在第一次国赛的褒姒中入门VMpwn
VM PWN
VMpwn指的是用一个ELF实现了某些解释器性质功能的题目,这些题往往需要较强的逆向能力,需要逆向去还原题目的指令集功能以及解释器相关的结构体等
广义VMpwn
这里说广义是包括了那些单纯改变了交互方式的pwn题,即将程序的输入方式实现为一次性输入多次交互所需要的字符串/数据/选项等
这里用house of emma的来源题目作为举例
![]()
可以看到也是很熟悉的读入一次opencode,然后进入函数去处理opencode
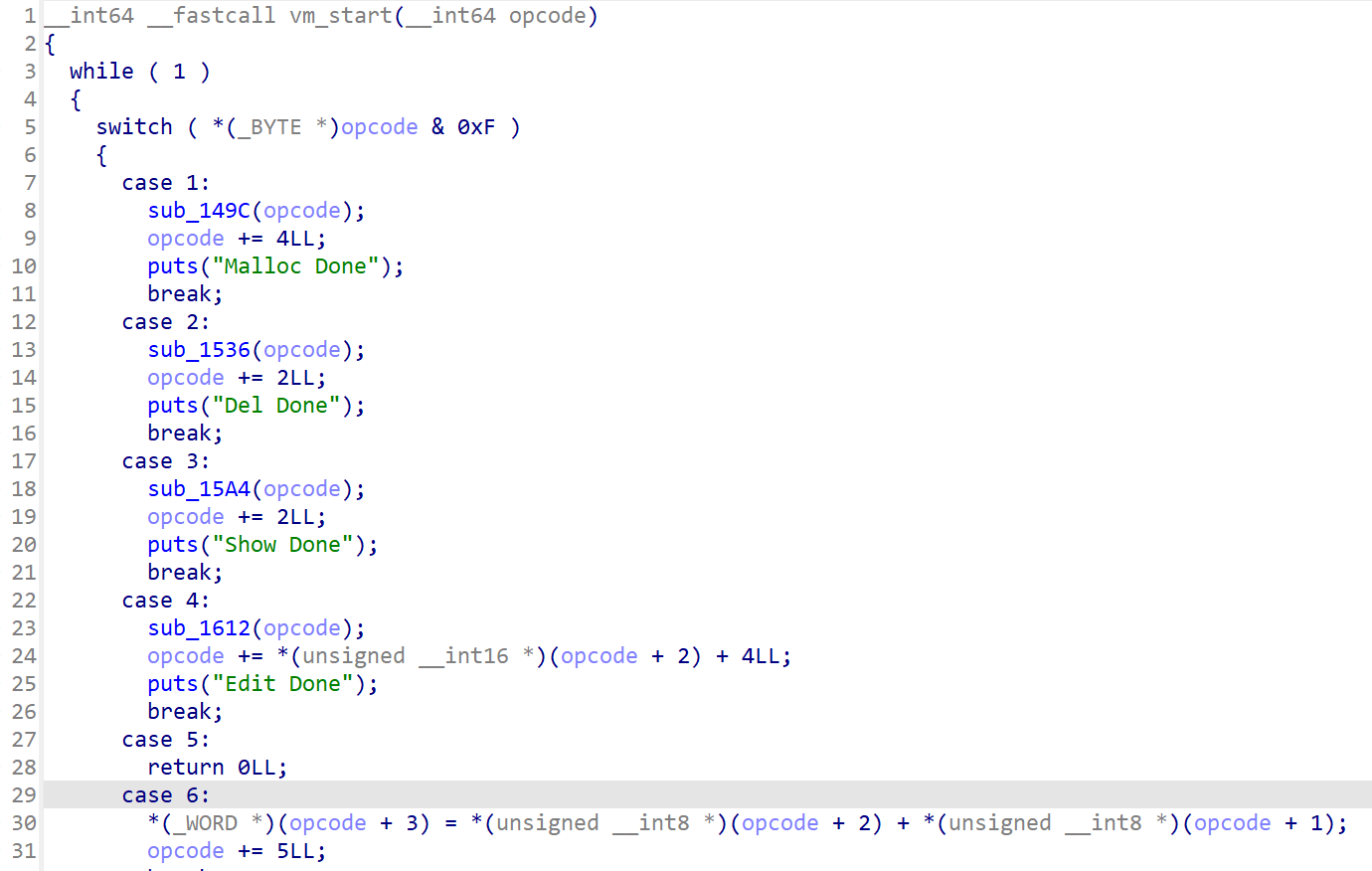
进函数后可以看到是进了一个switch去调用不同的功能,而之所以说这个题算是"广义"VMpwn是因为这个题的VM功能提供的其实依然是常见的菜单堆题里的增删改查功能,比较直观
比如第一个指令Add
![]()
这里首先是进入了Add函数去进行相关处理:
_DWORD *__fastcall Add(__int64 a1)
{
_DWORD *result; // rax
unsigned __int8 v2; // [rsp+1Dh] [rbp-13h]
unsigned __int16 v3; // [rsp+1Eh] [rbp-12h]
v2 = *(_BYTE *)(a1 + 1);
v3 = *(_WORD *)(a1 + 2);
if ( v3 <= 0x40Fu || v3 > 0x500u || v2 > 0x10u )
{
puts("ERROR");
_exit(0);
}
qword_4040[v2] = calloc(1uLL, v3);
result = dword_40C0;
dword_40C0[v2] = v3;
return result;
}
分析这段简单的Add代码可以知道,这个指令是用opencode中的一部分去进行"增"的操作,即根据size和index信息创建一个堆块,其中可以简单看出这里传进来的opcode:(a1+1)应该是index,即chunk在指针数组里的索引,占1字节;(a1+2)应该是size,即chunk的大小,占2字节;而*(a1/opcode+0)则是在外部的switch分支中使用,代表的应该是指令号,即该部分opcode要执行的功能
![]()
而进一步的,在VMpwn中我们可以在理解题目意图后还原出VM相关结构体,经过对add的逆向已经初步确定这个结构体中应该含有三个成员:指令号,index,size
在IDA中可以按 shift+F1 快捷键切到结构体视图
然后在左侧空白区域右键选择 "Add type" 即可创建新结构体
在IDA中可以很方便的使用C语言语法去还原结构体(不过貌似是9.0才有的功能来着?)
根据目前的信息可以得到这样的结构体

此时Add看起来会更加合理(在这种题目中结构体的作用其实没有那么那么关键,但在后面真正的VMpwn里还原出结构体必定会是非常必要的一个步骤)
另外也可以看到在VM主体中每次执行完指令都会将opcode指针向后移动
![]()
其移动后略过的字节就是这条指令中会用到的信息
然后再来看Edit函数去还原剩下的部分

首先可以看到Edit后的opcode指针移动是直接加了size+4的增量,算是为了防止指针移动出错
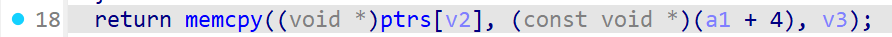
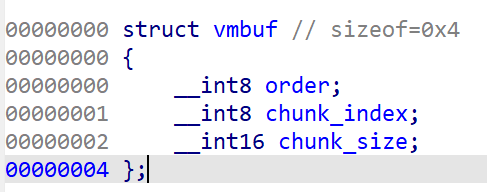
在Edit中可以看到第四个成员:写入内容
struct vmbuf
{
__int8 order;
__int8 chunk_index;
__int16 chunk_size;
char data_buf[32];//这里最后的字节数组的长度实质上取决于chunk_size的值
};
VMpwn
接下来就是"真正的"VMpwn了
实际上VMpwn更多的指的是用一个elf实现一个解释器/编译器的功能的题目,而做这种题时就需要寻找这些解释器中的漏洞
这里以ciscn2025初赛的avm题目为例子进行解析记录
结构体逆向:
unsigned __int64 __fastcall main(__int64 a1, char **a2, char **a3)
{
_BYTE s[3080]; // [rsp+0h] [rbp-C10h] BYREF
unsigned __int64 v5; // [rsp+C08h] [rbp-8h]
v5 = __readfsqword(0x28u);
sub_11E9(a1, a2, a3);
memset(s, 0, 0x300uLL);
write(1, "opcode: ", 8uLL);
read(0, s, 0x300uLL);
sub_1230(qword_40C0, s, 768LL);
sub_19F1(qword_40C0);
return v5 - __readfsqword(0x28u);
}
从打印"opcode"开始还是可以看出明显的VMpwn的特征的:输入一段opencode指令字符串,然后利用相关函数进行处理,这个函数实际上就是"解释器"了
其中两个函数往往分别起到了"初始化",“解释器”的作用
先来看初始化函数:
_QWORD *__fastcall sub_1230(_QWORD *a1, __int64 a2, __int64 a3)
{
_QWORD *result; // rax
int i; // [rsp+24h] [rbp-4h]
a1[33] = a2;
a1[34] = a3;
result = a1;
a1[32] = 0LL;
for ( i = 0; i <= 31; ++i )
{
result = a1;
a1[i] = 0LL;
}
return result;
}
这个函数看起来确实很抽象,索引很乱,加上反汇编得到的变量名完全不知所云
实际上负责初始化的函数主要是进行一些结构体的初始化操作,所以我们需要边还原结构体边看
![]() 首先是这个40c0,这里一眼顶针是VM的某种缓冲区
首先是这个40c0,这里一眼顶针是VM的某种缓冲区
改成VM_buf,进里面继续看

根据外部传参可以将init函数内改成这样:处理后的VM缓冲区,处理前的opencode缓冲,opencode字串长度
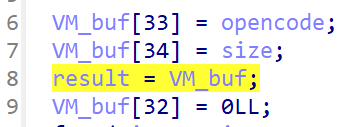
现在看起来就没有那么抽象了,首先这里之所以看起来索引指的很乱是因为VM_buf实质上是一个结构体,但IDA中没有还原结构体前都是数组形式的,所以看起来很怪
 照着这个样子看,我们能看出 VM_buf+0x110 放的是输入的opencode的指针,+0x118放的是opencode的最长长度0x300,+0x108放的是一个0
照着这个样子看,我们能看出 VM_buf+0x110 放的是输入的opencode的指针,+0x118放的是opencode的最长长度0x300,+0x108放的是一个0
所以先初步的还原一下结构体
如下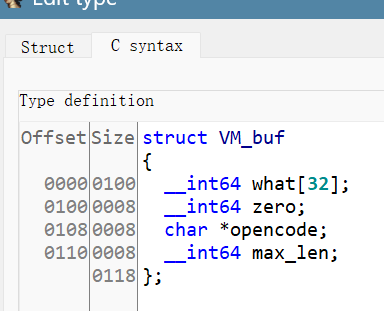
然后在函数内设置一下结构体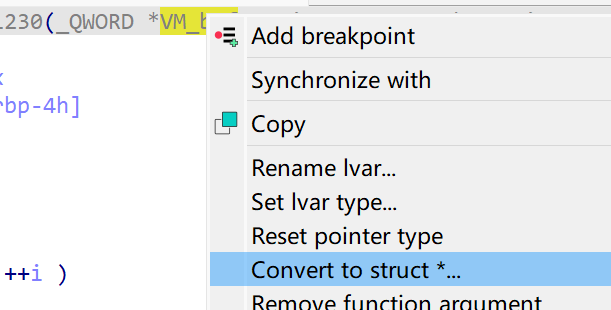
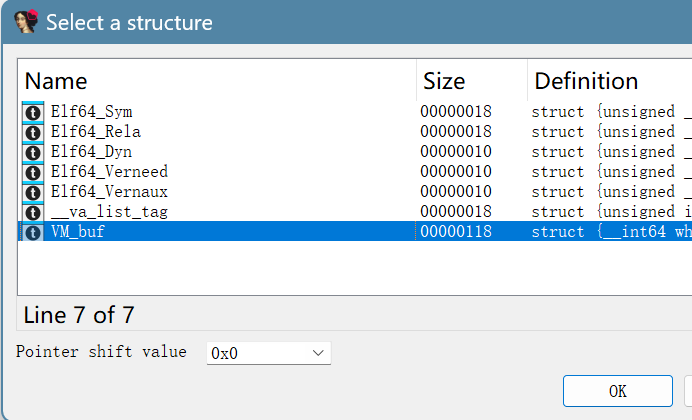
 世界都变得清晰了
世界都变得清晰了
再往下看会发现,刚才那32个不知道干嘛的8字节进行了一个清空的操作
但实际上根据一般VM题的规律是能猜到这里大概率是实现的寄存器,不然应该也能看出是一个类似于堆栈之类的缓冲区,这里就先命名为寄存器,在后面分析指令集时再进行验证
![]() 进入解释器主要逻辑所在函数
进入解释器主要逻辑所在函数
unsigned __int64 __fastcall VM_start(VM_buf *VM_buf)
{
unsigned int v2; // [rsp+1Ch] [rbp-114h]
_BYTE s[264]; // [rsp+20h] [rbp-110h] BYREF
memset(s, 0, 0x100uLL);
while ( VM_buf->zero < (unsigned __int64)VM_buf->max_len )
{
v2 = *(_DWORD *)&VM_buf->opencode[VM_buf->zero & 0xFFFFFFFFFFFFFFFCLL] >> 0x1C;
if ( v2 > 0xA || !v2 )
{
puts("Unsupported instruction");
return v4 - __readfsqword(0x28u);
}
((void (__fastcall *)(VM_buf *, _BYTE *))funcs_1AAD[v2])(VM_buf, s);
}
}
这个函数中,首先是将一个栈内的变量s的区域清空,然后验证了VM->zero(前面逆向看到的那个'0')是否小于VM_buf->max_len,小于则进入循环,同时这个条件也作为循环结构的条件,从这里能大概看出VM_buf->zero大概率是某种计数器的作用,我们先完善一下这个
然后往下看发现了这样一个表达式
high_bit = *(_DWORD *)&VM_buf->opencode[VM_buf->count & 0xFFFFFFFFFFFFFFFCLL] >> 0x1C
因为opencode是输入的指令字串,而count在作为执行计数器的同时也能起到索引的作用(因为指令是一次性输入的,所以当然要通过一个索引来找到接下来要执行的指令字串)
所以这句表达式的作用实际上就是取出当前指令的十六进制数的某一位(实际上就是最高位)
再往下看:

接下来是check了刚才取到的最高位,如果其大于或者为0就报错退出,即“high_bit“的合理值应该是1-0xa。
通过check后就将”high_bit“作为一个函数指针数组的索引去调用了一个函数,我们来看看这个数组
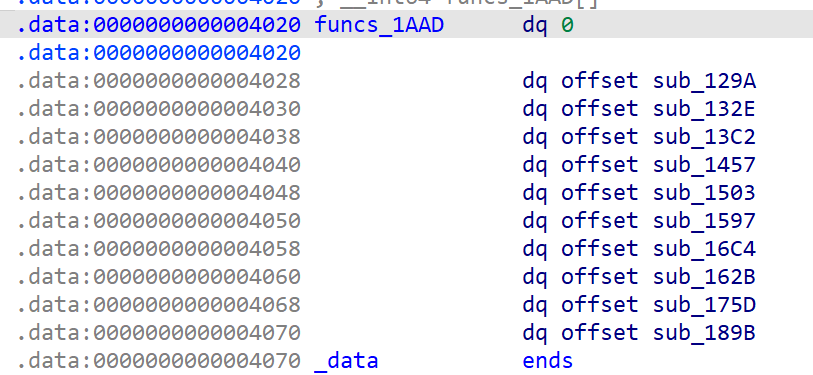 里面确实是十个函数指针
里面确实是十个函数指针
既然前面也说了VMpwn一般都是实现的一个解释器或者指令系统,那么不难猜到这十个指针应该就是这个题里的十条指令了,下一部分就需要根据这十个函数逆向出他们分别是什么指令
指令格式&指令集
第一个函数:

也是很抽象,但是不慌,我们先给他转换一下结构体
VM_buf *__fastcall sub_129A(VM_buf *vmbuf)
{
VM_buf *result; // rax
unsigned int v2; // [rsp+10h] [rbp-10h]
v2 = *(_DWORD *)&vmbuf->opencode[vmbuf->count & 0xFFFFFFFFFFFFFFFCLL];
vmbuf->count += 4LL;
result = vmbuf;
vmbuf->R[v2 & 0x1F] = vmbuf->R[HIWORD(v2) & 0x1F] + vmbuf->R[(v2 >> 5) & 0x1F];
return result;
}
也是一下就变清晰了,从这里面我们可以看出,这个指令是将我们的“寄存器”进行了加算,结果放进了第三个“寄存器”中,所以不难猜到这个函数实现的应该是一个算术加法的指令
在第6行也能看到vmbuf->count确实起到了计数器的作用,在每一个函数中都会自增4以指向下一条指令字串,同时我们也可以得知,指令字串应该是4字节长的
在第五行中用count寻址作为索引,把找到的指针传给了v2,而v2是一个四字节的变量,不难看出v2应该是当前指令用到的一部分字串,我们把它改成opcode表示它是opencode的 一部分
vmbuf->R[opcode & 0x1F] = vmbuf->R[HIWORD(opcode) & 0x1F] + vmbuf->R[(opcode >> 5) & 0x1F];
这条表达式就是这个指令的主要逻辑了,其中主要需要逆的就是索引的取值
这个函数中出现了三个索引值
目标寄存器:opcode & 0x1F ==> 第8位(最低位)
源寄存器1:HIWORD(opcode) & 0x1F ==> 第4位
源寄存器2:(opcode >> 5) & 0x1F ==> 第5、6位"中间"
首先每一个计算最后都会和0x1f进行一个按位与运算,这个0x1f其实是一个掩码,这种运算从我们熟悉的十六进制角度来看其实就是取出十六进制数的最后一位(数位不是字节位)
第一个索引比较简单,即使用opcode的最低一位为索引
第二个索引前面变成了HIWORD(),这个简单说就是截掉后4位,结合按位与就是取出第4位
第三个索引前面变成了 >>5,这个算是这个题比较麻烦的一部分,因为从十六进制考虑的话会发现它并不会和前面一样直接体现在哪一位上,但实际上只需要左移5就可以正确写入了,如果从十六进制考虑的话,这个其实就是将5、6位数的二进制值错位后的位置而已
结合前面知道的最高位(第1位)是指令号,我们可以得到这个题的指令字串格式:(在一些指令中2-4位会合并)
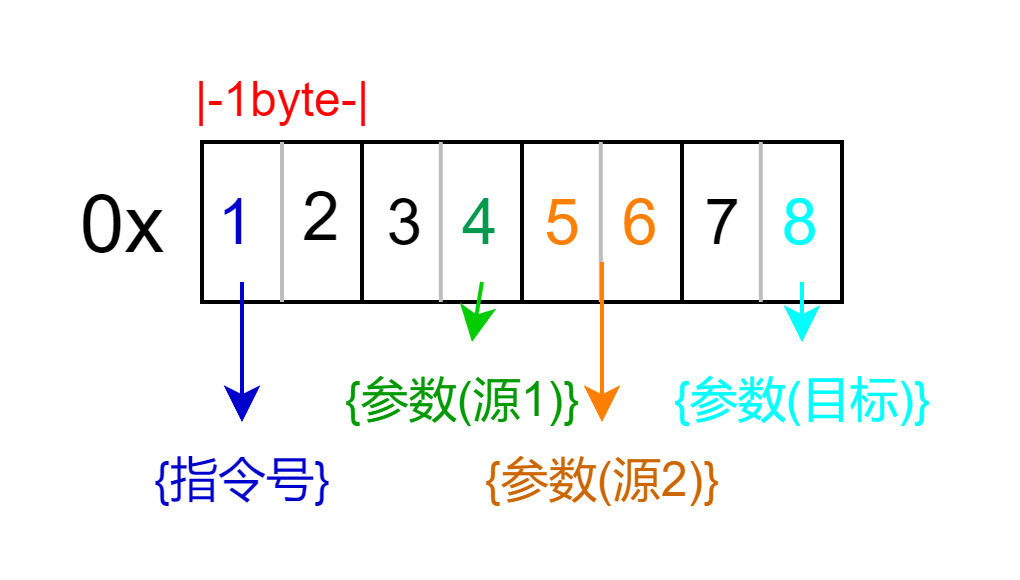
分析完指令格式后,我们可以根据指令的格式在攻击脚本中搓一个一键构造指令的代码,比如对于加法指令
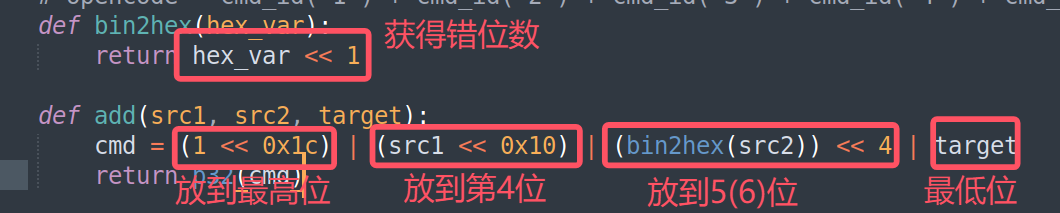
def bin2hex(hex_var):
return hex_var << 1
def add(src1, src2, target):
cmd = (1 << 0x1c) | (src1 << 0x10) | (bin2hex(src2)) << 4 | target
return p32(cmd)
即通过左移运算将各个数字参数放到它该在的位置上,形成一个4字节的指令
比如将R1+R2的结果放进R7中这样一个指令:![]()
剩余的指令就不过多赘述了,本质上就是一大顿逆向,学会一个其他的都好说
最终对于这个简单的VMpwn可以还原出的指令集和结构体:

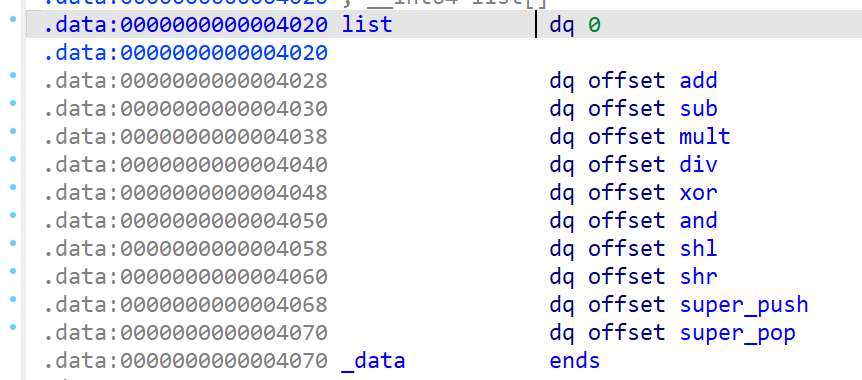
一般在VMpwn中,逆向完之后就是寻找这个解释器中的漏洞了,这个部分可能更多的会出现在一些C语言或者运算层面的逻辑错误上,在这部分笔记中就不记录了
ciscn2025初赛 avm
国赛赛中第一次见到了真正意义上的vmpwn(指这种通过结构体和代码段实现指令集效果的程序,而不单单是将输入字符直接映射为特定具体功能去执行)
做VMpwn大致需要两个步骤:
一、逆向分析程序里的指令集、结构体等信息
二、利用程序本身的功能/指令集对内存进行修改,或者寻找功能/指令集内存在的漏洞,利用漏洞进行攻击
逆向部分分在VMpwn笔记中记录,这里主要记录这个题的做法
经过逆向后大概可以得到这样的指令集和结构体
结构体:
struct vmbuf // sizeof=0x118
{
__int64 R[32]; // 视为通用寄存器,共有32个
__int64 Cmd_idx;// 计数器,每次执行指令时+4,同时作为对于指令的指针,所以命名为idx
__int64 Cmd_buf;// 指令缓冲区,实际上就是把输入点的栈地址指针传进来了
__int64 Size; // 指令缓冲的最大长度,即这个题最多执行0x300长度的指令
};
结构体逆向结果如上,其中主要就是"32个通用寄存器"
指令集:
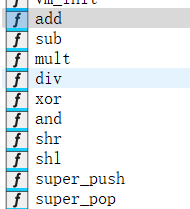
可以发现题目包括了以上指令,即基本的算术运算指令以及push和pop,不过这两个push和pop比较特殊,也是这个题的漏洞所在
而指令对应的操作码(我们需要输入的东西)的在这个题中是一个四字节八位的十六进制数,不同位代表了不同功能,大致上是:最高位为指令号,第2-4/4位为一部分操作数,第56位错位后是一部分操作数,最低位是~
其中要注重提到的是这个题在逆向中会碰到的一个问题

可以看到在add的内部实现中,是通过逐位设定"模式"的方式实现的,其中出现了一个 cmd>>5 的运算,这个应该也是题目描述中提到有错误的来源之一,或者是出题人单纯为了提高难度
如果从16进制角度考虑的话,这个题的opencode格式就是每一位数有自己的含义,而这个右移5使得56位并不是直接的映射出一个功能,而是其错位后的数字才是正确的

如图,其中位于5、6位上的操作数由于错位,不能直观的体现在16进制数上,需要错位后存储在5、6位中间
因为我是从十六进制角度构思的,这里的处理思路是先将正常数字左移1位得到错位数后再放到5、6位上
其他数则都是通过左移4的倍数放到该在的位置上的
然后再看看这个题的主要漏洞点,这个题在vmpwn中比较简单,并不需要寻找vm中的漏洞,只需要能够使用这个VM解释器即可,其中代码的问题主要出在pop和push上
这两个函数跟前面差不多,但是问题是这个题并没有创建独立的缓冲区,对于类似堆栈的需求是直接借用程序自身的栈帧来实现的,这就需要有严格的检查防止函数栈被溢出
这个题关于缓冲区的check:
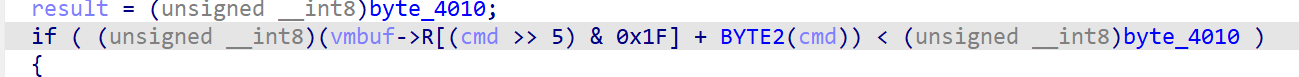
这里是将作为寻址索引的两个值进行加算得到了要pop/push的地址,然后比较是否小于0xFF,但问题是这里对于索引进行了取单字节的操作,这就导致无论实际上的操作数是多大,都会被截断后再check,也就导致这里的check失效,可以轻易的造成缓冲区溢出的问题
──────────[ REGISTERS / show-flags off / show-compact-regs off ]────
*RAX 0xff
...
*RDX 0x118
──────────[ DISASM / x86-64 / set emulate on ]────────
► 0x6256f89eb7ef cmp dl, al
汇编角度来看,即使作为被check数的rdx已经大于0xff,但写作dl被截断只剩1字节后(0x18)依然可以通过check
所以在这个题中我们就可以利用这个漏洞进行在栈上的任意地址写/读,我的思路是先泄露一个libc地址到VM寄存器中,计算转换为libc基地址,然后再通过super_push在返回地址处写ROP链进行ret2libc攻击
漏洞利用:
在这个题中刚开始时所有"通用寄存器"的内容都是0,但是这个题的指令集中又没有能够使用直接数的指令,所以在我的思路里首先是要获取一个基础数列(0,1,2,3,...)方便进行计算,那么首先是让一个"寄存器"非空,在没有任何可用有效操作数时可以直接使用super_pop指令(0xa)从栈里随便薅个数出来,然后用div(4)得到1,再通过一系列add(1)即可得到一个基础数列
opencode = p32(0xa1234567) + div(7, 7, 1) + add(1,1,2) + add(1,2,3) + add(2,2,4) + add(2,3,5) + add(3,3,6) + add(3,4,7)
opencode += add(4,4,8) + add(4,5,9) + add(5,5,10) + add(5,6,11) + add(6,6,12) + add(6,7,13) + add(7,7,14) + add(7,8,15) + sub(0,0,0)
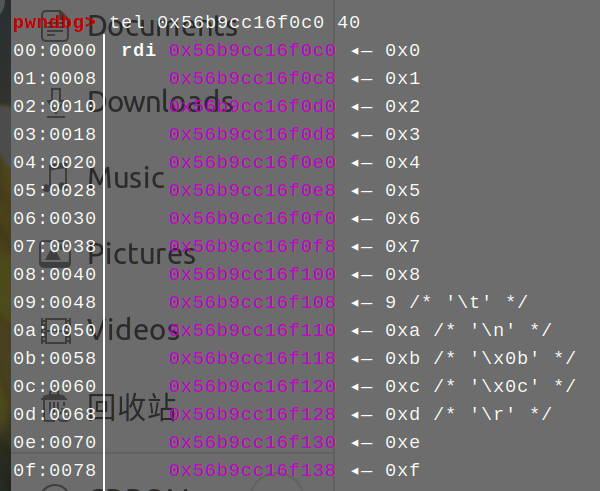
将R0-R15设置为对应的数字,转化为一些立即数来用
然后就是泄露libc了,这次有数字用了,计算出合适偏移,直接使用super_pop(a)把栈中地址转存到"寄存器"里
由于VM相关的函数栈内的一些内容都会随机化,这里可以直接去用main的start_call_main地址

偏移是0xd68,这个题不清楚为啥这个偏移需要-0x30(懒得测了awa),所以需要拿到的数是0xd38
这个题中我是直接写了个函数实现了一个专门获得需要十六进制数并放进目标寄存器的功能

直接get一个0xd38放进R16然后把libc地址提取到R31

然后可以通过右移20后左移20清空后五位得到基地址

然后继续用函数去获得gadget和函数地址的偏移地址数加算并布置ROP链即可

依然可以编写函数来简化操作(我这个写法需要手动布置第一块ROP链之后才能使用,因为push的栈地址的迭代是用已有地址偏移加算得到的)
这个题onegadget都用不了,传一个/bin/sh去调用system即可

这篇文章是由我先写好的学习笔记和题目笔记的两部分拼接而成,加上编写的时间跨度有点大,导致阅读起来可能有些割裂,但是还是想掏出来水篇博客awa~
如果能帮到一些师傅,那也是非常高兴了,祝大家越来越强~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号