

数据结构基础知识
什么是数据结构?
数据结构是计算机存储、组织数据的方式。
为什么需要数据结构?
数据是程序的核心要素,因此数据结构的价值不言而喻。在不同的场景下,数据需要以特定的方式存储,我们有不同的数据结构可以满足我们的需求。
8中常用的数据结构
数组、栈、队列、链表、图、树、前缀树、哈希表
1.数组
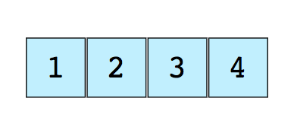
例如上图展示了1个数组,其中包括4个元素。
每一个数组元素的位置由数字编号,称为下标或者索引。大多数编程语言的数组第一个元素的下标是0。
根据维度区分有两种不同的数组:
A.一维数组(上图)
B.多维数组
数组的基本操作
Insert-在某个索引处插入元素
Get-读取某个索引处的元素
Delete-删除某个索引处的元素
Size-获取数组的长度
2.栈
栈中的元素采用Last In First Out,即后进先出

上图中的栈有三个元素,其中”3“在最上面,因此它会被第一个移除
(例如,常用的撤回功能Ctrl+z,实际上是把之前的应用状态保存到内存中,最近的状态放到第一个,这就是栈的一个简单应用)
栈的基本操作
Push:在栈的上方插入元素
Pop:返回栈最上方的元素,并将其删除
isEmpty:查询栈是否为空
Top:返回栈最上方的元素,并不删除
3.队列
队列与栈类似,都是采用线性结构存储数据。他们的区别在于,栈采用先进后出的方式,而队列是先进先出,即First in First Out。
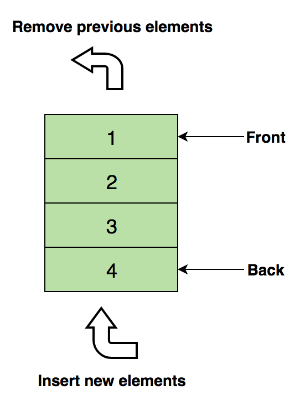
上图展示的是一个队列,1是最上面的元素,它会被第一个移除。
队列的基本操作
Enqueue-在队列末尾插入元素
Dequeue-将队列第一个元素删除
isEmpty-查询队列是否为空
Top-返回队列的第一个元素
4.链表
链表也是线性结构,它和数组看起来很像,但它们的内存分配方式、内部结构和插入删除操作方式都不一样。
链表是一系列节点组成的链,每一个节点保存了数据以及指向下一个节点的指针。链表头指针指向第一个节点,如果链表为空,则头指针为空或者为null。
链表可以用来实现文件系统、哈希表和邻接表。

上图展示了一个链表,它有3个节点
链表分为两种:
单向链表
双向链表
链表的基本操作
InsertAtEnd-在链表结尾插入元素
InsertAtHead-在链表开头插入元素
Delete-删除链表的指定元素
DeleteAtHead-删除链表的第一个元素
Search-在链表中查询指定的元素
isEmpty-查询链表是否为空
5.图
图由多个节点构成,节点之间可以互相连接组成一个网络。(x,y)表示一条边,它表示节点x与y相连。边可能由权值。
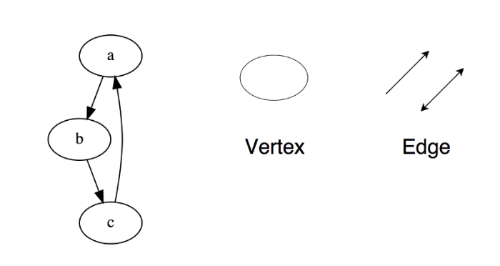
图分为两种:
有向图
无向图
在编程语言中,图有可能有以下两种形式表示:
邻接矩阵
邻接表
遍历图有两种算法
广度优先搜索
深度优先搜索
6.树
树是一个分层的数据结构,由节点和连接节点的边组成。树是一种特殊的图,它与图最大的区别就是没有循环。

树有很多分类:
1.二叉树
A.完全二叉树:若设二叉树的高度为h,除第h层外,其他各层(1~h-1)的结点树都达到最大个数,第h层有叶子节点,并且叶子结点都是从左到右依次排布,这就是完全二叉树。

四种常见遍历方法:
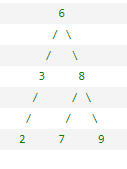
中序遍历:左-根-右,例如图中的遍历结果:D->B->E->A->C
先序遍历:根-左-右,例如图中的遍历结果:A->B->D->E->C
后序遍历:左-右-根,例如图中的遍历结果:D->E->B->C->A
层序遍历:即从第一层开始,逐层遍历,每层遍历按照从左到右遍历。例如图中的遍历结果:A->B->C->D->E
B.满二叉树:除了叶节点之外每个结点都有左右子叶并且叶子节点都处在最底层的二叉树。

C.平衡二叉树:平衡二叉树是一棵二叉排列树,它是一棵空树,或者它的左右两个子树的高度差绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
D.完全二叉树:叶节点只能出现在最下层和次下层,并且最下面一层的结点都集中在该层最左边的若干位置的二叉树。
E.二叉搜索树:对于任意一个结点,其值不小于左子树的任何结点,且不大于右子树的任何结点(反之亦可),则为二叉搜索树。如果按照中序遍历,其遍历结果是一个有序序列。
F.堆
最小堆:每一个节点的值都小于或等于其两个子节点的值
最大堆:每一个节点的值都大于或等于其两个子节点的值
红黑树:是一种近似平衡的二叉搜索树,最坏情况下时间复杂度O(log(n))
红黑树的特点
1.节点是红色或黑色。
2.根节点是黑色。
3.每个叶子节点都是黑色的空节点(NIL节点)。
4 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
5.从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
B树:
由于树的查询效率高,数据库索引会使用树结构存储。
由于数据库索引是存储在磁盘上,当数据量比较大时,索引的大小会比较大。当我们利用索引查询时,无法把整个索引都加载到内存中,只能逐一加载每一个磁盘页,其中每个磁盘页对应着索引树的节点。这样会导致最坏情况下,磁盘IO次数等于树的高度。
假如当前有一颗m阶的B树(注意阶的意思是指每个节点的孩子节点的个数),那么其符合:
(1)每个节点最多有m个子节点
(2)除了根节点和叶子节点之外,其他的每个节点最少有m/2(向上取整)个孩子节点
(3)根节点至少有两个孩子节点,(除了第一次插入的时候,此时只有一个节点,根节点同时是叶子节点)
(4)所有的叶子节点都在同一层
(5)有k个子节点的父节点包含k-1个关键码
除了上面B树的性质外,B树还有几个特点:
1.树高平衡,所有的叶节点都在同一层
2.关键码没有重复,父节点中的关键码是其子节点的分解
3.B树把值接近的相关记录放在同一个磁盘页中,从而利用了访问的局部性原理。
4.B树保证树种至少有一部分比例的节点是满的。
8.哈希表
哈希是将某个对象变换为唯一标识符,该标识符通常用一个短的随机字母和数字组成的字符串来代表。哈希可以用来实现各种数据结构。
哈希表通常由数组来实现。
哈希表的性能取决于3个指标:
- 哈希函数
- 哈希表的大小
- 哈希冲突处理方式
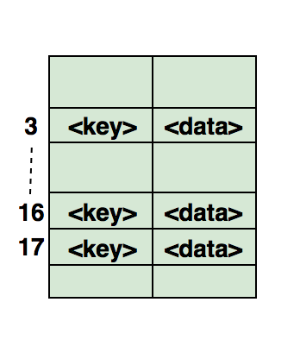
上图展示了由数组实现的哈希表,数组的下标即为哈希值,由哈希函数计算,作为哈希表的键(key),而数组中保存的数据即为值(value)
参考:
https://www.cnblogs.com/fundebug/p/data_structures_in_js_for_interview.html
https://blog.csdn.net/weixin_41012399/article/details/94896007

 浙公网安备 33010602011771号
浙公网安备 33010602011771号