2019暑期集训 - Day 12
臭题目,第一题害我调一下午,第二题害我调一晚上,第四题又害我调一下午
概述
提高 B 组
4题:T0 , T1 , T2 , T3
120/400 分
15/153 名
T0 少女觉
WA 0/100 分
Description
在幽暗的地灵殿中,居住着一位少女,名为古明地觉。
据说,从来没有人敢踏入过那座地灵殿,因为人们恐惧于觉一族拥有的能力——读心。
掌控人心者,可控天下。
咳咳。
人的记忆可以被描述为一个黑块 ( \(B\) ) 与白块 ( \(W\) ) 的序列,其中情感值被定义为序列中黑块数量与白块数量之比。
小五口在发动读心术时,首先要解析人的记忆序列,因此,需要将序列分割为一些段,并且要求每一段记忆序列的情感值都相等。
下面给出两个例子:
\(BWWWBB \to BW + WWBB\ \ (Ratio=1:1)\)
$WWWBBBWWWWWWWWWB \to WWWB + BBWWWWWW + WWWB\ \ (Ratio=3:1) $
现在小五手上有一个人的记忆序列,她想要知道,如何将手中的记忆序列分成尽可能多的段呢?
Input
第一行包含一个正整数 \(T\) ,代表数据组数。
对于每一组测试数据,第一行包含一个正整数 \(N\) 。
接下来 \(N\) 行描述一个序列,每行包含一个正整数 \(K\) 和一个大写字母 \(C\) ,表示序列接下来有连续 \(K\) 个颜色为 \(C\) 的方块。
Output
对于每组测试数据输出一行一个正整数,表示最多分成的段数。
Sample Input
3
3
1 B
3 W
2 B
4
3 W
3 B
9 W
1 B
2
2 W
3 W
Sample Output
2
3
5
Hint
对于10% 的数据, \(n\leq15\)
对于20% 的数据, \(n\leq500\)
另有30% 的数据, \(K=1\)
另有30% 的数据, \(K\leq50\)
对于100% 的数据, \(N\leq10^5\) ,序列长度不超过 \(10^9\)
保证对于全部测试点,输入文件行数不超过 \(2500000\)
Solution
暴力出奇迹
贪心暴搜
因为整体比例是固定的,所以我们可以用总的 \(B\) 和 \(W\) 的格数相除得到比值,这个比值就应作为每段中 \(B\) 和 \(W\) 的比值。
很容易证明,对于一个记忆序列的最优解,应当每段尽量早的分出去,也就是说,没碰到一次可以分出一段的情况,就该分出这一段。所以这个题目满足贪心策略。
考虑到序列长度可能很大,我们可能无法一个一个方块枚举计算,所以我们存储连续相同颜色的格子数。
比如对于 \(BBBWB\) 我们存储为 \(3,1,1\) ;对于 \(WWWBBBWWWWWWWWWB\) ,我们存储为 \(0,3,3,9,1\)(默认以 \(B\) 开始,次样例中第一个 \(0\) 代表最开始有 \(0\) 个 \(B\))。
从第一个数开始向后推,每次更新上次分段的结束点之后到此位置中 \(B\) 和 \(W\) 的格数,然后判断加入这一串格子中的一部分后是否能分为一段(即能否达到需要的比值),如果能,则将这部分分为一段,记录 ans++ 。
最后答案即分段数就是 ans。
T1 灵知的太阳信仰
WA 0/100 分
Description
在炽热的核熔炉中,居住着一位少女,名为灵乌路空。
据说,从来没有人敢踏入过那个熔炉,因为人们畏缩于空所持有的力量——核能。
核焰,可融真金。
咳咳。
每次核融的时候,空都会选取一些原子,排成一列。然后,她会将原子序列分成一些段,并将每段进行一次核融。
一个原子有两个属性:质子数和中子数。
每一段需要满足以下条件:
- 同种元素会发生相互排斥,因此,同一段中不能存在两个质子数相同的原子。
- 核融时,空需要对一段原子加以防护,如果这段原子的中子数最大为 \(x\) ,那么需要付出 \(x\) 的代价建立防护罩。
$ $
求核融整个原子序列的最小代价和。
Input
第一行一个正整数 \(N\) ,表示原子的个数。
接下来 \(N\) 行,每行两个正整数 \(p_i\) 和 \(h_i\) ,表示第 \(i\) 个原子的质子数和中子数。
Output
输出一行一个整数,表示最小代价和。
Sample Input
5
3 11
2 13
1 12
2 9
3 13
Sample Output
26
Hint
对于20% 的数据, \(1\leq n\leq 100\)
对于40% 的数据, \(1\leq n\leq 1000\)
对于100% 的数据, \(1\leq n\leq 10^5\) , \(1\leq p_i\leq n\) , \(1\le h_i\le 20000\)
Solution
DP 累死人
这题使用贪心策略肯定是有问题的,比如如下数据点:
3
1 1
2 5
1 3
使用贪心策略尽可能取每个原子时,这个点的答案为 \(5+3=8\) ,而正解答案应为 \(1+5=6\)
考虑使用动态规划完成,记 \(f_i\) 代表取前 \(i\) 个原子所需的最小代价,\(s_{i,j}\) 代表第 \(i\) 个原子到第 \(j\) 个原子的中子数最大值。
记录 \(l_i\) 代表从第 \(i\) 个原子开始向左能取到的最左边的位置,即 \(l_i\) 至 \(i\) 这两个位置间没有重复质子数,但 \(l_i-1\) 至 \(i\) 这两个位置间有重复质子数。
很容易得到, \(f_i=f_j+\min(s_{j+1,i})\) ,即前 \(j\ (j\ge l_i)\) 个数先分段,最后加上从 \(j\) 到 \(i\) 这一段。
然而,这样做时间复杂度 \(O(N^2)\) ,会 TLE ,所以考虑如何优化。
用一个单调递减的单调队列,维护 \(s_{l_i,i}\sim s_{i,i}\) ,即对于位置 \(i\) 所有可能取值 \(j\) ,\(s_{j+1,i}\) 的值。所以每次队首的位置 \(< l_i\) 时,就把它踢出队列,如果队尾的 \(s\) 值 \(\le h_i\) ,将队尾元素弹出,并加入 \(h_i\) 。这是因为对于位置 \(i\) 即其之后,既然队首元素的位置 \(<l_i\) ,所以从这个位置开始根本取不到第 \(i\) 个原子,对于更新 \(f_i\) 没有意义;如果队尾的 \(s\) 值 \(\le h_i\) ,则完全可以使用 \(h_i\) 更新以后的 \(f\) 值,队尾的 \(s\) 值也没有任何意义了。
这样,每次更新 \(f_i\) 时,只用队列里的 \(s\) 值更新就可以了。
最后的答案即为 \(f_n\) 。
T2 多段线性函数
AC 100/100 分
Description
有 \(n\) 个变量 \(x_1,x_2,\cdots,x_n\) ,满足 \(x_i\in \mathbb{R}\) 。对于每个变量,都有一个限制: \(x_i\in [l_i,r_i]\) 。人员两个变量的取值不互相影响。
小Z 给你一个多段线性函数:
\(\large{f(y)=\sum_{i=1}^{n}|y-x_i|}\)
定义这个函数的局部最小值 \(f_{\min}(y_0)\) 为:当 \(y\) 取某个值 \(y_0\) 时,存在一种 \(x_i\) 的取值方案使得函数值为 \(f_{\min}(y_0)\) ,且对于所有的 \(x_i\) 的取值方案,都有 \(f(y_0)\geq f_{\min}(y_0)\) 。
定义这个函数的全局最小值 \(f_{\min}\) 为:存在某个 \(y=y_0\) ,使得 \(f_{\min}(y_0)=f_{\min}\) ,且对于所有的 \(y\) ,都有 \(f_{\min}(y)\ge f_{\min}\) 。
你的任务是求出 \(y\) 的取值范围 \([L,R]\) ,使得对于所以的 \(y\in [L,R]\) ,都有 \(f_{\min}(y)=f_{\min}\) 。
可以证明 \([L,R]\) 是答案的一般形式,也就是说不存在多段的 \(y\) 满足题意。如果 \(y\) 仅能取一个值 \(z\) ,令 \(L=R=z\) 。
Input
第一行包含一个正整数 \(n\) 。
接下来 \(n\) 行,每行两个非负整数 \(l_i,r_i\) 。
Output
输出一行两个自然数,用空格隔开,依次为 \(L,R\) 。
Sample Input
5
1 3
2 3
3 5
5 5
6 7
Sample Output
3 5
Hint

Solution
口胡出正解
做法很简单,一起记录 \(l_i,r_i\) , sort ,输出中位数即最中间的两个数,没了。
至于证明 . . .
考虑另一个数
\(\large{s_t=\min(\ \sum_{i=1}^{n}2|t-x_i|+r_i-l_i}\ )\)
很容易得到 \(|t-x_i|\) 的值要么为 \(0\ (l_i\le t\le r_i)\) ,要么为 \(l_i-t\ (t<l_i)\) 或 \(t-r_i\ (t>r_i)\) 。而 \(2|t-x_i|+r_i-l_i\) 则一定等于 \(|t-l_i|+|t-r_i|\) ,即
\(\large{s_t=\min(\ \sum_{i=1}^{n}|t-l_i|+|t-r_i|}\ )\)
可以通过分类讨论的思想证明:
$\ \ \ \ 2|t-x_i|+r_i-l_i $
\(=0+r_i-l_i\)
\(=|t-l_i|+|t-r_i|\)
\(\ \ \ \ \ (l_i\le t\le r_i)\)
\(=2l_i-2t+r_i-l_i\)
\(=(r_i-t)+(l_i-t)\)
\(=|t-l_i|+|t-r_i|\)
\(\ \ \ \ \ (t<l_i)\)
\(=2t-2r_i+r_i-l_i\)
\(=(t-r_i)+(t-l_i)\)
\(=|t-l_i|+|t-r_i|\)
\(\ \ \ \ \ (t>r_i)\)
用数轴和绝对值的几何意义更好理解。
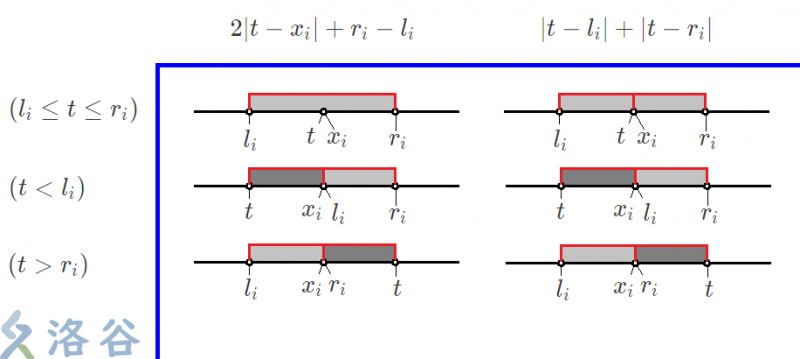
图中浅灰色代表算过一次,深灰色代表算过两次。
可以发现,两个计算的结果完全相同。
并且,我们发现,公式中,比原式多出的系数 \(2\) 和 \(\sum_{i=1}^{n}r_i-l_i\) 都是定值,不影响结果的大小比较。也就是说,当 \(s_t=s_{\min}\) 时, \(f_{\min}(t)=f_{\min}\) 。所以,我们只需求满足前式 \(s_t=s_{\min}\) 中 \(t\) 的取值范围就行了。
现在,我们把所有的 \(l_i,r_i\) 列入集合 \(d\) 中,问题变成了求
\(\large{\min(s_t=\ \sum_{i=1}^{2n}|t-d_i|}\ )\)
即将 \(d\) sort 后的中位数为 \(t\) 的取值范围。
T3 DY引擎
WA 20/100 分
Description
BOSS 送给小唐一辆车。小唐开着这辆车从 PKU 出发去 ZJU 上课了。
众所周知,天朝公路的收费站超多的。经过观察地图,小唐发现从PKU出发到ZJU的所有路径只会有 \(N\ (2\le N\le 300)\) 个不同的中转点,其中有 \(M\ (\max(0,N-100) \le M\le N)\) 个点是天朝的收费站。 \(N\) 个中转点标号为 \(1,2,\cdots ,N\),其中 \(1\) 代表 PKU , \(N\) 代表 ZJU 。中转点之间总共有 \(E\ (E\le 50,000)\) 条双向边连接。
每个点还有一个附加属性,用 \(0/1\) 标记, \(0\) 代表普通中转点, \(1\) 代表收费站。当然,天朝的地图上面是不会直接告诉你第 \(i\) 个点是普通中转点还是收费站的。地图上有 \(P\ (1\le P\le 3000)\) 个提示,用 \([u, v, t]\) 表示: \([u, v]\) 区间的所有中转点中,至少有 \(t\) 个收费站。数据保证由所有提示得到的每个点的属性是唯一的。
车既然是 BOSS 送的,自然非比寻常了。车子使用了世界上最先进的 DaxiaYayamao 引擎,简称 DY 引擎。 DY 引擎可以让车子从 \(U\) 瞬间转移到 \(V\) ,只要 \(U\) 和 \(V\) 的距离不超过 \(L\ (1\le L\le 1000000)\),并且 \(U\) 和 \(V\) 之间不能有收费站(小唐良民一枚,所以要是经过收费站就会停下来交完钱再走)。
DY 引擎果然是好东西,但是可惜引擎最多只能用 \(K\ (0\le K\le 30)\) 次。
Input
第一行有 \(6\) 个整数 \(N,M,E,P,L,K\) 分别代表: \(N\) 个中转点, \(M\) 个收费站, \(E\) 条边, \(P\) 个提示, DY 引擎的有效距离 \(L\) , DY 引擎的使用次数 \(K\) 。
接下去 \(E\) 行,每行有 \(3\) 个整数 $u,v,w\ (1\le u,v\le N;1\le w\le 1000000)\ $ 表示: \(u\) 和 \(v\) 之间有一条长度为 \(w\) 的双向边。
接下去 \(P\) 行,每行有 \(3\) 个整数 \(u,v,t\ (1\le u\le v\le N; 0\le t\le u-v+1)\) 表示: \([u, v]\) 标号区间至少有 \(t\) 个收费站。
Output
输出一个整数,表示小唐从 PZU 开到 ZJU 用的最短距离(瞬间转移距离当然是按 \(0\) 来计算的)。
Sample Input
6 2 6 2 5 1
1 2 1
2 3 2
3 6 3
1 4 1
4 5 2
5 6 3
2 5 2
4 6 2
Sample Output
1
Hint
【样例解释】
\(4,5\) 是收费站。 \(1\to 2(1)\to 6(1)\)
【数据范围】
对于30% 的数据保证:
\(2\le N\le 30\ ,\ \max(0,N-10) \le M\le N\ ,\ 0\le k\le 10\)
对于100% 的数据保证:
\(2\le N\le 300\ ,\ \max(0,N-100) \le M\le N\ ,\ E\le 50000\ ,\ 1\le P\le 3000\ ,\ 1\le L\le 1000000\ ,\ 0\le K\le 30\)
Solution
有必要把两个小题硬凑在一起吗?
差分约束 + 分层最短路
把每个收费站的提示当做一个不等式,因为题目保证只有唯一解,所以用差分约束解出每个点是否为收费站 ( SPFA ,最短路\(\times1\))
枚举任意两个点间是否可以瞬移 ( Floyd ,最短路\(\times 2\))
把图复制为 \(K+1\) 层,分别代表已开 \(0,1,2,\cdots,K\) 次挂对应的那一层,每两层的分别某个点如果可瞬移(上已枚举哪两个点可以互相瞬移),就在它们间连一条权值为 \(0\) 的边用来开挂。
从 \(1\) 开始跑一边最短路(最短路\(\times 3\)),然后对每层第 \(n\) 个点的 \(dist\) 取 \(\min\) ,结果即为答案。
最后也就 \(3\) 遍最短路, \(200\) 行左右吧。
差分约束
如果一个系统由 \(n\) 个变量和 \(m\) 个约束条件组成,形成 \(m\) 个形如 \(a_i-a_j\le k\) 的不等式( \(i,j∈[1,n]\),\(k\)为常数),则称其为差分约束系统( system of difference constraints )。
求解差分约束系统,可以转化成图论的单源最短路径(或最长路径)问题。
观察 \(x_j-x_i\le b_k\) ,会发现它类似最短路中的三角不等式 \(d[v]\le d[u]+w[u,v]\) ,即 \(d[v]-d[u]\le w[u,v]\) 。因此,以每个变量 \(x_i\) 为结点,对于约束条件 \(x_j-x_i\le b_k\) ,连接一条边 \((i,j)\) ,边权为 \(b_k\) 。我们再增加一个源点 \(s\) , \(s\) 与所有定点相连,边权均为 \(0\) 。对这个图,以 \(s\) 为源点运行 Bellman-ford 算法(或 SPFA 算法),最终 \(d[ i]\) 即为一组可行解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号