的降维,减小了参数空间,减少了计算量。
缺点:
- 参数较多,模型训练时间长;
- 可解释性较差。
循环神经网络概述
对于我们已经学过的传统神经网络,它们能够实现分类以及标注任务,但传统神经网络处理具有前后遗存关系的数据时,效果就不是十分理想了。这时不仅需要依赖当前的输入,还需要结合前一时刻或后一时刻的输入作为参考。
循环神经网络的主要用途是处理和预测序列数据。循环神经网络最初就是为了刻画一个序列当前的输出与之前信息的关系。从网络结构上来看,循环神经网络会记忆之前的信息,并利用之前的信息影响后面节点的输出。也就是说,循环神经网络的隐藏层之间的节点是有连接的,隐藏层的输入不仅包含输入层的输出,还包括上一时刻隐藏层的输出。
一般循环神经网络
传统的神经网络结构一般分为三层:输入层、隐藏层、输出层。输入层的输入经过加权计算输出到隐藏层,作为隐藏层的输入。隐藏层再对从输入层得到的输入进行加权计算输入到输出层,最后通过激活函数,由输出层输出最终的结果。
循环神经网络的结构与其十分的相似,都是由输入层、隐藏层和输出层构成,最大的区别在于循环神经网络的隐藏层多了一个自身到自身的环形连接,其结构如下图所示:
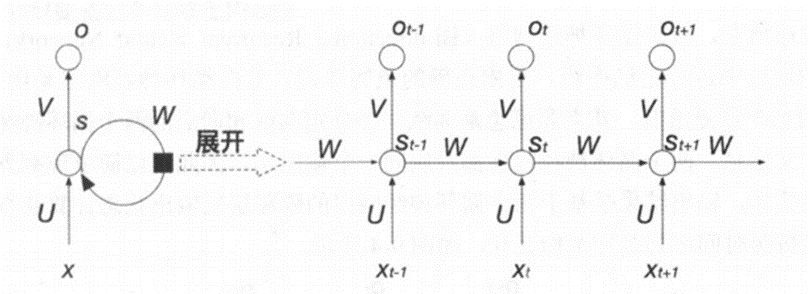
其中,x表示输入层,s表示隐藏层的输出,o表示输出层的值。U是输入x特征与隐藏层神经元全连接的权重矩阵,V则是隐藏层与输出层全连接的权值矩阵。o的输出由权值矩阵V和隐藏层输出s决定。s的输出不仅仅由权值矩阵U以及输入x来决定,还要依赖于新的权值矩阵W以及上一次s的输出。其中,W表示上一次隐藏层的输出到这一次隐藏层输入的权值矩阵,该层被称为循环层。
单向循环神经网络
将一般循环神经如下图所示展开便是单向循环神经网络:

对于单向循环神经网络的结构,你可以理解为网络的输入通过时间进行向后传播。当前隐藏层的输出st除了取决于当前的输入层的输入向量xt外,还受到上一时刻隐藏层的输出向量st+1的影响,因此,当前时刻隐藏层的输出信息包含了之前时刻的信息,表现出对之前信息记忆的能力。可以采用如下公式对单向循环神经网络进行表示:
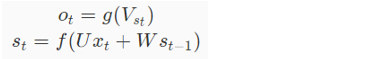
其中ot表示输出层的结果,g为输出层的激活函数,V为输出层的权值矩阵。st表示隐藏层的结果,它由当前时刻的输入层输入xt以及上一时刻隐藏层输出st−1共同决定,U表示输入层到隐藏层的权值矩阵,W为上一时刻的值st−1到这一次输入的权值矩阵,f为隐藏层的激活函数。循环神经网络的递归数学式如下所示:
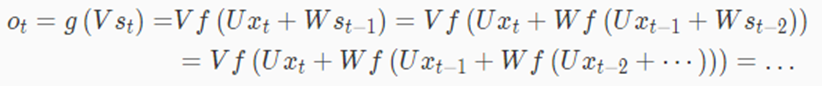
基于循环神经网络的字符级语言模型
接下来,我们看一下如何使用循环神经网络来构建语言模型。 设小批量大小为1,批量中的文本序列为“machine”。为了简化后续部分的训练,我们考虑使用字符级语言模型(character-level language model), 将文本词元化为字符而不是单词。下图演示了如何通过基于字符级语言建模的循环神经网络,使用当前的和先前的字符预测下一个字符。
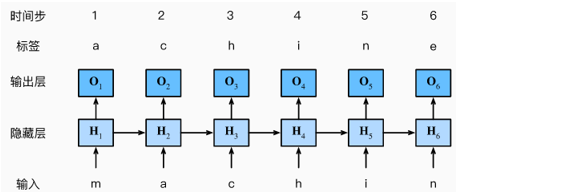
在训练过程中,对每个时间步的输出层的输出进行softmax操作,然后利用交叉熵损失计算模型输出和标签之间的误差。由于隐藏层中隐状态的循环计算上图中的第3个时间步的输出O3由文本序列“m”,“a”和“c”确定。由于训练数据中这个文本序列的下一个字符是“h”,因此第3个时间步的损失将取决于下一个字符的概率分布,而下一个字符是基于特征序列“m”,“a”,“c”和这个时间步的标签“h”生成的。
模型评价
RNN的优点:
- 能够记忆上一时间的输入信息。
- 处理任意长度的输入。
- 模型形状不随输入长度增加改变形状。
- 权重随时间共享
RNN的缺点:
- 计算速度慢。
- 难以获取很久以前的信息。
- 无法考虑当前状态的任何未来输入。
- 在RNN中经常遇到梯度消失和爆炸现象。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号