深度揭秘 HBase 协同机制:HMaster、RegionServer 与 ZooKeeper 的三角之恋
深度揭秘 HBase 协同机制:HMaster、RegionServer 与 ZooKeeper 的三角之恋
摘要:HBase 的高可用并不是单纯靠 HMaster 指挥 RegionServer 来实现的,而是依赖于 ZooKeeper 构建了一个精妙的“三角协同”体系。本文将从生命周期的维度,详细拆解 HMaster 与 RegionServer 也是如何启动、工作、以及处理故障的,并重点剖析 ZooKeeper 在其中扮演的核心角色。
1. 核心架构:由 ZooKeeper 维系的“三角关系”
在深入生命周期之前,我们需要先建立一个全局视角。HBase 的架构中,ZooKeeper (ZK) 并不是一个简单的配置中心,而是集群状态的唯一真理源(Source of Truth)。
- HMaster:通过 ZK 抢占领导权,并监听 ZK 上的节点变化来感知 RS 的动态。
- RegionServer:通过在 ZK 上注册临时节点来证明自己“活着”。
- 两者之间:HMaster 和 RegionServer 之间通过 RPC 进行具体的业务指令交互(如 Region 分配、汇报负载)。
一句话总结:“生死”看 ZK,“工作”走 RPC。
2. RegionServer 的全生命周期
RegionServer (RS) 是 HBase 中的“工人”,它的生命周期紧紧围绕着 ZooKeeper 展开。
2.1 启动阶段 (Startup)
当一个 RegionServer 进程启动时,会经历以下关键步骤:
- 连接 ZK:RS 启动后,首先连接 ZooKeeper 集群。
- 注册临时节点(关键):RS 会在 ZK 的
/hbase/rs目录下创建一个 Ephemeral Node(临时节点)。- 节点路径示例:
/hbase/rs/server1.hadoop.com,16020,12345678 - 这个节点的存在,就是 RS 的“心跳证明”。
- 节点路径示例:
- 向 Master 报到:注册完 ZK 后,RS 会通过 RPC 向 HMaster 发送
RegionServerStartup请求,告诉 Master:“我在 ZK 上注册好了,可以给我派活了”。
2.2 运行阶段 (Running)
一旦启动成功,RS 进入正常工作状态:
- 维持心跳 (ZK Session):RS 内部线程持续与 ZK 保持会话。只要网络通畅、进程不挂,
/hbase/rs下的临时节点就一直存在。 - 定期汇报 (RPC):RS 会周期性地(默认 3 秒)向 HMaster 发送
RegionServerReport。- 内容包括:内存使用率、请求 QPS、StoreFile 大小等。
- 目的:供 Master 进行负载均衡决策。
2.3 故障/下线阶段 (Failure/Shutdown)
- 正常关闭:RS 发送 RPC 告诉 Master 自己要下线,Master 会将其上的 Region 平滑迁移走,然后 RS 断开 ZK 连接,临时节点消失。
- 异常宕机:
- RS 进程崩溃,与 ZK 的 Session 超时。
- ZK 自动删除
/hbase/rs下对应的临时节点。 - Master 监听到节点删除事件,触发故障恢复流程。
3. HMaster 的全生命周期
HMaster 是集群的“大脑”,但它自身也需要通过 ZK 来确立地位。
3.1 启动与竞选 (Leader Election)
HBase 支持多 Master 高可用(Active-Standby),谁是老大由 ZK 决定。
- 争抢锁:多个 HMaster 启动时,都会尝试在 ZK 上创建同一个临时节点:
/hbase/master。 - 确立身份:
- Active Master:创建成功的那个 Master 成为主节点。
- Standby Master:创建失败的 Master 成为备用节点,并在
/hbase/master上设置 Watcher,随时准备接班。
- 初始化集群:Active Master 初始化时,会扫描 ZK 的
/hbase/rs目录,获取当前所有活着的 RegionServer 列表,并加载元数据。
3.2 运行与管理 (Coordination)
HMaster 并不主动通过网络长连接去“Ping”每一个 RS,而是利用 ZK 的事件驱动机制:
- 监听 RS 上线:Master 在
/hbase/rs目录上注册 Watcher。一旦有新节点增加,Master 就会把未分配的 Region 分给新来的 RS。 - 监听 RS 下线:一旦有节点消失,Master 收到 ZK 通知,立即将该 RS 标记为 Dead,并启动 WAL 切分(Log Splitting)和 Region 重分配。
3.3 故障转移 (Failover)
如果 Active Master 挂了:
- ZK 上的
/hbase/master临时节点消失。 - Standby Master 收到通知。
- Standby Master 再次尝试创建该节点,成功后升级为 Active Master。
- 新 Master 从 ZK 读取集群状态,恢复管理服务。
- 注意:在此期间,RegionServer 的读写服务不受影响。
4. 全流程协同图解
下面的时序图清晰展示了 HMaster、RegionServer 和 ZooKeeper 三者在生命周期中的交互:
![]()
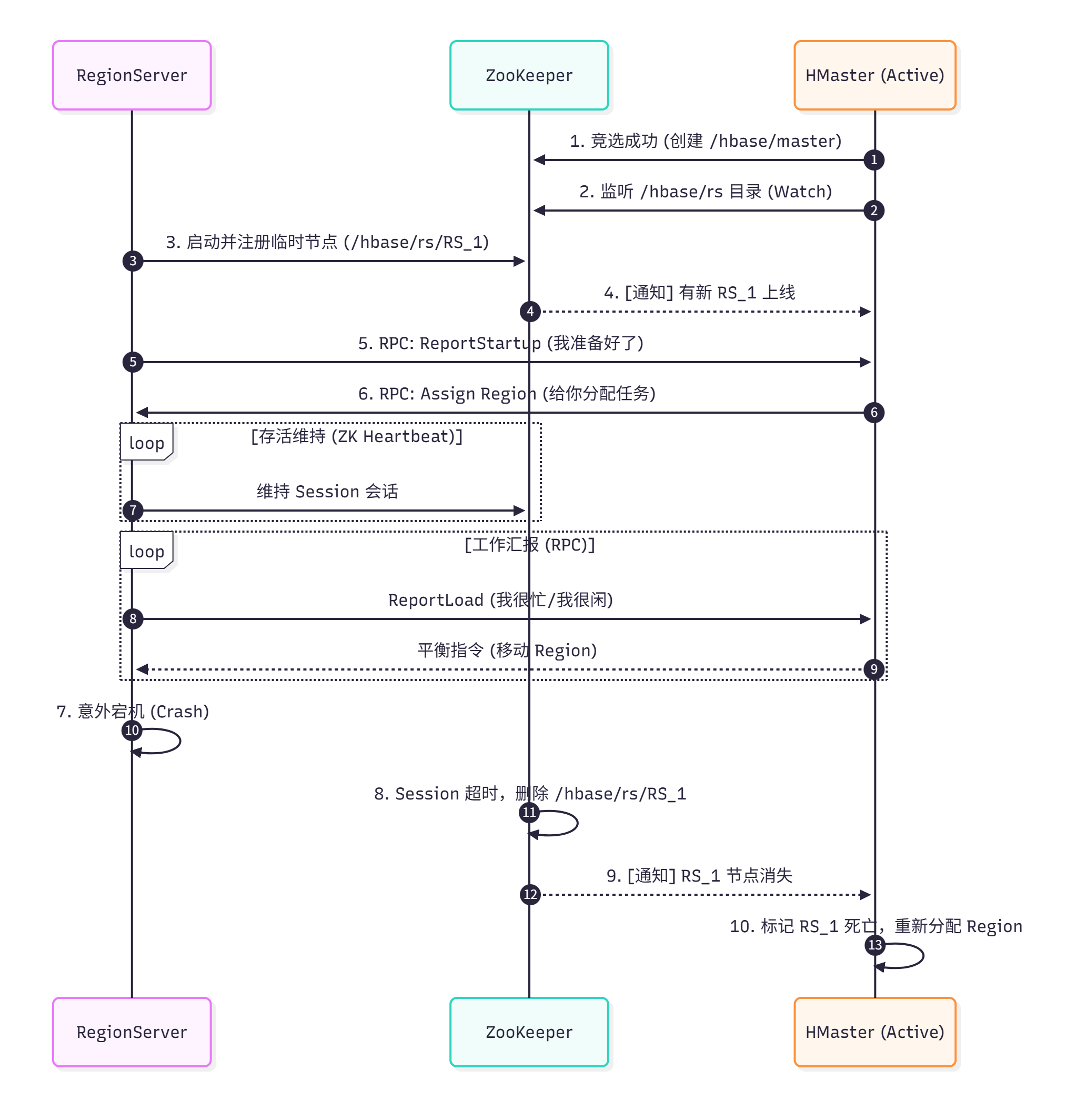
5. 总结:协同的艺术
通过上述分析,我们可以回答关于“协同”的核心逻辑:
-
关联方式:
- Master <-> ZK:竞选 Leader,监听 RS 列表变化。
- RS <-> ZK:注册临时节点,维持 Session(这是真正的“心跳”)。
- Master <-> RS:基于 RPC 的业务通信(启动汇报、负载汇报、Region 操作)。
-
为什么这样设计?
- 解耦:Master 不需要维护成千上万个 RS 的 Socket 连接来探测死活。
- 稳定性:ZK 擅长处理分布式一致性和状态监听,HBase 将“状态管理”外包给 ZK,Master 专注于“元数据管理”和“调度”。
理解了这一层生命周期关系,你就真正看懂了 HBase 能够大规模稳定运行的底层逻辑。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号