第一次作业——结合三次小作业
 爬爬爬
爬爬爬
第一次作业——结合三次小作业
作业①:
用requests和BeautifulSoup库爬取http://www.shanghairanking.cn/rankings/bcur/2020上的大学排名
1)UniversitiesRanking
代码:
import requests
import bs4
from bs4 import BeautifulSoup
#从网络上获取大学排名网页的内容
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
# 过滤
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].text.strip(), tds[1].text.strip(), tds[2].text.strip(), tds[3].text.strip(),
tds[4].text.strip()])
#利用数据结构展示输出结构
def printUnivList(ulist, num):
tplt='{0:^10}\t{1:{5}^10}\t{2:^10}\t{3:^10}\t{4:^10}'
#输出的结构布置
print(tplt.format('大学综合排名', '学校名称', '学校所在地', '学校类型', '总得分' ,chr(12288)))
#chr(12288)是中文空格填充字符
for i in range(num):
u=ulist[i]
print(tplt.format(u[0], u[1], u[2], u[3] , u[4] ,chr(12288)))
def main():
unifo=[]
url='http://www.shanghairanking.cn/rankings/bcur/2020'
html=getHTMLText(url)
fillUnivList(unifo, html)
printUnivList(unifo, 70)#列出70所学校的信息,不然福大就进不了这个榜单惹
main()
爬取结果(只能说这个排名对福大并不是很友好):
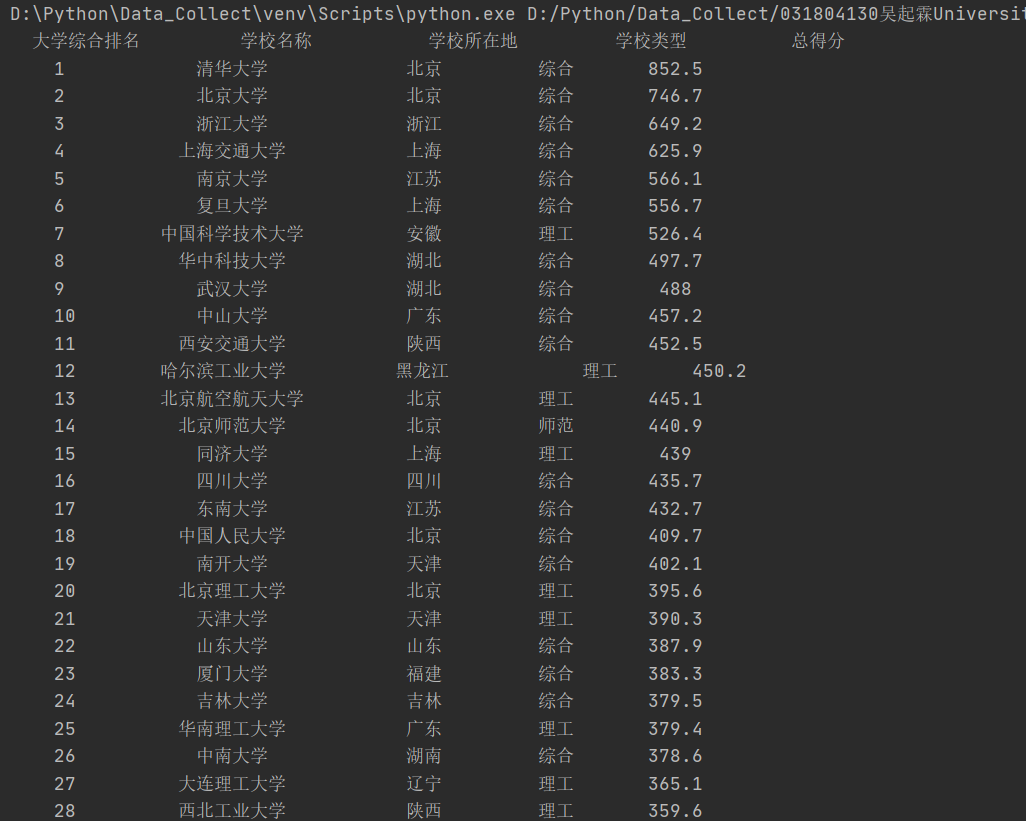
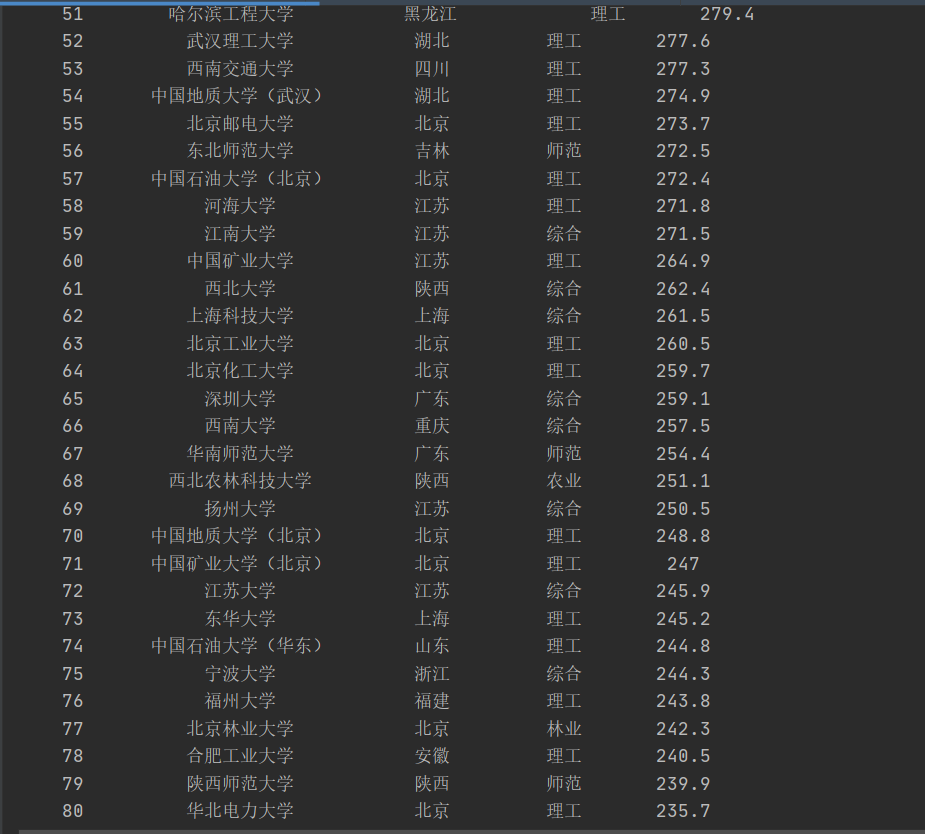
2)心得体会:
这次作业算是爬虫的第一次实践,初尝了beautifulsoup的美味。也学会了用F12来查看网页源代码的一些关键信息进行针对性的爬取。
作业②
用requests和re库方法设计淘宝商品比价定向爬虫,爬取该商城,以关键词“海力士”搜索页面的数据,爬取商品名称和价格。
1)GoodsPrice
代码:
import re
import requests
def getHTMLText(url): # 从网络获取网页内容
try:
headers = {
'authority': 's.taobao.com',
'cache-control': 'max-age=0',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'same-site',
'sec-fetch-mode': 'navigate',
'sec-fetch-user': '?1',
'sec-fetch-dest': 'document',
'referer': 'https://www.taobao.com/?spm=a230r.1.0.0.1dd868b8lGvN60',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': 'tg=0; thw=cn; hng=CN%7Czh-CN%7CCNY%7C156; t=2ca08877ffb9e0b891537536595eabf8; UM_distinctid=172f0b1c3d2319-00851ac8babea-4353760-144000-172f0b1c3d3b76; lgc=tb829577595; tracknick=tb829577595; enc=CZBYo25mziffJVFAywO1qiJv624L4BL4Np%2FZkgWwwqqYUqXJyTYzqHmBwP1SnWOdOY0vLmOzgtJoyIg03%2BzZ%2Bg%3D%3D; sgcookie=ElT95EJ%2FB1ORhYCCo2POp; uc3=nk2=F5RNZ%2BnoRpPe4WQ%3D&lg2=U%2BGCWk%2F75gdr5Q%3D%3D&vt3=F8dCufTAt%2F1UvboSuzA%3D&id2=Vy0bQr6DSq%2B75Q%3D%3D; uc4=id4=0%40VXqVEPgLMfIRLle6amB%2F2j8V1TUn&nk4=0%40FY4GsEknY9SIK4lW4RqmqjBI9M%2FHyQ%3D%3D; _cc_=VT5L2FSpdA%3D%3D; miid=626100861457475749; cna=257WF/sha30CAdpqkQZuE5vQ; mt=ci=-1_0; cookie2=123cb65f96a7c56e3639cbd72dd81bdc; _tb_token_=53b681e3be7b8; xlly_s=1; _m_h5_tk=c2de70d22be708574ae66f5d3ed4773d_1600407734111; _m_h5_tk_enc=41d95ba19889658d50418c19a9dcfbdf; v=0; alitrackid=www.taobao.com; lastalitrackid=www.taobao.com; JSESSIONID=246FBD963B96AA329691BCE6353E4C82; uc1=cookie14=Uoe0bUwfXhdzDA%3D%3D; tfstk=cqCCBFTdJDmBNqwrTwaw45saIBR5Zmr6SJtdR96MwIY-cn_CiMc2cFuhEcc9HF1..; l=eBQPDcoPQ8LkM8vyBOfanurza77OSIRYmuPzaNbMiOCP9l1p5xDNWZr8ezT9C3GVh6lDR3uV-FgLBeYBqIv4n5U62j-la_kmn; isg=BF1daYUm3pg7prs4TnQFOv9fbDlXepHM1CMjux8imbTj1n0I58qhnCtEBMpQEqmE',
}
r = requests.get(url, headers=headers)
r.raise_for_status
r.encoding = r.apparent_encoding
return r.text
except:
print("爬取失败")
def parsePage(ilt, html): # 解析
try:
plt = re.findall(r'\"view_price\":\"\d+\.\d*\"', html)
tlt = re.findall(r'\"raw_title\":\".*?\"', html)
for i in range(len(plt)):
price = eval(plt[i].split('\"')[3])
title = tlt[i].split('\"')[3]
ilt.append([title, price])
except:
print("解析出错")
def printGoodsList(ilt, num): # 输出
tplt = "{0:^10}\t{1:{3}^20}\t{2:^14}" # 中间一行用第三元素填充(中文)
print(tplt.format("序号", "价格", "商品名称", chr(12288)))
count = 0
for g in ilt:
count += 1
if count <= num:
print(tplt.format(count, g[0], g[1], chr(12288)))
def main():
goods = '海力士'
depth = 1
start_url = "https://s.taobao.com/search?q=" + goods
infolist = []
num = 200
for i in range(depth):
try:
url = start_url + '$S=' + str(44 * 1)
html = getHTMLText(url)
parsePage(infolist, html)
except:
continue
printGoodsList(infolist, num)
main()
结果:

2)实验心得:
这一次的实验和第一次实验类似,打开F12获取搜索界面网页的源代码的header相关消息,因为用爬虫爬淘宝,得到的页面是登录页面,需要“假登录”,获取头部headers信息,作为参数传给requests.get(url,headers = header)。
作业③
爬取学校宣传部(http://xcb.fzu.edu.cn/html/2019ztjy)的图片文件,并保存在本地。
1)JpgFileDownload
代码:
import requests
from bs4 import BeautifulSoup
import os
import re
url = "http://xcb.fzu.edu.cn/html/2019ztjy/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36"
}
html = requests.get(url, headers=headers)
html = html.text
# 获取当前根目录
root = os.getcwd()
# 改变当前目录
os.chdir("jpgfile")
if __name__ == '__main__':
# 解析网页
soup = BeautifulSoup(html, "html.parser")
imgTags = soup.find_all("img", attrs={"src": re.compile('jpg$')})
print(imgTags)
for imgTag in imgTags:
name = imgTag.get("alt")
src = imgTag.get("src")
#因为程序会保存src开头是/attach/要加上url
if src[0] == '/':
src = url + src
resp = requests.get(src, headers=headers)
with open(f"{name}.jpg", "wb") as f:
f.write(resp.content)
print(f"{name} {src} 保存成功")
结果:

2)实验心得
第三次实验还是比较简单,要爬取的图片信息格式相近,主要的还是正则表达式的应用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号