redis 数据读取方式性能对比
redis 数据读取方式性能对比
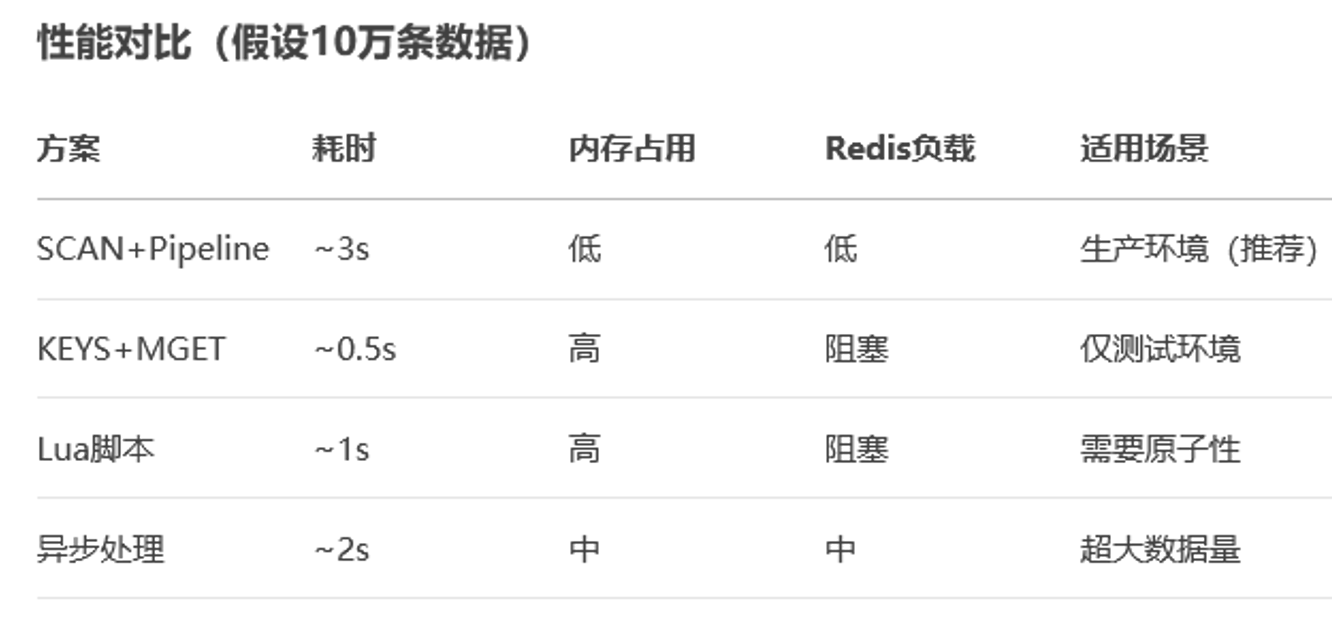
以下是快速获取 Redis 3 号数据库所有键值对的 4 种高效方案,根据数据量级和性能需求选择最适合的方式:
方案 1:SCAN + Pipeline 批量获取(推荐)
适用场景:大数据量(万级以上),不阻塞 Redis
/**
* 获取指定数据库的所有键值对(SCAN+Pipeline 安全迭代)
* @param dbIndex 数据库索引(如3)
* @return Map<key, value>(值不存在的key不会包含在结果中)
*/
public static Map<String, String> getAllValues(int dbIndex) {
Map<String, String> result = new HashMap<>();
try (Jedis jedis = selectDb(getJedis(), dbIndex)) {
String cursor = "0";
ScanParams scanParams = new ScanParams().count(500); // 每批扫描500个key
do {
// 1. SCAN获取一批key
ScanResult<String> scanResult = jedis.scan(cursor, scanParams);
List<String> keys = scanResult.getResult();
// 2. Pipeline批量获取值
Pipeline pipeline = jedis.pipelined();
Map<String, Response<String>> responses = new HashMap<>();
for (String key : keys) {
responses.put(key, pipeline.get(key));
}
pipeline.sync();
// 3. 解析结果
for (Map.Entry<String, Response<String>> entry : responses.entrySet()) {
String value = entry.getValue().get();
if (value != null) {
result.put(entry.getKey(), value);
}
}
cursor = scanResult.getCursor();
} while (!cursor.equals("0"));
}
return result;
}
优点:
-
无阻塞,适合生产环境
-
内存友好(分批处理)
调用方式:
Map<String, String> allData = JedisUtil.getAllValues(3);
方案 2:KEYS + MGET(慎用!)
适用场景:开发测试环境,数据量小(<1万)
public static Map<String, String> getAllValuesUnsafe(int dbIndex) {
try (Jedis jedis = selectDb(getJedis(), dbIndex)) {
// 1. 获取所有key(可能阻塞Redis!)
Set<String> keys = jedis.keys("*");
// 2. 批量获取值
List<String> values = jedis.mget(keys.toArray(new String[0]));
// 3. 构建键值对
Map<String, String> result = new HashMap<>();
Iterator<String> keyIter = keys.iterator();
Iterator<String> valueIter = values.iterator();
while (keyIter.hasNext() && valueIter.hasNext()) {
String value = valueIter.next();
if (value != null) {
result.put(keyIter.next(), value);
}
}
return result;
}
}
警告:
-
KEYS *会阻塞 Redis,生产环境禁用!
方案 3:Lua脚本(原子性操作)
适用场景:需要原子性获取全量数据
public static Map<String, String> getAllByLua(int dbIndex) {
String luaScript = ""
+ "local keys = redis.call('KEYS', '*') "
+ "local result = {} "
+ "for i, key in ipairs(keys) do "
+ " result[i] = {key, redis.call('GET', key)} "
+ "end "
+ "return result";
try (Jedis jedis = selectDb(getJedis(), dbIndex)) {
List<?> rawResult = (List<?>) jedis.eval(luaScript);
Map<String, String> result = new HashMap<>();
for (Object item : rawResult) {
List<?> pair = (List<?>) item;
if (pair.get(1) != null) {
result.put((String) pair.get(0), (String) pair.get(1));
}
}
return result;
}
}
特点:
-
原子性操作
-
仍会阻塞 Redis,仅适合特殊场景
方案 4:异步处理(超大数据量)
public static CompletableFuture<Map<String, String>> getAllValuesAsync(int dbIndex) {
return CompletableFuture.supplyAsync(() -> {
Map<String, String> result = new ConcurrentHashMap<>();
try (Jedis jedis = selectDb(getJedis(), dbIndex)) {
String cursor = "0";
ScanParams scanParams = new ScanParams().count(200);
do {
ScanResult<String> scanResult = jedis.scan(cursor, scanParams);
List<String> keys = scanResult.getResult();
// 并行处理每批key
keys.parallelStream().forEach(key -> {
String value = jedis.get(key);
if (value != null) {
result.put(key, value);
}
});
cursor = scanResult.getCursor();
} while (!cursor.equals("0"));
}
return result;
}, ForkJoinPool.commonPool()); // 使用公共线程池
}
适用场景:
-
超大数据量(百万级)
-
允许最终一致性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号