Transformers in Vision
Transformers in Vision
介绍
最初引入现在著名的Attention is all you need 1,Transformer 多年来一直主导着自然语言处理 (NLP) 领域。特别值得注意的是基于 Transformer 的模型的扩展,例如BERT 2、MegatronLM 3、T5 4和各种 GPT(GPT 5、GPT-2 6和GPT-3 7),因为它们具有良好的扩展性特征8、9。
Transformers 在 NLP 中的成功在其他领域也没有被忽视,他们在蛋白质折叠领域取得了重大突破,例如AlphaFold 2。
使transformers(和自我注意)适应视觉的重要工作包括注意增强卷积网络10、独立自我注意模型11(SASA 模型)、DETR 12、视觉transformers13和LambdaNetworks 14;以及生成域中的Image Transformers 15和Axial Transformers 16。
对于这些作品的深入介绍,我们推荐最近的两篇评论:视觉transformers调查17和视觉transformers:调查18。
概述
这篇博文旨在总结最近将transformers和自注意力应用于视觉的研究,重点是(但范围不限于)图像分类。虽然绝非详尽无遗,但它有望成为更深入研究文献的起点。
我们首先介绍 Vision Transformer,这是一种简单而强大的架构,由于其在大数据体系中的性能,它对最近的研究产生了重大影响。然后,我们继续进行许多工作,研究如何在数据不丰富时使用转换器(和自注意力)实现类似的高性能。最后,我们讨论了研究这些模型对扰动的鲁棒性以及它们在自我监督、医学和视频任务中的表现的论文。
图片取自各自的论文,除非标题中明确提供了来源。
在我们开始之前,值得注意的是,建议熟悉transformers和自注意力;大量资源包括 Jay Alammar 的Illustrated Transformer和 Peter Bloem从头开始的transformers。有关本文中讨论的许多模型的高质量实现,请查看 Ross Wightman 的PyTorch 图像模型以及Phil Wang 的工作。
用于图像识别的视觉转换器
一幅图像相当于16x16个单词: 视觉转换器
首次在An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale 19中首次介绍,Vision Transformers (ViTs) 席卷了计算机视觉,在几个月内获得了数百次引用。这篇论文的主要目标是展示一个普通的 Transformer,一旦适应了处理来自视觉领域的数据,就可以与迄今为止开发的一些性能最高的卷积神经网络 (CNN) 竞争。
Vision Transformer 架构在概念上很简单:将图像分成块,展平并将它们投影到DD维嵌入空间获得所谓的补丁嵌入,添加位置嵌入(一组可学习的向量允许模型保留位置信息)并连接一个(可学习的)类标记,然后让 Transformer 编码器发挥作用。最后,将分类头应用于类标记以获得模型的 logits。

图 1:对图像进行分类的视觉转换器。资源。
在 ImageNet 上训练时模型的性能是可以接受的(1M 图像),在 ImageNet-21k 上进行预训练时效果很好(14M 图像),以及在 Google 的内部 JFT-300M 数据集(300M 图像)。
显着的性能改进是由于减少了 Vision Transformers 特有的感应偏差。通过减少对数据的假设,Vision Transformers 可以更好地适应给定的任务。然而,这种能力是有代价的——当样本量太小(例如在 ImageNet 的情况下)时,模型会过拟合,从而导致性能下降。
许多后续论文的目标是匹配(并超越)“小”数据体系中最佳卷积模型的性能——ImageNet(毕竟超过一百万张图像)及以下。
更强的数据增强允许更有效的学习
《Training data-efficient image transformers & distillation through attention》是第一篇表明基于 ViT 的模型可以在 ImageNet 上具有竞争力的论文,而无需访问额外的数据。
这篇论文有两个主要贡献:
-
一种新颖的训练配方(以下称为 DeiT 配方),其特点是更大量的数据增强和随机深度21。这些变化引入了额外的正则化,限制了 ViT 在小数据机制中过度拟合的趋势,从而提高了其性能。作者推荐使用 Rand-Augment 22、Mixup 23、CutMix 24和 Random Erasing 25;他们还建议不要使用 DropOut 26。
-
硬标签蒸馏。在这种方法中,一个额外的可学习标记,称为蒸馏标记,被连接到补丁嵌入。然后用损失函数训练模型
\(\mathcal{L}_{CE}\)是交叉熵损失函数,\(\sigma\)是softmax函数,\(Z_{cls}\)和\(Z_{distill}\)是是分别从类和蒸馏标记派生的学生模型的 logits。\(y_{true}\)和\(y_{teacher}\)分别是真实的和老师的硬标签。
这种蒸馏技术允许模型学习,即使多个强数据增强的组合导致提供的标签不精确,因为教师网络将产生最可能的标签。有趣的是,作者发现 CNN 是比其他 Vision Transformer 更好的教师网络。
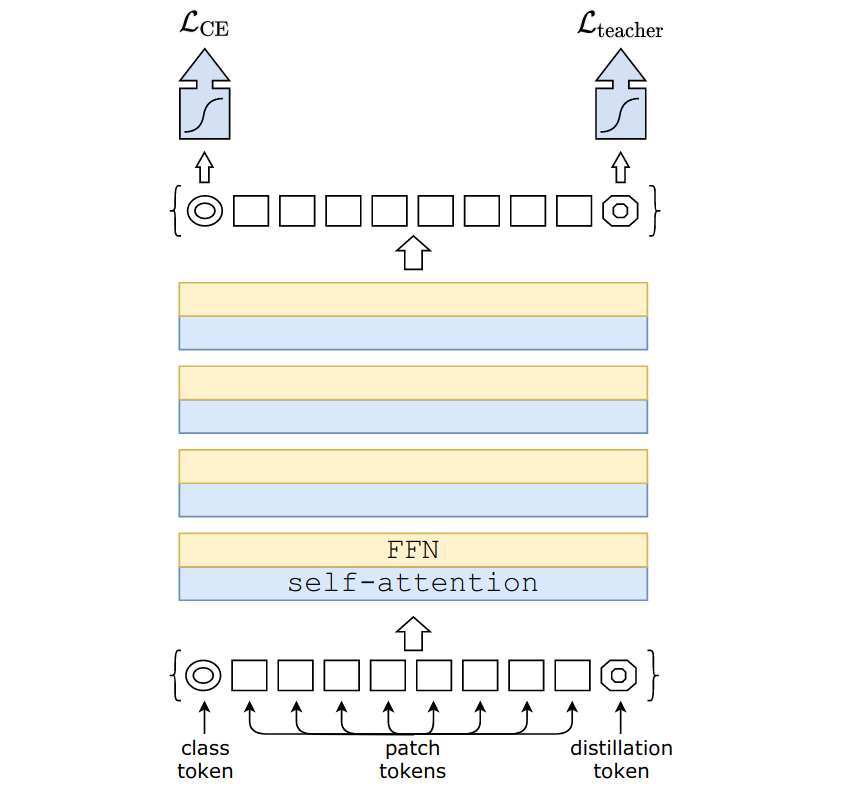
图 2:数据高效图像 Transformer 硬标签蒸馏过程。
由此产生的模型,称为数据高效图像转换器 (DeiTs),在精度/步长时间权衡方面与 EfficientNet 具有竞争力,证明即使在 ImageNet 数据体系中,基于 ViT 的模型也可以与高性能 CNN 竞争。然而值得注意的是,在准确度/参数和准确度/FLOPs 方面,DeiTs 的表现比EfficientNets 27差得多。
在 ResNet 设计中结合相对自注意力
Bottleneck Transformers for Visual Recognition 28研究了通过在 ResNet 设计中结合多头自我注意 (MHSA) 获得的一系列混合卷积和注意模型。特别是,作者表明,通过简单地替换3 × 3在 ResNet 的最后阶段的瓶颈块中使用相对位置 MHSA 层进行卷积,有可能在几个基线上获得改进。
一旦添加了额外的花里胡哨,例如Squeeze-and-Excite 层29和SiLU 非线性30,这些模型(作者称之为瓶颈transformers网络或 BoTNets)展示了良好的扩展性,在准确性/步长上优于 EfficientNets - 超过 83% 的 top-1 准确度的时间权衡。小型 BoTNet 模型的性能较差可能是由于作者没有使用 DeiT 训练方法来对抗过度拟合。
此外,在初始阶段使用 ResNet 块来有效地学习较低分辨率的特征图,使模型在实例分割和对象检测任务中表现良好,其中高分辨率图像是典型的。
条件位置编码
Vision Transformers 的条件位置编码31研究了 ViT 中使用的位置嵌入和类标记的替代方案。特别是,本文提出使用位置编码生成器 (PEG),这是一个动态生成位置编码的模块,以及使用全局平均池作为(非平移不变)类标记的替代方案。
PEG 将扁平化的输入序列重塑为 2D,应用一系列具有零填充的卷积层(作者使用深度可分离卷积),并将结果扁平化。因此,位置信息是由零填充的存在引入的,这与 ViT 不同,其中使用 1D 可学习位置嵌入。该方法有两个主要优点:
- 该模型现在是平移不变的。
- 该模型现在可以按原样用于更高的分辨率,这与需要在微调之前重新调整位置嵌入的普通 ViT 不同。
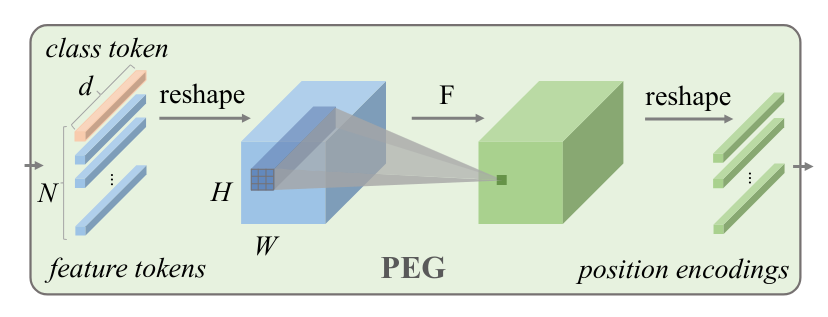
图 3:位置编码生成器 (PEG) 模块架构。
由此产生的模型,称为条件位置编码视觉转换器 (CPVT),使用 DeiT 配方进行训练,并在性能上获得小幅提升(特别是在未经微调的更高分辨率图像上进行测试时)。
建模局部补丁结构
Transformer 32 (TNT) 中的 Transformer 通过在 ViT 中使用的转换器块内引入一个专用于像素嵌入的附加转换器块来研究块内结构的重要性。
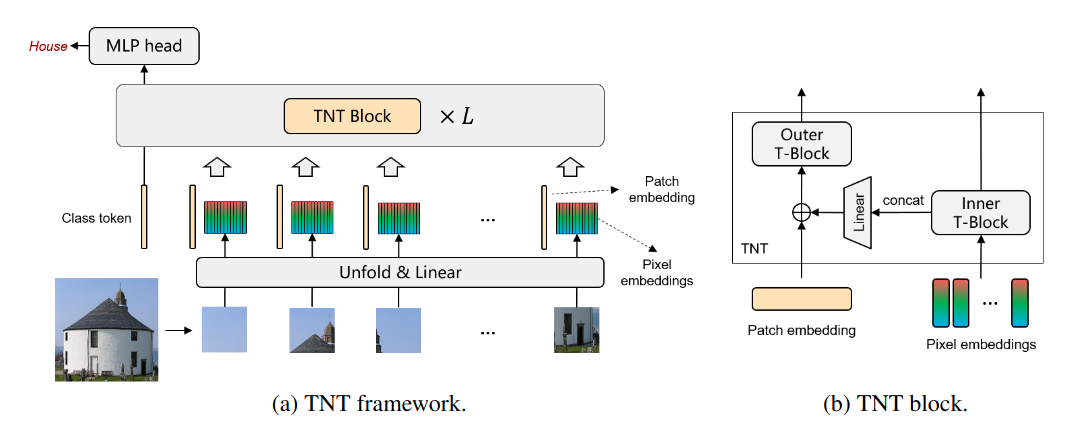
图 4:Transformer in Transformer (TNT) 架构。
内部转换器块的输出既按原样发送到下一层,也适用于外部转换器块,现在可以考虑补丁间关系(如 ViT 所做的那样)和补丁内结构。作者还引入了一组单独的位置嵌入,在进入编码器之前添加到像素嵌入中。
使用 DeiT 配方训练的模型在 ImageNet 上的表现优于 ViT 和 DeiT,实现了更高的参数和 FLOP 效率,尽管不如 EfficientNet 高。
Vision Transformers 越来越深入
DeepViT:迈向更深的视觉 Transformer 33研究了 ViT 的性能如何随着深度的增加而变化。在 24 个转换器块之后,作者发现添加额外的块并没有提高性能,因为特征图和注意矩阵最终彼此非常相似,他们将这个问题命名为 Attention Collapse。
为了解决这个问题,作者提出了一种简单的 self-attention 变体,他们称之为 Re-Attention,其特征是一个可学习的变换矩阵\(\Theta \in R^{H \times H}\)(H在 softmax 之后直接应用的注意力头的数量。该矩阵(在整个网络中共享,但也可以是特定于层的)允许模型建立交叉头通信,从而减少层间特征图的相似性。
作者还报告了采用类似于LazyFormer 34中提出的方法的积极结果:在网络的后半部分重用注意力矩阵不会导致性能下降。
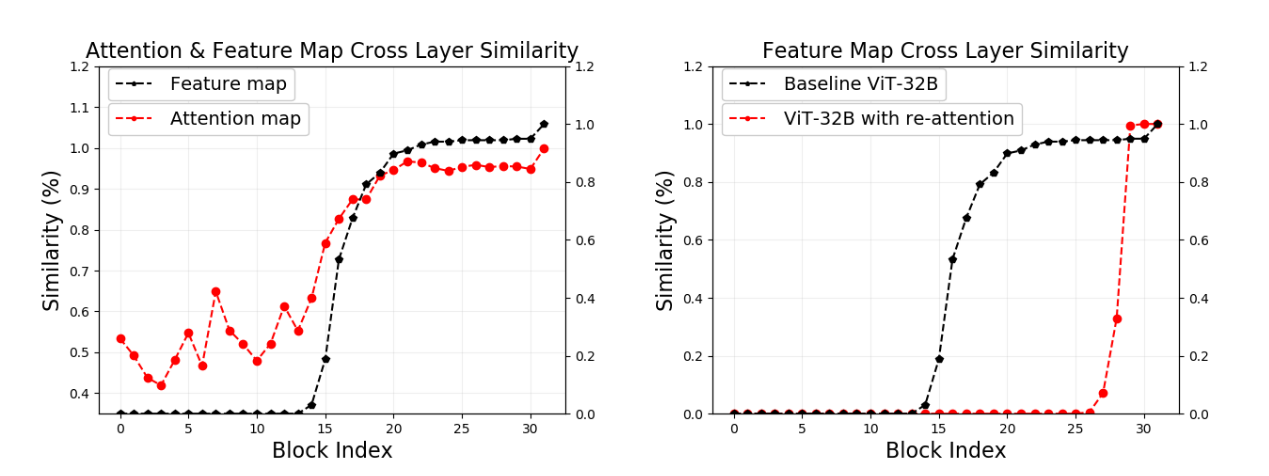
图 5:注意力和特征图跨层相似度(左);ViT 和 DeepViT 比较(右)。
由此产生的模型称为深度视觉转换器 (DeepViTs),其特点是随着深度的增加性能更好。
深入了解 Image Transformers 35发现了 DeiT 模型中的两个主要问题:在增加的网络深度下缺乏性能改进(甚至性能下降),以及transformers编码器的双重目标,它必须对两个补丁之间的关系进行建模就像类令牌和补丁嵌入之间的那样。为了证明后者,作者展示了稍后在网络中插入类令牌的 DeiT 优于正常的 DeiT。
这篇论文有两个主要贡献:
- LayerScale,一种应用于残差分支的新型归一化策略。
- 类注意层,专门用于从处理的补丁嵌入中有效提取与分类任务相关的信息的层。
LayerScale 的特点是一组特定于层的可学习对角矩阵,其对角线值被初始化为一个小的ε,应用于每个残差分支的输出。它在概念上类似于FixUp 36和SkipInit 37等方法,但为模型提供了更大的自由度,因为它是按通道的(与其他仅使用单个标量的方法不同)。
如前所述,Class-attention 层允许从处理过的补丁嵌入中有效地提取信息。作者发现它比简单的后期插入类令牌和全局平均池化更好,以更低的计算成本实现相同的准确性。
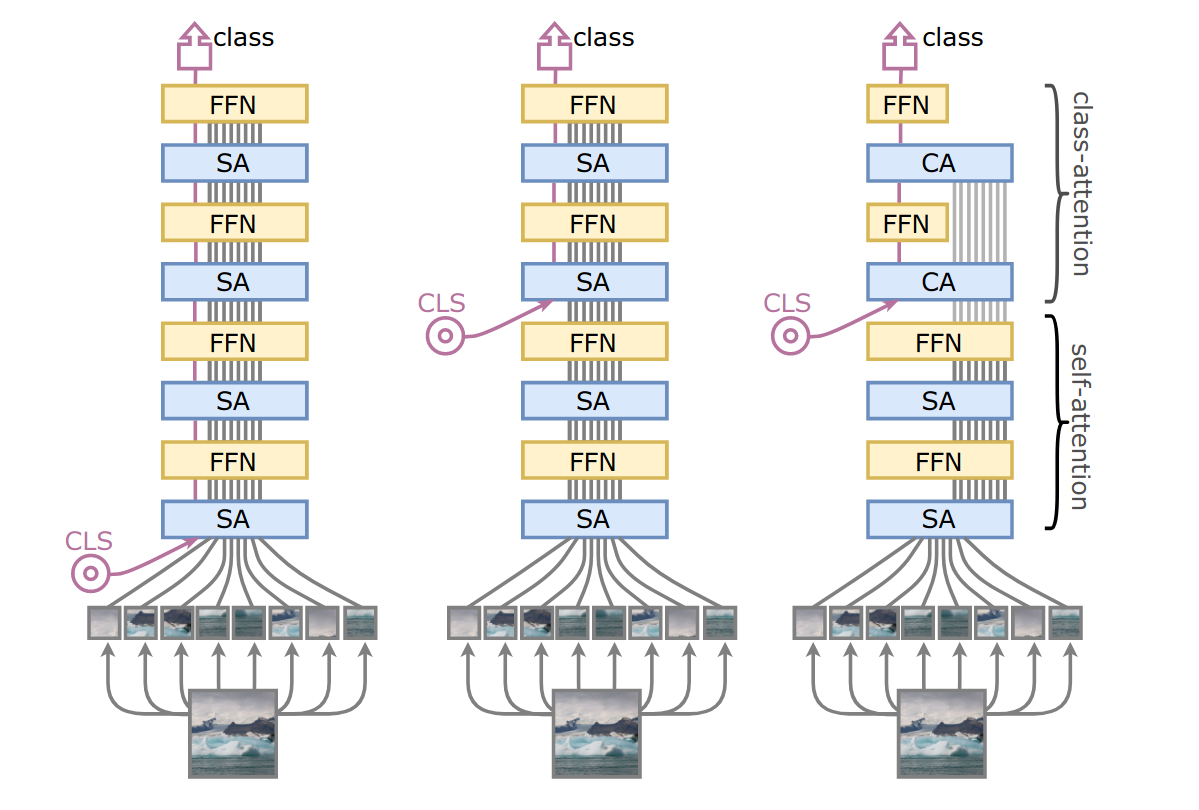
作者还建议使用额外的技巧,例如Talking Heads Attention 38。
由此产生的模型,称为类注意力图像转换器 (CaiTs),在 ImageNet 基准测试中取得了显着的性能。当同时使用 DeiT 训练配方和 DeiT 蒸馏技术时,CaiTs 甚至在准确度/参数权衡和准确度/FLOPs 权衡方面都优于最近的NFNets 39 。
卷积洞察
ConViT:使用软卷积归纳偏置改进视觉transformers40研究了使用软卷积偏置初始化自注意力块的令人兴奋的可能性。基于他们关于自注意力和卷积层之间的理论关系的研究41,作者介绍了门控位置自注意力 (GPSA),这是自注意力的一种变体,其特点是可能被局部偏差初始化。
更准确地说,GPSA 块的初始化由特定于头部的注意力中心(头部最关注的位置,给定查询补丁)和局部强度(确定每个头部在其周围的聚焦程度)参数化。关注的焦点)。GPSA 模块还采用门控机制来更好地平衡内容和位置信息。通过适当地设置 GPSA 块的关注中心和局部强度,该模型可以在低数据区域与 CNN 竞争,同时在大数据区域具有类似 ViT 的表达能力。
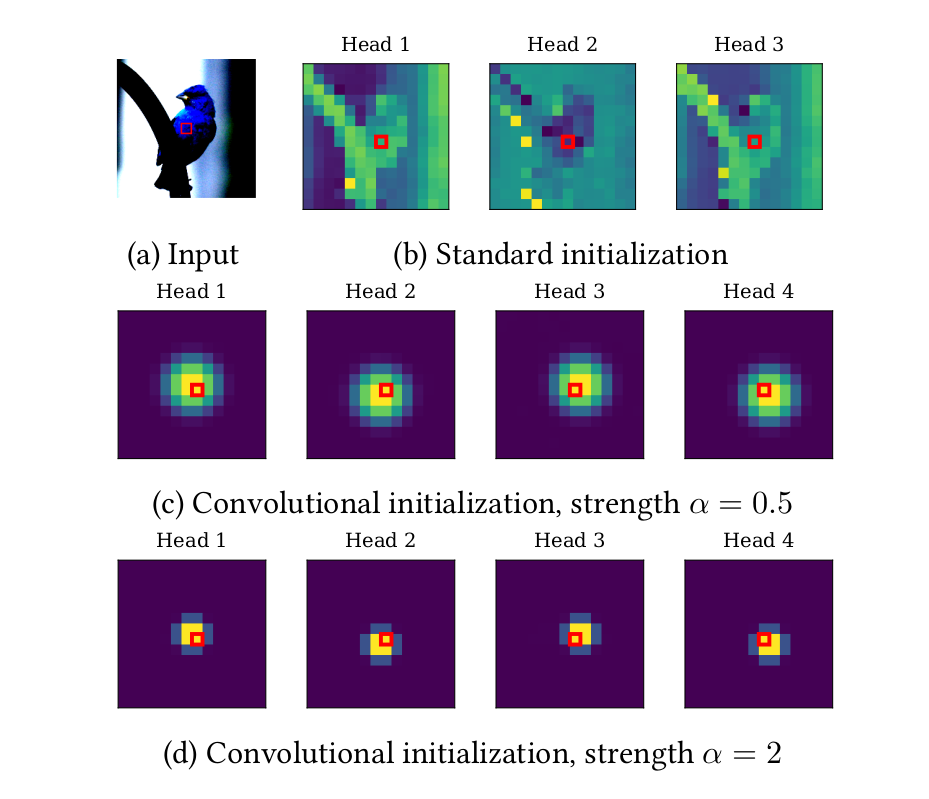
图 7:输入图像(左上)、未经训练的 SA 块(右上)和 GPSA 块(中心和底部)的注意力图。
者通过一项将 DeiT 与最终模型进行比较的实证研究证明了这种优雅方法的有效性,他们将其命名为 Convolutional Vision Transformers (ConViTs):在 ImageNet 上,随着样本量的减少,ConViT 的性能逐渐优越,同时保持了类似 DeiT 的性能全样本量。
另外两篇探讨卷积洞察在视觉转换器中的应用的论文是Incorporating Convolution Designs into Visual Transformers 42和LocalViT:为视觉转换器带来局部性43。
第一篇论文有三个主要贡献:
- Image-to-Tokens (I2T) 词干,替代了 ViT 的卷积词干,其特点是添加了一个最大池操作,然后是批量标准化。
- 局部增强的前馈块,替代 ViT 的前馈块,其特点是使用深度卷积和批量归一化。
- Layer-wise Class-Token Attention,应用于网络末端,单向关注整个网络中的所有类令牌。
作者采用了 DeiT 训练方法;他们的模型称为卷积增强图像变换器 (CeiTs),与相同大小的 DeiT 模型和相同大小的蒸馏 DeiT 模型相比,都获得了优异的结果。
第二篇论文还研究了深度卷积在前馈网络中的应用,同时消融了不同激活函数的使用以及 Squeeze-and-Excite 层的应用。
作者将这种方法应用于几个模型,获得了良好的结果。
层次结构的重要性
几篇论文研究了层次结构在视觉转换器中的应用。
Tokens-to-Token ViT:Training Vision Transformers from Scratch on ImageNet 44引入了 Token-to-Token 模块 (T2T),该模块将输入序列重塑为 2D 结构,应用软分割(允许重叠补丁),以及使生成的补丁变平。通过调整模块中使用的补丁大小,令牌序列的长度在整个网络中逐渐减小。
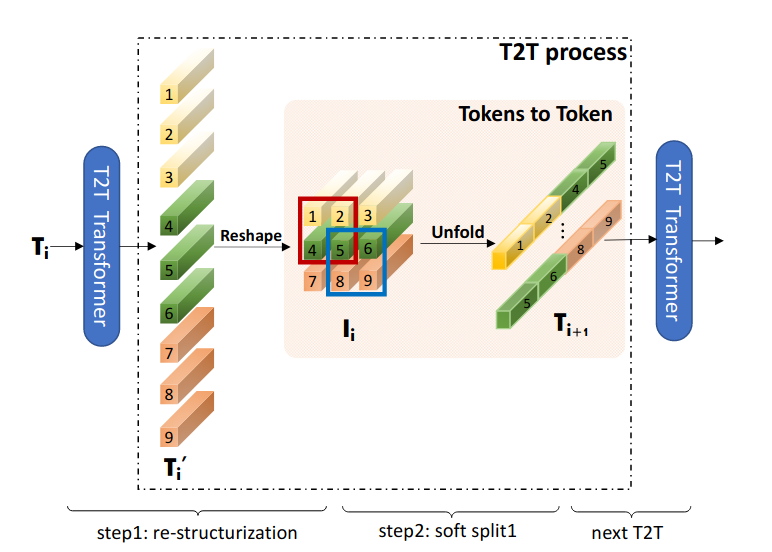
图 8:Token-to-Token 模块架构。
作者获得了良好的结果,其性能与MobileNets 45相当。
Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions 46引入了一种自注意力的变体,称为空间缩减注意力 (SRA),其特点是键和值的空间缩减。通过在几个阶段结束时应用 SRA,特征图的空间维度在整个模型中缓慢减小。由此产生的模型称为 Pyramid Vision Transformers (PVT),可以处理各种任务,包括密集预测、对象检测和语义分割,其中高分辨率图像是典型的。
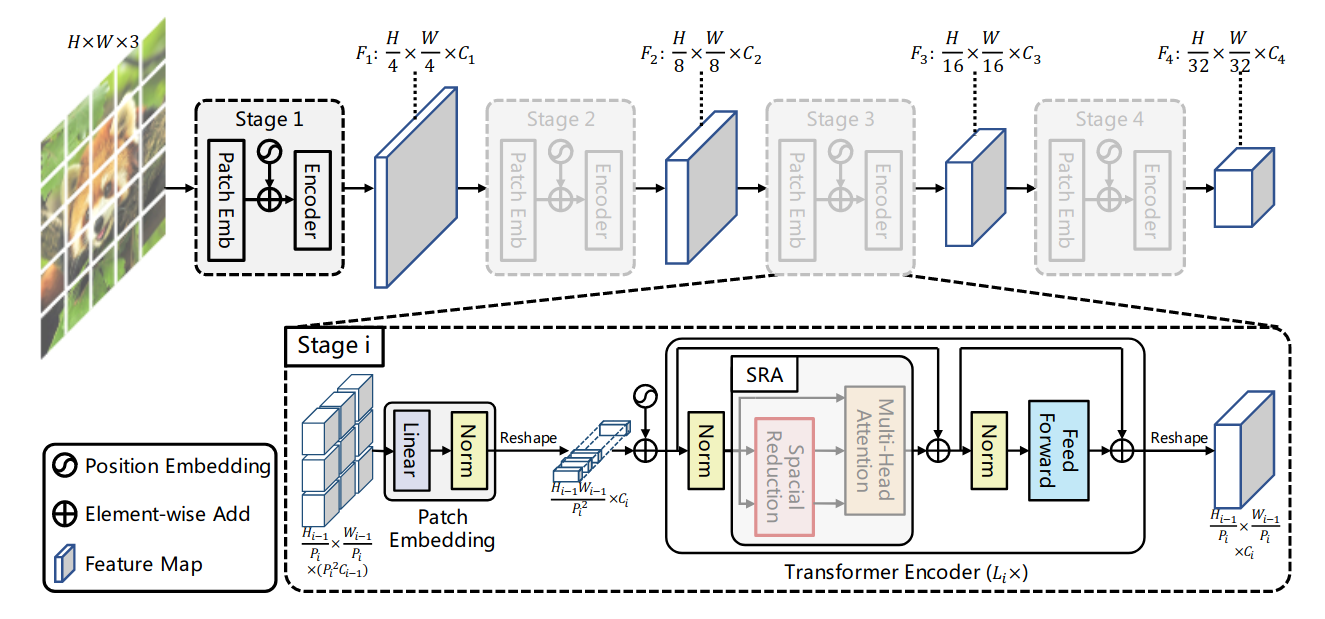
图 9:金字塔视觉转换器。
具有分层池的可扩展视觉转换器47探索了使用最大池来逐步减少序列长度。作者还将 ViT 中使用的类令牌替换为最终的全局平均池化层。由此产生的模型,称为分层视觉转换器 (HVT),使用 DeiT 配方进行训练并按比例放大(在嵌入维度和头数上)以具有与 DeiT 相当的计算成本,在低(子55) GFLOPs 制度。
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows 48提出了一条不同的路线:在(非重叠,本地)窗口内使用本地自注意力,通过所谓的移位窗口分区允许跨窗口通信,并通过渐进式生成分层表示合并窗口本身。
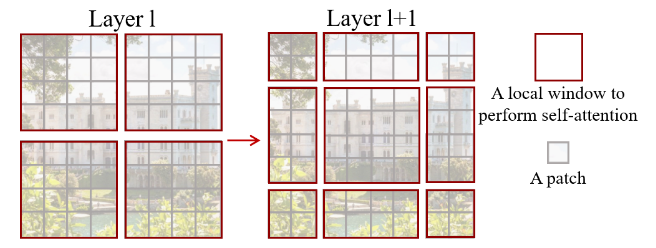
图 11:Swin Transformer(左)和 ViT(右)。注意应用于窗口(红色)内的补丁(黑色)。
在网络的最后阶段,所有局部窗口都已合并,从而在空间维度已显着减小的特征图上有效地使用全局自注意力来生成块。值得注意的是,这种方法随图像大小线性缩放。
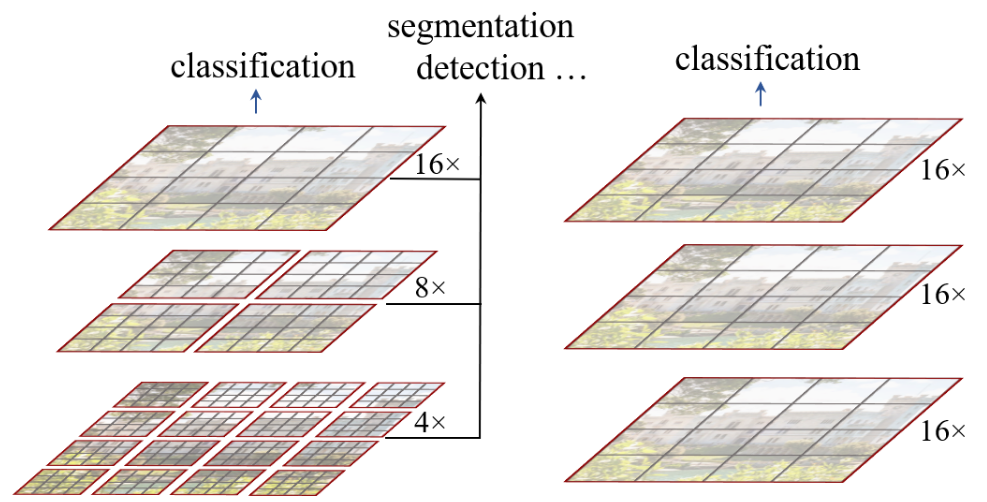
图 11:Swin Transformer(左)和 ViT(右)。注意应用于窗口(红色)内的补丁(黑色)。
作者还报告了在注意力块中应用 T5 式相对位置偏差的积极结果,并在 ImageNet 和 ImageNet-21k 以及对象检测和语义分割任务中获得了有希望的结果。
Rethinking Spatial Dimensions of Vision Transformers 49引入了一种新颖的池化层,其特点是深度卷积(用于补丁嵌入)和全连接层(用于类标记)。这一简单的改变使得名为基于池化的视觉转换器 (PiT) 的模型在 ImageNet 数据体系中的表现优于普通视觉转换器。
LeViT: a Vision Transformer in ConvNet's Clothing for Faster Inference 50研究了一种混合架构,其特征是更长的卷积茎和缩小的注意力块,逐渐减少整个网络中特征图的空间维度。作者还提出使用全局平均池而不是类标记,通过注意力偏差注入位置信息,以及在注意力块中添加GELU 激活51
作者将模型命名为 LeViTs,使用 DeiT 训练配方和 DeiT 蒸馏程序对其进行训练,并表明该网络能够进行高速推理,在精度/步长权衡方面优于 EfficientNets 和 DeiTs。 GPU和CPU。
多尺度特征和交叉注意
CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification 52通过将 Vision Transformer 适配成两个分支,提出了使用多尺度特征:
- 一个大的(或主要的),以大补丁大小、深transformers编码器和宽嵌入维度为特征。
- 一种小的(或互补的),其特征是更小的补丁大小、更浅的编码器和更窄的嵌入维度。
分支使用两个单独的类标记。在网络的后期(在添加了一组单独的位置嵌入之后),通过使用 Cross-Attention Fusion 块建立跨分支通信。
特别是,在交叉注意力融合块内,类标记被连接到另一个分支的补丁嵌入,并在返回到它们各自的分支之前通过注意力进行处理。
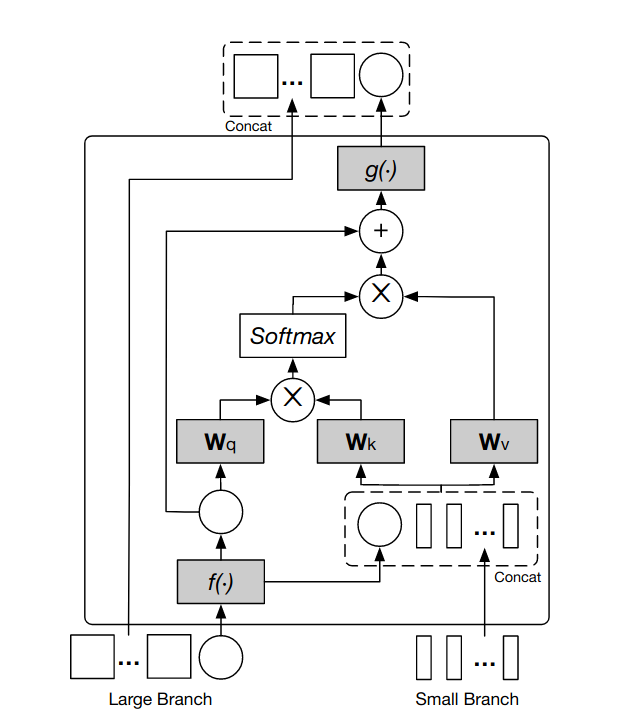
图 12:大分支的交叉注意力融合层。
然后将基于大小分支标记的 MLP 头的输出加在一起以生成模型的 logits。
由此产生的模型,作者命名为 CrossViTs,使用 DeiT 配方进行训练,并享受显着的性能提升,实现比 DeiT 更好的性能两倍,计算成本高出两倍。
在注意力中集成卷积
CvT: Introducing Convolutions to Vision Transformers 53可以被看作是对瓶颈变换器的补充方法,在 CNN 的最终块中不是使用多头自注意力,而是在内部使用卷积(在这种情况下,深度可分离的54) Vision Transformer 的自注意力模块。更准确地说,卷积视觉 Transformers(CvTs,其全名与 ConViTs 冲突)具有两个主要特征:
- Convolutional Token Embedding,一个以跨步卷积为特征的模块,并在每个阶段的开头插入。
- 注意块中的卷积投影。这些通过深度可分离卷积实现的投影允许查询、键和值受到相邻标记的影响。此外,键和值的较大步幅会减少令牌的空间维度,从而减少相关的参数数量和计算成本。
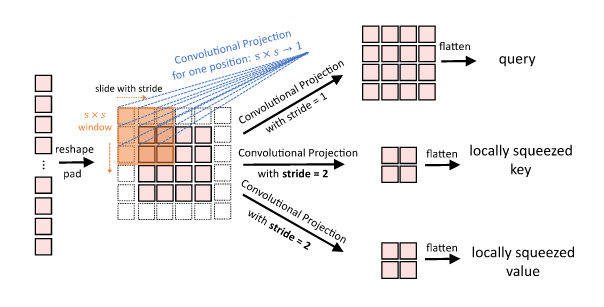
图 13:(跨步)卷积投影。
这两个特征允许模型逐步减少标记特征和空间维度,允许 CvT 采用分层多阶段架构。
值得注意的是,CvT 不使用位置嵌入,因为位置信息是通过在嵌入层和注意块中使用卷积来保留的。
作者在 ImageNet 上训练 CvT 时采用了原始的 ViT 训练配方并取得了具有竞争力的表现。提出的最大模型(CvT-W24),一旦在 ImageNet-21k 上进行预训练,就获得了惊人的87.7 %top-1 准确度,优于 BiT-L(在20倍多的数据) 与一小部分参数和计算。
Multi-Scale Vision Longformer: A New Vision Transformer for High-Resolution Image Encoding 55引入了Longformer 56的 2D 版本,作者称之为 Vision Longformer。从概念上讲,它的特点是两组不同的令牌:一组全局令牌,允许关注所有令牌,以及本地令牌,只允许关注全局令牌和空间上靠近它们的令牌。
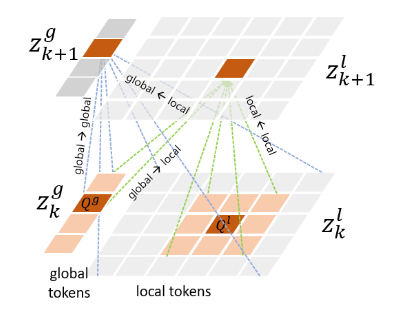
图 14:Multi-Scale Vision Longformers 中的全局和本地令牌。
值得注意的是,至少在仅视觉任务中,全局令牌在每个注意力块结束时被丢弃(而本地令牌被重新整形并传递给下一个),因为此时它们已经完成了允许空间上遥远的令牌之间的有效通信。
作者采用了 DeiT 风格的训练,并取得了令人印象深刻的参数和 FLOP 效率。
Haloing 和 Strided local Self-Attention
Scaling Local Self-Attention for Parameter Efficient Visual Backbones 57建立在 SASA 模型之上,通过开发新引入的晕圈操作提高了效率的仅局部自我注意模型系列。
更准确地说,作者引入了一种称为 Blocked Self-Attention 的新策略:首先将输入划分为块(将用作查询),然后将相邻像素捆绑在一起并填充,在称为晕圈的操作中,以生成键和值. 最后,应用注意力。
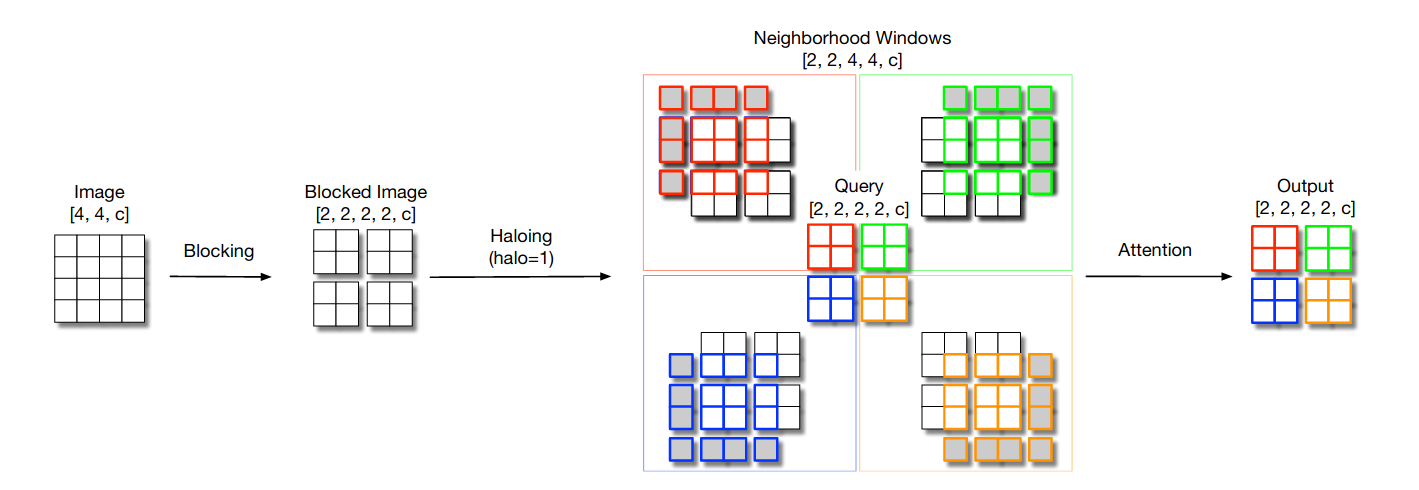
图 15:HaloNets 中使用的阻塞局部自我注意。
值得注意的是,这种操作会导致层不是平移等变的,但作者采取了这种方法来获得更高的硬件利用率。
由于在每个阶段结束时应用了跨步版本的自我注意(因此取代了 SASA 模型后注意平均池),该网络采用了分层结构。
由此产生的模型,称为 HaloNets,实现了极高的参数效率,略高于 EfficientNets,这是迄今为止任何其他模型都没有的壮举。然而,值得注意的是,HaloNets 的步进时间更长,尤其是在使用更大的配置时。
二阶池化
So-ViT: Mind Visual Tokens for Vision Transformer 58最近提出使用二阶池化从视觉标记(即除第一类之外的所有标记)中提取高级信息。模型的 logits 最终通过将两个单独的线性头的输出相加得到,一个应用于类令牌,一个应用于池化特征。
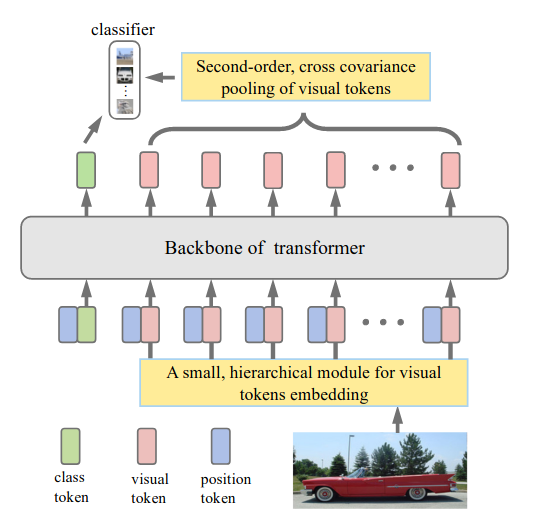
生成的模型称为二阶 ViT (So-ViT),使用扩展的 DeiT 配方进行训练,并获得有竞争力的结果。
图像分类比较
在继续之前,我们回顾一下目前为止大多数模型的报告性能。
为了提供公平的比较,我们只考虑以相同分辨率训练的模型(224 × 224) 除了受过培训的 ViT384 × 384. 我们还表示在更高(384 × 384) 具有向上箭头的分辨率,并排除训练超过400epochs 或使用 DeiT 硬标签蒸馏技术,因为只有 DeiT、T2T 和 CaiT 论文报告使用它的结果。包含一些卷积模型(EfficientNets、NFNets、ResNet-RS 和 EfficientNetV2s)以供参考,即使它们使用不同的配方和训练分辨率。
我们遵循An Analysis of Deep Neural Network Models for Practical Applications 59绘制 ImageNet top-1 精度与 FLOP 和参数计数的关系图。显示了很多模型,因此请确保启用和禁用各种模型的显示(通过单击图例中的它们)以更好地探索可视化。
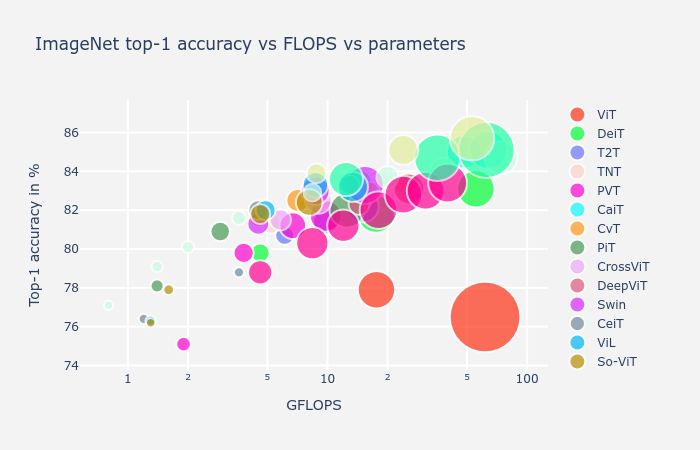
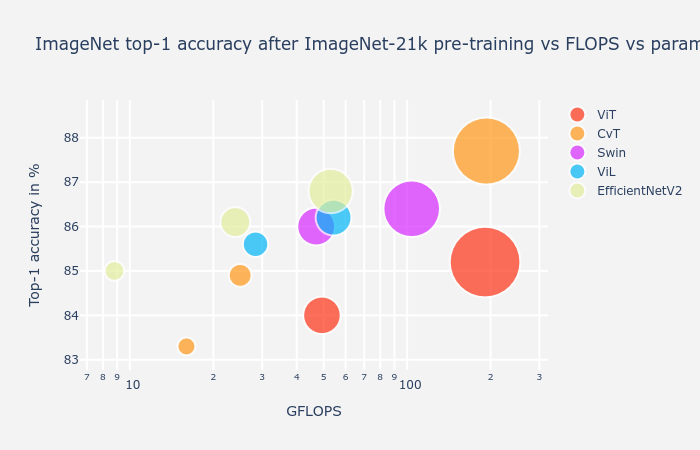
值得记住的是,FLOP 使用和参数计数不一定代表延迟或内存消耗。
正如最近的ResNet-RS 论文60所解释的那样,“在自定义硬件架构(例如 TPU 和 GPU)中,操作通常受到内存访问成本的限制,并且在现代矩阵乘法单元上具有不同级别的优化。” 由于这些原因,FLOPs 是延迟时间的一个特别差的代理。
同样,参数的数量是训练期间内存消耗的一个较差指标。同样来自 ResNet-RS 论文,“参数计数不一定决定训练期间的内存消耗,因为内存通常由激活的大小支配”,必须存储这些激活以执行反向传播算法。“在推理时,可以丢弃激活,参数计数是实际内存消耗的更好代表。”
ResNet-RS 模型就是这个问题的一个很好的例子:一个 ResNet-RS 分别有3 − 4 ×和2 ×类似准确的 EfficientNet 的参数和 FLOP 的数量,但它是3 ×一样快,消耗大约2 ×更少的内存。由于这些原因,新研究的作者最好包括参数计数和 FLOP 使用,以及延迟和内存使用测量。
鲁棒性和等效性
了解用于图像分类的 Transformer的鲁棒性61研究了 Vision Transformer 对输入、建模和对抗性扰动的鲁棒性。作者发现 Vision Transformer 在输入和模型扰动(特别是在大数据机制中)与类似大小的 CNN 相比具有优势。然而,对于某些类型的对抗性攻击,视觉transformers被发现更容易受到影响,至少对于小样本而言。
作者还发现 vanilla Vision Transformers 高度冗余,这是在 DeepViTs 中首次报道的一个发现,表明可能使用重剪枝作为更高效模型的途径。
在Group Equivariant Stand-Alone Self-Attention For Vision 62中,作者开发了一种与任意对称组等变的自注意公式。由此产生的模型,称为组自注意力网络(GSA-Nets),具有出色的参数效率,尽管还没有达到可比大小的等变 CNN 的水平。
自我监督学习中的视觉转换器
在之前的研究(iGPT 63和Vision Transformers 论文19中的蒙面补丁预测)的基础上,两篇论文研究了使用 Vision Transformers 的自我监督方法。
训练自监督视觉 Transformers 的实证研究64确定了在自监督训练期间遇到的不稳定性,导致性能下降,尤其是在大批量时。作者提出了一个奇怪的技巧:一个固定的随机补丁投影,不像普通的 ViT,补丁嵌入就像网络的其余部分一样学习。
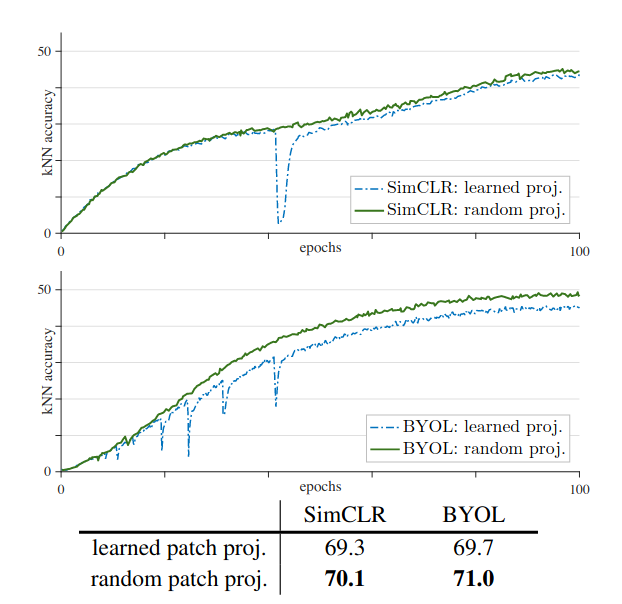
图 17:使用学习和随机补丁嵌入的训练稳定性比较。
作者表明,通过将此技巧与 MLP 块中的批量归一化(而不是层归一化)结合使用,可以使视觉转换器的自监督训练更加稳定,从而使模型在多个下游任务上实现卓越的性能。
不幸的是,作者还指出,这种方法还不够:不稳定性得到了缓解,但并未解决,尤其是在较大的学习率下。
SiT:Self-supervised vision Transformer 65,研究了三个半监督任务(旋转预测、图像重建和对比任务)的混合,当它们组合在一起时,可以让 Vision Transformer 在下游任务中表现良好。
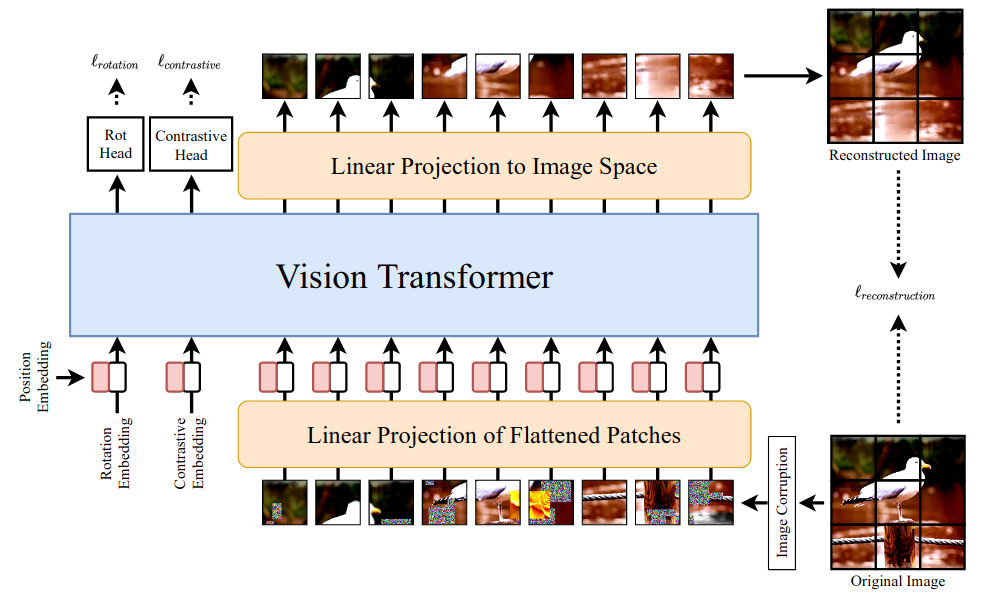
图 18:自监督视觉 Transformer 架构。
医学研究中的视觉transformers
视觉转换器最近被应用于医学研究,主要用于分割任务和诊断预测任务。
TransUNet:transformers为医学图像分割提供强大的编码器66在他们称为 TransUNet 的 UNet 风格架构中使用混合 CNN-ViT 编码器进行了探索。作者在几个分割任务中报告了良好的结果,特别是在使用级联上采样器获得最终分割掩码时。
在Medical Transformer: Gated Axial-Attention for Medical Image Segmentation 67中,作者提出使用两个分支,一个较浅的分支在图像的全局上下文上运行,而一个较深的分支在局部块上运行。用于模型的基本构建块,他们将其命名为 Medical Transformer (MedT),是(门控)轴向自注意力16。作者在几个医学分割任务上获得了对基线的改进。
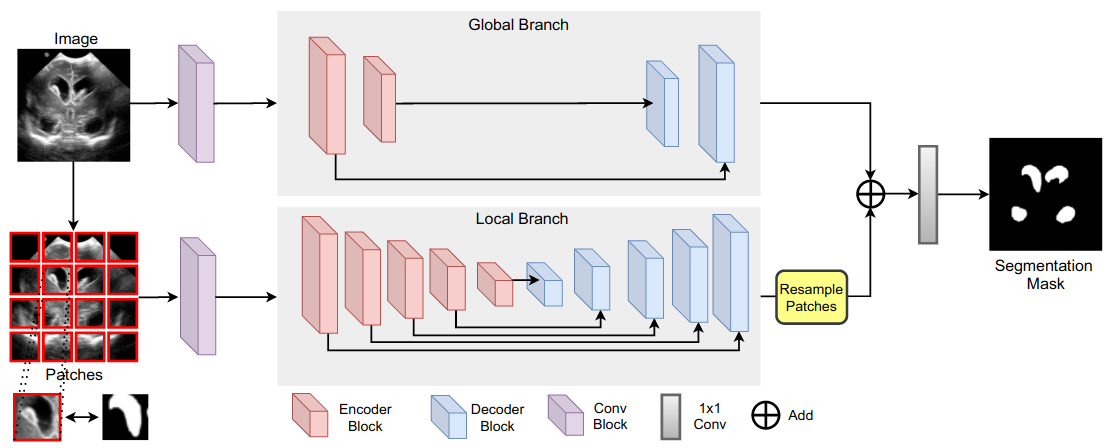
图 19:医疗transformers架构。
UNETR: Transformers for 3D Medical Image Segmentation 68为 3D 医学分割任务改编了 ViT。作者表明,一个简单的适应足以改进几个 3D 分割任务的基线。
用于视频识别的视觉转换器
Video Transformer Network 69 (VTN) 提议使用预训练的 2D 空间骨干网(作者对基于 CNN 和基于 ViT 的特征提取器进行实验)与对提取的 Transformer (在本例中为 Longformer)相结合特征图。作者表明,这种简单的方法与SlowFast 70等基线相比具有竞争力。
时空注意力是视频理解所需要的全部吗?71推出了 TimeSformer,这是 ViT 对视频的改编。在探索了几种可能的注意变体之后,作者提出了一种称为划分时空注意的变体。在这种方法中,帧首先被分成块并线性嵌入,然后馈送到单个transformers编码器。每个编码器层都有两个连续应用的注意块:第一个用于在同一位置但在不同帧中的块嵌入(时间注意),第二个用于同一帧中的块嵌入(空间注意)。
作者对空间注意块采用 ImageNet 预训练,并表明生成的模型达到了最先进的水平,在Kinetics-400 72等标准数据集上优于以前的基线。
一张图片价值 16x16 字,什么是视频价值?73提出使用视觉转换器对帧内补丁之间的关系进行建模,然后使用(时间)转换器编码器对帧间关系进行建模。它在概念上类似于具有基于 ViT 的空间主干的 VTN。
生成的模型(称为空间和时间变换器,或 STAM)在准确度/FLOPs 权衡方面优于强大的基线,例如X3D 74。
ViViT: A Video Vision Transformer 75讨论了使 ViT 适应视频的几种方法,并发现使用小管嵌入、时空管的线性投影是最有效的。
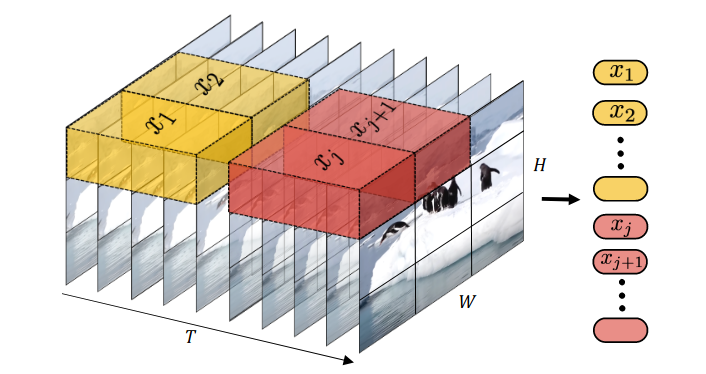
图 20:ViViT 中的 Tubelet 嵌入。
位置嵌入通过时间重复从预训练的 ViT 获得的位置嵌入来初始化。Tubelet 嵌入使用“中心帧初始化”进行初始化,其中时间中心帧的嵌入使用预训练的 ViT 补丁嵌入进行初始化,而其余部分使用零初始化。
由此产生的模型称为 Video Vision Transformers (ViViTs),在几个标准基准测试中实现了最先进的性能,优于 TimeSformers。作者甚至报告了使用名为 ViViT-H 的超大骨干进行的实验,该骨干是从在 JFT-300M 上预训练的类似大型 ViT-H 初始化的。该模型获得了显着的性能改进,尽管计算成本很高。
最近,Multiscale Vision Transformers 76提出通过逐步增加特征维度同时减少时空维度来采用分层结构。这是通过使用池化来实现的,应用于注意力块中的键和值。
作者通过展示生成的模型(称为 Multiscale Vision Transformers (MViTs))如何在标准基准测试上优于 TimeSFormers 和 ViViTs,同时使用一小部分计算,证明了这种方法的有效性。重要的是,这种方法不需要额外的数据(不像 TimeSFormers 和 ViViTs,需要 ImageNet 预训练)。
结论
在撰写本文时,唯一在效率上仍无法被 Transformer 超越的卷积架构是最近的EfficientNetV2 系列模型77,它是通过广泛的神经架构搜索获得的。没有对基于 ViT 的模型进行类似的广泛搜索,但在CvT:Introducing Convolutions to Vision Transformers 53中报告的小型搜索取得了可喜的结果(CvT-13-NAS)。
从最近的研究中,我们可以得出几个结论:
- 归纳偏差塑造了模型的性能。表征卷积神经网络的硬归纳偏差为它们提供了更高的性能下限和更低的性能上限。相反,基于转换器的方法难以在小数据体系中竞争(因此需要更强的数据增强),但在数据丰富的体系中表现出色。正如许多论文所研究的那样,一种有效的解决方案可能是在变压器中注入软电感偏置,从而在提供足够数据的情况下在小数据范围内实现高采样效率和高模型表现力。
- 香草视觉transformers显得非常多余;无论是通过自定义规范化策略、层次结构还是修剪,它们都可以在很少或没有性能成本的情况下提高计算效率。
- 几项研究强调了在原版 Vision Transformers 中使用类令牌的问题。更好的选择似乎是后期插入类令牌和使用全局平均池。二阶池化和类注意层似乎更好。
- 每天发布的研究数量非常可观。出于这个原因,我们想突出一些模型以进行更深入的了解,包括最初的Vision Transformers 19、DeiTs 20、TNTs 32、ConViTs 40、Swin Transformers 48、CvTs 53、CaiTs 35和ViLs 55。
- 视觉中的transformers才刚刚起步,随着计算机视觉社区的更广泛部分采用它们,它们的性能可能会继续提高。计算和数据可用性的增加也可能使天平越来越有利于他们。
transformers在视觉上的成功产生了深远的影响。我们已经讨论了它们对医疗和视频任务的影响,但它们的影响远至音频(使用AST 78,Keyword Transformer 79)和多模式架构(例如ViLT 80和VATT 81)。他们的成功也启发了具有更少归纳偏差的架构,例如Perceiver 82。
随着越来越多来自人工智能领域的研究人员汇聚到共同的、更通用的架构上,人们不禁感到兴奋。
Acknowledgements
Thanks to Simone Scardapane, Andrea Panizza, Amedeo Buonanno and Iacopo Poli for help in proofreading and improving this work.
References
1. Attention is all you need.
Vaswani, A., Shazeer, N., Parmar, N., et al., 2017.
2. BERT: Pre-training of deep bidirectional transformers for language understanding.
Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K., 2019.
3. Megatron-LM: Training multi-billion parameter language models using model parallelism.
Shoeybi, M., Patwary, M., Puri, R., LeGresley, P., Casper, J. & Catanzaro, B., 2019.
4. Exploring the limits of transfer learning with a unified text-to-text transformer.
Raffel, C., Shazeer, N., Roberts, A., et al., 2020.
5. Improving language understanding with unsupervised learning.
Radford, A., 2019.
6. Better language models and their implications.
Radford, A., 2018.
7. Language models are few-shot learners.
Brown, T. B., Mann, B., Ryder, N., et al., 2020.
8. Scaling laws for neural language models.
Kaplan, J., McCandlish, S., Henighan, T., et al., 2020.
9. Scaling laws for transfer.
Hernandez, D., Kaplan, J., Henighan, T. & McCandlish, S., 2021.
10. Attention augmented convolutional networks.
Bello, I., Zoph, B., Le, Q., Vaswani, A. & Shlens, J., 2019.
11. Stand-alone self-attention in vision models.
Parmar, N., Ramachandran, P., Vaswani, A., Bello, I., Levskaya, A. & Shlens, J., 2019.
12. End-to-end object detection with transformers.
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A. & Zagoruyko, S., 2020.
13. Visual transformers: Token-based image representation and processing for computer vision.
Wu, B., Xu, C., Dai, X., et al., 2020.
14. LambdaNetworks: Modeling long-range interactions without attention.
Bello, I., 2021.
15. Image transformer.
Parmar, N., Vaswani, A., Uszkoreit, J., et al., 2018.
16. Axial attention in multidimensional transformers.
Ho, J., Kalchbrenner, N., Weissenborn, D. & Salimans, T., 2019.
17. A survey on visual transformer.
Han, K., Wang, Y., Chen, H., et al., 2020.
18. Transformers in vision: A survey.
Khan, S., Naseer, M., Hayat, M., Zamir, S. W., Khan, F. S. & Shah, M., 2021.
19. An image is worth 16x16 words: Transformers for image recognition at scale.
Dosovitskiy, A., Beyer, L., Kolesnikov, A., et al., 2021.
20. Training data-efficient image transformers & distillation through attention.
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A. & Jégou, H., 2020.
21. Deep networks with stochastic depth.
Huang, G., Sun, Y., Liu, Z., Sedra, D. & Weinberger, K. Q., 2016.
22. RandAugment: Practical automated data augmentation with a reduced search space.
Cubuk, E. D., Zoph, B., Shlens, J. & Le, Q., 2020.
23. Mixup: Beyond empirical risk minimization.
Zhang, H., Cissé, M., Dauphin, Y. N. & Lopez-Paz, D., 2018.
24. CutMix: Regularization strategy to train strong classifiers with localizable features.
Yun, S., Han, D., Chun, S., Oh, S. J., Yoo, Y. & Choe, J., 2019.
25. Random erasing data augmentation.
Zhong, Z., Zheng, L., Kang, G., Li, S. & Yang, Y., 2020.
26. Dropout: A simple way to prevent neural networks from overfitting.
Srivastava, N., Hinton, G. E., Krizhevsky, A., Sutskever, I. & Salakhutdinov, R., 2014.
27. EfficientNet: Rethinking model scaling for convolutional neural networks.
Tan, M. & Le, Q. V., 2019.
28. Bottleneck transformers for visual recognition.
Srinivas, A., Lin, T.-Y., Parmar, N., Shlens, J., Abbeel, P. & Vaswani, A., 2021.
29. Squeeze-and-excitation networks.
Hu, J., Shen, L., Albanie, S., Sun, G. & Wu, E., 2020.
30. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning.
Elfwing, S., Uchibe, E. & Doya, K., 2018.
31. Conditional positional encodings for vision transformers.
Chu, X., Tian, Z., Zhang, B., et al., 2021.
32. Transformer in transformer.
Han, K., Xiao, A., Wu, E., Guo, J., Xu, C. & Wang, Y., 2021.
33. DeepViT: Towards deeper vision transformer.
Zhou, D., Kang, B., Jin, X., et al., 2021.
34. LazyFormer: Self attention with lazy update.
Ying, C., Ke, G., He, D. & Liu, T.-Y., 2021.
35. Going deeper with image transformers.
Touvron, H., Cord, M., Sablayrolles, A., Synnaeve, G. & Jégou, H., 2021.
36. Fixup initialization: Residual learning without normalization.
Zhang, H., Dauphin, Y. N. & Ma, T., 2019.
37. Batch normalization biases residual blocks towards the identity function in deep networks.
De, S. & Smith, S. L., 2020.
38. Talking-heads attention.
Shazeer, N., Lan, Z., Cheng, Y., Ding, N. & Hou, L., 2020.
39. High-performance large-scale image recognition without normalization.
Brock, A., De, S., Smith, S. L. & Simonyan, K., 2021.
40. ConViT: Improving vision transformers with soft convolutional inductive biases.
d’Ascoli, S., Touvron, H., Leavitt, M. L., Morcos, A. S., Biroli, G. & Sagun, L., 2021.
41. On the relationship between self-attention and convolutional layers.
Cordonnier, J.-B., Loukas, A. & Jaggi, M., 2020.
42. Incorporating convolution designs into visual transformers.
Yuan, K., Guo, S., Liu, Z., Zhou, A., Yu, F. & Wu, W., 2021.
43. LocalViT: Bringing locality to vision transformers.
Li, Y., Zhang, K., Cao, J., Timofte, R. & Gool, L. V., 2021.
44. Tokens-to-token ViT: Training vision transformers from scratch on ImageNet.
Yuan, L., Chen, Y., Wang, T., et al., 2021.
45. MobileNetV2: Inverted residuals and linear bottlenecks.
Sandler, M., Howard, A. G., Zhu, M., Zhmoginov, A. & Chen, L.-C., 2018.
46. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions.
Wang, W., Xie, E., Li, X., et al., 2021.
47. Scalable visual transformers with hierarchical pooling.
Pan, Z., Zhuang, B., Liu, J., He, H. & Cai, J., 2021.
48. Swin transformer: Hierarchical vision transformer using shifted windows.
Liu, Z., Lin, Y., Cao, Y., et al., 2021.
49. Rethinking spatial dimensions of vision transformers.
Heo, B., Yun, S., Han, D., Chun, S., Choe, J. & Oh, S. J., 2021.
50. LeViT: A vision transformer in ConvNet’s clothing for faster inference.
Graham, B., El-Nouby, A., Touvron, H., et al., 2021.
51. Bridging nonlinearities and stochastic regularizers with gaussian error linear units.
Hendrycks, D. & Gimpel, K., 2016.
52. CrossViT: Cross-attention multi-scale vision transformer for image classification.
Chen, C.-F., Fan, Q. & Panda, R., 2021.
53. CvT: Introducing convolutions to vision transformers.
Wu, H., Xiao, B., Codella, N., et al., 2021.
54. Xception: Deep learning with depthwise separable convolutions.
Chollet, F., 2017.
55. Multi-scale vision longformer: A new vision transformer for high-resolution image encoding.
Zhang, P., Dai, X., Yang, J., et al., 2021.
56. Longformer: The long-document transformer.
Beltagy, I., Peters, M. E. & Cohan, A., 2020.
57. Scaling local self-attention for parameter efficient visual backbones.
Vaswani, A., Ramachandran, P., Srinivas, A., Parmar, N., Hechtman, B. A. & Shlens, J., 2021.
58. So-ViT: Mind visual tokens for vision transformer.
Xie, J., Zeng, R., Wang, Q., Zhou, Z. & Li, P., 2021.
59. An analysis of deep neural network models for practical applications.
Canziani, A., Paszke, A. & Culurciello, E., 2016.
60. Revisiting ResNets: Improved training and scaling strategies.
Bello, I., Fedus, W., Du, X., et al., 2021.
61. Understanding robustness of transformers for image classification.
Bhojanapalli, S., Chakrabarti, A., Glasner, D., Li, D., Unterthiner, T. & Veit, A., 2021.
62. Group equivariant stand-alone self-attention for vision.
Romero, D. W. & Cordonnier, J.-B., 2021.
63. Generative pretraining from pixels.
Chen, M., Radford, A., Child, R., et al., 2020.
64. An empirical study of training self-supervised vision transformers.
Chen, X., Xie, S. & He, K., 2021.
65. SiT: Self-supervised vIsion transformer.
Ahmed, S. A. A., Awais, M. & Kittler, J., 2021.
66. TransUNet: Transformers make strong encoders for medical image segmentation.
Chen, J., Lu, Y., Yu, Q., et al., 2021.
67. Medical transformer: Gated axial-attention for medical image segmentation.
Valanarasu, J. M. J., Oza, P., Hacihaliloglu, I. & Patel, V. M., 2021.
68. UNETR: Transformers for 3D medical image segmentation.
Hatamizadeh, A., Yang, D., Roth, H. & Xu, D., 2021.
69. Video transformer network.
Neimark, D., Bar, O., Zohar, M. & Asselmann, D., 2021.
70. SlowFast networks for video recognition.
Feichtenhofer, C., Fan, H., Malik, J. & He, K., 2019.
71. Is space-time attention all you need for video understanding?
Bertasius, G., Wang, H. & Torresani, L., 2021.
72. The kinetics human action video dataset.
Kay, W., Carreira, J., Simonyan, K., et al., 2017.
73. An image is worth 16x16 words, what is a video worth?
Sharir, G., Noy, A. & Zelnik-Manor, L., 2021.
74. X3D: Expanding architectures for efficient video recognition.
Feichtenhofer, C., 2020.
75. ViViT: A video vision transformer.
Arnab, A., Dehghani, M., Heigold, G., Sun, C., Lucic, M. & Schmid, C., 2021.
76. Multiscale vision transformers.
Fan, H., Xiong, B., Mangalam, K., et al., 2021.
77. EfficientNetV2: Smaller models and faster training.
Tan, M. & Le, Q. V., 2021.
78. AST: Audio spectrogram transformer.
Gong, Y., Chung, Y.-A. & Glass, J. R., 2021.
79. Keyword transformer: A self-attention model for keyword spotting.
Berg, A., O’Connor, M. & Cruz, M. T., 2021.
80. ViLT: Vision-and-language transformer without convolution or region supervision.
Kim, W., Son, B. & Kim, I., 2021.
81. VATT: Transformers for multimodal self-supervised learning from raw video, audio and text.
Akbari, H., Yuan, L., Qian, R., et al., 2021.
82. Perceiver: General perception with iterative attention.
Jaegle, A., Gimeno, F., Brock, A., Zisserman, A., Vinyals, O. & Carreira, J., 2021.
Reuse
Text and figures are licensed under Creative Commons Attribution CC BY 4.0. The figures that have been reused from other sources don't fall under this license and can be recognized by a note in their caption: "Figure from ...".
Citation
For attribution, please cite this work as
Zanichelli (2021, April 28). IAML Distill Blog: Transformers in Vision. Retrieved from https://iaml-it.github.io/distill/posts/2021-04-28-transformers-in-vision/
BibTeX citation
@misc{zanichelli2021transformers,
author = {Zanichelli, Niccolò},
title = {IAML Distill Blog: Transformers in Vision},
url = {https://iaml-it.github.io/distill/posts/2021-04-28-transformers-in-vision/},
year = {2021}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号