务虚:建立团队的性能文化
之前的性能测试博客大多都是介绍性能测试的方法、思路以及测试工具的使用,可以称之为“务实”。这篇博客,聊聊“务虚”——如何建立团队的性能文化。。。
首先来看看团队中不同角色,他们对性能的关注点都是什么?然后拆分开,从不同视角聊聊如何针对性的建立团队的性能文化。。。
不同视角的性能关注点
| 角色视角 | 性能关注点 |
| 产品 | 用户数、使用时间、使用场景 |
| 开发 | 系统架构、代码设计、内存使用、通信方式 |
| 测试 | 系统性能表现是否满足性能需求指标:TPS/RT/CPU%/Memory%/Success% |
| 运维 | 资源使用率、系统容量、扩展性、稳定性 |
一、产品
对于产品童鞋而言,不会直接考虑到系统性能,而更多的是需要关注有多少用户数,他们在什么时间段使用我的产品,使用频次最高的场景是哪些等因素。
1、用户数
已有用户数:即系统已有的用户数,通常意义上性能测试中所谓的模拟用户数(并发)都是通过已有用户的数量,按照二八原则来进行预估。
所谓的“二八原则”,即80%的用户在20%的时间访问系统,进行业务场景的交互操作。
活跃用户数:如果要更进一步的划分用户类型的话,DAU(日活)是个很好的维度,通过监控,可以看出有多少用户在什么时间段进行了哪些业务操作,
各个不同的业务场景,在系统使用高峰时,各自的占比时长等。
潜在用户数:有时候由于业务快速发展或者用户引流渠道的拓展,会带来短期内的用户注册和使用频次的激增,这个时候,激增的用户数和对系统的高频使用,
会给系统带来巨大的负担,对类似这样的情况做到心中有数,做好应对方案,可以很大程度上避免系统出错甚至服务不可用的尴尬局面。
2、使用时间
高峰时间:即用户使用系统最频繁的时间段,以及使用系统的用户量较大的时间。这种时间维度的划分需要一些定量的指标来区分,可以根据具体的业务场景来对待。
平缓时间:即用户日常使用时间段,这个可以从使用频次和使用人数上来设定一个阈值,进而针对性的划分时间区间。
特殊时间:比如双十一,比如一些特卖或者秒杀活动,短时间内的用户数和使用频次的激增,会对系统造成很大的负担,如果不提前做好应对措施,很可能会造成一些不好的影响。
3、使用场景
高频业务场景:以电商网站举例,首页、搜索、商品明细页,这些场景可以说是用户高频访问的场景。
基础业务场景:同样以电商网站举例,用户注册、登录、搜索、商品分类可以算作基础业务场景,即用户使用产品所必须涉及到的业务场景(当然,和其他类型的场景存在重叠)。
核心业务场景:同上,购物车,支付,可以看做电商网站的核心业务场景。
特殊业务场景:比如某个促销或者秒杀业务场景,属于短期的有时效性但访问频次较高的,都可划归到特殊业务场景。
PS:上面的几种产品视角的关注点,更多的是从产品分析、需求分析的角度去看待和分类,如果能从产品设计或者需求阶段就考虑到这些因素带来的影响,
那么产品(或者说业务)更多的作为需求发起方,就可以在后续的开发测试运维阶段,让参与的童鞋都尽可能考虑到这些因素从技术角度该如何应对,
从而降低系统上线后所面对的性能风险,或者说有针对性的应对方案。
二、开发
1、系统架构
根据业务需求,用户场景以及未来可能的业务变化,系统架构设计要考虑到系统的稳定性、扩展性以及可迁移性。
比如是否采用集群/分布式,是否需要考虑多级缓存,数据库是否需要读写分离、主从热备等方式。
2、代码设计
在项目的开始阶段,一件必不可少的的事情就是就是确定代码的分层和架构,它在一定程度上决定了未来整个项目的代码风格。下面列举一些代码设计的目的和需要遵循的原则:
| 目的 | 原则 |
| 提供更好的可读性 | 经济原则 |
| 提高可维护性 | 最小可用原则 |
| 降低代码冗余 | 代码复用原则 |
| 高内聚低耦合 | 奥卡姆剃刀原则 |
关于代码设计需要遵循的原则,详细内容可参考这里:美团技术团队-性能优化模式
PS:当然,良好的代码设计,还包括开发规范、良好的命名方式、review、静态代码扫描等多种方式。
3、内存使用
这里的内存使用包括内存分配是否合理、代码运行是否会导致OOM、线程锁之类的问题。
4、通信方式
根据具体的业务需求,通信方式采用同步还是异步?同步和异步各自的优缺点是什么?如果采用异步,框架选型如何考虑?举个例子:
比如最常见也最重要的支付场景,对数据一致性和实时性要求很高,那么同步通信方式相比于异步,就更适合业务需求。
三、测试
1、性能测试指标
常见的性能测试指标包括TPS、RT、ART、CPU使用率、事务成功率、Memory使用率,指标的存在目的是为了对系统的性能表现有一个直观的衡量依据。
2、性能测试场景
场景,一句话概括的话就是:什么人(用户)在什么时间(峰值/平缓/异常)进行了哪些操作(比如支付、搜索)。
3、性能测试目的
进行性能测试的目的是什么?新系统上线投产前的容量测试?已有系统迭代的性能变化验证?性能基线的确定?异常流量下的容错处理和灾难恢复速率?
4、性能测试结果
系统性能表现是否满足需求?是否达到预期?存在什么风险,可能造成的影响是什么,解决方案/容灾策略是什么?
四、运维
1、资源使用率
CPU、内存使用占比是否合理?资源报警阈值如何设定?峰值流量时磁盘IO速率、日志占比等。
一般来说,应用日志占比不要超过磁盘的30%,CPU、内存达到75%就需要重点关注,超过85%,就需要针对性的进行扩容或者降级处理。
2、系统容量
在当前的系统服务配置下,单台服务在阈值下所能提供的最大处理能力。
举例:某个特定业务场景,在2C4G的配置下,CPU使用率为90%,TPS最大值为10笔/秒,RT为0.2S,事务成功率100%。
3、扩展性
随着用户数、使用频次的增加,系统能否及时的进行服务扩展,扩展的速率、利用率等。
4、稳定性
系统稳定性,简单来说就是:系统在性能阈值范围内长时间运行的性能表现。即系统长时间运行,各项指标相对平稳,不会有很大的波动或者突刺。
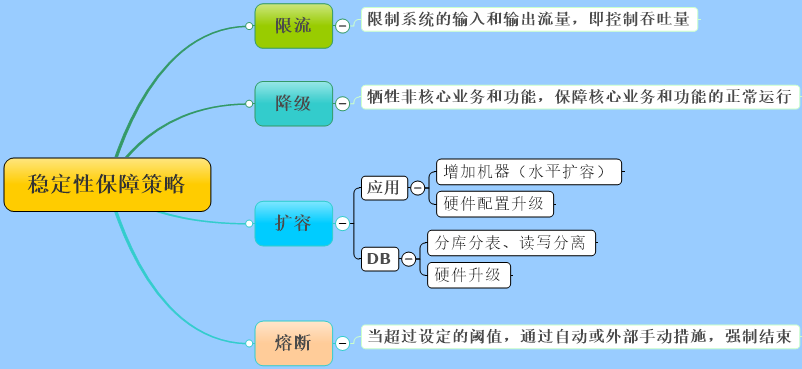
更多关于系统稳定性保障的策略,可以看这里:系统稳定性
最后,如何建立团队文化是个很抽象的问题,不同的研发流程、业务模式、工程师素养都是需要考虑的因素。
个人认为,可以通过设定统一的目标,明确每个岗位的职责,应该重点关注哪些方面,这样做有哪些价值,是否有正向的激励机制,提升沟通质量等手段,
长此以往,所谓的“团队文化”,也许就有了最适合自己的文化。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号