国企、互联网大厂招聘平台的招聘信息爬取
国企
国资央企招聘平台集成了众多国企央企的招聘。写一个脚本实现一下各个岗位的招聘
接口
当抓包的时候发现,这些岗位信息都是通过接口发布的。因此可以通过获取这个接口的数据爬取。
编写代码:
'''
基于国资央企招聘平台的招聘信息。
https://cujiuye.iguopin.com/
'''
import requests
class get_guoqi_job():
def __init__(self):
self.url = "https://gp-api.iguopin.com/api/jobs/v1/list"
self.headers = {
"Content-Type": "application/json;charset=UTF-8",
"Accept": "application/json, text/plain, */*",
"Device": "pc",
"Subsite": "cujiuye",
"Version": "5.0.0",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36"
}
'''
默认关键词 keyword = 网络安全 信息安全,工作数量爬取最大为200,页数为1,如果工作数量大于等于200,将page改为2再次爬取.
直接调用 get_guoqi_job()
关键词调用:
get_guoqi_job('销售‘)
'''
def __call__(self,keyword='网络安全 信息安全',job_num=200 , page=1):
data = {
"page": page,
"page_size": job_num,
"keyword": keyword,
"nature": ["115xW5oQ"]
}
response = requests.post(self.url, json=data, headers=self.headers)
jobs = []
# 打印响应的 JSON 内容
res_json = response.json()
data = res_json['data']
# print(data)
data_list = data['list']
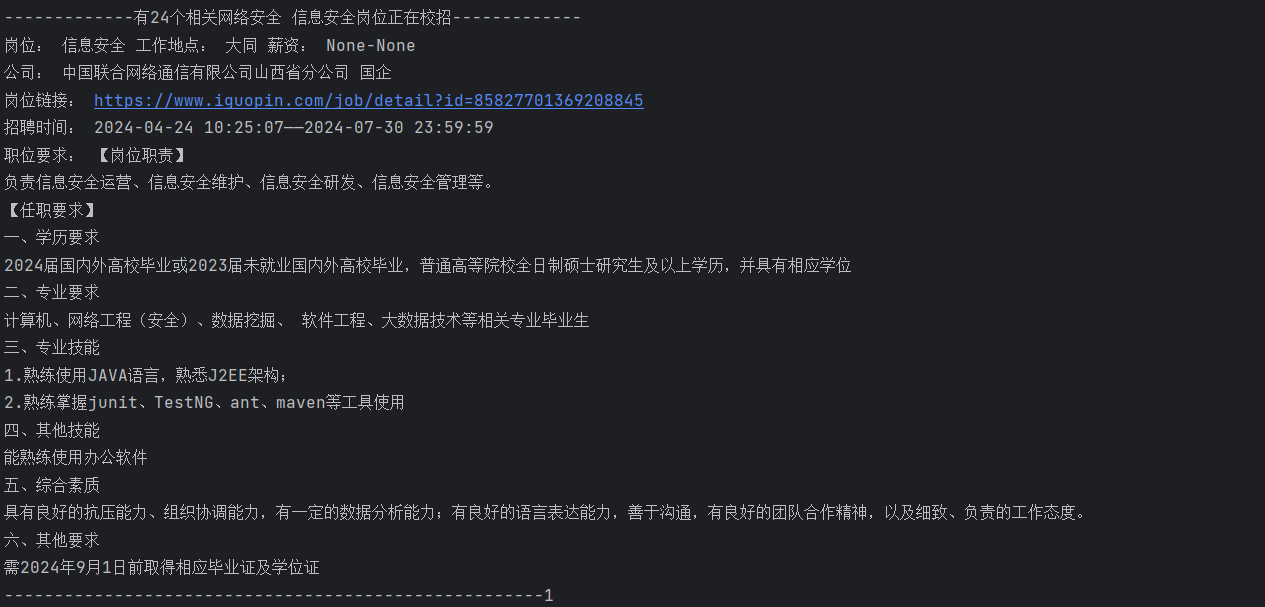
print(f'-------------有{len(data_list)}个相关{keyword}岗位正在校招-------------')
num =1
for company in data_list:
job_id = company['job_id']
job_url = 'https://www.iguopin.com/job/detail?id=' + str(job_id)
job_name = company['job_name']
company_name = company['company_name']
salary = str(company['min_wage']) + '-' + str(company['max_wage'])
education_cn = company['education_cn']
contents = company['contents']
area_cn = company['district_list'][0]['area_cn']
start_end_time = company['start_time'] + '——' + company['end_time']
company_info = company['company_info']['nature_cn']
print('岗位:',job_name, '工作地点:', area_cn, '薪资:', salary, education_cn)
print('公司:', company_name , company_info)
print('岗位链接:', job_url)
print('招聘时间:', start_end_time)
print('职位要求:', contents)
print(f'------------------------------------------------------{num}')
num +=1
job = {
'岗位' : job_name,
'工作地点': area_cn,
'薪资': salary,
'学历': education_cn,
'公司信息': company_name + ' ' + company_info,
'岗位链接:': job_url,
'招聘时间':start_end_time,
'职位要求': contents
}
jobs.append(job)
return jobs
if __name__ == '__main__':
get = get_guoqi_job()
get()
效果:
阿里巴巴
import requests
import json
def get_alibaba_job():
url = 'https://talent-holding.alibaba.com/position/search?_csrf=95fe7afd-a683-428d-94ea-4d8abad74ee9'
headers = {
'Host': 'talent-holding.alibaba.com',
'Cookie': (
'cna=FbAqHw6CgFYBASQOBFzhQPnx; '
'xlly_s=1; '
'XSRF-TOKEN=95fe7afd-a683-428d-94ea-4d8abad74ee9; '
'SESSION=MTc4NUU4NzM2QzY2N0YyMUMzMzBFNkI0QjA2RjBCQkU=; '
'prefered-lang=zh; '
'tfstk=fu2mfimSNSlXio-Oo8Df1UOzqVC-GEMsAPptWA3Na4uWBiaOc5mZyruxBNNYsF0uSAEA1sGiI44skjHVlA2gfkvxuAHx7OqQoqhT0PBi7kMq1S3tkVDgfyjRJ9BLcoMs_wQdpXPe1UkB_IJwWLRrYsgg0hWLcotymFSLa9di-pihjVzZgbkrD4o23qzZ44uSfc8qbKSu44iZQKoq0Qorfc-27AljNsubQ8yPoHCMjS0vJ8nmiVvtrd0gUphj8suyBd3SXjVY04vwQ8V5DeFEu6t-5x3bfm41dKMqsSzm4AXMUx4b0RluBaBKikoa5xePbIuUMrHz3WxwQuDmufejGEbo8-ZzdYlRLMqzFrEbElKNQ0UKzowqI9SInxuqE0wOPKuga5yxGATVoArobgzpaB8judiPX8R61joSq21dDf0zvvBmjgjkTGGqVmgdqgA61joSVQslqB5qg0i-u; '
'isg=BNDQjZ-KgvBCWF70uIVC5vNToR4imbTj_VG2LMqhfCvABXKvcqsWcRHz2c3l02y7'
),
'Content-Length': '200',
'Sec-Ch-Ua': '"Not)A;Brand";v="99", "Google Chrome";v="127", "Chromium";v="127"',
'Accept': 'application/json, text/plain, */*',
'Sec-Ch-Ua-Platform': '"Windows"',
'Bx-V': '2.5.11',
'Sec-Ch-Ua-Mobile': '?0',
'User-Agent': (
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/127.0.0.0 Safari/537.36'
),
'Content-Type': 'application/json',
'Origin': 'https://talent-holding.alibaba.com',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Dest': 'empty',
'Referer': 'https://talent-holding.alibaba.com/campus/position-list?campusType=internship&lang=zh',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Priority': 'u=1, i'
}
data = {
"channel": "campus_group_official_site",
"language": "zh",
"pageSize": 100,
"batchId": "",
"subCategories": "",
"regions": "",
"customDeptCode": "",
"corpCode": "",
"pageIndex": 1,
"key": "",
"categoryType": "internship"
}
response = requests.post(url, headers=headers, json=data)
res = response.json()
datas = res['content']['datas']
jobs=[]
num =1
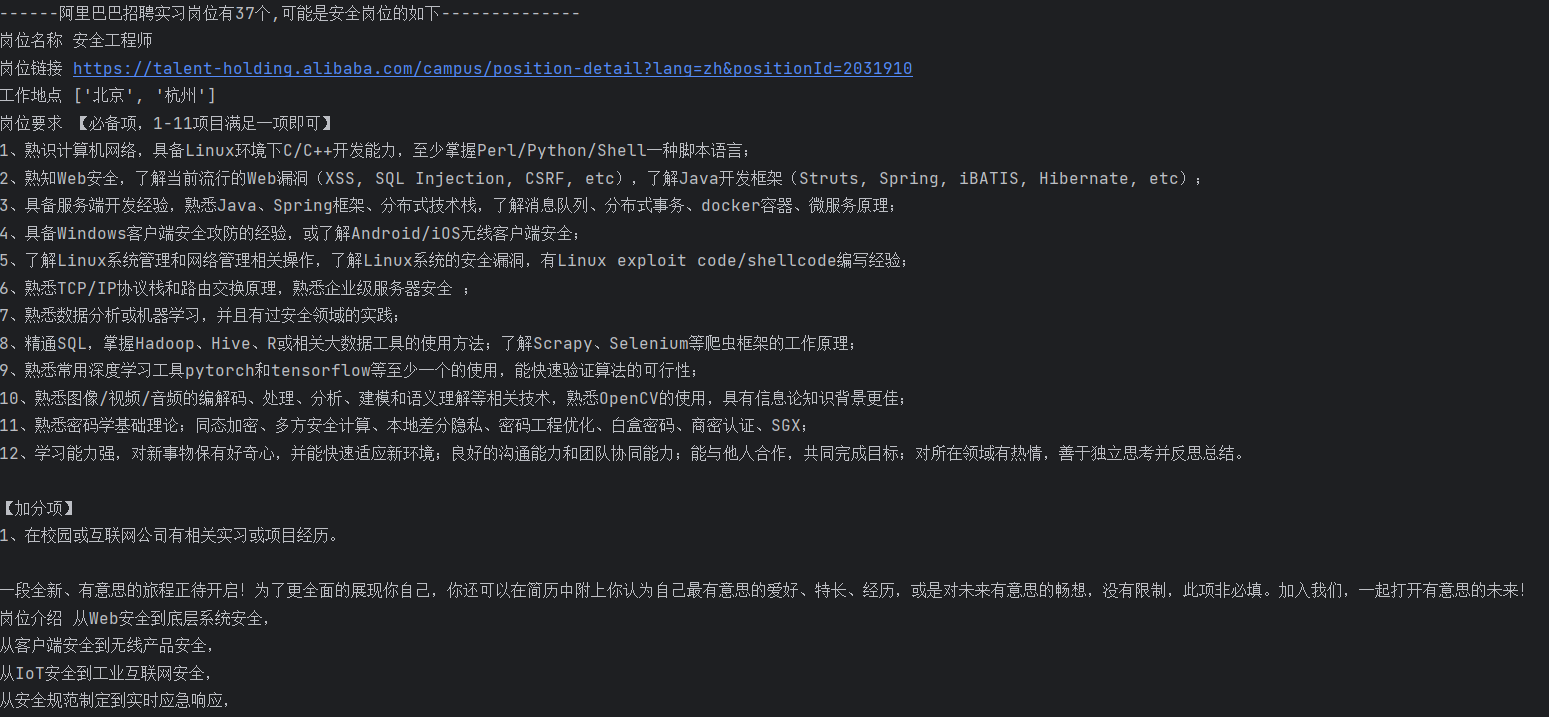
print(f'------阿里巴巴招聘实习岗位有{len(datas)}个,可能是安全岗位的如下--------------')
for data in datas:
job_name = data['name']
job_base = data['workLocations']
job_requir = data['requirement']
job_descrip = data['description']
job_id = data['id']
job_url = 'https://talent-holding.alibaba.com/campus/position-detail?lang=zh&positionId=' + str(job_id)
job ={
'岗位名称': job_name,
'岗位链接': job_url,
'工作地点': job_base,
'岗位要求': job_requir,
'岗位介绍': job_descrip,
}
if '安全' in job_name or '网络' in job_name:
for k,v in job.items():
print(k,v)
print(f'------------------------------------------------{num}')
num += 1
jobs.append(job)
return jobs
if __name__ == '__main__':
get_alibaba_job()
效果:
字节跳动
接口爬取有token验证,会过期不稳定,采用selenium爬取。模拟浏览器打开网址,再抓取最终的源码进行爬取。
from selenium import webdriver
from bs4 import BeautifulSoup
def get_ziji_job():
broser = webdriver.Chrome()
keyword = '网络%20安全%20信息'
broser.get(f'https://jobs.bytedance.com/campus/position/list?keywords={keyword}&category=&location=&project=&type=&job_hot_flag=¤t=1&limit=100&functionCategory=&tag=')
content = broser.page_source
soup = BeautifulSoup(content,'html.parser')
div = soup.find_all('div', class_ = 'listItems__1q9i5')[0]
a_s = div.find_all('a')
jobs = []
num =1
print(f'-------字节跳动共有{len(a_s)}个安全相关岗位正在招聘------------')
for a in a_s:
url_ = 'https://jobs.bytedance.com'+a['href']
job_name = a.find_all('span', class_='content__3ZUKJ clamp-content')[0].string
job_base = a.find_all('div', class_ = 'subTitle__3sRa3 positionItem-subTitle')[0].find_all('span')[0].string
job_descrip = a.find_all('div', class_='jobDesc__3ZDgU positionItem-jobDesc')[0].string
# print(url_,job_name, job_base, job_descrip)
job = {
'岗位名称': job_name,
'岗位链接': url_,
'岗位地点': job_base,
'岗位描述': job_descrip
}
jobs.append(job)
for k,v in job.items():
print(k,v)
print(f'----------------------------------{num}')
num+=1
return jobs
if __name__ == '__main__':
jobs = get_ziji_job()
print(jobs)
也有缺点就是需要打开浏览器。速度没requests快。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号