
Java并发编程-synchronized
这是Java并发编程学习的第一篇,最早在2013年时便励志要把JAVA的并发编程好好学习一下,那个时候才工作一年。后来由于各种各样的原因,未能学习起来,5年时间过去,技术止步不前,学到的都是业务领域知识,站在我个人发展角度,我希望在技术,主要是JAVA后端技术领域再往前走一步,所以在这里记录下我学习的点点滴滴,同时将代码记录在Github上。并发编程的文章主要是记录我的学习过程,应该会有很多错误的地方,也会有很多没有深度的内容,欢迎大家纠正。
1、为什么会用到synchronized
Java语言的一个高级特性就是支持多线程,线程在操作系统的实现上,可以看成是轻量级的进程,同一进程中的线程都将共享进程的内存空间,所以Java的多线程在共享JVM的内存空间。JVM的内存空间主要分为:程序计数器、虚拟机栈、本地方法栈、堆、方法区和运行时常量池。
在这些内存空间中,我们重点关注栈和堆,这里的栈包括了虚拟机栈和本地方法栈(实际上很多JVM的实现就是两者合二为一)。在JVM中,每个线程有自己的栈内存,其他线程无法访问该栈的内存数据,栈中的数据也仅仅限于基本类型和对象引用。在JVM中,所有的线程共享堆内存,而堆上则不保存基本类型和对象引用,只包含对象。除了重点关注的栈和堆,还有一部分数据存放在方法区,比如类的静态变量,方法区和栈类似,只能存放基本类型和对象引用,不同的是方法区是所有线程共享的。
如上所述,JVM的堆(对象信息)和方法区(静态变量)是所有线程共享的,那么多线程如果访问同一个对象或者静态变量时,就需要进行管控,否则可能出现无法预测的结果。为了协调多线程对数据的共享访问,JVM给每个对象和类都分配了一个锁,同一时刻,只有一个线程可以拥有这个对象或者类的锁。JVM中锁是通过监视器(Monitors)来实现的,监视器的主要功能就是监视一段代码,确保在同一时间只有一个线程在执行。每个监视器都和一个对象关联,当线程执行到监视器的监视代码第一条指令时,线程获取到该对象的锁定,直到代码执行完成,执行完成后,线程释放该对象的锁。
synchronized就是Java语言中一种内置的Monitor实现,我们在多线程的实现上就会用到synchronized来对类和对象进行行为的管控。
2、synchronized用法及背后原理
主要提供了2种方式来协调多线程的同步访问数据:同步方法和同步代码块。代码如下:
public class SynchronizedPrincipleTest { public synchronized void f1() { System.out.println("synchronized void f1()"); } public void f2() { synchronized(this) { System.out.println("synchronized(this)"); } } public static void main(String[] args) { SynchronizedPrincipleTest test = new SynchronizedPrincipleTest(); test.f1(); test.f2(); } }
f1就是同步方法,f2就是同步代码块。这两种实现在背后有什么差异呢?我们可以先javac编译,然后再通过javap反编译来看下。
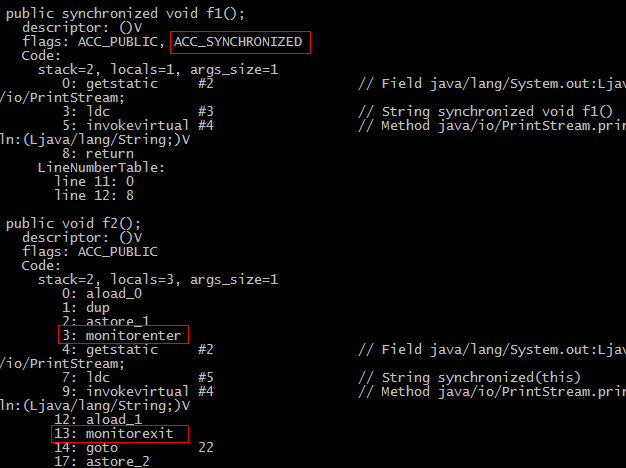
图一
从图一可以看出同步方法JVM是通过ACC_SYNCHRONIZED来实现的,同步代码块JVM是通过monitorenter、monitorexit来实现的。在JVM规范中,同步方法通过ACC_SYNCHRONIZED标记对方法隐式加锁,同步代码块则显示的通过monitorenter和monitorexit进行加锁,当线程执行到monitorenter时,先获得锁,然后执行方法,执行到monitorexit再释放锁。
3、JVM Monitor背后实现
查阅网上各种资料及翻阅openJDK代码。
synchronized uses a locking mechanism that is built into the JVM and MONITORENTER / MONITOREXIT bytecode instructions. So the underlying implementation is JVM-specific (that is why it is called intrinsic lock) and AFAIK usually (subject to change) uses a pretty conservative strategy: once lock is "inflated" after threads collision on lock acquiring, synchronized begin to use OS-based locking ("fat locking") instead of fast CAS ("thin locking") and do not "like" to use CAS again soon (even if contention is gone). ………… PS: you're pretty curious and I highly recommend you to look at HotSpot sources to go deeper (and to find out exact implementations for specific platform version). It may really help. Starting point is somewhere here: http://hg.openjdk.java.net/jdk8/jdk8/hotspot/file/87ee5ee27509/src/share/vm/runtime/synchronizer.cpp
上述表达的大致意思是同步在字节码层面就是通过monitorenter和monitorexit来实现的,可以理解为这种实现是JVM规范,一旦线程在锁获取时出现冲突,锁就会膨胀,这种膨胀是基于系统的实现(胖锁)来替代CAS实现(瘦锁)。最后给出JVM底层C++代码的链接。
查看该类代码,有如下注释:
// This is full version of monitor enter and exit. I choose not // to use enter() and exit() in order to make sure user be ware // of the performance and semantics difference. They are normally // used by ObjectLocker etc. The interpreter and compiler use // assembly copies of these routines. Please keep them synchornized.
知道这个类是所有monitor enter and exit的实现,其中方法jni_enter和jni_exit就是heavy weight monitor的实现。再看这个jni_enter方法的实现,调用了inflate方法,返回ObjectMonitor指针。
再看类ObjectMonitor,给出了具体enter和exit方法的实现。
// The ObjectMonitor class is used to implement JavaMonitors which have // transformed from the lightweight structure of the thread stack to a // heavy weight lock due to contention
与wiki.openjdk描述一致:
Synchronization affects multiple parts of the JVM: The structure of the object header is defined in the classes oopDesc and markOopDesc, the code for thin locks is integrated in the interpreter and compilers, and the class ObjectMonitor represents inflated locks.
4、锁优化
从上述中的注释我们可以看出synchronized是一种heavy weight lock,Brian Goetz在IBM developerworks的论文《Java theory and practice:More flexible, scalable locking in JDK 5.0》也比较了synchronized和ReentrantLock两者的性能,所以在JDK1.6之后对锁做了很多优化,主要有:自旋锁和自适应自旋、锁消除、锁粗化、轻量级锁和偏向锁。
4.1、自旋锁和自适应自旋
线程执行到synchronized同步方法或者代码块时,如果另外的线程已经获取到该对象的锁,该线程就只能等待,被操作系统挂起,直到另外的线程处理完成,该线程才能恢复执行。线程的挂起和恢复都需要从应用的用户态切换到操作系统的内核态才能完成,这种操作给系统也带来了性能上很大的影响。同时虚拟机的研发团队注意到在很多应用上,共享数据上的锁只会持续很短的时间,为了这点时间去挂起和恢复线程是不值得的。如果物理机上有多个CPU,那么就可以同时让多个线程并行执行,就可以在JVM的层面上让请求锁的线程“稍等一下”,但不放弃CPU的执行时间,看下持有锁的线程是否会很快就释放锁。为了让线程等待,就让线程去执行一个忙循环(自旋),这种技术就是所谓的自旋锁。举个例子,我觉得有点像,工作中我正在回复邮件,这个动作其实很快就能做完,这个时候另外一个人给我打电话,我接通了,但是我告诉他等我一下,我回复完这封邮件,咱们再交流。这个过程,回复邮件占用了我这个资源,另外一个人要和我通话,如果完全阻塞,我就不接电话直接完成回复邮件再接通电话,但是其实回复邮件只要一会儿时间,所以我接通了电话,然后对方一直在线上等占用着我的时间(他自己也一直在等我,暂时不做别的事情,忙循环),等我回复邮件完成,立马切换过来电话交流。在这个例子里面,其实我们也可以看出如果对方一直等待,如果我邮件迟迟未回复完成,对方也是一直在耗着等待且不能做其他的工作,这也是性能的浪费,这个就是自旋锁的缺点,所以自旋不能没有限制,要能做到“智能”的判断,这个就是自适应自旋的概念,自适应自旋时间不固定,是由前一次锁的自旋时间和锁的拥有者的状态决定的,如果之前自旋成功获取过锁,则此次自旋等待的时间可以长一点,否则省略自旋,避免资源浪费。同样,拿这个例子来说,如果此次对方在电话那头就等了我一小段时间,我就和对方沟通了,那么下次碰到同样的情况时,对方会继续在电话耐心的等待,否则对方就直接挂电话了(因为丧失了“信任”)。
4.2、锁消除
锁消除指的是JVM在JIT运行时,对一些代码要求同步而实际该段代码在数据共享上不可能出现竞争的锁而进行消除操作。比如代码(EascapeTest类)如下:
private static String concatString(String s1,String s2) { return s1 + s2; } public static void main(String[] args) { EascapeTest eascapeTest = new EascapeTest(); eascapeTest.concatString("a","b"); }
方法concatString,是我们在实际开发中经常会用到的一个字符串拼接的实现,从源代码层面上看是没有任何同步操作的。但实际JVM在运行这个方法时会优化为StringBuilder的append()操作,这个我们可以通过javap反编译来验证,见图二。

图二
JVM采用StringBuilder来实现,是通过同步方法来实现的,但是concatString方法中StringBuilder的对象的作用域是被限制在这个方法内部,只要做到EascapeTest被安全的发布,那么concatString方法中StringBuilder的所有对象都不会发生逸出,也就是线程安全的,对应的锁可以被消除,从而提升性能。
4.3、锁粗化
锁粗化是合并使用相同锁定对象的相邻同步块的过程。看如下代码:
public void addStooges(Vector v) { v.add("Moe"); v.add("Larry"); v.add("Curly"); }
addStooges方法中的一系列操作都是在不断的对同一个对象进行反复的加锁和解锁,即使没有线程竞争,如此频繁的同步操作也是很损耗性能的,JVM如果探测到这样的操作,就会对同步范围进行粗化,把锁放在第一个操作加上,然后在最后一个操作中释放,这样就只加了一次锁但是达到了同样的效果。
4.4、轻量级锁和偏向锁
学习轻量级锁和偏向锁之前,咱们得先来学习下Java对象模型和对象头,有了这个基础才好来理解这两个锁。
4.4.1、Java对象模型及对象头
Java虚拟机有很多对应的实现版本,本小节的内容基于HotSpot虚拟机来学习下Java对象模型和对象头。HotSpot的底层是用C++实现的,这个可以通过下载OpenJDK源代码来看即可确认。众所周知,C++和Java都是面向对象的语言,那么Java的对象在虚拟机的表示,最简单的一种实现就是在C++层面上实现一个与之对应的类,然而HotSpot并没有这么实现,而是专门设计一套OOP-Klass二分模型。
OOP:ordinary object pointer,普通对象指针,用来描述对象实例信息。
Klass:Java类的C++对等体,用来描述Java类。
之所以会这么设计,其中一个理由就是设计者不想让每一个对象都有一个C++虚函数指针(取自klass.hpp注释)。
// One reason for the oop/klass dichotomy in the implementation is // that we don't want a C++ vtbl pointer in every object. ……….
对于OOP对象来说,主要职能是表示对象的实例信息,没必要持有任何虚函数;而在描述Java类的Klass对象中含有VTBL(继承自klass_vtbl),那么Klass就可以根据Java对象的实际类型进行C++的分发,这样OOP对象只需要通过相应的Klass便可以找到所有的虚函数,就避免了给每一个对象都分配一个C++的虚函数指针。
Klass向JVM提供了2个功能:
实现语言层面的Java类;
实现Java对象的分发功能;
这2个功能在一个C++类中就能实现,前者在基类Klass中已经实现,而后者就由Klass的子类提供虚函数实现(取自klass.hpp注释)。
// A Klass provides: // 1: language level class object (method dictionary etc.) // 2: provide vm dispatch behavior for the object // Both functions are combined into one C++ class.
OOP框架和Klass框架的关系可以在oopsHierarchy.hpp文件中体现,JDK1.7和JDK1.8由于内存空间的变化,所以oopsHierarchy.hpp的实现也不一样,这里以OpenJDK1.7来描述OOP-Klass。
typedef class oopDesc* oop;//oops基类 typedef class instanceOopDesc* instanceOop; //Java类实例 typedef class methodOopDesc* methodOop; //Java方法 typedef class constMethodOopDesc* constMethodOop; //Java方法不变信息 typedef class methodDataOopDesc* methodDataOop; //性能信息数据结构 typedef class arrayOopDesc* arrayOop; //数组oops基类 typedef class objArrayOopDesc* objArrayOop; //数组oops对象 typedef class typeArrayOopDesc* typeArrayOop; typedef class constantPoolOopDesc* constantPoolOop; typedef class constantPoolCacheOopDesc* constantPoolCacheOop; typedef class klassOopDesc* klassOop; //与Java类对等的C++类 typedef class markOopDesc* markOop; //Java对象头 typedef class compiledICHolderOopDesc* compiledICHolderOop;
在Java程序运行的过程中,每创建一个Java对象,在JVM内部就会相应的创建一个OOP对象来表示该Java对象。OOP对象的基类就是oopDesc,它的代码实现如下:
volatile markOop _mark; union _metadata { wideKlassOop _klass; narrowOop _compressed_klass; } _metadata;
在虚拟机内部,通过instanceOopDesc来表示一个Java对象。对象在内部中的布局可以分为两个连续的部分:instanceOopDesc和实例数据。instanceOopDesc又被称为对象头,继承自oopDesc,看instanceOop.hpp的实现,未新增新的数据结构,和oopDesc一样,包含如下2部分信息:
_mark:markOop类型,存储对象运行时记录信息,主要有HashCode、分代年龄、锁状态标记、线程持有的锁、偏向线程ID等,占用内存和虚拟机位长一致,如果是32位虚拟机则为32位,在64位虚拟机则为64位;
_metadata:联合体,指向描述类型的Klass对象的指针,因为Klass对象包含了实例对象所属类型的元数据,故被称为元数据指针。虚拟机运行时将频繁使用这个指针定位到方法区的类信息。
到此基本描述了Java的对象头,但是这只是一部分,还有一部分是Klass,合起来才是完整的对象模型。那么Klass在对象模型中是如何体现的呢?实际上,HotSpot是这样处理的,通过为每一个已加载的Java类创建一个instanceKlass对象,用来在JVM层表示Java类。来看看instanceKlass的数据结构。
// Method array.方法列表 objArrayOop _methods; // Int array containing the original order of method in the class file (for // JVMTI).方法顺序 typeArrayOop _method_ordering; // Interface (klassOops) this class declares locally to implement.实现接口 objArrayOop _local_interfaces; // Interface (klassOops) this class implements transitively.继承接口 objArrayOop _transitive_interfaces; ………… typeArrayOop _fields; // Constant pool for this class. constantPoolOop _constants; // Class loader used to load this class, NULL if VM loader used. oop _class_loader; // Protection domain. oop _protection_domain;
可以看到一个类该有的内容,instanceKlass基本都有了。
综上,Java对象在JVM中的表示是这样的,对象的实例(instanceOopDesc)存储在堆上,对象的元数据(instanceKlass)存储在方法区,对象的引用存储在栈上。如下图:
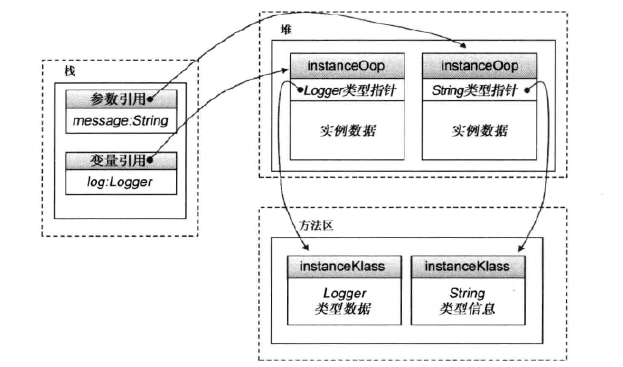
图三 取自参考资料
4.4.2、轻量级锁
轻量级锁并不是用来替代重量级锁的,它的本意是在没有多线程竞争的前提下,减少重量级锁使用操作系统互斥量产生的性能消耗。上面我们已经介绍了Java对象头(instanceOopDesc),数据结构如下:
enum { age_bits = 4, lock_bits = 2, biased_lock_bits = 1, max_hash_bits = BitsPerWord - age_bits - lock_bits - biased_lock_bits, hash_bits = max_hash_bits > 31 ? 31 : max_hash_bits, cms_bits = LP64_ONLY(1) NOT_LP64(0), epoch_bits = 2 };
此结构和网络数据包的报文头结构非常像。
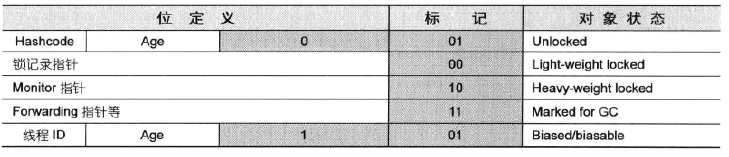
图四 取自参考资料
简单介绍完对象头的构造后,回到轻量级锁的的执行过程上。在代码进入同步块的时候,如果此时同步对象未被锁定(Unlocked,01),JVM会在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前的Mark Word的拷贝(Displace Mark Word)。然后,JVM将使用CAS操作尝试将该对象的Mark Word指向Lock Record的指针,如果这个操作成功,则线程就拥有了该对象的锁,并且对象的Mark Word状态变成(Light-weight locked,00),表示轻量级锁定。如果这个操作失败的话,JVM会先检查对象的Mark Word是不是已经指向当前栈帧,如果是则直接进入同步代码块执行,否则说明对象已经被其他线程抢占了。如果同时有两个线程以上争用同一个锁,那轻量级锁不再有效,要膨胀为重量级锁,锁标记状态更新为“10”(Heavy-weight locked),后面等待锁的线程直接进入阻塞状态。
轻量级锁的解锁过程,也是一样的,通过CAS来实现,如果对象的Mark Word仍然指向线程的锁记录,那么就用CAS操作把对象当前的Mark Word和线程复制的Displace Mark Word替换回来。
4.4.3、偏向锁
如果说轻量级锁是在无竞争的情况下使用CAS操作消除同步使用的互斥量,那偏向锁就是在无竞争的情况下将整个同步都消除掉,连CAS都不操作了。偏向的意思就是这个对象的锁会偏向于第一个获取到它的线程,如果再接下来的过程中,该锁没有被其他线程获取,则持有偏向锁的线程将永远不需要同步。
是否开启偏向锁模式,看的是参数UseBiasedLocking,这个在synchronizer.cpp文件中也可以看到。
if (UseBiasedLocking) { BiasedLocking::revoke_and_rebias(obj, false, THREAD); assert(!obj->mark()->has_bias_pattern(), "biases should be revoked by now"); }
如果启用了偏向锁,那么当锁对象第一次被线程获取的时候,JVM会把对象头的标志位置为“01”,Biased/Biasable,同时使用CAS操作把获得锁的线程ID记录在对象的Mark Word之中,如果CAS操作成功,持有偏向锁的线程以后每次进入到这个锁的相关同步块时JVM均不用再次进行同步操作。当另外有线程去尝试获取这个锁时,偏向模式宣布结束,恢复到Unlocked或者是Light-weight locked,后续的同步操作就和上述轻量级锁那样执行。
提纲:先描述了为什么会用到synchronized,再学习了同步的用法及背后的实现,最后到JVM中ObjectMonitor,这里没有分析ObjectMonitor具体是怎么做的,最后学了一下锁的优化技术。
参考资料:
https://github.com/lingjiango/ConcurrentProgramPractice
https://wiki.openjdk.java.net/display/HotSpot/Synchronization
https://stackoverflow.com/questions/26357186/what-is-in-java-object-header
https://stackoverflow.com/questions/36371149/reentrantlock-vs-synchronized-on-cpu-level
https://www.ibm.com/developerworks/java/library/j-jtp10264/
https://stackoverflow.com/questions/47605/string-concatenation-concat-vs-operator
<<HotSpot实战>>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号