并发编程 07.02
1.并发编发
串行:程序自上而下,按顺序执行,必须把当前任务执行完毕才能执行下一个任务,不计较时间成本。
并发:多个任务同时被执行;并发编程指的是编写支持多任务并发的程序。
串行和并发都是程序处理任务的方式。
并行:真正的同时运行,必须具备多核CPU,有几个核心就可以多并行几个任务,当任务数量超过核心数时还是并发执行。
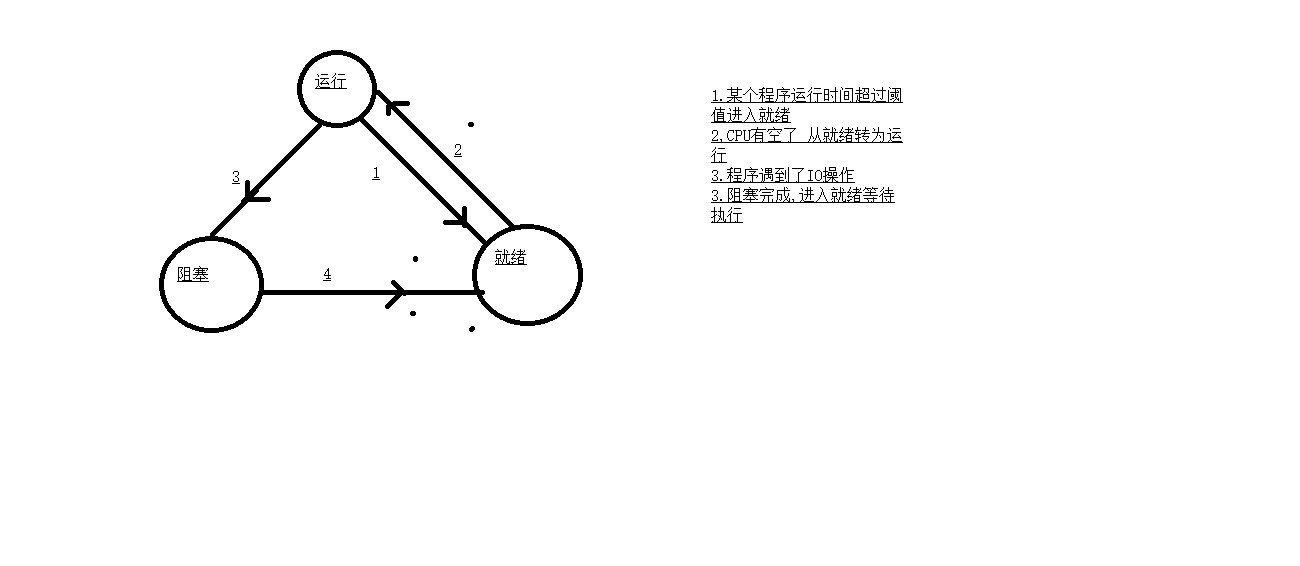
阻塞:指的是程序遇到IO操作,无法继续执行代码时的一种状态
input()默认为阻塞
非阻塞:指的是程序没有遇到IO操作的一种状态
一个进程的三种状态:阻塞、运行、就绪
实现并发的方式:
- 多进程
- 多线程
- 协程
进程:正在运行的程序,是操作系统以及进行资源分配的基本单位
进程的由来:当把一个程序从硬盘读入到内存时,进程就产生了
多进程:同一时间有多个程序被装入内存并执行,进程来自于操作系统,有操作系统进行调度以及资源分配;多进程的原理就是操作系统调度进程的原理。
操作系统:可以当成一款特殊的软件
主要功能:
- 隐藏了硬件系统的复杂性的操作,提供了简单直观的API接口
- 将硬件的竞争变的有序可控
与普通软件的区别:
- 操作系统可以直接与硬件交互
- 操作系统是受保护的,不能直接被修改
- 操作系统更加长寿,一旦完成基本不会被修改,如内核系统
操作系统的发展史
第一代计算机(真空管和穿孔卡片)特点:
- 没有操作系统概念,所有程序设计都是直接操控硬件
第二代计算机(晶体管和批处理系统)的缺点:
- 需要人为参与;任务串行执行;程序员调试效率低。
第三代计算机(集成电路芯片和多道程序设计)的特点:
- 使用了SPOOLING联机技术,避免了二代计算机的缺点;使用了多道技术;采用了多个联机终端+多道技术
第四代计算机(个人计算机):
- 大规模集成电路+多用户终端系统
- 体积降低,成本降低,可视化界面
- 大多具备GUI界面,可供普通用户使用
多道技术:
实现原理:
- 空间复用 同一时间加载多个任务到内存中去,多个进程之间内存区域需要相互隔离,这种隔离是物理层上的隔离,其目的是保证数据的安全
- 时间复用 时间复用指的是操作系统会在多个进程之间做切换执行
切换任务的两种情况:
- 当一个进程遇到IO操作时会自动切换
- 当一个任务执行时间超过阈值会强制切换
- 注意点:在切换前必须保存状态,以便后续恢复执行,频繁切换也会占用资源
- 当所有任务都没有IO操作时,切换执行效率反而降低,但是为了保证并发执行,必须牺牲效率
进程的创建和销毁
创建:
- 用户的交互式请求,双击鼠标;
- 由一个正在运行的程序,调用开启进程的接口 subprocess
- 一个批处理作业的开始
- 系统初始化
销毁:
- 任务完成,自愿退出
- 强制结束 taskkill
- 程序遇到了异常
- 发生严重错误,如访问了不该访问的内存
进程和程序:
程序是一堆代码放在一个文件中,通常后缀为exe
进行是由启动程序产生的,一个程序可以产生多个进程,每个进程都具有一个PID进程编号,且唯一
PID & PPID
PID:当前进程的编号;
PPID:是当前程序父进程的编号
访问PID & PPID:
import os:
os.getpid()
os.getppid()
进程的层次结构:
在Linux中进程具备父子关系,是一个树状结构,可以互相查找到对方
在Windows中没有层级关系,父进程可以将子进程的句柄转让
在python中实现多进程:
#方式一(实例化Process类):
from multiprocessing import Process
import time
def task(name):
print('%s is running'% name)
time.sleep(3)
print('%s is done'% name)
if __name__ == ‘__main__’:
#在Windows系统中,开启子进程的操作一定要放到这下面
#Process(target=task,kwargs={'name':'nick'})
p = Process(target=task,args=('jack',))
p.start()# 向操作系统发送请求,操作系统会申请内存空间,然后把父进程的数据拷贝给子进程,作为子进程的初始状态
print('主进程')
#方式二(继承Process类 并覆盖run方法):
from multiprocessing import Process
import time
class MyProcess(Process):
def __init__(self,name):
super(MyProcess,self).__init__()
self.name = name
def run(self):
print('%s is running'%self.name)
time.sleep(3)
print('%s is done' % self.name)
if __name__ == ‘__main__’:
p = MyProcess('jack')
p.start()
print('主进程')
linux 与windows开启进程的方式不同
linux 会将父进程的内存数据 完整copy一份给子进程
注意:
-
在windows下 开启子进程必须放到
__main__下面,因为windows在开启子进程时会重新加载所有的代码造成递归创建进程 -
第二种方式中,必须将要执行的代码放到run方法中,子进程只会执行run方法其他的一概不管
-
start仅仅是给操作系统发送消息,而操作系统创建进程是要花费时间的,所以会有两种情况发送
3.1开启进程速度慢于程序执行速度,先打印”主“ 在打印task中的消息
3.2开启进程速度快于程序执行速度,先打印task中的消息,在打印”主
#进程之间内存相互隔离
from multiprocessing import Process
import os, time
a = 257
def task():
global a
a = 200
if __name__ == '__main__':
p = Process(target=task)
p.start() #开启进程,向操作系统发送指令
time.sleep(4)
print(a)
join函数:
from multiprocessing import Process
import time
def task1(name):
for i in range(10000):
print("%s run" % name)
def task2(name):
for i in range(100):
print("%s run" % name)
if __name__ == '__main__': # args 是给子进程传递的参数 必须是元组
p1 = Process(target=task1,args=("p1",))
p1.start() # 向操作系统发送指令
# p1.join() # 让主进程 等待子进程执行完毕在继续执行
p2 = Process(target=task2,args=("p2",))
p2.start() # 向操作系统发送指令
p2.join() # 让主进程 等待子进程执行完毕在继续执行
p1.join()
#需要达到的效果是 必须保证两个子进程是并发执行的 并且 over一定是在所有任务执行完毕后执行
print("over")
from multiprocessing import Process
import time
def task1(name):
for i in range(10):
print("%s run" % name)
if __name__ == '__main__': # args 是给子进程传递的参数 必须是元组
ps = []
for i in range(10):
p = Process(target=task1,args=(i,))
p.start()
ps.append(p)
for i in ps:
i.join()
print("over")
进程对象的常用属性:
from multiprocessing import Process
if __name__ == '__main__':
p = Process(target=task,name='nick')
p.start()
p.join()
prinr(p.name)
p.daemon #守护进程
p.join()
print(p.exitcode)# 获取进程的退出码 就是exit()函数中传入的值
print(p.is_alive())#查看进程是否活着
print('zi',p.pid)# 查看子进程
print(os.getpid())
p.terminate()#终止进程与strat相同的是不会立即终止,因为操作系统有很多事情要做
print(p.is_alive())
僵尸进程与孤儿进程
- 孤儿进程:父进程已结束运行,但子进程仍在运行,尤其存在的必要性,无不良影响
- 僵尸进程:当一个进程已经结束了但是,它仍然还有一些数据存在 此时称之为僵尸进程
在linux中,有这么一个机制,父进程无论什么时候都可以获取到子进程的的 一些数据
子进程 任务执行完毕后,确实结束了但是仍然保留一些数据 目的是为了让父进程能够获取这些信息
linux中 可以调用waitpid来是彻底清除子进程的残留信息
python中 已经封装了处理僵尸进程的操作 ,无需关心

 浙公网安备 33010602011771号
浙公网安备 33010602011771号