


xpath解析:最常用且最便捷高效的一种解析方式,通用性
-xpath解析原理:
-1、实例化一个etree的对象,且需要将被解析的页面源码数据加载到该对象中。
-2、调用etree对象中的xpath方法结合这xpath表达式实现标签的定位和内容的捕获
-环境的安装:
-pip install lxml
-如何实例化一个etree对象:from lxml import etree
-1、将本地的html文档中的源码加载到etree对象中:
etree.parse(filePath,etree.HTMLParser())
-2、可以将从互联网上获取的源码数据加载到该对象
etree.HTML(‘page_text’)
-xpath(‘xpath表达式’)
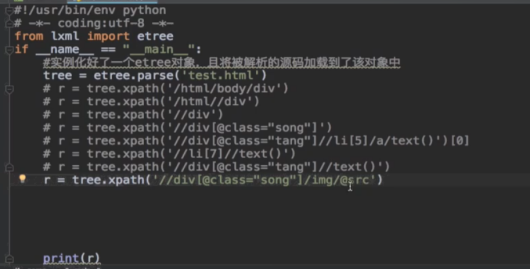
-xpath表达式:
- /:表示的是从根节点开始定位,表示的是一个层级
- //:表示的是多个层级,可以表示从任意位置开始定位
-属性定位: //div[@class=’song’] tag[@attrName=”attrValue”]
-索引定位://div[@class=’song]/p[3] 索引从1开始的
-取文本
- /text() 获取的是标签中直系的文本内容
- //text() 标签中非直系的文本内容(所有的文本内容)
-取属性:
/@attrName ==> img/src
基础:
实例一:xpath_4k图片下载
先查询网页的编码标准
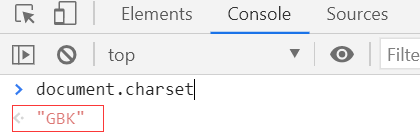
表示该网页编码标准为GBK
1 import os 2 3 import requests 4 from lxml import etree 5 6 if __name__=="__main__": 7 url="http://pic.netbian.com/4kfengjing/" 8 headers={ 9 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36' 10 } 11 response=requests.get(url=url,headers=headers) 12 response.encoding="GBK" 13 page_text=response.text 14 tree=etree.HTML(page_text) 15 16 li_list=tree.xpath('//div[@class="slist"]/ul/li') 17 #print(li_list) 18 19 20 #创建文件夹 21 if not os.path.exists('./picLibs'): 22 os.mkdir('./picLibs') 23 24 for li in li_list: 25 img_url='http://pic.netbian.com/'+li.xpath('./a/img/@src')[0] 26 27 img_name=li.xpath('./a/img/@alt')[0]+'.jpg' 28 29 #下载图片 30 img_data=requests.get(url=img_url,headers=headers).content 31 #图片永久化存储 32 img_path='picLibs/'+img_name 33 34 with open(img_path,'wb') as fp: #图片二进制存储 35 fp.write(img_data) 36 print(img_name+' 爬取成功!!!')
实例二:xpath_全国城市名称爬取

1 import requests 2 3 from lxml import etree 4 5 if __name__=="__main__": 6 url="https://www.aqistudy.cn/historydata/" 7 headers={ 8 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36' 9 } 10 11 page_text=requests.get(url=url,headers=headers).text 12 13 tree=etree.HTML(page_text) 14 15 li_list=tree.xpath('//div[@class="bottom"]/ul/li | //div[@class="bottom"]/ul/div[2]/li') 16 all_city_names=[] 17 for li in li_list: 18 city_name=li.xpath('./a/text()')[0] 19 all_city_names.append(city_name) 20 21 print(all_city_names)
