论文总结:Deep Model Compression-Distilling Knowledge from Noisy Teachers
- 原文:https://arxiv.org/abs/1610.09650
- 参照:Distilling the Knowledge in a Neural Network
Abstract
此文可以认为是"Distilling the Knowledge in a Neural Network"的变形,在某些地方做了延伸,某些地方做了精简,部分专业名词会略有不同,但核心思路都是认为teacher network(cumbersome model)的dark knowleges可以从logits中获得,因此要把teacher network的logits作为训练student network(small model)时的soft target。由于这两篇文章内容相近,故此文介绍会相对精简,另外,相比"Distilling the Knowledge in a Neural Network",本文作者对实验结果的总结较为清晰。
1 Introduction
如"Distilling the Knowledge in a Neural Network"提到的,模型部署时对计算资源的要求会比较严格,因此需要做模型压缩以满足要求,本文介绍一种名为teacher-student approach模型压缩方法。这种方法是使用teacher-student framework来通过pretrained teacher network提高student network的表现且使student network保持较低的复杂度,将这种算法称为teacher-student learning algorithm。
本文使用的方法与"Distilling the Knowledge in a Neural Network"中提到的方法主要区别有如下几点:
- teacher-student learning algorithm在训练student model时仅使用了soft target(logits of pretrained teacher model),并未像"Distilling the Knowledge in a Neural Network"中一样引入了hard target。
- 本文中的logits可以不仅仅来自于单独一个teacher model,而是可以由多个teacher model的logits组合而成。
- 本文相比"Distilling the Knowledge in a Neural Network",对logits做了perturbation(扰动)。
以下是该算法的一些优势:
- 对于student model,teacher model中的dark knowledge是很有效的target-cum-regularizer,将其作为训练student model时的soft target可以有效地共享一些teacher model中的有效信息。
- 相比使用hard target,soft target可以是模型训练时收敛更快。
- 通常只需要少量样本即可训练student model。
以上这些优势让我们尝试使用noisy teachers来拓展前文中的算法。
2 Student Learning using Logit Regression
以逻辑回归为例,用\(z\)表示log probability values,即logits,它是softmax输出层之前的隐含层的值。所以student model的训练集为:\(\{ (x^{(1)}, z^{(1)}), (x^{(2)}, z^{(2)}), ... , (x^{(n)}, z^{(n)}) \}\),此时训练student model时的L2 loss function为:
其中:
- \(T\)为mini-batch size。
- \(x^{(i)}\)为mini-batch中\(i^{th}\)训练样本。
- \(z^{(i)}\)为mini-batch中\(i^{th}\)训练样本所对应的pretrained teacher model中的logit(即soft target)。
- \(\theta\)为student model的参数集合。
- \(g(x^{(i)}; \theta)\)为\(x^{(i)}\)在student model所对应的logit。

现在,来建立前文提到的noisy teachers。
2.1 ‘Noisy Teachers’: Student Learning using Logit Perturbation
teacher-student framework可以很大程度上提升student model的表现,如果在此基础上让students model从多个teacher model学习呢? 在此,我们提出一种方法来模拟多个teacher model的效果,这种模拟方式是通过对teacher进行injecting noise和perturbing the logit outputs这两种操作达成的。perturbed outputs在模拟了多个teacher model的情形同时,也恰好对loss layer注入了噪音(noisy),起到了一定的正则化的效果。这样,我们就得到了noisy teacher,它可以使student model具有接近teacher model的表现,我们也称这种方法为Logit Perturbation,下面来阐述算法细节。
令\(\xi\)为元素均值为0,方差为\(\sigma\)的向量,故\(\xi\)的维度为teacher model的classes/logits的数量。令\(z^{(i)}\)为teacher model中\(x^{(i)}\)所对应的logit,现用如下公式修改\(z^{(i)}\):
其中,\(\boldsymbol{1}\)表示vector of ones 且\(i \epsilon \mathbb{R}^n\),\(n\)为class的数量。此时将\((2)\)代入\((1)\)可得:
令\(\sigma\)表示the amount of perturbation on the teacher’s original logit values \(z'^{(i)}\)。注意, 这种扰动并未施加在全部样本上。令\(\alpha\)表示一个固定的概率,并以此概率在mini-batch中随机选择样本以\((2)\)式进行扰动。
假设student model的初始化参数为\(\theta_0\),我们通过SGD对参数进行优化,\((t+1)^{th}\)次迭代,\(\theta\)按照如下公式更新:
其中,\(T = |D_t|\)是随机抽样产生的mini-batch的样本容量,\(\gamma_t\)为学习率,\(L(x, z', \theta)\)为\((3)\)式,\(\nabla_{\theta_t}[L(x, z', \theta)]\)为梯度,通过反向传播的方式计算。
总结,首先,一些样本被从mini-batch中随机抽样出来进行扰动,即通过\((2)\)式计算扰动后的logits。接着用\((3)\)式作为损失函数训练student network。
2.2 Equivalence to Noise-Based Regularization
公认的观点是,使用扰动后的数据(noisy data)有助于模型的正则化。。Bishop层证明,在损失函数中加入正则项等价于在input data中加入Gaussian noise。正则化后的损失函数为:
其中,\(x'\)为注入Gaussian noisy的\(x\),\(L(x', \theta, z)\)为noisi input data所对应的L2损失函数,\(R(\theta)\)为L2正则项。本文才用的方法为对target output \(z\) 而不是 \(x\) 注入噪声。下面证明,对 target output \(z\) 进行扰动等价于对损失函数增加一个noise-based regularization项目。由\((2)\)式可得:
因子,可以将\((3)\)式重写为:
其中:
可以将\(E_R\)理解为new regularizer that is based on the noise \(\xi\)。因此,对teacher network的logits加入扰动等价于对损失函数加入一个基于噪声\(\xi\)的正则项。
3 Experimental Results
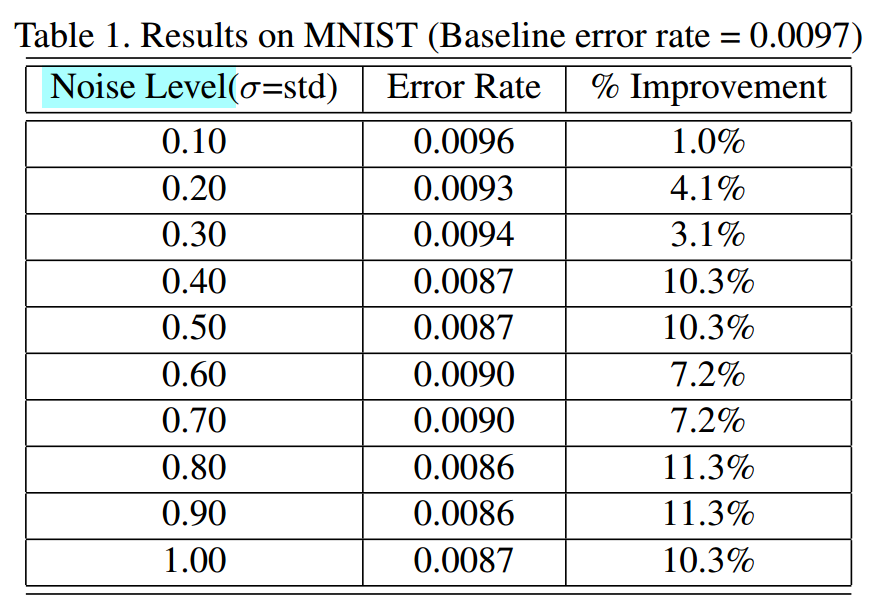
3.1 MINST
- Teacher Network: 使用LeNet,[C5(S1P0)@20-MP2(S2)]-
[C5(S1P0)@50-MP2(S2)]- FC500- FC10。 - Student Network: 使用MLP,FC800-FC800-FC10。
- 其他参数:$ \alpha = 0.15, \mu=0$, 使用不同的 $ \sigma $。
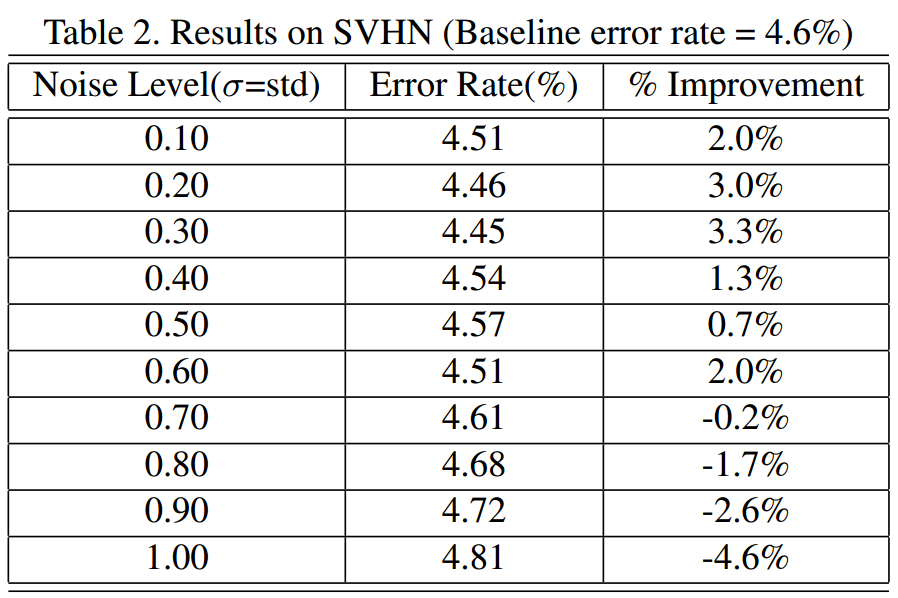
3.2 Street View House Numbers (SVHN)
SVHN数据集是由通过Google Street View收集并裁剪的房屋号组成,相比MINST,其数字的量级更大。
- Teacher Network:Network-in-Network,[C5(S1P2)@192]-
[C1(S1P0)@160]- [C1(S1P0)@96-MP3(S2)]- D0.5-
[C5(S1P2)@192]- [C1(S1P0)@192]- [C1(S1P0)@192-
AP3(S2)]- D0.5- [C3(S1P1)@192]- [C1(S1P0)@192]-
[C1(S1P0)@10]- AP8(S1)。 - Student Network:LeNet, [C5(S1P2)@32-MP3(S2)]- [C5(S1P2)@64-MP3(S2)]-
FC1024-FC10。 - 其他参数:$ \alpha = 0.15, \mu=0$, 使用不同的 $ \sigma $。
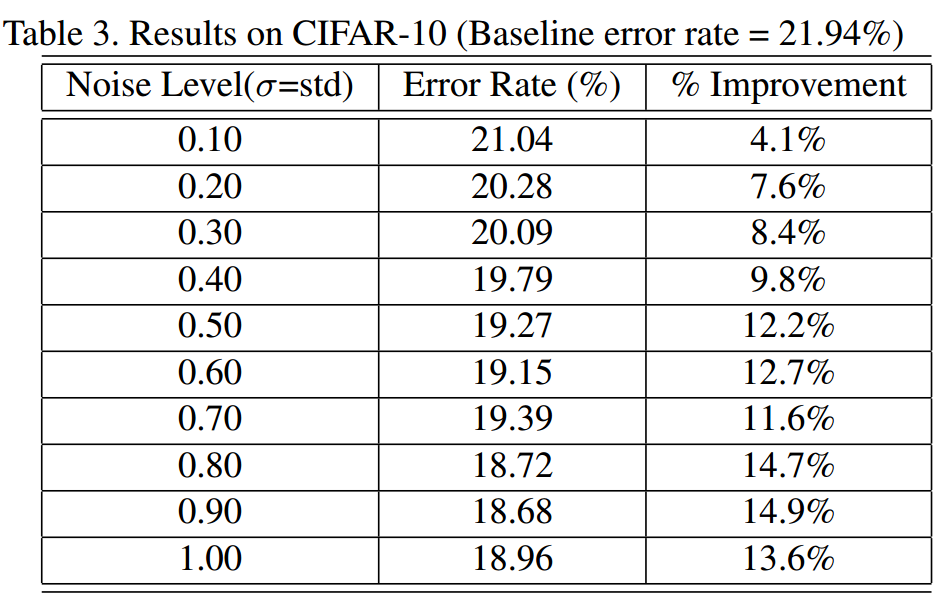
3.3 CIFAR-10
CIFAR-10是训练用作小范围图片识别模型的数据集。此处在训练之前做了训练集扩充的操作。
- Teacher Network:与SVHN相同。
- Student Network:modified LeNet,[C5(S1P2)@64-MP2(S2)]- [C5(S1P2)@128-
MP2(S2)]-FC1024-FC10。 - 其他参数:$ \alpha = 0.5, \mu=0$, 使用不同的 $ \sigma $。
4 Discussions and Analysis
本节通过分子实验结果来对比 noisy teacher 和 student regularized directly with noise及其它正则化方法。
4.1 Varying Noise in the Teacher
Noisy Teacher指对部分Teacher Network的logits加入噪声以进行扰动。在实验3.3中, $ \sigma $为变量,在此处,将 $ \sigma \(固定,调节\) \alpha$,相关结果如下:
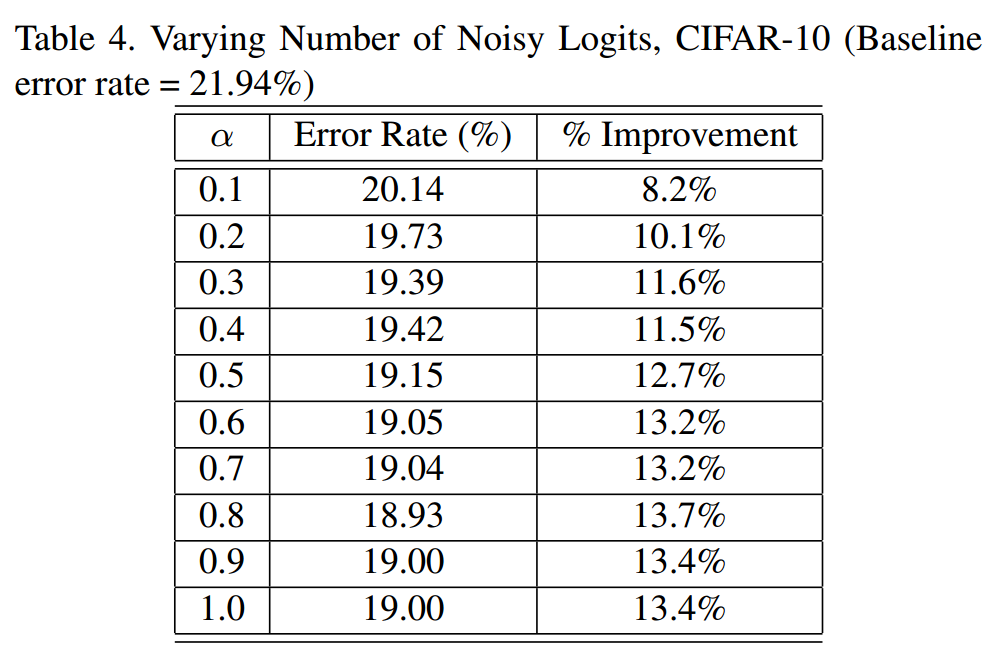
可以看出,更大的$ \alpha$同样可以帮助Student Model获得更好的表现。
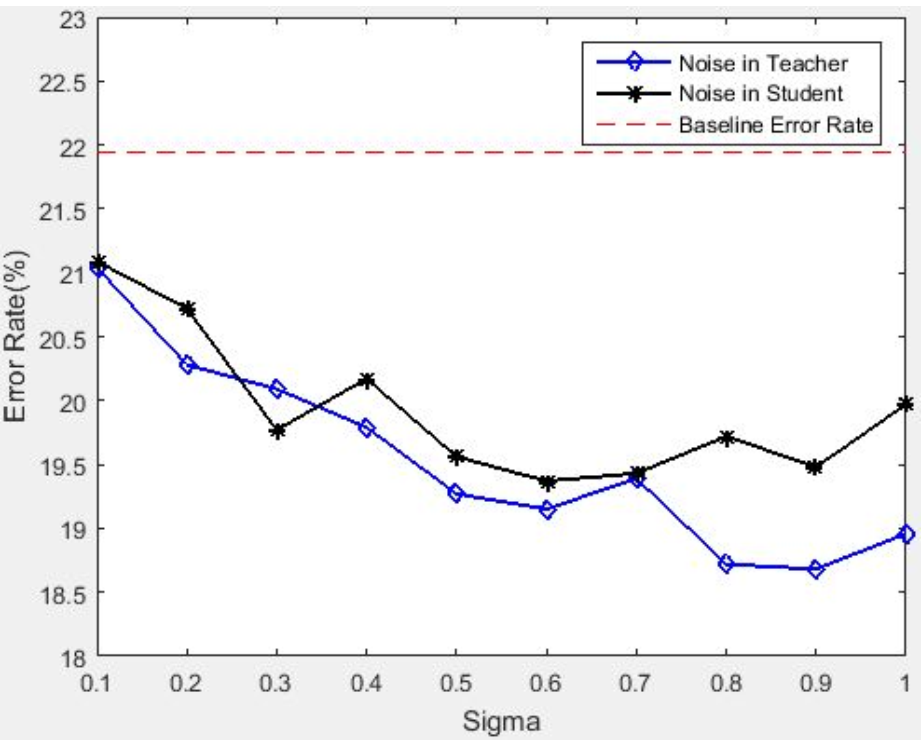
4.2 Noisy in Teacher VS Noisy in Student
Noisy in Teacher指对Teacher Network的logits加入扰动,Noisy in Student指在训练Student Network时使用一些正则化技术。本节来对这两种提高Student Network性能的方式进行对比。
4.2.1 Comparison with DropOut
结果表明,DropOut的效果弱于noisy teacher regularizer。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号