番茄小说网页端字体加密
效果
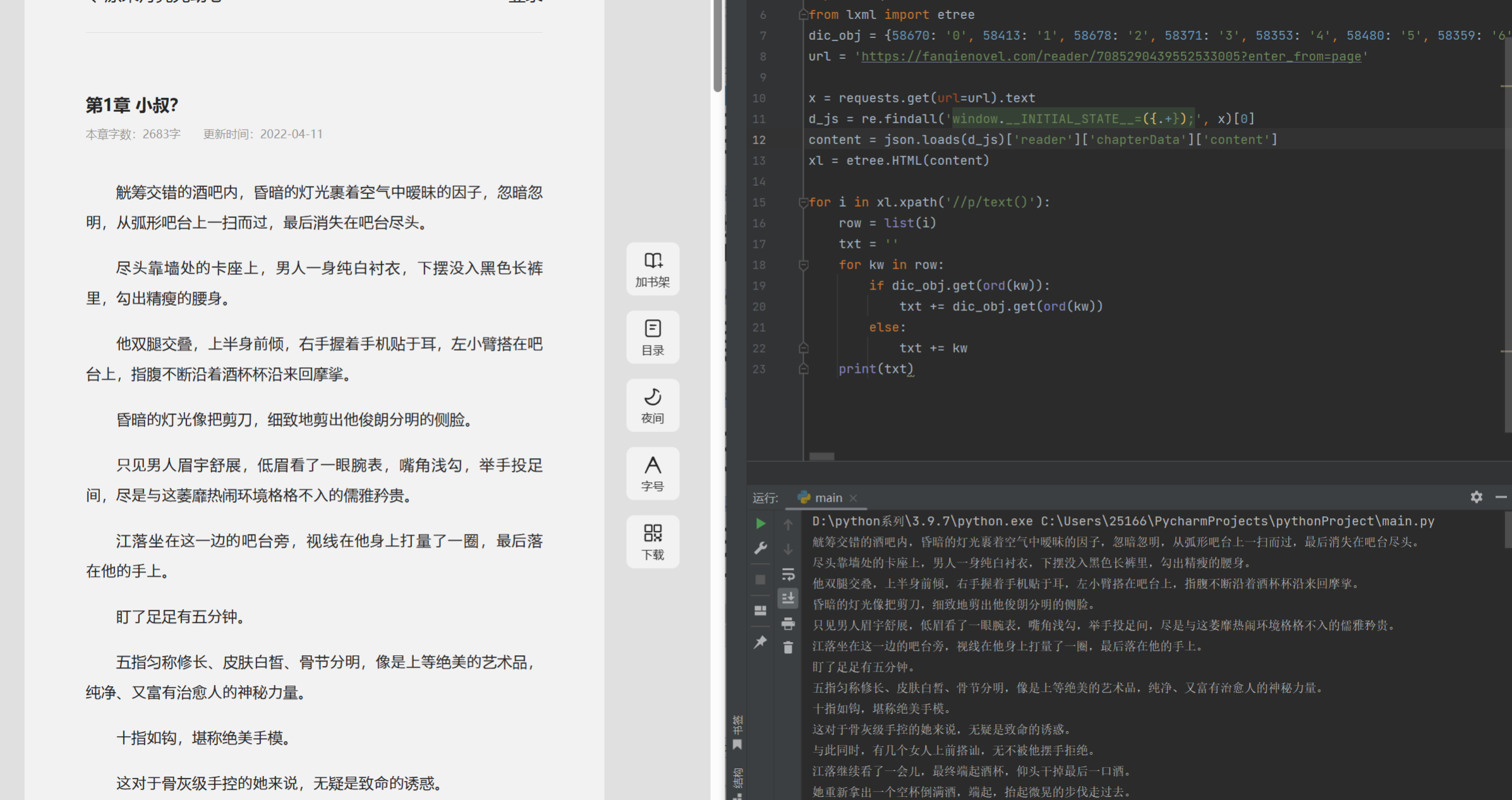
代码


import json from fontTools.ttLib import TTFont import re from lxml import etree with open('t.xml', 'r', encoding='utf-8') as fp: x = fp.read().encode('utf-8') xl = etree.HTML(x) k = {} for i in xl.xpath('//cmap/*/map'): k[int(i.xpath('./@code')[0], 16)] = i.xpath('./@name')[0] def check_word(kw): pass with open('1.html', 'r', encoding='utf-8') as fp: x = fp.read() d_js = re.findall('window.__INITIAL_STATE__=({.+});', x)[0] content = json.loads(d_js)['reader']['chapterData']['content'] xl = etree.HTML(content) for i in xl.xpath('//p/text()'): row = list(i) txt = '' for kw in row: if k.get(ord(kw)): txt += k.get(ord(kw)) else: txt += kw print(txt,row)
通过ocr识别字体的 速度有点慢 希望有大神可以推荐一个ocr识别库,这个库识别中文还有点错误
第二种方法
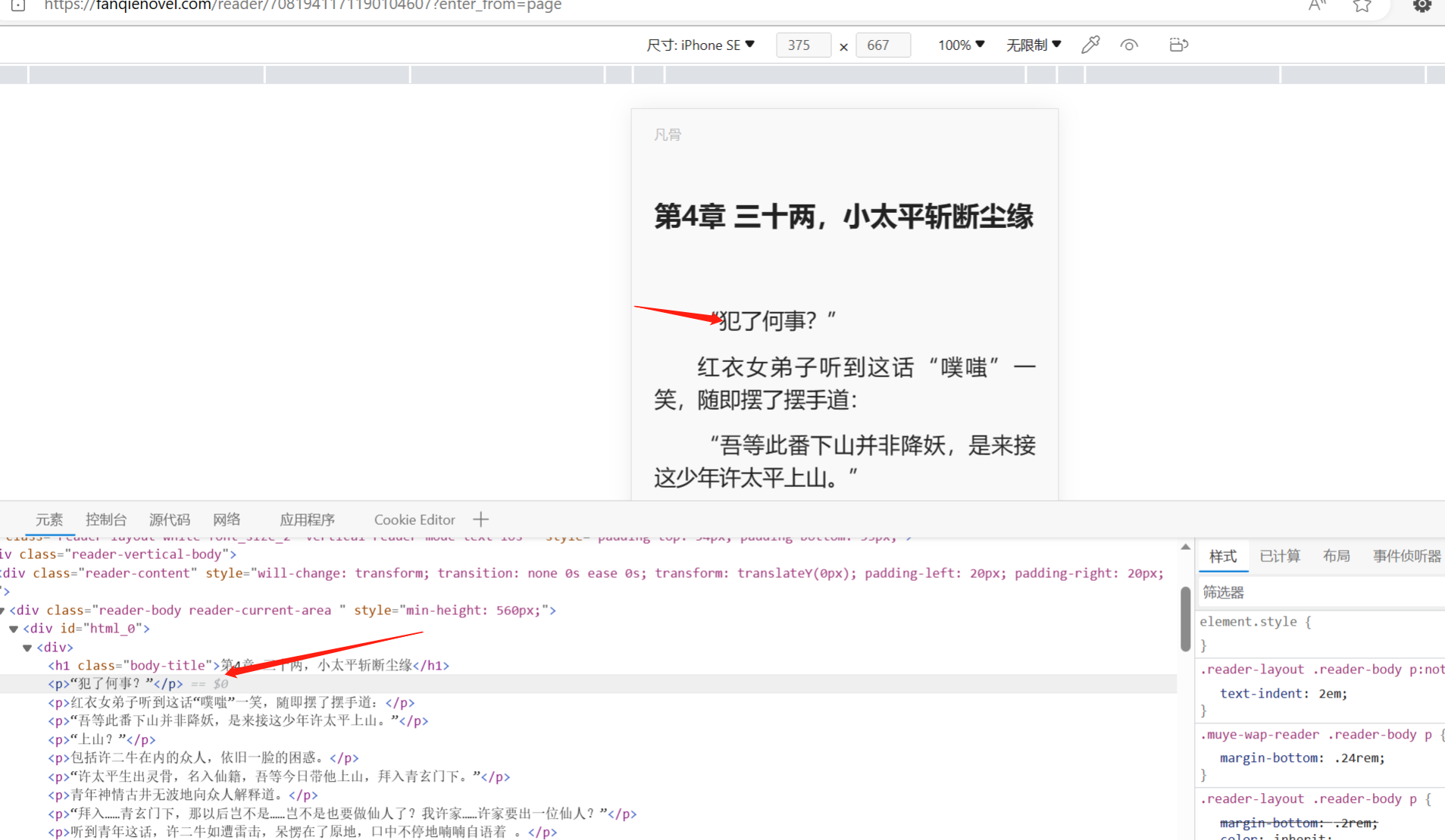
手机段无字体加密

 浙公网安备 33010602011771号
浙公网安备 33010602011771号