Decision Transformer: Reinforcement Learning via Sequence Modeling
发表时间:2021
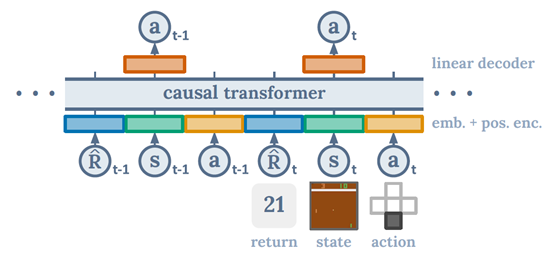
文章要点:这篇文章提出了一个Decision Transformer的模型,在offline RL的设定下,不用RL的方法学value function,也不需要做policy improvement,就可以达到甚至超过offline RL baseline。具体做法很简单,就是用transformer去拟合数据,数据结构如下

这里的R不是reward,是return,具体来说应该是reward-to-go-return。这个transformer好像具有自己从数据中发现规律的能力,不需要做batch RL里面的policy improvement就能找到更优的策略(Thus, by combining the tools of sequence modeling with hindsight return information, we achieve policy improvement without the need for dynamic programming.)。然后用的时候,需要输入target_return,就是你想达到的累计回报。所有输入为
R, s, a, t, done = [ target_return ], [env. reset ()] , [], [1] , False
然后就输出这个target return对应的动作。然后执行动作得到下一个状态和reward,计算剩下的return,再把新的数据输入得到下一个动作,以此类推。

文章开头还举了个例子来说明这个问题的直觉解释
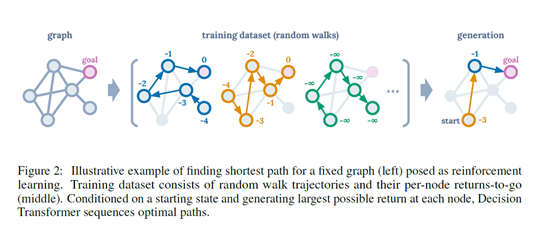
大概就是说对一个图来找最短路径。我们有的是random walk的轨迹,然后transformer拟合这些轨迹后就能从中找到一条到达目标的最优轨迹。
总结:这篇文章其实是有点玄幻的。虽然你是transformer,但是拟合就是拟合,难道真的网络已经有了很强大的推理能力了吗?应该最多只能达到和dataset里最好的trajectory的效果,这才是make sense的。会不会是刚好样本里面就有这么一条好的轨迹,拟合之后就刚好能输出对应的动作呢?至于为什么会超过offline RL baseline,就如文章所说,是不是可能是error propagation and value overestimation的锅,如果是的话,调调参是不是baseline的效果就上去了?毕竟传统的offline RL还有个policy improvement的步骤,再差也不至于比imitation差吧。
疑问:不懂transformer的原理,不知道为啥他可以效果这么好,难道这不就是一个imitation learning吗,为啥效果可以超过batch RL的算法?causal self-attention mask是啥,难道效果好是因为这个?感觉需要了解一下transformer了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号