2019暑期集训 - Day 13
这题目害人啊!!!
概述
提高 B 组
4题:T0 , T1 , T2 , T3
140/400 分
73/161 名
T0 rank
WA 40/100 分
Description
小H 和小R 正在看之前的期末 & 三校联考成绩,小R 看完成绩之后很伤心,共有 \(n\ (n\le 5000000)\) 个学生,第 \(i\) 个学生有一个总成绩 \(X_i\ (0\le X_i\le 10^5)\) ,因为他的排名是倒数第 \(k\ (1\le k\le n)\)个,于是小R 想知道那些成绩比他低(包括成绩和他一样)的同学的成绩,这样能让他没那么伤心。
Input
第一行, \(n\) 和 \(k\) ,表示有 \(n\) 个学生,小R 排倒数第 \(k\) .
第二行, \(n\) 个非负整数,表示这 \(n\) 个学生的成绩。
Output
一行,共 \(k\) 个数,从小到大输出。(相同成绩按不同排名算)
Sample Input
5 3
1 1 2 2 3
Sample Output
1 1 2
Solution
这题我都能错,哪题我还不能错???
裸的排序, sort 得加快读,桶排要从 \(0\) 开始输出。
T1 seek
MLE 40/100 分
Description
俗话说“好命不如好名”,小H 准备给他的宠物狗起个新的名字,于是他把一些英文的名字全抄下来了,写成一行长长的字符串,小H 觉得一个名字如果是好名字,那么这个名字在这个串中既是前缀,又是后缀,即是这个名字从前面开始可以匹配,从后面开始也可以匹配,例如 \(abc\) 在 \(abcddabc\) 中既是前缀,也是后缀,而 \(ab\) 就不是,可是长达 \(400000\) 的字符串让小H 几乎昏过去了,为了给自己的小狗起个好名字,小H 向你求救,并且他要求要将所有的好名字的长度都输出来。
Input
一行,要处理的字符串(都是小写字母)。
Output
一行若干个数字,从小到大输出,表示好名字的长度。
Sample Input
abcddabc
Sample Output
3 8
Solution
Hash 再也不用 map 了!!!
正解 KMP ,不想写。
歪解 Hash ,过得去,随便一个哈希函数就行,亏我还傻傻的用 map 和 set !!!
T2 pot
TLE 20/100 分
Description
这个假期,小H 在自家院子里种了许多花,它们围成了一个圈,以 \(1,2,\cdots,n\) 编号(\(n\le100000\)),小H 对每盆花都有一个喜好值 \(x_i\) ,( \(-1000\le xi\le 1000\) ),小H 现在觉得这样一成不变很枯燥,于是他做了 \(m\ (m\le 100000)\) 个改动,每次把第 \(k_i\) 盘花改成喜好值为 \(d_i\) 的花,然后小H 要你告诉他,在这个花圈中,连续的最大喜好值是多少。
Input
第一行, \(n\) ,花盆的数量。
第二行, \(n\) 个数,表示对于每盆花的喜好值。
第三行: \(m\) , 改动的次数。
以下 \(m\) 行,每行两个数 \(k_i\) 和 \(d_i\) 。
Output
\(m\) 行,每一行对应一个更改,表示连续的最大喜好值,且不能整圈都选。(注意:是在圈上找)
Sample Input
5
3 -2 1 2 -5
4
2 -2
5 -5
2 -4
5 -1
Sample Output
4
4
3
5
Solution
一个线段树要维护 \(7\) 个值,想死啊
其实它就是把喜好值当做点的权值,要我们求一个环上的最大子段和。因为环上可以首尾相接,所以我们不能用平常的方法做。
把环先当做一个序列处理。从考虑两种情况,第一种情况最大子段在序列中,即最大字段不跨越第 \(n\) 盆花和第 \(1\) 盆花;第二种情况最大子段不在序列中,即最大字段不跨越第 \(n\) 盆花和第 \(1\) 盆花。
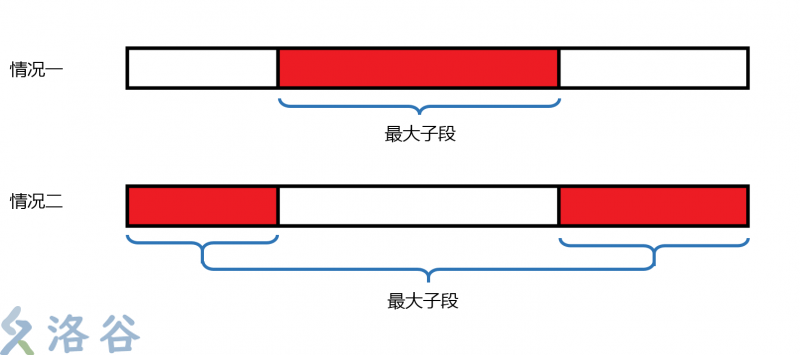 (图中红色为选中部分,白色为未选中部分)
(图中红色为选中部分,白色为未选中部分)
考虑到第二种情况中,一定在序列中间有一段未被选中,因为序列的和是一定的,而这个最大子段和又是由整个序列的和减去未被选的部分,所以未被选的部分即为最小子段和。
我们在线段树中维护 \(7\) 个值:
区间和 \(sum\)
最大子段和 \(maxs\)
最大前缀和 \(maxl\)
最大后缀和 \(maxr\)
最小子段和 \(mins\)
最小前缀和 \(minl\)
最小后缀和 \(minr\)
设 \(l_i\) 代表 \(i\) 的左子数树根, \(r_i\) 代表 \(i\) 的右子树树根,很容易得到:
sum[i]=sum[l[i]]+sum[r[i]]
maxl[i]=max(maxl[l[i]],sum[l[i]]+maxl[r[i]])
maxr[i]=max(maxr[r[i]],sum[r[i]]+maxr[l[i]])
maxs[i]=max(maxs[l[i]],maxs[r[i]],maxr[l[i]]+maxl[r[i]])
minl[i]=min(minl[l[i]],sum[l[i]]+minl[r[i]])
minr[i]=min(minr[r[i]],sum[r[i]]+minr[l[i]])
mins[i]=min(mins[l[i]],mins[r[i]],minr[l[i]]+minl[r[i]])
然后每次改变喜好值就往线段树里更新这些值。
然后答案就为 \(\max(maxs[1],sum[1]-mins[1])\) ( \(1\) 是树根)。
注意,如果 \(maxs[1]=sum[1]\) ,说明取了整个环,需要删去一个最小的点。
T3 show
TLE 40/100 分
Description
有三支队伍,分别是 \(A,B,C\) 。有 \(n\) 个游戏节目,玩第 \(i\) 个游戏,队伍 \(A\) 可以得到的分数是 \(A_i\) ,队伍 \(B\) 可以得到的分数是 \(B_i\) ,队伍 \(C\) 可以得到的分数是 \(C_i\) 。由于时间有限,可能不是每个节目都能玩,于是节目主持人决定要从 \(n\) 个游戏节目里面挑选至少 \(k\) 个节目出来(被选中的节目不分次序),使得队伍 \(A\) 成为赢家。队伍 \(A\) 能成为赢家的条件是队伍 \(A\) 的总得分要比队伍 \(B\) 的总得分要高,同时也要比队伍 \(C\) 的总得分要高。节目主持人有多少种不同的选取方案?
Input
第一行,两个整数 \(n\) 和 \(k\) 。
第二行, \(n\) 个整数,分别是 \(A_1,A_2,A_3,\cdots,A_n\) 。
第三行, \(n\) 个整数,分别是 \(B_1,B_2,B_3,\cdots,B_n\) 。
第四行, \(n\) 个整数,分别是 \(C_1,C_2,C_3,\cdots,C_n\) 。
Output
一个整数,表示不同的选取方案数量。
Sample Input
3 2
1 1 2
1 1 1
1 1 1
Sample Output
3
Hint
【样例解释】
方案一:选取节目1 和节目3 。
方案二:选取节目2 和节目3 。
方案三:选取节目1 、节目2 、节目3 。
【数据范围】
对于40% 数据, \(2\le n\le 20\)。
对于100% 数据, \(2 \le n \le 34\ ,\ 1 \le k \le \min(n,7)\ ,\ 1 \le A_i, B_i, C_i\le 10^9\) 。
Solution
又是线段树 . . .
暴力 \(O(2^n)\) 肯定只拿 \(40\) 分,正解还需要进一步优化。
观察发现, \(k\) 其实很小,我们可以先将不到 \(k\) 个节目的选取方式枚举出来,然后用总选取方式数减去它就完了。
枚举不到 \(k\) 个节目的选取方式可以直接暴搜,很快的,把这种选取方式的个数先存进 \(cnt\) 中。
现在问题就是如何算出可行的总数。
由于 \(34\) 的一半很小,我们考虑把总游戏表劈成两半,每一半分别暴力枚举每种情况的比分值,记录两个值 \(x=sum(A-B)\ ,\ y=sum(A-C)\) ,左边记录在结构体序列 \(L\) ,右边记录在结构体序列 \(R\) ,然后考虑如何合并。
很显然,当 \(L_i.x+R_j.x>0\) 且 \(L_i.y+R_j.y>0\) 时,左半边的 \(L_i\) 可以和右半边的 \(R_j\) 合并。
我们将 \(L\) 以 \(x\) 为关键字从小到大排序, \(R\) 以 \(x\) 为关键字从大到小排序。排完序后,对于每个 \(i\) 我们找到一个最大的 \(j\) 满足 \(L_i.x+R_j.x>0\) 。因为\(R\) 以 \(x\) 为关键字从大到小排序了,所以对于每个 \(k\ (1\le k\le j)\) 都有 \(L_i.x+R_k.x>0\) ,即满足第一小个条件。那么我们现在只用查询 \(R_{1\sim j}\) 中满足第二个条件的位置即可。
我们把所有的 \(L_k.y\ (1\le k\le j)\) 放入线段树中,每次查询大于 \(-L_i.x\) 的数的个数,即区间 \([-L_i.x+1,\infty ]\) 的数的个数,即为与 \(L_i\) 对应成立的个数。
循环遍历每一个 \(i\) ,结果全部加到 \(ans\) 中, \(ans-cnt\) 即为答案。
哈希
不管是对于存储字符串还是数字,哈希算法都是非常常用的时空压缩工具,而哈希算法的精髓,便是散列函数的选取。
散列函数能使对一个数据序列的访问过程更加迅速有效,通过散列函数,数据元素将被更快地定位。
常用 Hash 函数有:
- 直接寻址法。
取关键字或关键字的某个线性函数值为散列地址。即 \(H(key)=key\) 或 \(H(key) = a\times key + b\) ,其中 \(a\) 和 \(b\) 为常数(这种散列函数叫做自身函数) - 数字分析法。
分析一组数据,比如一组员工的出生年月日,这时我们发现出生年月日的前几位数字大体相同,这样的话,出现冲突的几率就会很大,但是我们发现年月日的后几位表示月份和具体日期的数字差别很大,如果用后面的数字来构成散列地址,则冲突的几率会明显降低。因此数字分析法就是找出数字的规律,尽可能利用这些数据来构造冲突几率较低的散列地址。 - 平方取中法。
取关键字平方后的中间几位作为散列地址。 - 折叠法。
将关键字分割成位数相同的几部分,最后一部分位数可以不同,然后取这几部分的叠加和(去除进位)作为散列地址。 - 随机数法。
选择一随机函数,取关键字作为随机函数的种子生成随机值作为散列地址,通常用于关键字长度不同的场合。 - 除留余数法。
取关键字被某个不大于散列表表长 \(m\) 的数 \(p\) 除后所得的余数为散列地址。即 \(H(key) = key \mod p\ ,\ p\le m\) 。不仅可以对关键字直接取模,也可在折叠、平方取中等运算之后取模。对 \(p\) 的选择很重要,一般取素数或 \(m\) ,若 \(p\) 选的不好,容易产生碰撞。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号