最全RAG技术详解
一 什么是RAG技术
RAG(retrieval Augmented generation) ,中文检索增强技术。因为LLM在生成答案的时候可能会胡说八道,缺少专业知识,RAG技术可以连通LLM与外部数据,使得LLM的generation 中的答案来源于外部资源,保证答案的准确性。
最早出自于2020年facebook的论文https://proceedings.neurips.cc/paper_files/paper/2020/file/6b493230205f780e1bc26945df7481e5-Paper.pdf
后来出现各种高级的RAG技术:比如最具有代表的Grap RAG ,LightRAG 等等。
二 普通RAG技术理论详解
RAG技术大体框架如下:
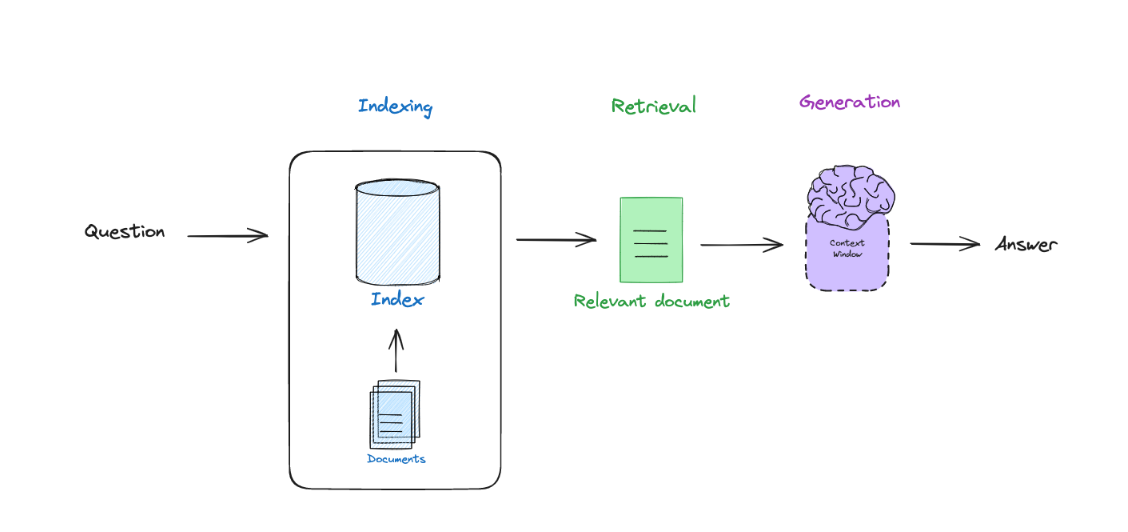
当我们输入一个问题的时候,首先需要去数据库里面检索(retrieval)知识,最后LLM根据这个知识进行回答。
那我们就得事先构建好知识库或者数据库,供LLM检索。这里的数据库可以是向量数据库,知识图谱等等。
因此,RAG技术可以分为三个部分。
1.建立索引阶段(indexing):将知识数据存入向量数据库中,这里需要embding 的知识。
2.检索阶段(retrieval) : 根据用户输入的问题去数据库中检索相关 的知识,涉及到相似度,知识图谱,检索算法等知识
3.生成阶段:将检索到的知识和问题一起交给LLM ,LLM生成答案。涉及到的技术包括提示词技术。
2.1 第一阶段(indexing)
(1)建立向量数据库需要将知识数据进行预处理,通常是先结构化,分块。而在这里又涉及到很多知识和挑战,比如如何分块?分块后如何保证知识不丢失?
(2)对split知识片段进行embedding,存入向量数据库中。
如上述两点,对数据源进行处理的知识先不考虑,demo中的知识都比较简单,因此,要完成第二点,那么就需要先安装一个向量数据库,以及准备一个embedding 模型。
Qdant向量数据库安装及使用
Qdrant(读作:quadrant)是一个向量相似性搜索引擎。它提供了一项可用于生产的服务,其中包含一个方便的 API,用于存储、搜索和管理向量,并提供额外的负载和扩展的过滤支持。它适用于各种神经网络或基于语义的匹配、分面搜索和其他应用程序。
参考链接:https://mp.weixin.qq.com/s/qhmHgISskXC-Z3AGL9TTHw
这里介绍了LangChain中使用Qdrant来实现对向量的检索。
免安装Qdrant使用
# 安装必要的库
# pip install langchain langchain-community langchain-text-splitters qdrant-client sentence-transformers
# 没有连接本地的Qdrant实例,使用内存中存储,也可以使用本地路径如 "./qdrant_db"
import os
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Qdrant
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.document_loaders import TextLoader
# 1. 初始化嵌入模型 - 使用适合CPU运行的小型模型
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2",
model_kwargs={'device': 'cpu'}
)
# 2. 函数:加载文本文件并分割成块
def load_and_split_text(file_path, chunk_size=1000, chunk_overlap=200):
loader = TextLoader(file_path, encoding='utf-8')
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
length_function=len
)
text_chunks = text_splitter.split_documents(documents)
print(f"文本已分割成 {len(text_chunks)} 个块")
return text_chunks
# 3. 函数:创建Qdrant向量数据库并存储文本嵌入
def create_vector_db(text_chunks, collection_name="text_collection"):
# 创建一个本地Qdrant实例
vector_db = Qdrant.from_documents(
documents=text_chunks,
embedding=embeddings,
location=":memory:", # 内存中存储,也可以使用本地路径如 "./qdrant_db"
collection_name=collection_name,
)
print(f"向量数据库已创建,集合名称: {collection_name}")
return vector_db
# 4. 函数:根据用户查询检索相关文本
def search_similar_text(vector_db, query, k=3):
results = vector_db.similarity_search(query, k=k)
return results
# 5. 主函数:演示整个流程
def main():
# 示例文本文件路径
text_file_path = "your_text_file.txt" # 替换为您的文本文件路径
# 如果没有示例文件,创建一个
if not os.path.exists(text_file_path):
with open(text_file_path, "w", encoding="utf-8") as f:
f.write("""
向量数据库是一种专门设计用于存储和检索向量数据的数据库系统。在人工智能和机器学习领域,数据通常被表示为高维向量。
Qdrant是一个开源的向量相似度搜索引擎,专注于生产环境中的高效向量相似度搜索。它提供了REST API和gRPC接口,并具有过滤功能。
LangChain是一个用于开发由语言模型驱动的应用程序的框架。它可以将各种组件连接起来,包括语言模型、向量数据库和其他工具。
向量嵌入是将文本、图像或其他数据转换为数值向量的过程。这些向量捕获了原始数据的语义信息,使得相似的内容在向量空间中更接近。
相似度搜索是在向量空间中寻找与查询向量最相似的向量的过程。常用的度量方法包括余弦相似度和欧几里得距离。
""")
print(f"创建了示例文本文件: {text_file_path}")
# 加载并分割文本
text_chunks = load_and_split_text(text_file_path)
# 创建向量数据库
print("\n创建向量数据库...")
vector_db = create_vector_db(text_chunks)
# 用户查询交互
while True:
query = input("\n请输入您的查询 (输入'exit'退出): ")
if query.lower() == 'exit':
break
# 搜索相似文本
results = search_similar_text(vector_db, query)
print("\n找到的相关文本片段:")
for i, doc in enumerate(results):
print(f"\n--- 结果 {i+1} ---")
print(f"内容: {doc.page_content}")
print(f"元数据: {doc.metadata}")
# print(f"相似度: {doc.metadata['score']}")
if __name__ == "__main__":
main()
上述代码就直接实现了索引向量数据库的创建,检索功能。
2.2 第二阶段(检索)
results = vector_db.similarity_search(query, k=k)
retriever = vector_db.as_retriever(search_kwargs={"k": 3})
在 LangChain 框架中,这两种检索方式有以下区别:
-
抽象层级不同:
•vector_db.as_retriever()返回的是一个实现了BaseRetriever接口的检索器对象,这是 LangChain 的链式工作流(Chains)的标准接口
•vector_db.similarity_search()是向量数据库的直接搜索方法,属于底层操作 -
参数传递方式:
• Retriever 通过search_kwargs参数字典配置搜索参数(如 k=3)
• similarity_search 直接接受明确参数(如 query, k=k) -
功能扩展性:
• Retriever 支持更复杂的检索流程(如结果后处理、多路召回等)
• similarity_search 是基础相似度搜索的直接实现
常见的其他检索方法包括:
- 最大边际相关性搜索 (MMR)
results = vector_db.max_marginal_relevance_search(query, k=5, fetch_k=20)
在保证相关性的同时增加结果多样性
- 元数据过滤搜索
results = vector_db.similarity_search(
query,
k=5,
filter={"author": "鲁迅", "year": {"$gte": 2020}}
)
- 自定义相似度算法
# 可自定义距离计算方式(余弦/欧氏/内积等)
vector_db = FAISS.from_texts(texts, embeddings, distance_strategy=DistanceStrategy.COSINE)
-
多向量检索
• 父文档检索器 (ParentDocumentRetriever)
• 层次化检索(先粗筛后精筛) -
混合检索:
• 结合传统 BM25 与向量检索的混合搜索
• 使用 RRF(Reciprocal Rank Fusion)合并多路召回结果 -
异步检索:
results = await vector_db.asimilarity_search(query, k=3)
- 分数阈值过滤:
retriever = vector_db.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"k": 5, "score_threshold": 0.8}
)
实际选择时应考虑:
• 简单场景直接使用 similarity_search
• 需要集成到 LangChain 工作流时使用 Retriever
• 需要结果多样性时用 MMR
• 需要精确过滤时用元数据查询
• 大规模数据用层次化检索
2.3 第三阶段(生成)
生成阶段需要涉及到LLM,加载LLM的方法有以下几种:
在本地加载和使用大模型的方法主要分为应用部署工具和源码部署两大类,以下从这两种类型展开具体方法,并结合与模型的交互场景(如对话)进行说明:
一、应用部署工具(适合新手/非编程用户)
这类工具通过提供图形化界面或简化命令操作,降低本地部署大模型的门槛。
1. Ollama
• 特点:开源、跨平台(支持Windows/Mac/Linux),支持类似Docker的命令行操作,生态丰富(可集成Open WebUI等前端)。
• 步骤:
- 官网下载安装包并完成安装。
- 命令行输入
ollama run <模型名>(如ollama run llama3),自动下载并加载模型。 - 启动后可直接在命令行输入文本与模型对话,输入
/bye退出。
• 进阶:
• 通过Docker部署前端界面(如Open WebUI),实现类似ChatGPT的交互体验。
• 支持API调用,方便集成到其他应用中。
2. LM Studio
• 特点:图形化界面操作,内置模型市场,支持GPU/CPU自动切换。
• 步骤:
- 官网下载安装并打开软件。
- 搜索并下载所需模型(如Llama 3)。
- 加载模型后进入对话界面,输入文本即可交互。
• 优势:无需命令行知识,适合小白用户快速上手。
3. GPT4All
• 特点:无需GPU支持,纯CPU运行,隐私性强,适合低配置设备。
• 步骤:
- 官网下载客户端并安装。
- 在界面中选择模型(如GPT-J)并下载。
- 加载模型后直接通过内置聊天面板对话。
二、源码部署(需编程基础)
通过代码调用框架或库直接加载模型,灵活性更高,适合开发者。
1. Hugging Face Transformers库
• 核心方法:
• 使用pipeline快速加载模型:
from transformers import pipeline
# 加载对话模型
chatbot = pipeline("text-generation", model="facebook/opt-1.3b")
response = chatbot("你好,如何学习AI?")
print(response[0]['generated_text'])
• 手动下载并本地加载模型:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("gpt2", cache_dir="./models")
tokenizer = AutoTokenizer.from_pretrained("gpt2", cache_dir="./models")
通过cache_dir指定本地路径,确保离线使用。
• 优化技巧:
• GPU加速:设置device=0将模型加载到GPU。
• 量化压缩:使用bitsandbytes库减少显存占用。
2. 构建API服务(结合FastAPI)
• 步骤:
- 使用FastAPI创建后端接口,调用Hugging Face模型:
```python
from fastapi import FastAPI
from transformers import pipeline
app = FastAPI()
chatbot = pipeline("text-generation", model="gpt2")
@app.post("/chat")
def get_response(text: str):
return chatbot(text)[0]['generated_text']
```
- 运行服务后,通过HTTP请求与模型交互。
• 应用场景:开发智能客服、自动化文档生成等。
三、进阶技巧与优化
- 模型压缩:
• 量化:将模型精度从FP32降至INT8,显存占用减少50%以上。
• 剪枝:移除冗余参数,提升推理速度。 - 硬件适配:
• 多GPU并行:通过device_map="auto"自动分配计算资源。
• 内存扩展:增加交换空间以支持大模型运行。 - 监控与维护:
• 使用日志工具跟踪模型性能,定期更新模型版本。
四、工具对比与选择建议
| 工具/方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| Ollama | 开发者、命令行用户 | 生态丰富、支持自定义模型 | 需一定技术基础 |
| LM Studio | 非技术用户、快速原型 | 图形界面、开箱即用 | 功能相对单一 |
| Hugging Face | 开发者、定制化需求 | 灵活性高、支持多种任务 | 需配置Python环境 |
| FastAPI集成 | 企业级API服务 | 高并发、易扩展 | 开发复杂度较高 |
2.4 LLM的封装与使用
1. HuggingFacePipeline vs 直接使用 pipeline 的区别
(1) 直接使用 pipeline
• 代码示例:
from transformers import pipeline
# 直接加载模型并创建对话工具
chatbot = pipeline("text-generation", model="facebook/opt-1.3b")
response = chatbot("Hello, how are you?")
• 作用:
• 直接调用 Hugging Face Transformers 库的 pipeline 函数,自动加载模型、分词器,并封装成一个端到端的推理工具。
• 适用于快速原型开发或简单任务,无需额外封装。
(2) 使用 HuggingFacePipeline
• 代码示例:
from transformers import pipeline
from langchain.llms import HuggingFacePipeline
# 先创建原生的 pipeline
pipe = pipeline("text-generation", model="facebook/opt-1.3b")
# 再封装为 LangChain 的组件
llm = HuggingFacePipeline(pipeline=pipe)
• 作用:
• HuggingFacePipeline 是 LangChain 框架中的一个类,目的是将 Hugging Face 模型封装为 LangChain 的标准化接口。
• 通过这种封装,模型可以无缝集成到 LangChain 的工作流中(如链式调用、智能体、记忆模块等)。
• 关键区别:
• 灵活性:直接使用 pipeline 适合单一任务;HuggingFacePipeline 适合复杂应用(如结合检索增强生成 RAG)。
• 输入输出格式:LangChain 的 HuggingFacePipeline 会强制模型输出符合 LangChain 的 Generation 对象格式,方便后续处理。
2. 为什么需要 GGUF 格式?
(1) 什么是 GGUF?
• 定义:GGUF(GPT-Generated Unified Format)是 llama.cpp 团队设计的模型格式,专为高效推理优化,支持 CPU/GPU 混合计算。
• 核心优势:
• 量化支持:允许将模型权重压缩为 4-bit、5-bit 等低精度格式,显著降低显存和内存占用。
• 跨平台推理:可在纯 CPU 或低配 GPU 设备上运行大模型(如 8GB 内存运行 7B 模型)。
• 速度优化:通过 C/C++ 底层优化,提升推理速度。
(2) GGUF 与 Transformers 默认模型的区别
| 特性 | Hugging Face Transformers 模型 | GGUF 模型 |
|---|---|---|
| 格式 | PyTorch(.bin)或 Safetensors |
.gguf |
| 加载方式 | 通过 from_pretrained 加载 |
通过 llama-cpp-python 库加载 |
| 量化支持 | 需要额外库(如 bitsandbytes) |
原生支持多种量化级别 |
| 适用场景 | GPU 优先,适合完整精度推理 | CPU/低配 GPU,适合资源受限环境 |
(3) 如何使用 GGUF 模型?
• 安装依赖:
pip install llama-cpp-python
• 加载模型:
from llama_cpp import Llama
# 加载 GGUF 模型(以 llama-2-7b.Q4_K_M.gguf 为例)
llm = Llama(
model_path="llama-2-7b.Q4_K_M.gguf",
n_gpu_layers=40, # 启用 GPU 加速
n_threads=8 # 多线程优化
)
# 生成文本
response = llm("Hello, how are you?", max_tokens=50)
3. pipeline 下载的是什么?
当运行以下代码时:
pipeline("text-generation", model="facebook/opt-1.3b")
• 下载内容:
- 模型权重:存储在 PyTorch 的
.bin或 Hugging Face 的.safetensors格式中。 - 分词器(Tokenizer):包含词汇表、特殊 token 定义(
tokenizer.json或vocab.txt)。 - 配置文件:模型结构(
config.json)、生成参数(generation_config.json)。
• 存储位置:
• 默认下载到 Hugging Face 的缓存目录(~/.cache/huggingface/hub)。
• 可通过cache_dir参数指定自定义路径:
```python
pipeline("text-generation", model="facebook/opt-1.3b", cache_dir="./my_models")
```
4. 如何选择加载方式?
• 直接使用 pipeline:
• 适合快速测试模型、简单对话任务。
• 需要 GPU 资源和完整精度模型。
• 使用 GGUF 模型:
• 适合资源受限环境(如笔记本电脑、嵌入式设备)。
• 需要量化压缩模型以降低硬件门槛。
• 使用 HuggingFacePipeline(LangChain):
• 适合复杂应用开发(如结合知识库、多步骤推理)。
代码示例:对比两种加载方式
(1) 直接使用 pipeline
from transformers import pipeline
chatbot = pipeline("text-generation", model="facebook/opt-1.3b")
print(chatbot("What is AI?"))
(2) 使用 LangChain 的 HuggingFacePipeline
from transformers import pipeline
from langchain.llms import HuggingFacePipeline
pipe = pipeline("text-generation", model="facebook/opt-1.3b")
llm = HuggingFacePipeline(pipeline=pipe)
# 在 LangChain 链中使用
from langchain import PromptTemplate, LLMChain
template = """Question: {question}\nAnswer:"""
prompt = PromptTemplate(template=template, input_variables=["question"])
chain = LLMChain(prompt=prompt, llm=llm)
print(chain.run("What is AI?"))
(3)使用gguf格式的LLM
from llama_cpp import Llama
# 初始化模型(根据硬件调整参数)
llm = Llama(
model_path="llama-3-8b.Q4_K_M.gguf", # GGUF模型路径
n_ctx=4096, # 上下文长度(最大支持4096)
n_gpu_layers=40, # 使用GPU加速的层数(设为0则纯CPU运行)
n_threads=8, # CPU线程数(建议设为物理核心数)
verbose=False # 关闭详细日志
)
# 定义生成参数
generation_kwargs = {
"max_tokens": 200, # 生成最大token数
"temperature": 0.7, # 温度(控制随机性,0-1之间)
"top_p": 0.9, # 核心采样概率(过滤低概率token)
"stop": ["<|eot_id|>"], # 停止标记(Llama3的结束符)
"echo": False # 不返回输入文本
}
# 与模型对话
prompt = "<|start_header_id|>user<|end_header_id|>\n\n你好,如何学习深度学习?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n"
output = llm(prompt, **generation_kwargs)
# 提取模型回复
response = output["choices"][0]["text"]
print(response)
总结
• 技术选型:
• 需要快速测试 → pipeline
• 资源有限 → GGUF + llama-cpp-python
• 复杂应用 → LangChain + HuggingFacePipeline
• 模型格式:
• 完整精度 → Hugging Face 原生格式
• 量化压缩 → GGUF
三 构建完整的普通RAG工作流
# 安装必要的库
# pip install langchain langchain-community langchain-text-splitters qdrant-client sentence-transformers
# pip install langchain-openai langchain-llamacpp dashscope # 用于LLM支持
import os
from typing import List, Dict, Any, Optional
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Qdrant
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema import Document
from langchain.prompts import PromptTemplate
from qdrant_client import QdrantClient
import argparse
# 设置环境变量,如果使用通义千问API
os.environ["DASHSCOPE_API_KEY"] = "sk-9"
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
from huggingface_hub import login
hf_token = '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' # 这里替换成你的huggingface的token
login(hf_token)
# 定义模型选择
MODEL_CHOICES = ["local", "qwen"]
# 参数解析
def parse_args():
parser = argparse.ArgumentParser(description="RAG系统:索引、检索和生成")
parser.add_argument("--model", type=str, choices=MODEL_CHOICES, default="local",
help="选择LLM模型: local(本地模型)或qwen(通义千问API)")
parser.add_argument("--local_model_path", type=str, default="meta-llama/Llama-2-7b-chat",
help="本地模型路径,仅在选择local模型时使用")
parser.add_argument("--qdrant_host", type=str, default="localhost",
help="Qdrant服务器主机")
parser.add_argument("--qdrant_port", type=int, default=6333,
help="Qdrant服务器端口")
parser.add_argument("--use_local_file", action="store_true", default=True,
help="使用本地文件存储而非Qdrant服务器")
parser.add_argument("--local_file_path", type=str, default=":memory:",
help="本地Qdrant文件存储路径")
parser.add_argument("--collection", type=str, default="text_collection",
help="Qdrant集合名称")
parser.add_argument("--text_file", type=str, default="your_text_file.txt",
help="要处理的文本文件路径")
return parser.parse_args()
# 1. 初始化嵌入模型
def init_embeddings():
return HuggingFaceEmbeddings(
model_name="sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2",
model_kwargs={'device': 'cpu'}
)
# 2. 初始化LLM(本地模型或通义千问API)
def init_llm(model_choice="local", local_model_path=None):
"""
这里加载本地模型时提供了两种方法去加载llm,一种是加载gguf类型的模型,一种是加载hugginface中的模型,这种如果没有会自动下载到本地。如果使用verbose参数就会报错句柄错误,不知道为什么。
"""
if model_choice == "local":
try:
## 最原始的方法:
# 使用本地LLama CPP模型
from langchain_community.llms import LlamaCpp
if not local_model_path or not os.path.exists(local_model_path):
raise ValueError(f"本地模型路径无效: {local_model_path}")
llm = LlamaCpp(
model_path=local_model_path,
temperature=0.7,
max_tokens=100,
top_p=0.9,
# verbose=False,#去掉verbose
)
print(f"已加载本地模型: {local_model_path}")
return llm
# 使用Hugging Face Transformers
from langchain_community.llms import HuggingFacePipeline
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
import torch
if torch.cuda.is_available():
device = 0 # 使用GPU
else:
device = -1 # 使用CPU
# 对于量化模型,您可能需要使用不同的加载方式
# 这里假设使用正常的模型文件夹路径
model_id = local_model_path
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16 if torch.cuda.is_available() else torch.float32,
low_cpu_mem_usage=True,
device_map="auto"
)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_length=2048,
temperature=0.1,
top_p=0.95,
repetition_penalty=1.15
)
llm = HuggingFacePipeline(pipeline=pipe)
print(f"已加载本地模型: {model_id}")
return llm
except Exception as e:
print(f"本地模型加载失败: {e},将使用API")
model_choice = "qwen"
if model_choice == "qwen":
# 使用通义千问API
from langchain_community.llms import Tongyi
api_key = os.environ.get("DASHSCOPE_API_KEY")
if not api_key:
raise ValueError("未设置DASHSCOPE_API_KEY环境变量")
llm = Tongyi(
model_name="qwen-max", # 或其他可用模型
temperature=0.1,
dashscope_api_key=api_key
)
print("已连接到通义千问API")
elif model_choice != "local" and model_choice != "qwen":
raise ValueError(f"不支持的模型选择: {model_choice}")
return llm
# 3. 加载文本文件并分割成块
def load_and_split_text(file_path, chunk_size=1000, chunk_overlap=200):
if not os.path.exists(file_path):
create_sample_text_file(file_path)
loader = TextLoader(file_path, encoding='utf-8')
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
length_function=len
)
text_chunks = text_splitter.split_documents(documents)
print(f"文本已分割成 {len(text_chunks)} 个块")
return text_chunks
# 4. 创建样本文本文件
def create_sample_text_file(file_path):
with open(file_path, "w", encoding="utf-8") as f:
f.write("""
向量数据库是一种专门设计用于存储和检索向量数据的数据库系统。在人工智能和机器学习领域,数据通常被表示为高维向量。
Qdrant是一个开源的向量相似度搜索引擎,专注于生产环境中的高效向量相似度搜索。它提供了REST API和gRPC接口,并具有过滤功能。
LangChain是一个用于开发由语言模型驱动的应用程序的框架。它可以将各种组件连接起来,包括语言模型、向量数据库和其他工具。
向量嵌入是将文本、图像或其他数据转换为数值向量的过程。这些向量捕获了原始数据的语义信息,使得相似的内容在向量空间中更接近。
相似度搜索是在向量空间中寻找与查询向量最相似的向量的过程。常用的度量方法包括余弦相似度和欧几里得距离。
RAG (检索增强生成) 是一种结合检索系统和生成模型的方法。它首先检索相关文档,然后将这些文档作为上下文提供给生成模型,以生成更准确、更相关的回答。
本地模型部署允许在自己的硬件上运行AI模型,而不依赖云服务。这提供了数据隐私、离线操作和成本控制等优势,但可能需要更多的计算资源。
通义千问是阿里云推出的大型语言模型,提供问答、对话、文本生成等功能。它可以通过API的方式访问,支持中英文的自然语言处理任务。
LLaMa是Meta AI开发的一系列大型语言模型,提供开源和商业版本。LLaMa-2在代码生成、推理和创意写作方面表现良好,并且有多种尺寸可供选择。
问答系统是设计用来回答用户以自然语言提出的问题的系统。现代问答系统通常结合了信息检索技术和自然语言处理技术,以提供准确的答案。
""")
print(f"创建了示例文本文件: {file_path}")
# 5. 初始化Qdrant向量数据库
def init_vector_db(embeddings, args, text_chunks=None):
if args.use_local_file:
# 使用本地文件存储
location = args.local_file_path
url = None
client = None
print(f"使用本地文件存储: {location}")
else:
# 使用Qdrant服务器
location = None
url = f"http://{args.qdrant_host}:{args.qdrant_port}"
client = QdrantClient(host=args.qdrant_host, port=args.qdrant_port)
print(f"连接到Qdrant服务器: {url}")
# 检查集合是否存在
if not args.use_local_file and client:
collections = client.get_collections().collections
collection_names = [collection.name for collection in collections]
if args.collection in collection_names:
# 如果集合存在,直接连接
vector_db = Qdrant(
client=client,
collection_name=args.collection,
embedding_function=embeddings.embed_query
)
print(f"已连接到现有集合: {args.collection}")
return vector_db
# 如果集合不存在或使用本地文件,且有文本块,则创建新集合
if text_chunks:
vector_db = Qdrant.from_documents(
documents=text_chunks,
embedding=embeddings,
location=location,
url=url,
collection_name=args.collection,
client=client
)
print(f"已创建新的向量存储: {args.collection}")
return vector_db
else:
raise ValueError("无法找到现有集合,且没有提供文本块来创建新集合")
# 6. 设置RAG提示模板
def setup_rag_prompt():
template = """基于以下检索到的上下文信息,请回答问题。
上下文信息:
{context}
问题: {question}
回答:"""
return PromptTemplate.from_template(template)
# 7. 格式化检索到的文档
def format_docs(docs: List[Document]) -> str:
return "\n\n".join(f"文档 {i+1}:\n{doc.page_content}" for i, doc in enumerate(docs))
# 8. 构建RAG链
def build_rag_chain(vector_db, llm):
# 创建检索器
retriever = vector_db.as_retriever(search_kwargs={"k": 3})
# 设置提示模板
prompt = setup_rag_prompt()
# 构建RAG链
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
)
return rag_chain
# 9. 主函数
def main():
# 解析命令行参数
args = parse_args()
# 初始化嵌入模型
embeddings = init_embeddings()
# 加载并分割文本(如果文件存在)
text_chunks = None
if os.path.exists(args.text_file):
text_chunks = load_and_split_text(args.text_file)
else:
# 如果文件不存在且需要使用现有集合
text_chunks = load_and_split_text(args.text_file) # 这将创建样本文件
# 初始化向量数据库
try:
vector_db = init_vector_db(embeddings, args, text_chunks)
except Exception as e:
print(f"初始化向量数据库时出错: {e}")
return
# 初始化LLM
try:
llm = init_llm(args.model, args.local_model_path)
except Exception as e:
print(f"初始化LLM时出错: {e}")
return
# 构建RAG链
rag_chain = build_rag_chain(vector_db, llm)
# 用户交互循环
print("\n========== RAG系统已准备就绪 ==========")
print(f"使用模型: {args.model}")
print(f"向量数据库: {'本地文件' if args.use_local_file else 'Qdrant服务器'}")
print("输入'exit'退出\n")
while True:
query = input("\n请输入您的问题: ")
if query.lower() in ['exit', 'quit', '退出']:
break
try:
# 调用RAG链获取回答
response = rag_chain.invoke(query)
print("\n回答:")
print(response)
except Exception as e:
print(f"处理查询时出错: {e}")
# 入口点
if __name__ == "__main__":
main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号