第三次作业
第二次作业
作业①:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。
输出信息:
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
1)Weather Forecast
单线程代码:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import threading
count = 0
def imageSpider(start_url):
#global threads
global count
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36"
}
try:
urls=[]
req=urllib.request.Request(start_url,headers=headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup=BeautifulSoup(data,"lxml")
images=soup.select("img")
for image in images:
try:
src=image["src"]
url=urllib.request.urljoin(start_url,src)
if url not in urls:
#urls.append(url)
#print(url)
#count = count + 1
#T = threading.Thread(target= download , args=(url,count))
#T.setDaemon(False)
#T.start()
#threads.append(T)
urls.append(url)
print(url)
download(url)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url,count):
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36"
}
try:
count += 1
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4:]
else:
ext = ""
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("jpgfile\\" + str(count) + ext, "wb")
fobj.write(data)
fobj.close()
print("downloaded " + str(count) + ext)
except Exception as err:
print(err)
start_url="http://www.weather.com.cn/weather/101280601.shtml"
#threads = []
imageSpider(start_url)
多线程代码:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import threading
count = 0
def imageSpider(start_url):
global threads
global count
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36"
}
try:
urls=[]
req=urllib.request.Request(start_url,headers=headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup=BeautifulSoup(data,"lxml")
images=soup.select("img")
for image in images:
try:
src=image["src"]
url=urllib.request.urljoin(start_url,src)
if url not in urls:
urls.append(url)
print(url)
count = count + 1
T = threading.Thread(target= download , args=(url,count))
T.setDaemon(False)
T.start()
threads.append(T)
urls.append(url)
print(url)
download(url)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url,count):
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36"
}
try:
count += 1
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4:]
else:
ext = ""
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("jpgfile\\" + str(count) + ext, "wb")
fobj.write(data)
fobj.close()
print("downloaded " + str(count) + ext)
except Exception as err:
print(err)
start_url="http://www.weather.com.cn/weather/101280601.shtml"
threads = []
imageSpider(start_url)
for t in threads:
t.join()
print(
"The End"
)
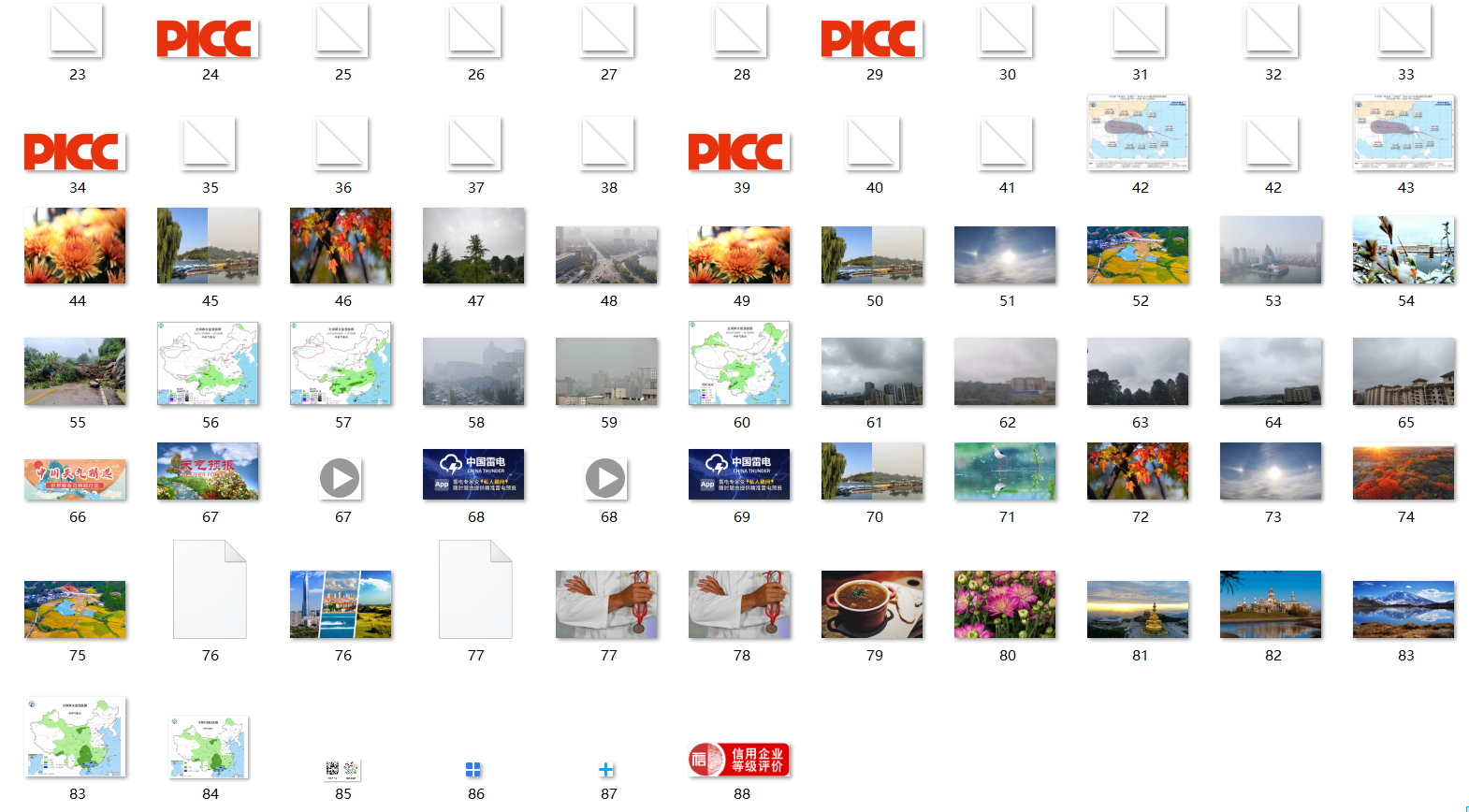
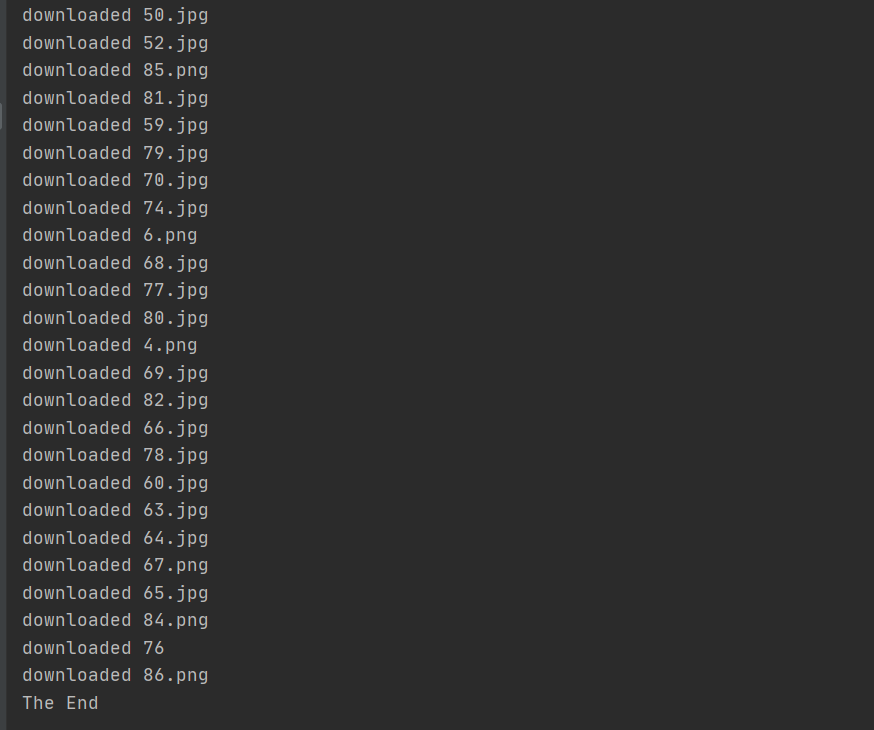
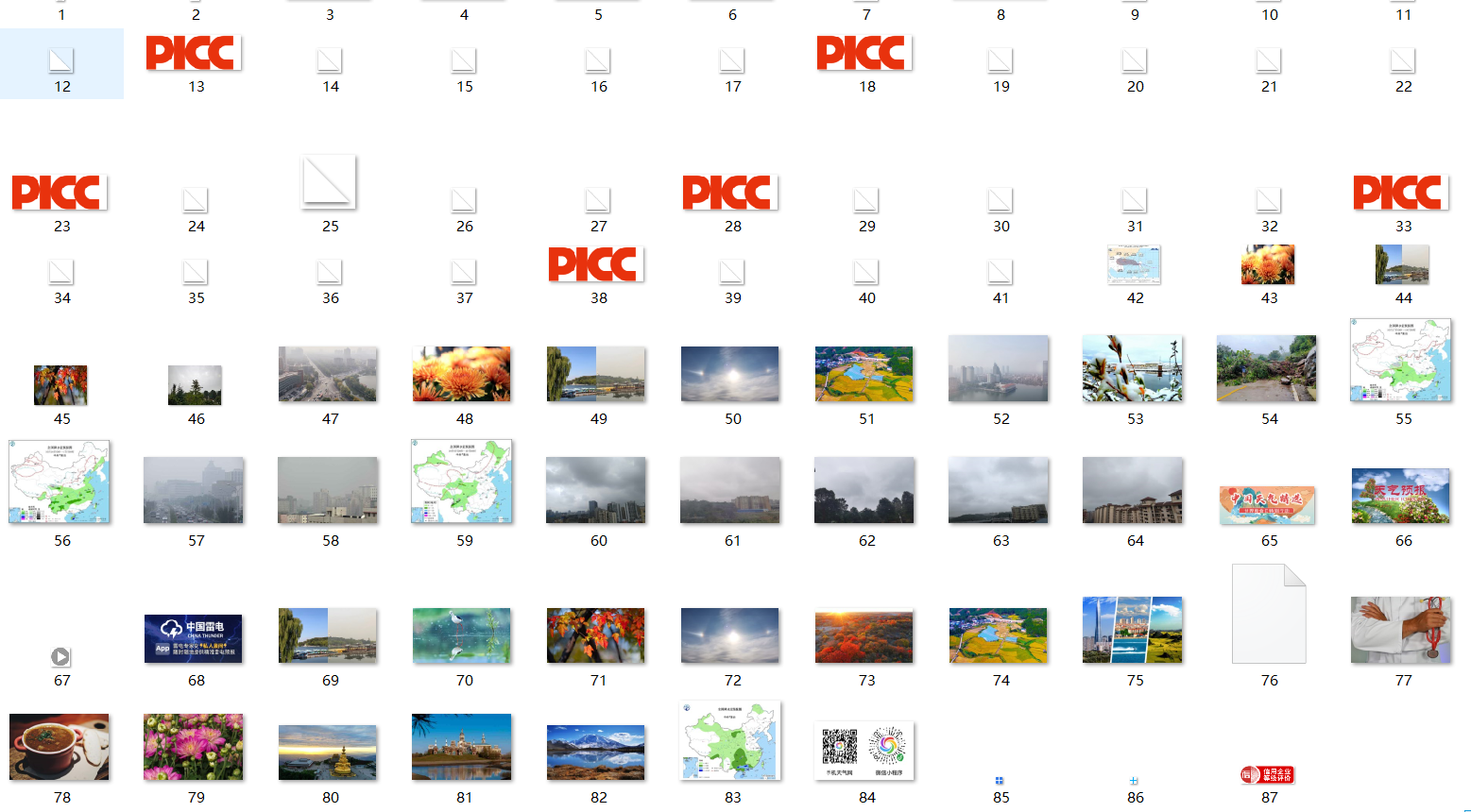
爬取结果:
单线程:
多线程:
2)心得体会:
这份作业只是把书上的代码进行复现了一下,体验了一下单线程与多线程的速度差距
作业②
-
要求:使用scrapy框架复现作业①。
-
输出信息:
同作业①
1)
Settings代码:
BOT_NAME = 'Weather_Scrapy'
DEFAULT_REQUEST_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36"
}
SPIDER_MODULES = ['Weather_Scrapy.spiders']
NEWSPIDER_MODULE = 'Weather_Scrapy.spiders'
ITEM_PIPELINES = {
'Weather_Scrapy.pipelines.WeatherScrapyPipeline': 300,
}
items代码:
import scrapy
class WeatherScrapyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
src = scrapy.Field()
pipellines代码:
import urllib
class WeatherScrapyPipeline:
count = 0
def process_item(self, item, spider):
start_url='http://www.weather.com.cn/weather/101280601.shtml'
url=urllib.request.urljoin(start_url, item['img'])
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36"
}
try:
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4:]
else:
ext = ""
self.count+=1
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("D:/Python/Data_Collect/Scrapy_Download" + str(self.count) + ext, "wb")
fobj.write(data)
fobj.close()
print("downloaded " + str(self.count) + ext)
except Exception as err:
print(err)
return item
主函数MySpider代码:
from Weather_Scrapy.items import WeatherScrapyItem
class Image_Scrapy(scrapy.spiders.Spider):
name = "Image_Scrapy"
start_url = "http://www.weather.com.cn/weather/101280601.shtml"
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
images = selector.xpath("//img/@src")
images = images.extract()
for image in images:
item = WeatherScrapyItem()
item['src'] = image
print(item)
yield item
except Exception as err:
print(err)
新建一个Run.py帮助爬虫启动:
from scrapy import cmdline
cmdline.execute("scrapy crawl Image_Scrapy -s LOG_ENABLED=false".split())
结果:
只显示程序运行,未显示任何结果,不知道出了什么问题,还未解决。

2)实验心得:
觉得自己太菜了
作业③
-
要求:使用scrapy框架爬取股票相关信息。
-
候选网站:东方财富网:https://www.eastmoney.com/
1)GetStock
主函数MySpider代码:
import scrapy
import requests
import re
from CrawlStock.items import CrawlstockItem
from pipelines import CrawlstockPipeline
class MySpider(scrapy.Spider):
name = 'MySpider'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36"
}
url = "http://nufm.dfcfw.com/EM_Finance2014NumericApplication/JS.aspx?" \
"cb=jQuery112406115645482397511_1542356447436&type=CT" \
"&token=4f1862fc3b5e77c150a2b985b12db0fd&sty=FCOIATC" \
"&js""=(%7Bdata%3A%5B(x)%5D%2CrecordsFiltered%3A(tot)%7D)" \
"&cmd=C.5&st=" \
"(ChangePercent)&sr=-1&p=1&ps=500&_=1602644108381"
def parse(self, response):
data = requests.get(self.url, headers=self.headers)
data = data.content.decode()
#colums = ['代码', '名称', '最新价格', '涨跌额', '涨跌幅', '成交量', '成交额', '振幅', '最高', '最低', '今开', '昨收', '今开']
if (data != []):
datas = data.split('["')[1].split('"]')[0].split('","')
items = []
for i in range(len(datas)):
# 创建字典
data = datas[i].split(',')[1:13]
item = CrawlstockItem(location=data[0],no=data[1], name=data[2], price=data[3], edu=data[4], fdu=data[5],
cjl=data[6],
cje=data[7], zf=data[8], highest=data[9], lowest=data[10],
today=data[11], yesterday=data[12])
# x.add_row([i,datas[i].split(',')[1],datas[i].split(',')[2],datas[i].split(',')[3],datas[i].split(',')[4],datas[i].split(',')[5],datas[i].split(',')[6],datas[i].split(',')[7],datas[i].split(',')[8],datas[i].split(',')[9],datas[i].split(',')[10],datas[i].split(',')[11],datas[i].split(',')[12],datas[i].split(',')[13]])
print(item)
yield item
print(CrawlstockPipeline.tb)
pipelines代码:
import prettytable as pt
tb = pt.PrettyTable(["序号", "股票代码", "股票名称", "最新报价", "涨跌幅", "涨跌额", "成交量", "成交额", "振幅", "最高", "最低", "今开", "昨收"])
class CrawlstockPipeline:
def process_item(self, item, MySpider):
tb.add_row(
[item["location"], item["no"], item["name"], item["price"], item["edu"], item["fdu"],
item["cjl"], item["cje"], item["zf"], item["highest"], item["lowest"],
item["lowest"], item["today"], item["yesterday"]])
print(tb)
return item
items代码:
import scrapy
class CrawlstockItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
count =scrapy.Field()
no = scrapy.Field()
name= scrapy.Field()
price = scrapy.Field()
edu = scrapy.Field()
fudu = scrapy.Field()
cjl = scrapy.Field()
cje = scrapy.Field()
zf = scrapy.Field()
highest = scrapy.Field()
lowest = scrapy.Field()
today = scrapy.Field()
yesterday = scrapy.Field()
pass
settings代码:
BOT_NAME = 'CrawlStock'
SPIDER_MODULES = ['CrawlStock.spiders']
NEWSPIDER_MODULE = 'CrawlStock.spiders'
ROBOTSTXT_OBEY = True
结果:
遇到的问题同作业②,也是没有任何结果输出,程序正常运行,问题还未解决。

2)实验心得
觉得自己是真滴菜


 浙公网安备 33010602011771号
浙公网安备 33010602011771号