内存管理-UnpooledByteBufAllocator
Netty 是基于 Java 实现的,从分配的内存的位置来看,Allocator 分为 Heap (JVM 堆)和 Direct (直接内存)两种;从内存管理方式上来看池化(PooledByteBufAllocator)和非池化(UnpooledByteBufAllocator)两大类。因为池化的比较复杂,所以先从简单的非池化入手去了解 Netty 的内存管理。
目标
- 了解 Netty UnpooledByteBufAllocator 非池化的 Allocator
- 了解 AtomicIntegerFieldUpdater 的用法
- 了解 Unsafe 类对数组以及内存的操作方法
- 学会 for + cas 的乐观锁用法
核心问题
UnpooledByteBufAllocator 顾名思义是不带池化的内存分配器,用于从堆上或直接内存上进行内存的分配和释放。那么带着以下问题去读代码:
- 堆上内存和直接内存怎样申请?
- 堆上内存和直接内存怎样释放?
示例代码:
public static void main(String[] args) { ByteBufAllocator allocator = UnpooledByteBufAllocator.DEFAULT; ByteBuf heapByteBuf = allocator.heapBuffer(); heapByteBuf.release(); ByteBuf directByteBuf = allocator.directBuffer(); directByteBuf.release(); }
代码阅读
heapByteBuf
首先看一下 heapBuffer 的申请:
public ByteBuf heapBuffer(int initialCapacity, int maxCapacity) { if (initialCapacity == 0 && maxCapacity == 0) { return emptyBuf; }
// check 空间是否够用 validate(initialCapacity, maxCapacity); // newHeapBuffer 创建 ByteBuf return newHeapBuffer(initialCapacity, maxCapacity); } protected ByteBuf newHeapBuffer(int initialCapacity, int maxCapacity) { /** * 1. 支持 Unsafe 则使用 InstrumentedUnpooledUnsafeHeapByteBuf * 2. 不支持则使用 InstrumentedUnpooledHeapByteBuf */ return PlatformDependent.hasUnsafe() ? new InstrumentedUnpooledUnsafeHeapByteBuf(this, initialCapacity, maxCapacity) : new InstrumentedUnpooledHeapByteBuf(this, initialCapacity, maxCapacity); }
从上面两段代码,引出了两个新的类 InstrumentedUnpooledUnsafeHeapByteBuf 和 InstrumentedUnpooledHeapByteBuf,那么这两个类有什么区别呢,为什么在环境支持 Unsafe 的时候优先使用 InstrumentedUnpooledUnsafeHeapByteBuf 呢?
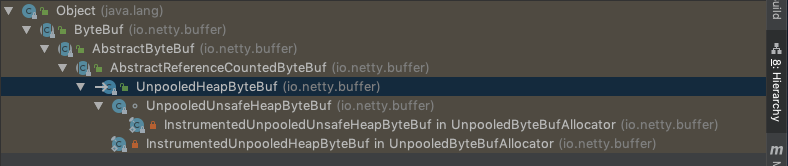
首先看下继承关系,非 Unsafe 的直接继承自 UnpooledHeapByteBuf,Unsafe 的继承自 UnpooledUnsafeHeapByteBuf, 但 UnpooledUnsafeHeapByteBuf 继承自 UnpooledHeapByteBuf。那么 UnpooledUnsafeHeapByteBuf Override 的内容就成了这两个类的重要区别所在了。重点分析两个方法:allocateArray 和 _getByte
UnpooledHeapByteBuf
public class UnpooledHeapByteBuf extends AbstractReferenceCountedByteBuf { ... byte[] allocateArray(int initialCapacity) { // 非常简单,直接在堆上搞了个 byte 数组 return new byte[initialCapacity]; } @Override protected byte _getByte(int index) { return HeapByteBufUtil.getByte(array, index); } ... } final class HeapByteBufUtil { // get 也非常简单,直接在 byte 数组里面通过下标索引 static byte getByte(byte[] memory, int index) { return memory[index]; } ... }
从上面代码可以看出,UnpooledHeapByteBuf 其实就是在 JVM 堆上直接 new 了一个 byte 数组,获取 byte 的时候,也是直接通过数组下标的方式从数组中读了出来。这个符合我们对 Heap 的基本认识,那么 Unsafe 不是这样做的吗?且往下看。
UnpooledUnsafeHeapByteBuf
class UnpooledUnsafeHeapByteBuf extends UnpooledHeapByteBuf { ... @Override byte[] allocateArray(int initialCapacity) { // 这里使用了 PlatformDependent, 这个类里面用到了 Unsafe 的方法绕过 JVM 直接操作内存 return PlatformDependent.allocateUninitializedArray(initialCapacity); } @Override public byte getByte(int index) { checkIndex(index); return _getByte(index); } @Override protected byte _getByte(int index) { return UnsafeByteBufUtil.getByte(array, index); } ... }
从上面的代码片段可以看出, Unsafe 的 Override 了 allcateArray 以及 _getByte,均使用了 Unsafe 的方式,细节如下:
final class UnsafeByteBufUtil { ... static byte getByte(byte[] array, int index) { return PlatformDependent.getByte(array, index); } ... } public final class PlatformDependent { ... static byte getByte(byte[] data, int index) { // 这里直接使用内存地址访问数组,而不是数组下标的方式 return UNSAFE.getByte(data, BYTE_ARRAY_BASE_OFFSET + index); } ... } final class PlatformDependent0 { ... // 这一步计算 byte[].class 数组类中0个元素的起始偏移量 BYTE_ARRAY_BASE_OFFSET = arrayBaseOffset(); static long arrayBaseOffset() { // 对象中成员变量的布局是由类确定的,因此通过类就可以获取偏移量 return UNSAFE.arrayBaseOffset(byte[].class); } ... }
由此可知,这里采用了 Unsafe 的方法直接操作 JVM 的内存地址的方式来获取数组中的元素,来进一步提高内存查询效率。
回到上面介绍的继承关系,我们可以知道不管是 Unsafe 的还是非 Unsafe 的都继承自 AbstractReferenceCountedByteBuf,因此这两种 ByteBuf 都会调用 AbstractReferenceCountedByteBuf 的初始化方法,而这个类是通过引用计数的方式来判断 ByteBuf 是否还在被引用的。下面介绍一下如何该类是如何实现引用计数的。
注:在 Netty 的编程中,引用计数是我们绕不过的话题,比如一个 ByteBuf 在线程1设置完成以后,线程 2 又要使用,那么就需要进行引用计数加 1,否则就会依赖线程 1 的释放时间来确保线程 2 使用该 ByteBuf 的时候,该 ByteBuf 还未释放
代码如下:
public abstract class AbstractReferenceCountedByteBuf extends AbstractByteBuf { private static final AtomicIntegerFieldUpdater<AbstractReferenceCountedByteBuf> refCntUpdater = AtomicIntegerFieldUpdater.newUpdater(AbstractReferenceCountedByteBuf.class, "refCnt"); // 相比于 Atomic 类型的变量,int 只是一个基本数据类型,占据 4 个字节,即每个 ByteBuf 中有一个 4 字节的 refCnt // 如果使用 Atomic 类型的变化,每个 ByteBuf 中会有一个 Atomic 类型的引用 4 个字节 + 这个引用指向的 Atomic 类型对象占据的空间,会比 int 大很多 private volatile int refCnt = 1; ... private ByteBuf retain0(int increment) { // 循环 + CAS 实现乐观锁,也可以叫做无锁 for (;;) { int refCnt = this.refCnt; final int nextCnt = refCnt + increment; // Ensure we not resurrect (which means the refCnt was 0) and also that we encountered an overflow. if (nextCnt <= increment) { throw new IllegalReferenceCountException(refCnt, increment); } if (refCntUpdater.compareAndSet(this, refCnt, nextCnt)) { break; } } return this; } ... private boolean release0(int decrement) { for (;;) { // 减之前先赋值,因为 volatile 只有可见性,没有原子性,不赋值,可能会导致减多次 int refCnt = this.refCnt; if (refCnt < decrement) { throw new IllegalReferenceCountException(refCnt, -decrement); } if (refCntUpdater.compareAndSet(this, refCnt, refCnt - decrement)) { // refCnt == decrement 并且 CAS 成功,说明减完了,释放内存 if (refCnt == decrement) { deallocate(); return true; } return false; } } } ... }
Netty 的引用计数方案:使用 AtomicIntegerFieldUpdater refCntUpdater 和 volatile refCnt 来完成引用计数的功能。
- 为什么不使用 Atomic 原子变量呢?因为 refCnt 占用内存更小 4 个字节,而 Atomic 是一个对象,需要对象头 + 对象体,并且需要一个引用,占用字节数比较多。refCntUpdater 是类的公共变量,因此是属于类的,不是每个对象一个。
- retain0 和 release0 是典型的通过 cas 实现乐观锁的用法, 循环 + cas。
释放操作非常简单,直接 release 了,没有引用以后,会被 JVM 回收掉。
directByteBuf
有了 heapByteBuf 的基础,了解 directByteBuf 也就更加方便了。沿着代码读进来,会找到 InstrumentedUnpooledUnsafeNoCleanerDirectByteBuf:
private static final class InstrumentedUnpooledUnsafeNoCleanerDirectByteBuf { ... @Override protected ByteBuffer allocateDirect(int initialCapacity) { // 申请内存 ByteBuffer buffer = super.allocateDirect(initialCapacity); ((UnpooledByteBufAllocator) alloc()).incrementDirect(buffer.capacity()); return buffer; } ... @Override protected void freeDirect(ByteBuffer buffer) { int capacity = buffer.capacity(); // 释放内存 super.freeDirect(buffer); ((UnpooledByteBufAllocator) alloc()).decrementDirect(capacity); } ... }
申请和释放内存
final class PlatformDependent0 { ... static ByteBuffer allocateDirectNoCleaner(int capacity) { // 申请 direct 的内存,并且构造成 DirectByteBuffer return newDirectBuffer(UNSAFE.allocateMemory(capacity), capacity); } ... static void freeMemory(long address) { // 归还到直接内存 UNSAFE.freeMemory(address); } ... }
和 heapByteBuf 本质的区别就是内存的来源不同,directByteBuf 内存来源为不受 JVM 管理的直接内存,因此并不受 gc 的控制,使用完以后必须通过 Unsafe 的 freeMemory 方法归还到进程的直接内存,否则会有内存泄漏。
其余部分基本是一致的。
小练习
下面的可以用于加断点,了解内部实现。
public static void testUnpooled() { ByteBufAllocator allocator = UnpooledByteBufAllocator.DEFAULT; ByteBuf heapByteBuf = allocator.heapBuffer(); heapByteBuf.release(); ByteBuf directByteBuf = allocator.directBuffer(); directByteBuf.release(); } public static void testUnsafeArray() { byte[] bytes = PlatformDependent.allocateUninitializedArray(10); int index = 5; bytes[index] = 'c'; int offset = UNSAFE.arrayBaseOffset(byte[].class); int offset2 = UNSAFE.arrayBaseOffset(int[].class); System.out.println(offset); System.out.println(offset2); int indexScale = UNSAFE.arrayIndexScale(byte[].class); byte c = UNSAFE.getByte(bytes, offset + indexScale * index); System.out.println(c); } public static void testUnsafeDirect() { long address = UNSAFE.allocateMemory(10); UNSAFE.putInt(address, 5); int value = UNSAFE.getInt(address); System.out.println(value); }
Ref
https://tech.meituan.com/2019/02/14/talk-about-java-magic-class-unsafe.html
//返回数组中第一个元素的偏移地址 public native int arrayBaseOffset(Class<?> arrayClass); //返回数组中一个元素占用的大小 public native int arrayIndexScale(Class<?> arrayClass);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号