Scrapy 概览笔记
本项目代码可参考 imzhizi/myspider: a scrapy demo with elasticsearch
虚拟环境的创建
建议爬虫项目都创建虚拟环境
虚拟环境在 Python 项目中真的非常重要并且非常有意义
虚拟空间的使用可参考 Python 虚拟空间的使用 - 难以想象的晴朗.
# 创建虚拟环境
mkdir spider-demo
cd spider-demo
python3 -m venv spidervenv
# 进入虚拟环境
source spidervenv/bin/activate
# 安装 Scrapy
pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple
新建项目
# 使用 scrapy 新建工程
scrapy startproject myspider
# 此时文件夹中会创建一个 myspider 文件夹
# 项目结构大概是
spider-demo # 根文件夹
├── myspider # 创建的爬虫项目, 若使用 IDE, 可把此文件夹当作根文件夹
│ ├── myspider # 真正的爬虫代码文件夹
│ │ ├── __init__.py
│ │ ├── items.py # 用于规定爬取数据形成的 model
│ │ ├── middlewares.py # 中间件
│ │ ├── pipelines.py # 流水线, 决定了爬取的数据的流向
│ │ ├── settings.py # 配置信息
│ │ └── spiders # 爬虫代码所在地
│ │ ├── __init__.py
│ │ └── __pycache__
│ └── scrapy.cfg # 项目设置
└── spidervenv # 此处为虚拟环境文件, 已经忽略
新建爬虫
# 首先来到爬虫代码文件夹
cd myspider/myspider/spiders
# 使用 scrapy genspider 创建简单的爬虫模版
# 会在 spiders 文件夹下创建名为 doubanSpider.py 的文件, 同时该爬虫也命名为 doubanSpider
scrapy genspider doubanSpider douban.com
PyCharm 适配
经过一系列创建操作, 基本上一个爬虫应该有的组件就都准备好了, 一般情况下会使用命令 scrapy crawl name 启动爬虫, 但为了方便 IDE (PyCharm) 中直接开始爬虫, 一般会在 spider-demo/myspider 文件夹下创建 start.py 文件, 其中包含以下代码
若使用 PyCharm 打开项目,还需将 interpreter 改为 spidervenv
from scrapy.cmdline import execute
import sys
import os
# 将系统当前目录设置为项目根目录
# os.path.abspath(__file__) 为当前文件所在绝对路径
# os.path.dirname 为文件所在目录
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute(["scrapy", "crawl", "doubanSpider"])
工作流程
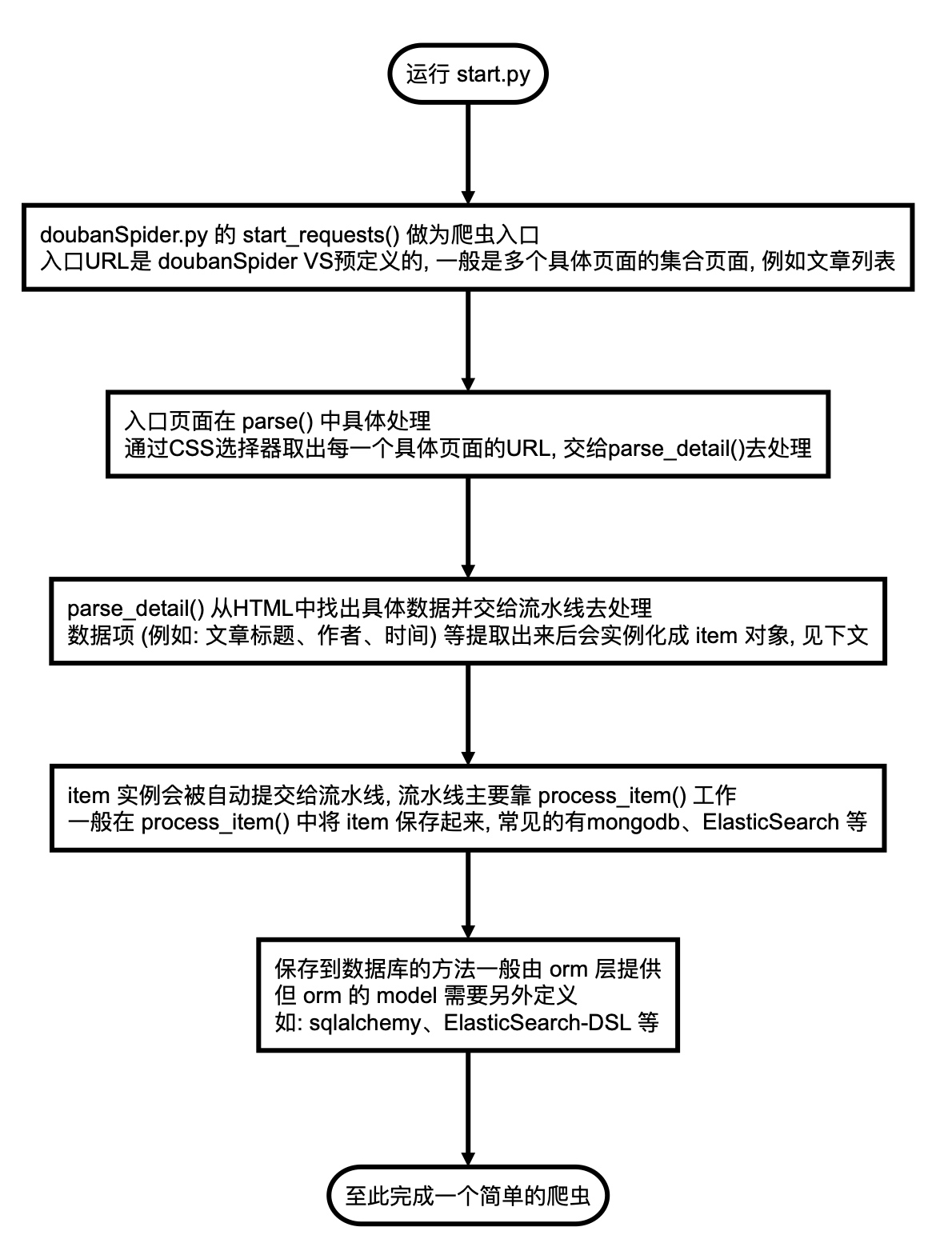 

流程图中部分代码的参考
# items.py
class DoubanItem(scrapy.Item):
title = scrapy.Field()
douban_link = scrapy.Field()
rating = scrapy.Field()
def save_to_db():
douban = DoubanModel()
douban.title = self['title']
douban.douban_link = self['douban_link']
douban.rating = self['rating']
douban.save()
# pipelines.py
class DoubanPipeline(object):
def process_item(self, item, spider):
item.save_to_db()
return item
# ES model, 继承的 Document 提供了 save() 方法
# 一般保存在 spiders 文件夹上层
class DoubanType(Document):
title = Text()
douban_link = Text()
rating = Double()
其他配置
为了让爬虫顺利进行, 需要对 settings.py 进行一些修改
# settings.py
## 不遵守 robot.tx 规则
ROBOTSTXT_OBEY = False
## 下载延迟
DOWNLOAD_DELAY = 3
## 用户代理( 爬豆瓣用 )
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
## 请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
## 启用的流水线
ITEM_PIPELINES = {
'myspider.pipelines.MyspiderPipeline': 300,
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号