


数据库常见面试题
范式
什么是范式:简言之就是,数据库设计对数据的存储性能,还有开发人员对数据的操作都有莫大的关系。所以建立科学的,规范的的数据库是需要满足一些规范来优化数据数据存储方式。在关系型数据库中这些规范就可以称为范式。
什么是三大范式:
第一范式:当关系模式R的所有属性都不能在分解为更基本的数据单位时,称R是满足第一范式的,简记为1NF。满足第一范式是关系模式规范化的最低要求,否则,将有很多基本操作在这样的关系模式中实现不了。
第二范式:如果关系模式R满足第一范式,并且R得所有非主属性都完全依赖于R的每一个候选关键属性,称R满足第二范式,简记为2NF。
第三范式:设R是一个满足第一范式条件的关系模式,X是R的任意属性集,如果X非传递依赖于R的任意一个候选关键字,称R满足第三范式,简记为3NF.
注:关系实质上是一张二维表,其中每一行是一个元组,每一列是一个属性。
基本概念:
- 实体:现实世界中客观存在并可以被区别的事物。比如“一个学生”、“一本书”、“一门课”等等。值得强调的是这里所说的“事物”不仅仅是看得见摸得着的“东西”,它也可以是虚拟的,不如说“老师与学校的关系”。
- 属性:教科书上解释为:“实体所具有的某一特性”,由此可见,属性一开始是个逻辑概念,比如说,“性别”是“人”的一个属性。在关系数据库中,属性又是个物理概念,属性可以看作是“表的一列”。
- 元组:表中的一行就是一个元组。
- 分量:元组的某个属性值。在一个关系数据库中,它是一个操作原子,即关系数据库在做任何操作的时候,属性是“不可分的”。否则就不是关系数据库了。
- 码:表中可以唯一确定一个元组的某个属性(或者属性组),如果这样的码有不止一个,那么大家都叫候选码,我们从候选码中挑一个出来做老大,它就叫主码。
- 全码:如果一个码包含了所有的属性,这个码就是全码。
- 主属性:一个属性只要在任何一个候选码中出现过,这个属性就是主属性。
- 非主属性:与上面相反,没有在任何候选码中出现过,这个属性就是非主属性。
- 外码:一个属性(或属性组),它不是码,但是它别的表的码,它就是外码。
注:码==健
理解三大范式
第一范式
1、每一列属性都是不可再分的属性值,确保每一列的原子性。
2、两列的属性相近或相似或一样,尽量合并属性一样的列,确保不产生冗余数据。
例如,由“职工号”“姓名”“电话号码”组成的表(一个人可能有一部办公电话和一部移动电话),这时将其规范化为1NF可以将电话号码分为“办公电话”和“移动电话”两个属性,即职工(职工号,姓名,办公电话,移动电话)。
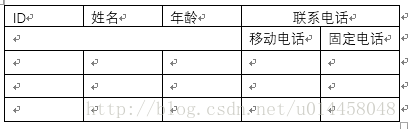 不是1NF。
不是1NF。
第二范式
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被唯一地区分,为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。每一行的数据只能与其中一列相关,即一行数据只做一件事。只要数据列中出现数据重复,就要把表拆分开来。
如果关系模型R为第一范式,并且R中的每一个非主属性完全函数依赖于R的某个候选键,则称R为第二范式模式(如果A是关系模式R的候选键的一个属性,则称A是R的主属性,否则称A是R的非主属性)。
例如,在选课关系表(学号,课程号,成绩,学分),关键字为组合关键字(学号,课程号),但由于非主属性学分仅依赖于课程号,对关键字(学号,课程号)只是部分依赖,而不是完全依赖,因此此种方式会导致数据冗余以及更新异常等问题,解决办法是将其分为两个关系模式:学生表(学号,课程号,分数)和课程表(课程号,学分),新关系通过学生表中的外关键字课程号联系,在需要时进行连接。
第三范式
如果关系模型R是第二范式,且每个非主属性都不传递依赖于R的候选键,则称R是第三范式的模式。即每个非主属性都跟候选键有直接关系而不是间接关系。像:a-->b-->c 属性之间含有这样的关系,是不符合第三范式的。主属性a可以确定出某一非主属性b,而b又可以确定出c,这意味着c依赖于一个非主属性b。因此第三范式又可描述为:表中不存在可以确定其他非主属性的非主属性。
例如,以学生表(学号,姓名,课程号,成绩)为例,其中学生姓名无重名,所以该表有两个候选码(学号,课程号)和(姓名,课程号),故存在函数依赖:学号——>姓名,(学号,课程号)——>成绩,唯一的非主属性成绩对码不存在部分依赖,也不存在传递依赖,所以属性属于第三范式。
注意:第二范式(2NF)和第三范式(3NF)的概念很容易混淆,区分它们的关键点在于,2NF:非主属性是否完全依赖于候选码,还是依赖于候选码的一部分;3NF:非主属性是直接依赖于候选码,还是间接依赖于候选码。
*BCNF(BC范式)
它构建在第三范式的基础上,如果关系模型R是第三范式,且每个属性都不传递依赖于R的候选键,那么称R为BCNF的模式。
*4NF(第四范式)
设R是一个关系模型,D是R上的多值依赖集合。如果D中存在非平凡多值依赖X->Y时,X必是R的超键,那么称R是第四范式的模式。
参考博客:https://www.cnblogs.com/ybwang/archive/2010/06/04/1751279.html
https://www.zhihu.com/question/24696366
事务
事务:用户定义的一个数据库操作序列,这些操作要么全做,要么全不做。
-
事务的概念来自于两个独立的需求:并发数据库访问,系统错误恢复。
-
一个事务是可以被看作一个单元的一系列SQL语句的集合。
事务的特性(ACID)
-
atomacity 原子性 :事务必须是原子工作单元;对于其数据修改,要么全都执行,要么全都不执行。通常,与某个事务关联的操作具有共同的目标,并且是相互依赖的。如果系统只执行这些操作的一个子集,则可能会破坏事务的总体目标。原子性消除了系统处理操作子集的可能性。
举例: A给B转帐100元钱。
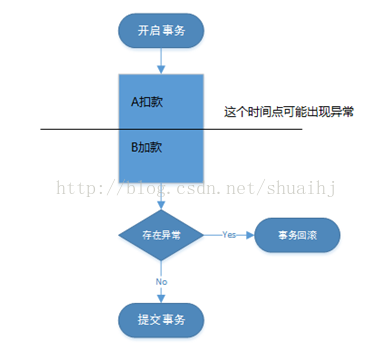
begin transaction update account set money= money - 100 where name='A'; update account set money= money +100 where name='B'; if Error then rollback else commit
在事务中的扣款和加款两条语句,要么都执行,要么就都不执行。否则如果只执行了扣款语句,就提交了,此时如果突然断电,A账号已经发生了扣款,B账号却没收到加款,在生活中就会引起纠纷。
解决方案:利用日志。
-
consistency 一致性:事务将数据库从一种一致状态转变为下一种一致状态。也就是说,事务在完成时,必须使所有的数据都保持一致状态(各种 constraint 不被破坏)。
对银行转帐事务,不管事务成功还是失败,应该保证事务结束后ACCOUNT表中aaa和bbb的存款总额为2000元。
-
isolation 隔离性:由并发事务所作的修改必须与任何其它并发事务所作的修改隔离。事务查看数据时数据所处的状态,要么是另一并发事务修改它之前的状态,要么是另一事务修改它之后的状态,事务不会查看中间状态的数据。换句话说,一个事务的影响在该事务提交前对其他事务都不可见。
-
durability 持久性:事务完成之后,它对于系统的影响是永久性的。该修改即使出现致命的系统故障也将一直保持。
事务的隔离级别
如果不对数据库进行并发控制,可能会产生异常情况:
脏读(Dirty Read)
-
当一个事务读取另一个事务尚未提交的修改时,产生脏读。
-
一个事务开始读取了某行数据,但是另外一个事务已经更新了此数据但没有能够及时提交。这是相当危险的,因为很可能所有的操作都被回滚,也就是说读取出的数据其实是错误的。
不可重复读(Nonrepeatable Read)
-
一个事务对同一行数据重复读取两次,但是却得到了不同的结果。同一查询在同一事务中多次进行,由于其他提交事务所做的修改或删除,每次返回不同的结果集,此时发生非重复读。这是由于在查询间隔,被另一个事务修改并提交了。
注:不可重复读和脏读的区别是,脏读是某一事务读取了另一个事务未提交的脏数据,而不可重复读则是读取了前一事务提交的数据。
幻读(Phantom Reads)
-
事务在操作过程中进行两次查询,第二次查询的结果包含了第一次查询中未出现的数据(这里并不要求两次查询的SQL语句相同)。这是因为在两次查询过程中有另外一个事务插入数据造成的。
-
当对某行执行插入或删除操作,而该行属于某个事务正在读取的行的范围时,会发生幻像读问题。
丢失修改(Lost Update)
-
第一类:当两个事务更新相同的数据源,如果第一个事务被提交,第二个却被撤销,那么连同第一个事务做的更新也被撤销。
-
第二类:有两个并发事务同时读取同一行数据,然后其中一个对它进行修改提交,而另一个也进行了修改提交。这就会造成第一次写操作失效。
为了兼顾并发效率和异常控制,在标准SQL规范中,MySQL数据库为我们提供的四种事务隔离级别,( Oracle 和 SQL Server 对标准隔离级别有不同的实现 )
未提交读(Read Uncommitted)
-
直译就是读未提交,意思就是即使一个更新语句没有提交,但是别的事务可以读到这个改变。
-
Read Uncommitted允许脏读。
已提交读(Read Committed)
-
直译就是读提交,意思就是语句提交以后,即执行了 Commit以后别的事务就能读到这个改变,只能读取到已经提交的数据。Oracle等多数数据库默认都是该级别。
-
Read Commited 不允许脏读,但会出现非重复读。
可重复读(Repeatable Read):
-
直译就是可以重复读,这是说在同一个事务里面先后执行同一个查询语句的时候,得到的结果是一样的。
-
Repeatable Read 不允许脏读,不允许非重复读,但是会出现幻象读。
串行读(Serializable)
-
直译就是序列化,意思是说这个事务执行的时候不允许别的事务并发执行。完全串行化的读,每次读都需要获得表级共享锁,读写相互都会阻塞。
-
Serializable 不允许不一致现象的出现。
事务隔离的实现——锁
共享锁(S锁,读锁)
-
用于只读操作(SELECT),锁定共享的资源。共享锁不会阻止其他用户读,但是阻止其他的用户写和修改。
更新锁(U锁)
-
用于可更新的资源中。防止当多个会话在读取、锁定以及随后可能进行的资源更新时发生常见形式的死锁。
独占锁(X锁,也叫排他锁,写锁)
-
一次只能有一个独占锁用在一个资源上,并且阻止其他所有的锁包括共享锁。写是独占锁,可以有效的防止“脏读”。
Read Uncommited 如果一个事务已经开始写数据,则另外一个事务则不允许同时进行写操作,但允许其他事务读此行数据。该隔离级别可以通过“排他写锁”实现。
Read Committed 读取数据的事务允许其他事务继续访问该行数据,但是未提交的写事务将会禁止其他事务访问该行。可以通过“瞬间共享读锁”和“排他写锁”实现。
Repeatable Read 读取数据的事务将会禁止写事务(但允许读事务),写事务则禁止任何其他事务。可以通过“共享读锁”和“排他写锁”实现。
Serializable 读加共享锁,写加排他锁,读写互斥。
锁必看:https://www.cnblogs.com/ismallboy/p/5574006.html
死锁产生原因:链接
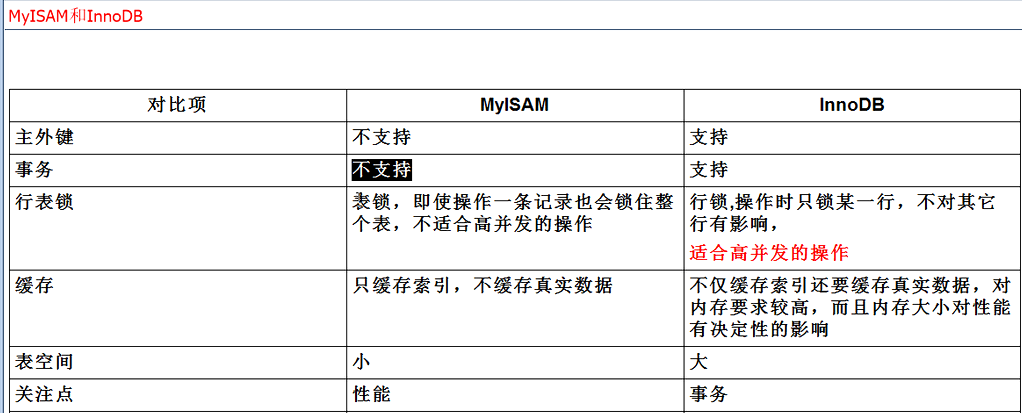
MySQL中MyISAM与InnoDB区别及选择
1、MyISAM:默认表类型,它是基于传统的ISAM类型,ISAM是Indexed Sequential Access Method (有索引的顺序访问方法) 的缩写,它是存储记录和文件的标准方法。不是事务安全的,而且不支持外键,如果执行大量的select,insert MyISAM比较适合。
2、InnoDB:支持事务安全的引擎,支持外键、行锁、事务是他的最大特点。如果有大量的update和insert,建议使用InnoDB,特别是针对多个并发和QPS较高的情况。
参考博客:https://www.cnblogs.com/lyl2016/p/5797519.html
InnoDB与MyIsam区别:
1.存储结构
MyISAM:每个MyISAM在磁盘上存储成三个文件。
InnoDB:所有的表都保存在同一个数据文件中(也可能是多个文件,或者是独立的表空间文件),InnoDB表的大小只受限于操作系统文件的大小,一般为2GB。
2.存储空间
MyISAM:可被压缩,存储空间较小。支持三种不同的存储格式:静态表(默认,但是注意数据末尾不能有空格,会被去掉)、动态表、压缩表。
InnoDB:需要更多的内存和存储,它会在主内存中建立其专用的缓冲池用于高速缓冲数据和索引。
3、 可移植性、备份及恢复
MyISAM:数据是以文件的形式存储,所以在跨平台的数据转移中会很方便。在备份和恢复时可单独针对某个表进行操作。
InnoDB:免费的方案可以是拷贝数据文件、备份 binlog,或者用 mysqldump,在数据量达到几十G的时候就相对痛苦了。
4、 事务支持
MyISAM:强调的是性能,每次查询具有原子性,其执行数度比InnoDB类型更快,但是不提供事务支持。
InnoDB:提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
5、 AUTO_INCREMENT
MyISAM:可以和其他字段一起建立联合索引。引擎的自动增长列必须是索引,如果是组合索引,自动增长可以不是第一列,他可以根据前面几列进行排序后递增。
InnoDB:InnoDB中必须包含只有该字段的索引。引擎的自动增长列必须是索引,如果是组合索引也必须是组合索引的第一列。
6、 表锁差异
MyISAM:只支持表级锁,用户在操作myisam表时,select,update,delete,insert语句都会给表自动加锁,如果加锁以后的表满足insert并发的情况下,可以在表的尾部插入新的数据。
InnoDB:支持事务和行级锁,是innodb的最大特色。行锁大幅度提高了多用户并发操作的新能。但是InnoDB的行锁,只是在WHERE的主键是有效的,非主键的WHERE都会锁全表的。
7、 全文索引
MyISAM:支持 FULLTEXT类型的全文索引
InnoDB:不支持FULLTEXT类型的全文索引,但是innodb可以使用sphinx插件支持全文索引,并且效果更好。
8、 表主键
MyISAM:允许没有任何索引和主键的表存在,索引都是保存行的地址。
InnoDB:如果没有设定主键或者非空唯一索引,就会自动生成一个6字节的主键(用户不可见),数据是主索引的一部分,附加索引保存的是主索引的值。
9、 表的具体行数
MyISAM:保存有表的总行数,如果select count(*) from table;会直接取出出该值。
InnoDB:没有保存表的总行数,如果使用select count(*) from table;就会遍历整个表,消耗相当大,但是在加了wehre条件后,myisam和innodb处理的方式都一样。
10、 CURD操作
MyISAM:如果执行大量的SELECT,MyISAM是更好的选择。
InnoDB:如果你的数据执行大量的INSERT或UPDATE,出于性能方面的考虑,应该使用InnoDB表。DELETE 从性能上InnoDB更优,但DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除,在innodb上如果要清空保存有大量数据的表,最好使用truncate table这个命令。
11、 外键
MyISAM:不支持
InnoDB:支持
选择:
因为MyISAM相对简单所以在效率上要优于InnoDB.如果系统读多,写少。对原子性要求低。那么MyISAM最好的选择。且MyISAM恢复速度快。可直接用备份覆盖恢复。
如果系统读少,写多的时候,尤其是并发写入高的时候。InnoDB就是首选了。
两种类型都有自己优缺点,选择那个完全要看自己的实际需要。
MySQL的行级锁和表级锁:参考
索引
概念
索引在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要。索引优化应该是对查询性能优化最有效的手段了。索引能够轻易将查询性能提高好几个数量级。索引相当于字典的音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查。
原理参考博客:https://www.cnblogs.com/bypp/p/7755307.html
MySQL中索引的存储类型有两种:Btree和Hash,具体和表的存储引擎相关;
MyISAM和InnoDB存储引擎只支持Btree索引,MEMORY/HEAP存储引擎可以支持Hash和Btree索引。
索引分类:
普通索引和唯一索引
- 普通索引: 数据库中的基本索引类型,允许在定义索引的列中插入重复值和空值
- 唯一索引: 索引列的值必须唯一,但允许有空值,主键索引是一种特殊的唯一索引,不允许有空值(比如自增ID)
单列索引和组合索引
- 单列索引: 即一个索引只包含单个列,一个表可以有多个单列索引
- 组合索引: 指在表的多个字段组合上创建的索引,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用
全文索引
- 全文索引: 类型为
FULLTEXT,在定义索引的列上支持值的全文查找,允许在这些索引列中插入重复值和空值。全文索引可以在CHAR、VARCHAR或者TEXT类型的列上创建,MySQL中只有MyISAM存储引擎支持全文索引
索引优点:
- 加快数据的查询速度
- 唯一索引,可以保证数据库表中每一行数据的唯一性
- 在实现数据的参考完整性方面,可以加速表和表之间的连接
- 在使用分组和排序子句进行数据查询时,也可以显著减少查询中分组和排序的时间
索引缺点:
- 占用磁盘空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果有大量的索引,索引文件可能比数据文件更快达到最大文件尺寸(合理运用,问题不大)
- 损耗性能(添加、修改、删除) 索引需要动态地维护
应该对如下的列建立索引
-
在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构。(主键自动建立唯一索引)
-
在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度。
-
在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的。
-
在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间。
-
在经常使用在where子句中的列上面创建索引,加快条件的判断速度。
有些列不应该创建索引
-
在查询中很少使用或者作为参考的列不应该创建索引。
-
对于那些只有很少数据值的列也不应该增加索引(比如性别,结果集的数据行占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度)。
- 经常要增删改的表不建索引。因为(索引只能提高查询速度,相反,会降低insert和update的速度,因为有了索引,添加数据时不仅要添加数据表,还要添加索引表,还可能调整索引表中其他数据的位置,因此索引会降低insert等语句的速度。)
创建索引的方法:直接创建和间接创建(在表中定义主键约束或者唯一性约束时,同时也创建了索引)
索引优化以及索引失效情况分析
索引失效情况:链接
全值匹配我最爱,最左前缀要遵守
带头大哥不能死,中间兄弟不能断
索引列上少计算,范围之后全失效
Like百分写最右,覆盖索引不写星
不等空值还有or,索引失效要少用
VAR引号不可丢,SQL高级也不难!
注:索引能够增加insert语句的速度么?不能,索引只能提高查询速度,相反,会降低insert和update的速度,因为有了索引,添加数据时不仅要添加数据表,还要添加索引表,还可能调整索引表中其他数据的位置,因此索引会降低insert语句的速度。
为什么说B+-tree比B 树更适合实际应用中操作系统的文件索引和数据库索引?
1) B+-tree的磁盘读写代价更低
B+-tree的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
举个例子,假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵9阶B-tree(一个结点最多8个关键字)的内部结点需要2个盘快。而B+ 树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B 树就比B+ 树多一次盘块查找时间(在磁盘中就是盘片旋转的时间)。
2) B+-tree的查询效率更加稳定
由于非叶结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
那么为什么不用红黑树呢?
因为数据量大的时候,会导致这种二叉树深度太深,io次数会很多,层数很少的b+树可以有效降低io次数。
注:
候选码就是可以区别一个元组(即表中的一行数据)的属性或属性的集合,比如学生表student(id,name,age,sex,deptno),其中的id是可以唯一标识一个元组的,所以id是可以作为候选码的,既然id都可以做候选码了,那么id和name这两个属性的组合可不可以唯一区别一个元组呢?显然是可以的,此时的id可以成为码,id和name的组合也可以成为码,但是id和name的组合不能称之为候选码,因为即使去掉name属性,剩下的id属性也完全可以唯一标识一个元组,就是说,候选码中的所有属性都是必须的,缺少了任何一个属性,就不能唯一标识一个元组了,给候选码下一个精确的定义就是:可以唯一标识一个元组的最少的属性集合。而码是没有最少属性这个要求的。另外,一个表的候选码可能有多个,从这些个候选码中选择一个做为主码,至于选择哪一个候选码,这个是无所谓的,只要是从候选码中选的就行。
至于主属性,刚才提到了,一个表可以有多个候选码,那么对于某个属性来说,如果这个属性存在于所有的候选码中,它就称之为主属性。
非主属性不包含在主码中的属性称为非主属性。
数据库完整性
1) 实体完整性:规定表的每一行在表中是惟一的实体。用PRIMARY KEY定义。
2) 域完整性:是指表中的列必须满足某种特定的数据类型约束,其中约束又包括取值范围、精度等规定。
3) 参照完整性:是指两个表的主关键字和外关键字的数据应一致,保证了表之间的数据的一致性,防止了数据丢失或无意义的数据在数据库中扩散。(FOREIGN KEY REFERENCES)
4) 用户定义的完整性:不同的关系数据库系统根据其应用环境的不同,往往还需要一些特殊的约束条件。用户定义的完整性即是针对某个特定关系数据库的约束条件,它反映某一具体应用必须满足的语义要求。
比如: primary key(主键)约束,foreign key(外键)约束,not null,unique(惟一)约束,check约束
什么是主键、外键:
元组==记录
关系型数据库中的一条记录中有若干个属性,若其中某一个属性组(注意是组)能唯一标识一条记录,该属性组就可以成为一个主键
比如
学生表(学号,姓名,性别,班级)
其中每个学生的学号是唯一的,学号就是一个主键
课程表(课程编号,课程名,学分)
其中课程编号是唯一的,课程编号就是一个主键
成绩表(学号,课程号,成绩)
成绩表中单一一个属性无法唯一标识一条记录,学号和课程号的组合才可以唯一标识一条记录,所以 学号和课程号的属性组是一个主键
成绩表中的学号不是成绩表的主键,但它和学生表中的学号相对应,并且学生表中的学号是学生表的主键,则称成绩表中的学号是学生表的外键
同理 成绩表中的课程号是课程表的外键
定义主键和外键主要是为了维护关系数据库的完整性,总结一下:
1.主键是能确定一条记录的唯一标识,比如,一条记录包括身份正号,姓名,年龄。
身份证号是唯一能确定你这个人的,其他都可能有重复,所以,身份证号是主键。
2.外键用于与另一张表的关联。是能确定另一张表记录的字段,用于保持数据的一致性。
比如,A表中的一个字段,是B表的主键,那他就可以是A表的外键。
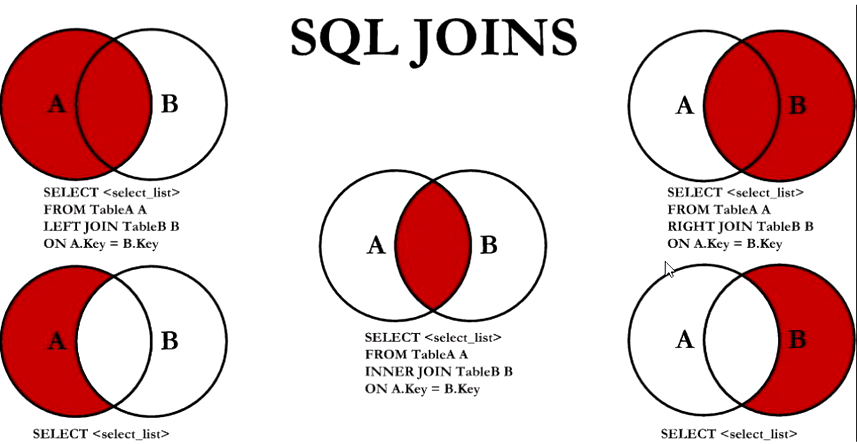
join
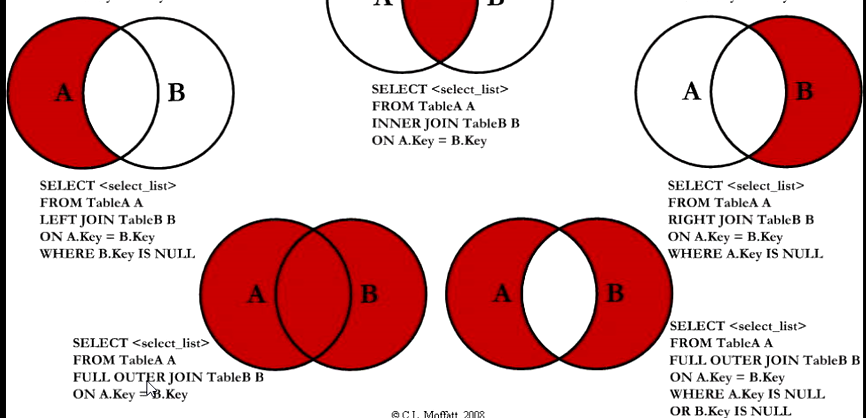
视图与表的区别与联系
数据库中的数据都是存储在表中的,而视图只是一个或多个表依照某个条件组合而成的结果集,一般来说你可以用update,insert,delete等sql语句修改表中的数据,而对视图只能进行select操作。
表是物理存在的,你可以理解成计算机中的文件!
视图是虚拟的内存表,你可以理解成Windows的快捷方式!
区别:
1、视图是已经编译好的sql语句。而表不是。
2、视图没有实际的物理记录。而表有。
3、表是内容,视图是窗口。
4、表只用物理空间而视图不占用物理空间,视图只是逻辑概念的存在,表可以及时对它进行修改,但视图只能有创建的语句来修改。
5、表是内模式,视图是外模式
6、视图是查看数据表的一种方法,可以查询数据表中某些字段构成的数据,只是一些SQL语句的集合。从安全的角度说,视图可以不给用户接触数据表,从而不知道表结构。
7、表属于全局模式中的表,是实表;视图属于局部模式的表,是虚表。
8、视图的建立和删除只影响视图本身,不影响对应的基本表。
联系:视图(view)是在基本表之上建立的表,它的结构(即所定义的列)和内容(即所有数据行)都来自基本表,它依据基本表存在而存在。一个视图可以对应一个基本表,也可以对应多个基本表。视图是基本表的抽象和在逻辑意义上建立的新关系。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号