机器学习简介
机器学习简介
Learn from data、深度学习
经典定义:利用经验改善系统自身的性能 [T. Mitchell 教科书, 1997]。
数据 -> 算法 -> 模型
基本术语
数据:
-
数据集;训练;测试
-
示例(instance);样例(example)
-
样本(sample)
-
属性(attribute);特征(feature);属性值
-
属性空间;样本空间;输入空间
-
特征向量(feature vector)
-
类别标记(label)
-
标记空间;输出空间
模型:
-
假设(hypothesis)
-
真相(ground-truth)
-
学习器(learner)
任务:
- 分类(离散);回归(连续)
- 二分类;多分类
- 正类;反类
是否有标注信息:
-
监督学习(supervised learning)
-
无监督学习(unsupervised learning)
-
自监督学习(self-supervised learning)
测试:
- 未见样本(unseen instance)
- 未知“分布”
- 独立同分布(i.i.d.)
- 泛化(generalization)
典型的机器学习过程
什么模型好?
泛化能力强:能很好地适用于unseen instance,错误率低,精度高。
机器学习有坚实的理论基础
计算学习理论(Computational learning theory)
最重要的理论模型:PAC(Probably Approximately Correct,概率近似正确)learning model [Valiant, 1984]
归纳偏好(Inductive Bias)
机器学习算法在学习过程中对某种类型假设的偏好。
一般原则:奥卡姆剃刀——若非必要勿增实体
任何一个有效的机器学习算法必有其偏好。
学习算法的归纳偏好是否与问题本身匹配,大多数时候直接决定了算法能否取得好的性能。
没有免费午餐(NFL)定理:一个算法 \(\mathcal{L}_a\) 若在某些问题上比另一个算法 \(\mathcal{L}_b\) 好,必存在另一些问题 \(\mathcal{L}_b\) 比 \(\mathcal{L}_a\) 好。
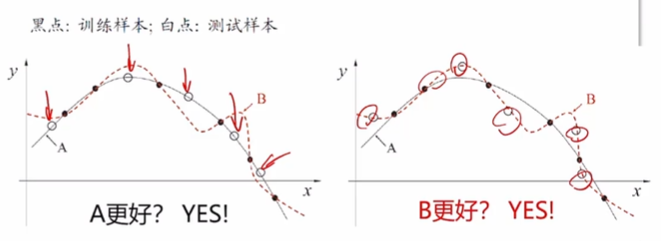
评估方法
关键:怎么获得“测试集”(test set)?
测试集应该与训练集“互斥”
常见方法:
- 留出法(hold-out)
- 交叉验证法(cross validation)
- 自助法(bootstrap)
留出法
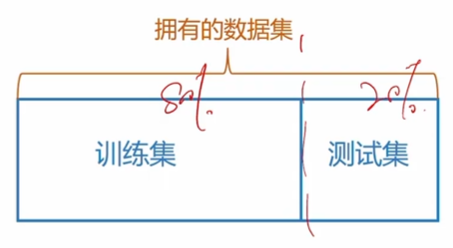
注意:
- 保持数据分布一致性(例如:分层采样)
- 多次重复划分(例如:100次随机划分)
- 测试集不能太大、不能太小(例如:1/5~1/3)
\(k\)-折交叉验证法
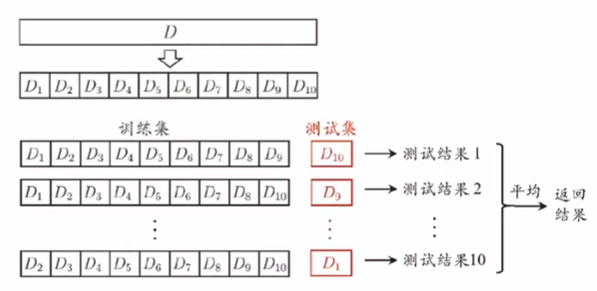
若 \(k=m\) ,则得到“留一法”(leave-one-out, LOO)
性能度量
性能度量(performance measure)是衡量模型泛化能力的评价标准,反映了任务需求。
使用不同的性能度量往往会导致不同的评判结果。
什么样的模型是“好”的,不仅取决于算法和数据,还取决于任务需求。
-
回归(regression)任务常用均方误差(MSE):
\[E(f;D) = \frac{1}{m}\sum_{i=1}^m(f(x_i) - y_i)^2 \] -
错误率:
\[E(f;D) = \frac{1}{m}\sum_{i=1}^m\mathbb{I}(f(x_i)\neq y_i) \] -
精度:
\[\begin{align} acc(f;D) &= \frac{1}{m}\sum_{i=1}^m\mathbb{I}(f(x_i) = y_i) \\ &= 1 - E(f;D) \end{align} \]
线性模型
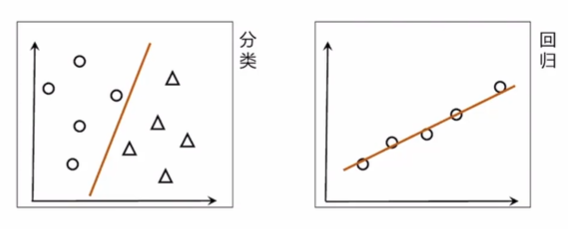
线性模型(linear model)试图学得一个通过属性的线性组合来进行预测的函数。
向量形式
线性回归(Linear Regression)
离散属性的处理:若有“序”(order),则连续化;否则,转化为 \(k\) 维向量。
令均方误差最小化,有
对 \(E_{(\boldsymbol{w},b)} = \sum_{i=1}^m(y_i-\boldsymbol{w}^\mathrm{T}\boldsymbol{x}_i-b)^2\) 进行最小二乘估计。
优化目标
基本思路:优化模型的经验误差,同时控制模型的复杂度。
其中 \(\mathscr{l}_{0/1}\) 是 \(0/1\) 损失函数(0/1 loss function)
障碍:\(0/1\) 损失函数非凸、非连续,不易优化!
替代损失(Surrogata Loss)
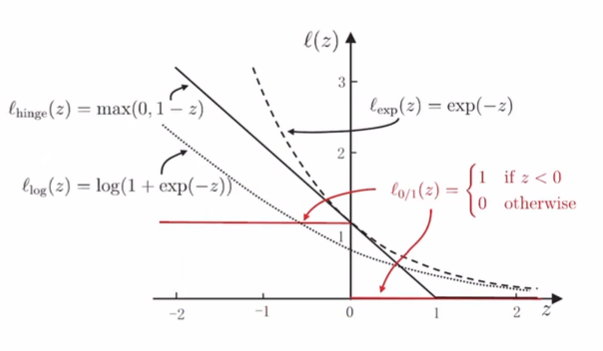
- 采用替代损失函数,是在解决困难问题时的常见技巧。
- 求解替代函数得到的解是否仍是原问题的解?理论上成为替代损失的“一致性”(Consistency)问题。
软间隔支持向量机(Soft-margin Support Vector Machine)
原始问题
引入“松弛量”(Slack Varinbles)\(\xi_i\)
对偶问题
正则化(Regularization)
统计学习模型(例如SVM)的更一般形式
正则化项 \(\Omega(f)\) :结构风险(Structural Risk)描述模型本身的某些性质,归纳偏好。
损失函数 \(l(f(\boldsymbol{x}_i),y_i)\) :经验风险(Empirical Risk)描述模型与训练数据的契合程度。
- 正则化可理解为“罚函数法”,通过对不希望的结果施以惩罚,使得优化过程趋向于希望目标。
- 从贝叶斯估计的角度,则可认为是提供了问题的先验概率。
多层前馈网络结构
-
多层网络:包含隐层的网络。
-
前馈网络:神经元之间不存在同层连接也不存在跨层连接。
-
隐层和输出层神经元亦称“功能单元”(Functional Unit)。
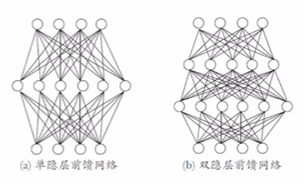
多层前馈网络有强大的表示能力(“万有逼近性”):
仅需一个包含足够多神经元的隐层,多层前馈神经网络就能以任意精度逼近任意复杂度的连续函数 [Hornik et al., 1989]。
但是,如何设置隐层神经元数是未决问题(Open Problem),实际常用“试错法”。
”简单单元“:神经元模型
M-P神经元模型 [McCulloch and Pitts, 1943]
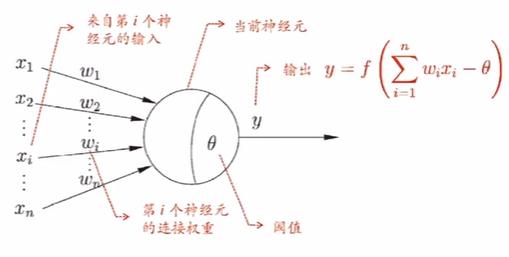
神经网络学得的知识蕴含在连接权与阈值中。
决策树模型
决策树基于”树“结构进行决策
- 每个”内部节点“对应于某个属性上的”测试“(test)。
- 每个分支对应于该测试的一种可能结果(即该属性的某个取值)。
- 每个”叶节点“对应于一个”测试结果”。
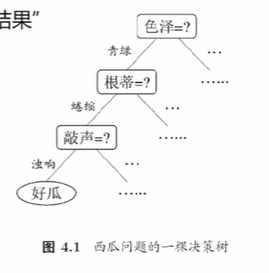
学习过程:通过对训练样本的分析来确定“划分属性”(即内部节点所对应的属性)。
预测过程:将测试示例从根节点开始沿着划分属性所构成的“判定测试序列“下行,直到叶节点。
策略:“分而治之”(divide-and-conquer)
优化方法
无约束优化
- 零阶优化方法:\(f(\boldsymbol{x})\) .
- 一阶优化方法:\(f(\boldsymbol{x}),\nabla f(\boldsymbol{x})\) .
- 高阶优化方法:\(f(\boldsymbol{x}),\nabla f(\boldsymbol{x}),\nabla^2f(\boldsymbol{x}),\dots\) .
- 随机优化方法:随机子集.
类别不平衡(class-imbalance)
不同类别的样本比例相差很大;“小类”往往更重要。
基本思路:
\(y\) 正类概率
基本策略——“再缩放”(rescaling):
然而,精确估计 \(\frac{m^-}{m^+}\) 通常很困难!
常见类别不平衡学习方法:
- 过采样(oversampling)
例如:SMOTE - 欠采样(undersampling)
例如:EasyEnsemble - 阈值移动(threshold-moving)
多分类学习
拆解法:将一个多分类任务拆分为若干个二分类任务求解。
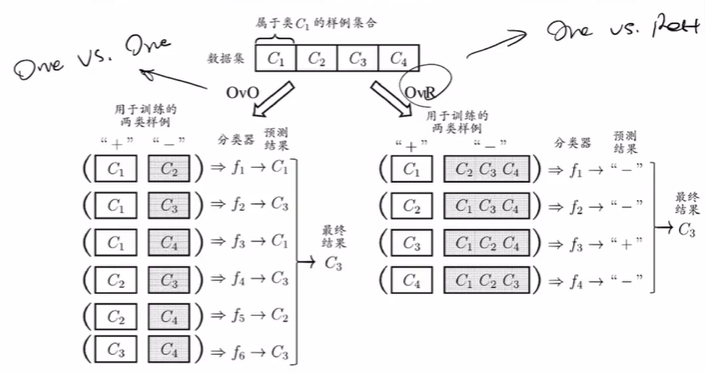
OvO:
- 训练 \(\frac{N(N-1)}{2}\) 个分类器,存储开销和测试时间大。
- 训练只用两个类的样例,训练时间短。
OvR:
- 训练 \(N\) 个分类器,存储开销和测试时间小。
- 训练用到全部训练样例,训练时间长。
预测性能取决于具体数据分布,多数情况下两者差不多。
讨论
传统机器学习方法 vs. 当代大模型方法




 浙公网安备 33010602011771号
浙公网安备 33010602011771号