第六次作业
作业①:
- 要求:
- 用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据。
- 每部电影的图片,采用多线程的方法爬取,图片名字为电影名
- 了解正则的使用方法
- 候选网站:豆瓣电影:https://movie.douban.com/top250
1)爬取豆瓣实验:
代码部分:
import requests
from bs4 import BeautifulSoup
import re,os
import threading
import pymysql
import urllib
class MySpider:
def startUp(self,url):
headers = {
'Cookie': 'll="118200"; bid=6RFUdwTYOEU; _vwo_uuid_v2=D7971B6FDCF69217A8423EFCC2A21955D|41eb25e765bdf98853fd557b53016cd5; __gads=ID=9a583143d12c55e0-22dbef27e3c400c8:T=1606284964:RT=1606284964:S=ALNI_MYBPSHfsIfrvOZ_oltRmjCgkRpjRg; __utmc=30149280; ap_v=0,6.0; dbcl2="227293793:AVawqnPg0jI"; ck=SAKz; push_noty_num=0; push_doumail_num=0; __utma=30149280.2093786334.1603594037.1606300411.1606306536.8; __utmz=30149280.1606306536.8.5.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmt=1; __utmv=30149280.22729; __utmb=30149280.2.10.1606306536',\
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'
}
self.open = False
try:
self.con = pymysql.connect(host='localhost',port=3306,user='root',passwd='123456',database='mydb',charset='utf8')
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.open = True
try:
self.cursor.execute("drop table if exists movies")
except Exception as err:
# print(err)
pass
except Exception as err:
print(err)
self.no = 0
# self.page = 0
self.Threads = []
# page_text = requests.get(url=url,headers=headers).text
# soup = BeautifulSoup(page_text,'lxml')
# print(soup)
# li_list = soup.select("ol[class='grid_view'] li"c)
urls = []
for i in range(10):
url = 'https://movie.douban.com/top250?start=' + str(i*25) + '&filter='
print(url)
page_text = requests.get(url=url,headers=headers).text
soup = BeautifulSoup(page_text,'lxml')
# print(soup)
li_list = soup.select("ol[class='grid_view'] li")
print(len(li_list))
for li in li_list:
movie_rank = li.select("div[class='item'] div em")[0].text
movie_name = li.select("div[class='info'] div a span[class='title']")[0].text
print(movie_name)
dir_act = li.select("div[class='info'] div[class='bd'] p")[0].text
dir_act = ' '.join(dir_act.split())
try:
movie_director = re.search(':.*:',dir_act).group()[1:-3]
except:
movie_director = "奥利维·那卡什 Olivier Nakache / 艾力克·托兰达 Eric Toledano "
# print(direct)
# print(dir_act)
s = dir_act.split(':')
# print(s)
try:
movie_actor = re.search(r'(\D)*',s[2]).group()
except:
movie_actor = "..."
# print(main_act)
pattern = re.compile('\d+',re.S)
movie_time = pattern.search(dir_act).group()
# print(show_time)
countryAndmovie_type = dir_act.split('/')
movie_country = countryAndmovie_type[-2]
movie_type = countryAndmovie_type[-1]
movie_score = li.select("div[class='info'] div[class='star'] span")[1].text
# print(score)
movie_count = re.match(r'\d+',li.select("div[class='info'] div[class='star'] span")[3].text).group()
# print(score,count,quote)
img_name = li.select("div[class='item'] div a img")[0]["alt"]
try:
quote = li.select("div[class='info'] p[class='quote'] span")[0].text
except:
quote = ""
# print(img_name)
img_src = li.select("div[class='item'] div a img[src]")[0]["src"]
path = 'movie_img\\' + img_name + '.jpg'
# print(img_name,img_src,path)
print(movie_rank, '2', movie_name, '3', movie_director, '4', movie_actor, '5', movie_time, '6', movie_country, '7', movie_type, '8', movie_score, '9', movie_count, '10', quote, '11', path)
try:
self.insertDB(movie_rank,movie_name,movie_director,movie_actor,movie_time,movie_country,movie_type,movie_score,movie_count,quote,path)
self.no += 1
except Exception as err:
print(err)
print("数据插入失败")
if url not in urls:
T = threading.Thread(target=self.download,args=(img_name,img_src))
T.setDaemon(False)
T.start()
self.Threads.append(T)
# print(len(li_list))
def download(self,img_name,img_src):
dir_path = 'movie_img'
if not os.path.exists(dir_path):
os.mkdir(dir_path)
# for img in os.listdir(movie_img):
# os.remove(os.path.join(movie_img,img))
file_path = dir_path + '/' + img_name + '.jpg'
with open(file_path,'wb') as fp:
data = urllib.request.urlopen(img_src)
data = data.read()
# print("正在下载:" + img_name)
fp.write(data)
# print(img_name+ "下载完成")
fp.close()
def insertDB(self, rank, name, director, mainactor, time, country, type, score, rateCount, quote,path):
try:
self.cursor.execute("insert into douban (排名,电影名称,导演,主演,上映时间,国家,电影类型,评分,评价人数,引用,文件路径) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",
(rank, name, director, mainactor, time, country, type, score, rateCount, quote,path))
except Exception as err:
print(err)
def closeUp(self):
if self.open:
self.con.commit()
self.con.close()
self.open = False
print("一共爬取了" ,self.no,"条数据")
url = 'https://movie.douban.com/top250'
myspider = MySpider()
myspider.startUp(url)
myspider.closeUp()
for t in myspider.Threads:
t.join()
print("End")
爬取结果:
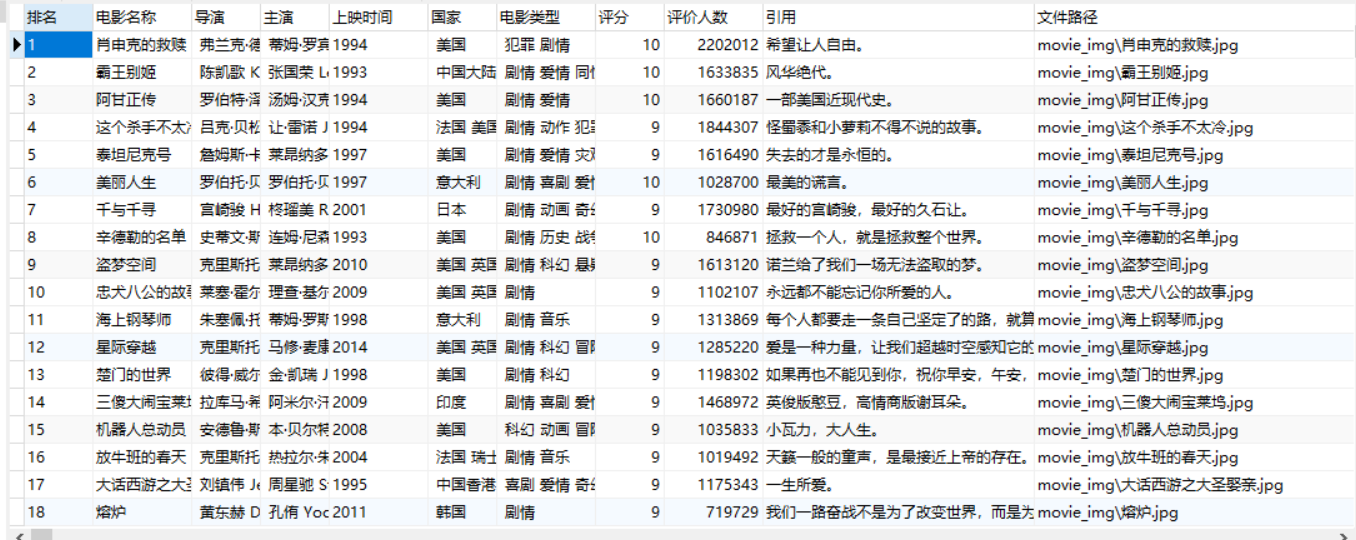

2)心得体会
刚开始是卡在电影导演和主演的信息怎么分开的部分,看了(copy)同学的代码才彳亍
作业②
-
要求:
- 熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取科软排名信息
- 爬取科软学校排名,并获取学校的详细链接,进入下载学校Logo存储、获取官网Url、院校信息等内容。
-
关键词:学生自由选择
-
输出信息:MYSQL的输出信息如下
1)爬取软科大学排名实验
代码部分:
主代码:
import scrapy import requests import time from university_rank.items import UniversityRankItem from bs4 import UnicodeDammit class MySpiderSpider(scrapy.Spider): name = 'My_Spider' def start_requests(self): url = 'https://www.shanghairanking.cn/rankings/bcur/2020' yield scrapy.Request(url=url,callback=self.parse) def parse(self, response): try: dammit = UnicodeDammit(response.body, ["utf-8", "gbk"]) data = dammit.unicode_markup selector=scrapy.Selector(text=data) collegelist=selector.xpath("//table[@class='rk-table']/tbody/tr") for college in collegelist: detailUrl="https://www.shanghairanking.cn"+college.xpath("./td[@class='align-left']/a/@href").extract_first() print(detailUrl) req = requests.get(detailUrl) req.encoding='utf-8' text=req.text selector_1=scrapy.Selector(text=text) #抓取数据 sNo=college.xpath("./td[position()=1]/text()").extract_first().strip() print(sNo) schoolName=selector_1.xpath("//div[@class='univ-name']/text()").extract_first() print(schoolName) city=college.xpath("./td[position()=3]/text()").extract_first().strip() print(city) officialUrl=selector_1.xpath("//div[@class='univ-website']/a/text()").extract_first() print(officialUrl) info=selector_1.xpath("//div[@class='univ-introduce']/p/text()").extract_first() print(info) mFile=sNo+'.jpg' #获取并下载图片 src = selector_1.xpath("//td[@class='univ-logo']/img/@src").extract_first() req_1 = requests.get(src) image=req_1.content picture=open("D:/Python/Data_Collect/university_img/"+str(sNo)+'.png',"wb") picture.write(image) picture.close() #存入item item=UniversityRankItem() item['sNo']=sNo if sNo else "" item['schoolName']=schoolName if schoolName else "" item['city']=city if city else "" item['officialUrl']=officialUrl if officialUrl else "" item['info']=info if info else "" item['mFile']=mFile if mFile else "" yield item except Exception as err: print(err)
items.py:
import scrapy
class UniversityRankItem(scrapy.Item):
sNo = scrapy.Field()
schoolName = scrapy.Field()
city = scrapy.Field()
officialUrl = scrapy.Field()
info = scrapy.Field()
mFile=scrapy.Field()
mSrc=scrapy.Field()
pipelines.py:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import os
import pymysql
class UniversityRankPipeline:
def __init__(self):
self.count = 0
self.opened = True
def open_spider(self, spider):
print("连接数据库")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
except Exception as err:
print("数据库连接失败")
self.opened = False
# 提交数据并关闭数据库,使用count变量统计爬取的信息数
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.showDB()
self.con.close()
self.opened = False
print("关闭数据库")
print("总共爬取", self.count, "条信息")
def process_item(self, item, spider):
try:
self.cursor.execute(
"insert into College (sNo,schoolName,city,officalUrl,info,mFile) values (%s,%s,%s,%s,%s,%s)",
(item['sNo'], item['schoolName'], item['city'], item['officialUrl'], item['info'], item['mFile']))
except Exception as err:
print(err)
return item
爬取结果:


2)心得体会:
scrapy更像套模板,比较好弄
作业③
1)爬取MOOC个人课程
代码部分:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
import pymysql
import re
from selenium.webdriver import ChromeOptions
class MySpider:
def startUp(self, url):
print('begin')
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
self.driver = webdriver.Chrome(options=option)
self.driver.maximize_window()
self.count = 1
self.open = False
try:
self.db = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123456', database='mydb',
charset='utf8')
self.cursor = self.db.cursor()
self.open = True
except:
self.db.close()
self.open = False
print("数据库连接或者表格创建失败")
print(self.open)
self.driver.get(url)
"""
1. 全局性设定
2. 每个半秒查询一次元素,直到超出最大时间
3. 后面所有选择元素的代码不需要单独指定周期定等待了
"""
self.driver.implicitly_wait(10) # 隐式等待
time.sleep(1)
enter_first = self.driver.find_element_by_xpath(
"//div[@id='g-container']//div[@class='web-nav-right-part']//a[@class='f-f0 navLoginBtn']")
enter_first.click()
# time.sleep(1)
other_enter = self.driver.find_element_by_xpath("//span[@class='ux-login-set-scan-code_ft_back']")
other_enter.click()
# time.sleep(1)
phone_enter = self.driver.find_element_by_xpath("//ul[@class='ux-tabs-underline_hd']/li[2]")
phone_enter.click()
time.sleep(1)
iframe = self.driver.find_element_by_xpath("//div[@class='ux-login-set-container']//iframe")
self.driver.switch_to.frame(iframe)
phone_number = self.driver.find_element_by_xpath("//div[@class='u-input box']//input[@id='phoneipt']")
# phone_number = self.driver.find_element_by_id('phoneipt')
phone_number.send_keys('18650084388')
time.sleep(1)
phone_passwd = self.driver.find_element_by_xpath("//div[@class='u-input box']/input[2]")
phone_passwd.send_keys('wuqilin2000420')
time.sleep(1)
self.driver.find_element_by_xpath("//div[@class='f-cb loginbox']/a").click()
time.sleep(3)
self.driver.find_element_by_xpath("//div[@class='ga-click u-navLogin-myCourse']//span").click()
div_list = self.driver.find_elements_by_xpath("//div[@class='course-panel-wrapper']/div/div")
time.sleep(2)
for div in div_list:
# 点击课程
div.click()
time.sleep(2)
new_tab = self.driver.window_handles[-1]
self.driver.switch_to.window(new_tab)
time.sleep(2)
# 点击课程详细
self.driver.find_element_by_xpath("//h4[@class='f-fc3 courseTxt']").click()
time.sleep(2)
new_new_tab = self.driver.window_handles[-1]
self.driver.switch_to.window(new_new_tab)
id = self.count
# print(id)
Course = self.driver.find_element_by_xpath(
"//*[@id='g-body']/div[1]/div/div[3]/div/div[1]/div[1]/span[1]").text
# print(Course)
College = self.driver.find_element_by_xpath("//*[@id='j-teacher']/div/a/img").get_attribute("alt")
# print(College)
Teacher = self.driver.find_element_by_xpath(
"//*[@id='j-teacher']/div/div/div[2]/div/div/div/div/div/h3").text
# print(Teacher)
Teamlist = self.driver.find_elements_by_xpath(
"//*[@id='j-teacher']/div/div/div[2]/div/div[@class='um-list-slider_con']/div")
Team = ''
for name in Teamlist:
main_name = name.find_element_by_xpath("./div/div/h3[@class='f-fc3']").text
Team += str(main_name) + " "
# print(Team)
Count = self.driver.find_element_by_xpath("//*[@id='course-enroll-info']/div/div[2]/div[1]/span").text
Count = Count.split(" ")[1]
# print(Count)
Process = self.driver.find_element_by_xpath(
'//*[@id="course-enroll-info"]/div/div[1]/div[2]/div[1]/span[2]').text
# print(Process)
Brief = self.driver.find_element_by_xpath('//*[@id="j-rectxt2"]').text
# print(Brief)
time.sleep(2)
# 关闭课程详细界面
self.driver.close()
pre_tab = self.driver.window_handles[1]
self.driver.switch_to.window(pre_tab)
time.sleep(2)
# 关闭课程界面
self.driver.close()
pre_pre_tab = self.driver.window_handles[0]
self.driver.switch_to.window(pre_pre_tab)
time.sleep(2)
self.count += 1
self.insertDB(id, Course, College, Teacher, Team, Count, Process, Brief)
try:
time.sleep(2)
# 下一页
nextpage = self.driver.find_element_by_xpath("//a[@class='th-bk-main-gh']")
time.sleep(2)
nextpage.click()
self.processSpider()
except:
self.driver.find_element_by_xpath("//a[@class='th-bk-disable-gh']")
print(id, Course, College, Teacher, Team, Count, Process, Brief)
# print(type(id),type(course),type(college),type(teacher),type(team),type(count),type(process),type(brief))
self.insertDB(id, Course, College, Teacher, Team, Count, Process, Brief)
def insertDB(self, id, course, college, teacher, team, count, process, brief):
try:
self.cursor.execute(
"insert into Personal_Mooc( Id, cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief) values(%s,%s,%s,%s,%s,%s,%s,%s)", \
(id, course, college, teacher, team, count, process, brief))
self.db.commit()
except Exception as err:
print("数据插入失败")
print(err)
def closeUp(self):
print(self.open)
if self.open:
self.db.commit()
self.open = False
self.driver.close()
print('一共爬取了', self.count, '条数据')
mooc_url = 'https://www.icourse163.org/'
spider = MySpider()
spider.startUp(mooc_url)
spider.closeUp()
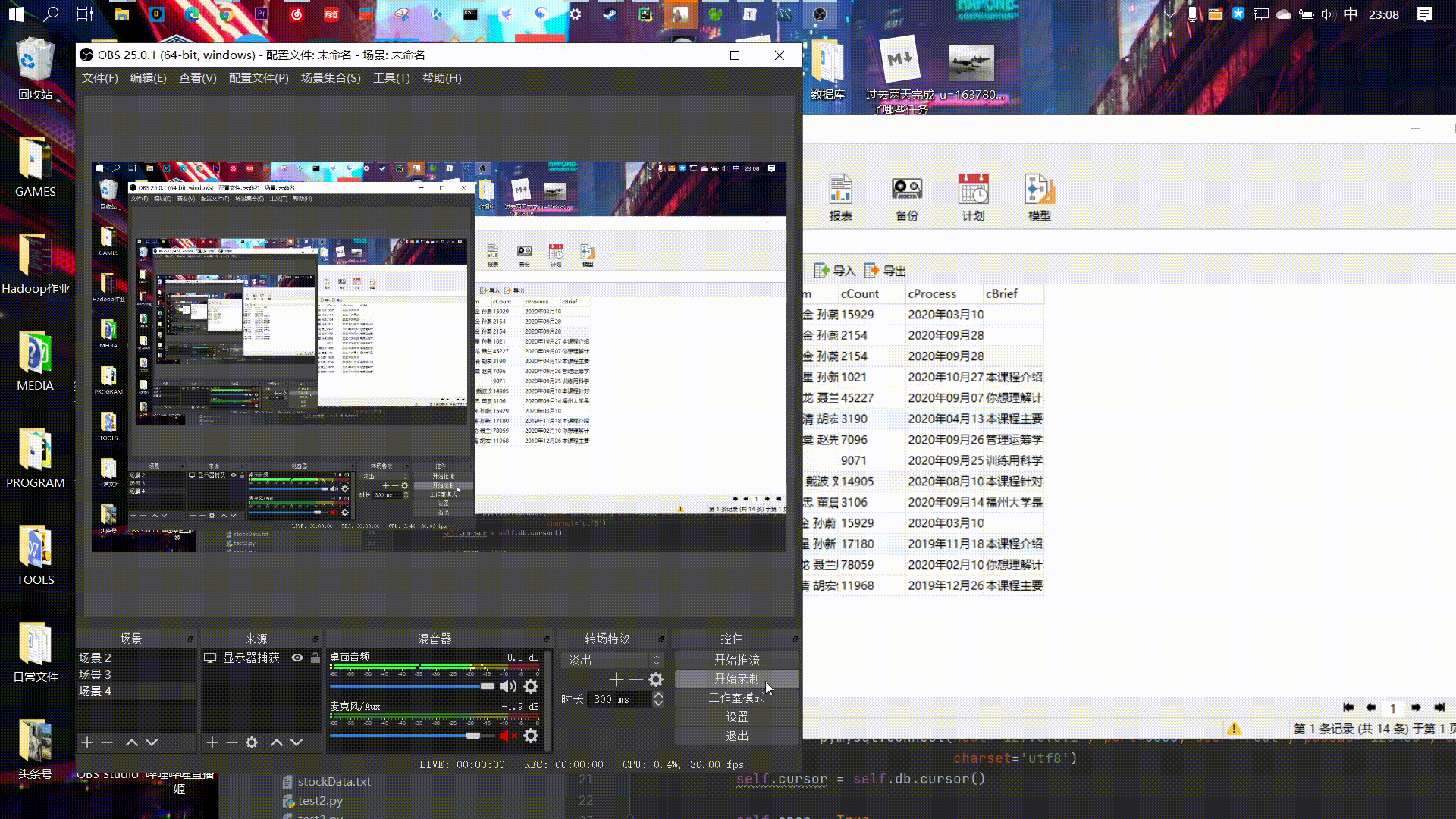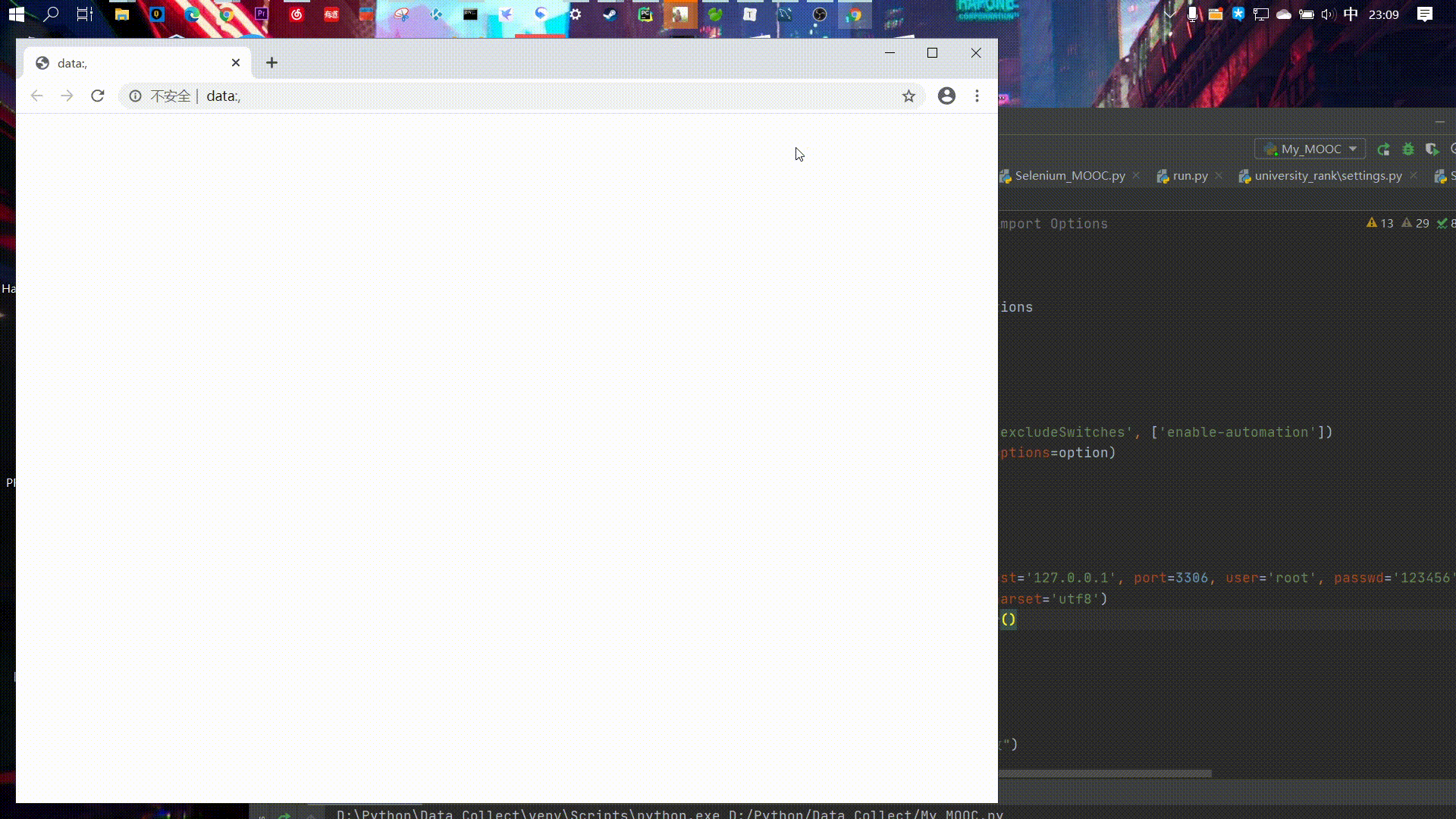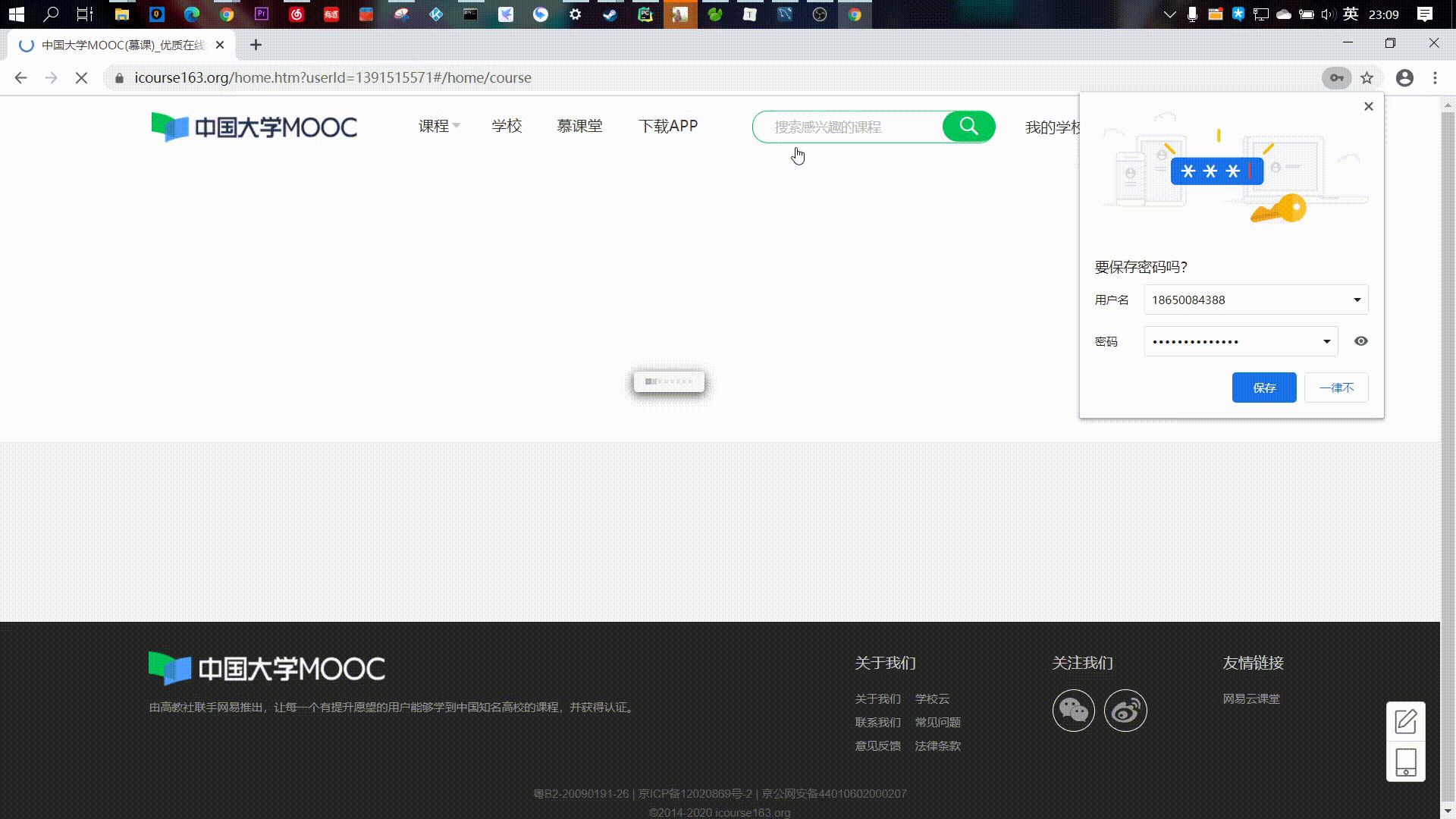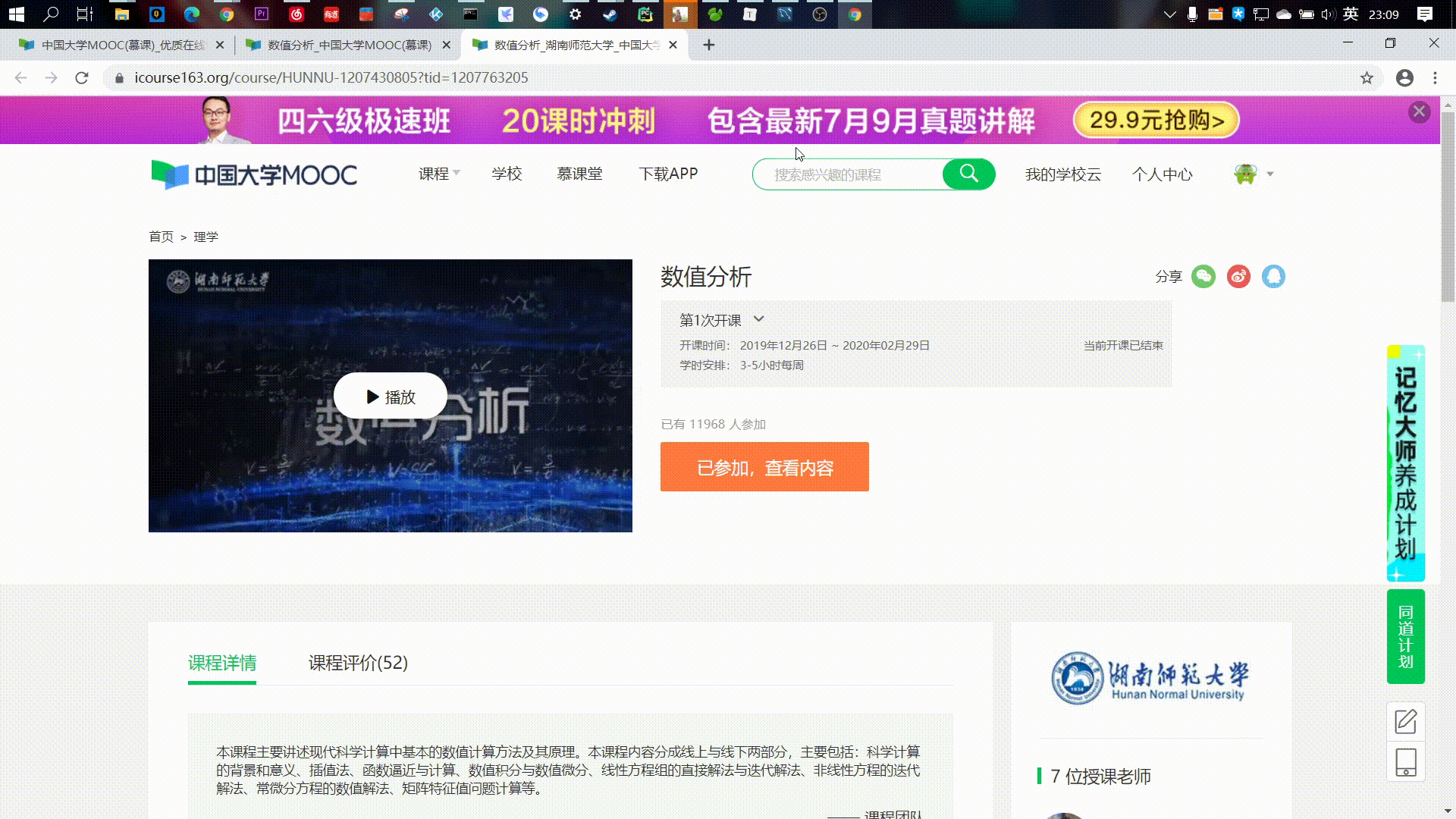
爬取结果:
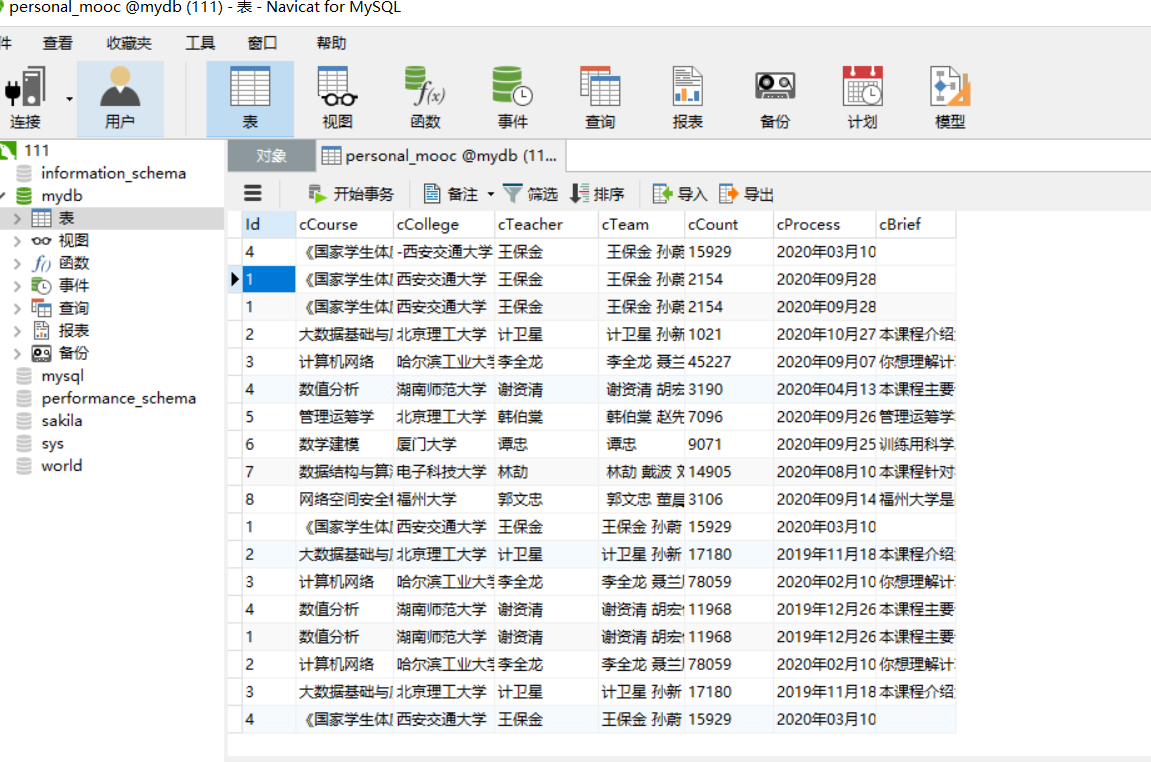
本来只有四条的,之前多试了几次就插了这么多数据进来
2)心得体会:
上一次的selenium爬取mooc卡在了教师界面还没有解决,这次也是看了很多同学的代码才做出来,难点在页面的转换。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号