第四次作业
作业①:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
关键词:学生自由选择
1)爬取当当网实验:
1.创建数据库
下载MySQL后创建mydb数据库和books表,在navicat中查看:
2.编写items.py:
import scrapy
class BookItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
author=scrapy.Field()
date=scrapy.Field()
publisher=scrapy.Field()
detail=scrapy.Field()
price=scrapy.Field()
3.编写pipelins.py:
import pymysql
class BookPipeline(object):
def open_spider(self,spider):
print("opened")
try:
self.con=pymysql.connect(host="127.0.0.1",port=3306,user="root",passwd="123456",db="mydb",charset="utf8")
self.cursor=self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from books")
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "本书籍")
def process_item(self, item, spider):
try:
print(item["title"])
print(item["author"])
print(item["publisher"])
print(item["date"])
print(item["price"])
print(item["detail"])
print()
if self.opened:
self.cursor.execute("insert into books (bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail) values( % s, % s, % s, % s, % s, % s)",(item["title"],item["author"],item["publisher"],item["date"],item["price"],item["detail"]))
self.count += 1
except Exception as err:
print(err)
return item
4.编写settings.py:
BOT_NAME = 'DangDang'
SPIDER_MODULES = ['DangDang.spiders']
NEWSPIDER_MODULE = 'DangDang.spiders'
ITEM_PIPELINES = {
'DangDang.pipelines.BookPipeline': 300,
}
5.编写爬虫程序:
import scrapy
from DangDang.items import BookItem
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
class MydangdangSpider(scrapy.Spider):
name = 'mydangdang'
key = '毛选'
source_url = 'http://search.dangdang.com/'
def start_requests(self):
url = MydangdangSpider.source_url + "?key="+MydangdangSpider.key
yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
lis = selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]")
for li in lis:
title = li.xpath("./a[position()=1]/@title").extract_first()
price =li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
date =li.xpath("./p[@class='search_book_author']/span[position()=last()- 1]/text()").extract_first()
publisher = li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title ").extract_first()
detail = li.xpath("./p[@class='detail']/text()").extract_first()
# detail有时没有,结果None
item = BookItem()
item["title"] = title.strip() if title else ""
item["author"] = author.strip() if author else ""
item["date"] = date.strip()[1:] if date else ""
item["publisher"] = publisher.strip() if publisher else ""
item["price"] = price.strip() if price else ""
item["detail"] = detail.strip() if detail else ""
yield item
link = selector.xpath("//div[@class='paging']/ul[@name='Fy']/li[@class='next'] / a / @ href").extract_first()
if link:
url = response.urljoin(link)
yield scrapy.Request(url=url, callback=self.parse)
except Exception as err:
print(err)
pass
6.编写Run.py
from scrapy import cmdline
cmdline.execute("scrapy crawl mydangdang -s LOG_ENABLED=False".split())
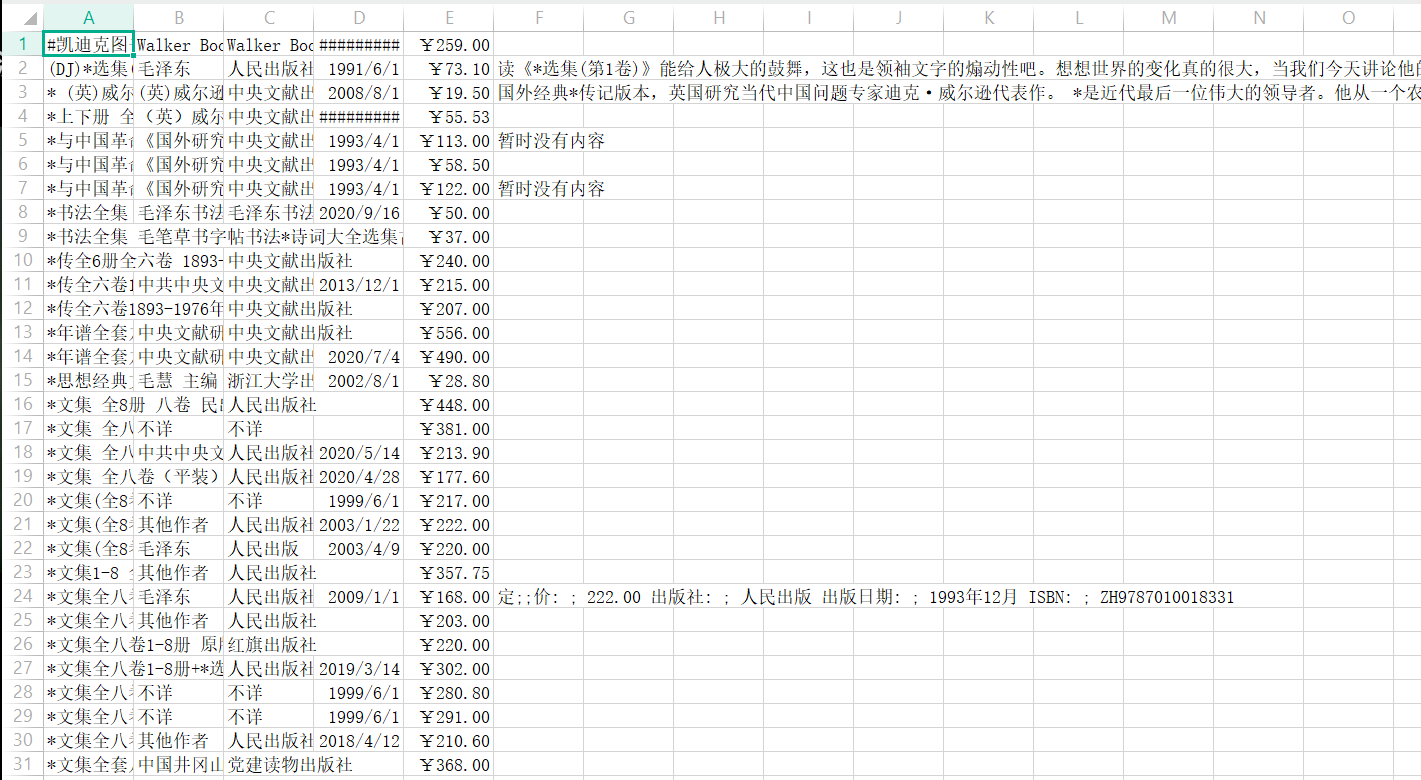
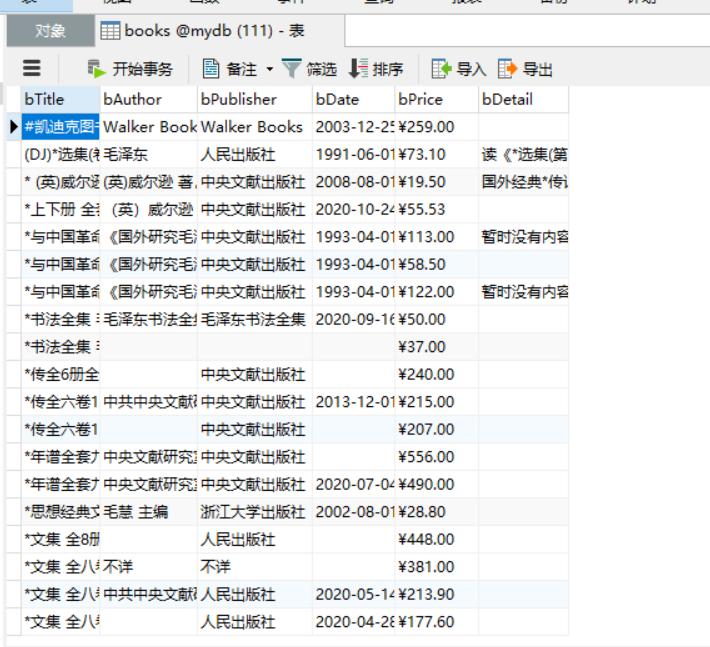
爬取结果:
在navicat中查看,同时导出为excel:
2)心得体会
这次也是书上代码的复现,也学会了mysql的数据库相关知识,懂得用navicat来进行数据库查询和管理。
作业②
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取股票相关信息
候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/
输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头
1)爬取股票实验
1.items.py
import scrapy
class XpathStockItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
id = scrapy.Field()
no = scrapy.Field()
name= scrapy.Field()
price = scrapy.Field()
edu = scrapy.Field()
fudu = scrapy.Field()
cjl = scrapy.Field()
cje = scrapy.Field()
zf = scrapy.Field()
highest = scrapy.Field()
lowest = scrapy.Field()
today = scrapy.Field()
yesterday = scrapy.Field()
pass
2.pipelines.py
import pymysql
class XpathStockPipeline(object):
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from stocks")
self.opened = True
self.count = 0
except Exception as err:
print("数据库打开失败")
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "行数据")
def process_item(self, item, spider):
try:
print(item["id"])
print(item["name"])
print(item["price"])
print(item["edu"])
if self.opened:
self.cursor.execute(
"insert into stocks (id,no,name,price,edu,fudu,cjl,cje,zf,highest,lowest,today,yseterday) values( % s, % s, % s, % s, % s, % s, % s, % s, % s, % s, % s, % s, % s)",
(item["id"],item["no"],item["name"],item["price"],item["edu"],item["fudu"],item["cjl"],item["cje"],item["zf"],item["highest"]
,item["lowest"]
,item["today"]
,item["yesterday"]))
self.count += 1
except Exception as err:
print("数据插入失败",err)
return item
3.settings.py
BOT_NAME = 'Stock_Xpath'
SPIDER_MODULES = ['Stock_Xpath.spiders']
NEWSPIDER_MODULE = 'Stock_Xpath.spiders'
ITEM_PIPELINES = {
'Stock_Xpath.pipelines.XpathStockPipeline': 300,
}
DEFAULT_REQUEST_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36"
}
4.My_spider.py
import scrapy
from bs4 import UnicodeDammit
from selenium import webdriver
from ..items import XpathStockItem
from selenium.webdriver.chrome.options import Options
class MySpider(scrapy.Spider):
name = 'stock'
def start_requests(self):
url = 'http://quote.eastmoney.com/center/gridlist.html#hs_a_board'
yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response):
driver = webdriver.Chrome()
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
list = selector.xpath("//tr[@class]")
for li in list:
ID=li.find_elements_by_xpath("./td[position()=1]")[0].text
no=li.find_elements_by_xpath("./td[position()=2]/a")[0].text
Name=li.find_elements_by_xpath("./td[position()=3]/a")[0].text
Price=li.find_elements_by_xpath("./td[position()=5]/span")[0].text
Edu=li.find_elements_by_xpath("./td[position()=6]/span")[0].text
Fudu =li.find_elements_by_xpath("./td[position()=7]/span")[0].text
cjl =li.find_elements_by_xpath("./td[position()=8]")[0].text
cje =li.find_elements_by_xpath("./td[position()=9]")[0].text
zf =li.find_elements_by_xpath("./td[position()=10]")[0].text
highest =li.find_elements_by_xpath("./td[position()=11]/span")[0].text
lowest =li.find_elements_by_xpath("./td[position()=12]/span")[0].text
today =li.find_elements_by_xpath("./td[position()=13]/span")[0].text
yesterday =li.find_elements_by_xpath("./td[position()=14]")[0].text
print(ID)
print(no)
print(Name)
item=XpathStockItem()
item["id"]=ID
item["no"]=no
item["name"]=Name
item["price"]=Price
item["edu"]=Edu
item["fudu"]=Fudu
item["cjl"]=cjl
item["cje"]=cje
item["zf"]=zf
item["highest"]=highest
item["lowest"]=lowest
item["today"]=today
item["yesterday"]=yesterday
yield item
except Exception as err:
print(err)
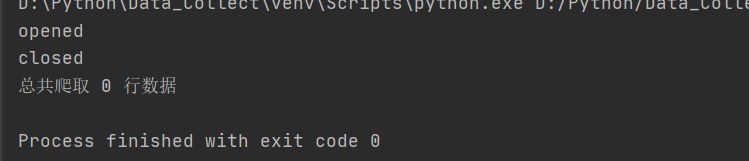
编写程序运行后出现了和上次作业一样的问题,并没有运行出什么结果,也不知道咋解决:
作业③:
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:招商银行网:http://fx.cmbchina.com/hq/
输出信息:MYSQL数据库存储和输出格式
1)爬取外汇网站实验
1.items.py
import scrapy
class XpathCmdItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Currency = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
Time = scrapy.Field()
pass
2.pipelines.py
import pymysql
class XpathCmdPipeline:
def open_spider(self, spider):
print("连接数据库")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="123456", db="mydb",charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.opened = True
self.count = 0
except Exception as err:
print("连接失败")
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("关闭数据库")
print("总共爬取", self.count, "条信息")
def process_item(self, item, spider):
try:
print(item)
if self.opened:
self.count += 1
# 插入数据到表中
self.cursor.execute(
"insert into cma(id,Currency,TSP,CSP,TBP,CBP,Time) values(%s,%s,%s,%s,%s,%s,%s)",
(self.count, item["Currency"], item["TSP"], item["CSP"], item["TBP"], item["CBP"], item["Time"]))
except Exception as err:
print(err)
return item
return item
3.settings.py
BOT_NAME = 'Xpath_cmd'
SPIDER_MODULES = ['Xpath_cmd.spiders']
NEWSPIDER_MODULE = 'Xpath_cmd.spiders'
ITEM_PIPELINES = {
'Xpath_cmd.pipelines.XpathCmdPipeline': 300,
}
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'Xpath_cmd (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
4.My_Spider.py
import scrapy
from bs4 import UnicodeDammit
from Xpath_cmd.items import XpathCmdItem
class MySpiderSpider(scrapy.Spider):
name = 'My_Spider'
allowed_domains = ['http://fx.cmbchina.com/hq/']
start_urls = ['http://http://fx.cmbchina.com/hq//']
source_url = 'http://fx.cmbchina.com/hq/'
def start_requests(self):
url = MySpiderSpider.source_url
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
table = selector.xpath("//div[@id='realRateInfo']/table[@class='data']")
trs = table.xpath("./tr")
for tr in trs[1:]:
Currency = tr.xpath("./td[position()=1]/text()").extract_first()
TSP = tr.xpath("./td[position()=4]/text()").extract_first()
CSP = tr.xpath("./td[position()=5]/text()").extract_first()
TBP = tr.xpath("./td[position()=6]/text()").extract_first()
CBP = tr.xpath("./td[position()=7]/text()").extract_first()
Time = tr.xpath("./td[position()=8]/text()").extract_first()
item = XpathCmdItem()
item["Currency"] = Currency.strip() if Currency else ""
item["TSP"] = TSP.strip() if TSP else ""
item["CSP"] = CSP.strip() if CSP else ""
item["TBP"] = TBP.strip() if TBP else ""
item["CBP"] = CBP.strip() if CBP else ""
item["Time"] = Time.strip() if Time else ""
yield item
except Exception as err:
print(err)
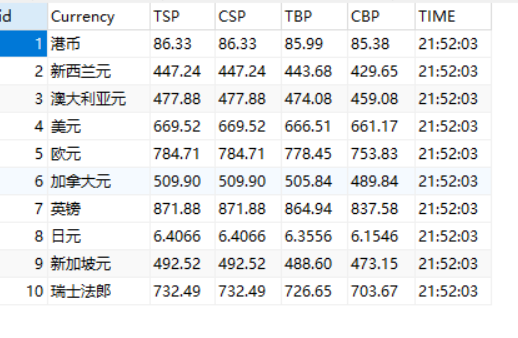
爬取结果
编写运行程序之后得到数据库中的如下结果:
2)心得体会
在这次爬取过程中,在数据库这块遇到了一个报错:"Incorrect string value: '\xE6\xB8\xAF\xE5\xB8\x81' for column 'Currency' at row 1"
是因为数据库中的格式设置与所需要插入的数据不相符导致插入失败,在使用navicat对列属性进行设置为utf8格式后就能正常插入。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号