面试题综合
零基础测试开发考核体系:
Python知识:
1、字典排序使用到的函数具体是哪个?举例说明
字典排序用到的具体函数是sorted(),它可以根据key值和value值来排序
#先创建一个字典 dict{'key':'value','key':'value',.......}
dict1={'name':'lyl','age':'18'}
#sorted()默认是对字典的键,对所有对象进行排序操作,从小到大进行排序,这个单词本身就是排序的意思
print('根据key值排序:',dict(sorted(dict1.items(),key=lambda item:item[0])))
print('根据value值排序:',dict(sorted(dict1.items(),key=lambda item:item[1])))
结果如下图:

2、字符串格式化使用到的关键字是哪个,举例说明
format()接受不限个参数,位置可以不按顺序
例一:
site1 = {"name": "admin", "passwd": "123456"}
print("用户名:{name},密码:{passwd}".format(**site1))
结果如下图:

例二:
username=input("请输入用户名:\n")
age=int(input("请输入年龄:\n"))
print('my name is {0},and my age is {1}'.format(username,age))
print('my name is {username},and my age is {age}'.format(username=username,age=age))
结果如下图:

3、列表中append()与insert()的区别是什么?举例说明
append()是向列表的最后一位添加元素list1.append('value')
list1=[2,6,'ok',9,'你好','啊']
list1.append('嘿嘿')
print(list1)
结果如下图:

insert是按照索引位给列表添加元素.list1.insert(索引位,’value‘)
list1=[2,6,'ok',9,'你好','啊'] list1.insert(4,'哈哈') print(list1)
结果如下图:

4、列表与元组的区别是什么
list列表是可变的,而tuple刚好是不可变的,
5、查看一个对象的类型关键字是什么?查看对象的内存地址关键字是什么
查看一个对象的关键字是type()
查看对象的内存地址关键字是id()
6、怎么获取字符串的索引信息
str4="hi abcd"
print("获取a的索引信息:",str4[4])
结果如下图:

7、举例说明列表推导式的使用
列表推导式书写形式:[表达式 for 变量 in 列表] 或者 [表达式 for 变量 in 列表 if 条件]
list2 = [item for item in range(10) if item > 4] print(list2)
结果如下图:

8、当元组只有一个对象的时候,需要注意什么?
当tuple里面的对象并且只有一个的时候,记得需要加,如果不加的话,就不再是tuple的数据类型,二是字符串的数据类型。
9、怎么理解函数的返回值?
一个函数,不管是否写return的关键字,函数都是有它的返回值的,如果在定义的函数里面没有写return的关键字,那么函数的返回值为None,
如果写了,函数的返回值就是return后面的内容。同时需要说明的是一个函数, 可以有N个返回值。
10、怎么理解函数的动态参数
当形式参数的个数和类型不确定的时候使用
11、字符串与列表之间的互相转换
#字符串拆分split后,把str类型转为list类型
list_str="hello,CCC"
str_list=list_str.split(',')
print(str_list)
print(type(str_list))
结果如下图:

12、字符串的替换使用到的方法是?
字符串的替换使用到的方法是:replace()
str1="hello world"
print("把hello替换为CCC;", str1.replace("hello", "CCC"))
结果如下图:

13、怎么理解is,in,==
is 是比较两个对象的内存地址(隐含了类型与内容一致))
in 比较的是内容包含,也暗含了数据类型的比较,因为比较首先提前是数据类型是一致的(查看一个对象是否包含在另一个对象里面)
== 主要比较的是内容和具体的数据类型(类型与内容一致,那么两个对象是相等的)
14、使用os库编写一个文件的路径拼接
import os
'''获取当前的工程路径'''
def base_dir():
#os.path.dirname()去掉脚本的文件名,返回目录
return os.path.dirname(os.path.dirname(__file__))
def filePath(directory='data',fileName=None):
'''找到具体的文件路径'''
return os.path.join(base_dir(),directory,fileName)
15、怎么理解序列化与反序列化
序列化就是将python对象编码转化为json格式的字符串
反序列化就是将json格式的字符串解码为python数据对象
16、举例说明文件的a,w,r的模式
a:只能在文件里写;如果文件不存在,就会创建这个文件;如果文件已存在,不会覆盖存在的文件,只会在存在的文件里继续添加写的内容。
w:只能在文件里写;如果文件不存在,就会创建这个文件;如果文件已存在,会覆盖存在的文件
r:只能读文件;如果文件不存在,就报错
17、使用with上下文的模式来处理文件
with上下文,内部会进行文件的关闭处理
with open('log.txt','r',encoding='utf-8函数') as f:
print(f.read())
18、怎么理解编码与解码
编码:就是把str的数据类型转换成bytes的数据类型的过程,使用到的关键字是encode。
解码:把bytes的数据类型转换为str的数据类型的过程,使用到的关键字是:decode
19、使用datetime获取当前的时间
mport datetime
import time
print('获取当前时间:', datetime.datetime.now())
20、使用time等待5秒的时间(举例说明)
import time as t
t.sleep(5)
21、怎么理解装饰器
在很多程序都要修改一个内容时,使用装饰器可以一次性解决
22、怎么理解局部变量与全局变量
在函数里面定义的变量是局部变量,而在程序开始定义的变量是全局变量;全局变量的作用域是整个函数,而在局部变量的作用仅仅只是函数而已;
当全局变量和局部变量的名字一样的时候,在函数内部,局部变量是第一优先级,而在函数外,全局变量是第一优先级。
23、Java的继承与Python的继承有什么区别
Java的继承是多继承
Python的继承是单继承
24、如果子类重写了父类的方法,那么实例化子类后,调用重写后的方法,调用的是子类的方法还是父类的方法
当子类重写父类的方法后,子类实例化后,调用重写的方法,优先考虑的是子类的方法
继承里面的第一个原则:当实例化类后,子类对象调用的方法和父类里面的方法重名,优先考虑子类的方法(前提:单继承)
class Father(object): #父类(基类)
def __init__(self,name,age):
self.name=name
self.age=age
def show(self):
print('name is {0},and age is {1}'.format(self.name,self.age))
objWork=(name='lyl',age=18)
objWork.show()

当子类重写父类的方法后,子类实例化后:
class Father(object): #父类(基类)
def __init__(self,name,age):
self.name=name
self.age=age
def show(self):
print('name is {0},\nand age is {1}'.format(self.name,self.age))
objFather=Father(name='lyl',age=18)
objFather.show()
class Son(Father): #子类(派生类)继承父类(基类)
def __init__(self,name,age,salary): #继承父类并重写父类的方法
#super()的方法继承父类的实例属性
super().__init__(name,age)
#继承父类
#Person.__init__(self,name,age)和 super().__init__(name,age)效果一样
self.salary=salary
def show(self):
print('name is {0},\nand age is {1},\nand salary is {2}'.format(self.name,self.age,self.salary))
objSon=Son(name='lyl',age=18,salary=200.3)
#重新调用子类的show(),因为父类的满足不了子类
objSon.show()
子类调用父类之后,重写了父类的方法,最后优先考虑子类

Linux知识:
1、查看进程的命令
ps
2、查看端口的命令
lsof、netstat
3、赋予文件权限的关键字
chmod
4、r,w,x对应的数字是多少
r --> 4
w --> 2
x --> 1
5、给一个文件给rwx权限
chmod 421 文件名
6、git提交文件的命令是什么
git add 文件名
git commit -m " "
7、git创建仓库的命令是什么
git init
8、查看内存的命令
nmon
9、编辑文件的步骤
vim 文件名
a或者i 添加内容,保存退出
10、查看文件前5行的命令
head -n 5 文件名
11、查看文件后10行的命令
tail -n 10 文件名
12、文件查看命令
ls、cat 文件名
13、平均负载怎么查看
uptime
API知识:
1、HTTP的完整请求流程
客户端与服务端建立tcp连接;
客户端向服务端发送request请求;
服务端回复response响应客服端;
最后客户端和服务端建立tcp的连接。
2、怎么理解get和post请求
Get:获取资源
Post:发送请求
3、在postman中写断言的地方为?
Tests
4、怎么理解postman里面的collections
集合:是一个收集器,可以理解成一个测试项目,这个项目下添加需要测试的接口。
在postman中能够批量运行集合里面的测试用例,能够解决集合中的业务关联
5、动态参数在postman里面的解决思路,请使用步骤的方式描述出来
以书籍管理系统为例,我们先登录到书籍管理系统中,然后对此进行添加删除书籍的操作。首先我们需要先获取用例的书籍ID,然后将书籍ID设置为变量,
最后在删除书籍时调用这个变量。
6、在postman中,怎么调用变量
使用两个花括号调用变量。
7、接口断言需要是那方面
业务状态码
协议状态码
响应数据
8、怎么理解协议状态码:404
请求资源并不存在
9、如果一个接口访问时400,排查思路时什么?
(1)请求参数
(2)请求参数类型(例如int)
(3)特定类型(例如性别)
(4)请求头(缺少)
10、怎么理解同步通信
同步请求:客户端向服务端发送请求,服务端必须做出响应
缺点:客户端发送请求,服务端迟迟不作出回应
客户端发送的请求为计算量大或逻辑存在问题,请求就会堵塞,后面就会积压
11、怎么理解异步通信
在异步的交互中,客户端和服务端互相不需要关注对⽅的存在,只需要关注对应的MQ的消息,客户端与服务端的交互主要是会通过MQ的消息中间作为消息的传递来进⾏交互的。
12、怎么理解cookie,session,token
cookie请求:客户端发送登录请求,生成一个cookie凭证,服务端通过set-cookie把cookie再返给客户端,客户端再将请求头cookie带上返回的凭证发送给服务端。
session请求:客户端发送登录信息登录成功后生成session ID,set-cookie将session ID给客户端,请求头cookie带上session ID再给服务端。
token请求:本质上和session的原理差不多。用户登录系统生成token,每次生成的token都是随机的字符串,
cookie存储在客户端session、token存储在服务端都用来验证信息正确性
13、请按步骤的方式描述session的请求流程
已请求登录为例:
第一步:客户端发送登录请求信息,服务端生成sessionID
第二步:服务端将sessionID返回给客户端
第三步:客户端在cookie中带上sessionID发送给服务端,服务端核对sessionID的真确性
14、如果发送请求,协议状态码返回500的错误,怎么解决?
代码出错,查代码。(服务器出错)
15、怎么理解协议状态码和业务状态码
HTTP 状态码是 HTTP 协议的工程实现。如果服务器端的实现不符合协议的规定,我们可以认为 服务器的 HTTP 实现是错误的
业务状态码是服务端给出的关于业务描述的码,用于客户端明确得知本次请求的资源的状态情况
测试基础理论:
1、bug完整的生命周期
2、编写测试用例的要素是什么?
分别是:测试用例id,测试用例名称,测试用例的目的,测试用例环境,测试用例的前提,测试用例的步骤,测试用例的结果;
3、怎么理解黑合测试,白盒测试?
黑盒测试(从用户的角度出发),它是通过测试来检测每个功能是否都能正常使用。在测试中,把程序看作一个不能打开的黑盒子,在完全不考虑程序内部结构和内部特性的情况下,
在程序接口进行测试,它只检查程序功能是否按照需求规格说明书的规定正常使用,程序是否能适当地接收输入数据而产生正确的输出信息。黑盒测试着眼于程序外部结构,不考虑内部
逻辑结构,主要针对软件界面和软件功能进行测试。
白盒测试,白盒测试又称结构测试、透明盒测试、逻辑驱动测试或基于代码的测试。白盒测试是一种测试用例设计方法,盒子指的是被测试的软件,白盒指的是盒子是可视的,即清楚
盒子内部的东西以及里面是如何运作的。"白盒"法全面了解程序内部逻辑结构、对所有逻辑路径进行测试。"白盒"法是穷举路径测试。在使用这一方案时,测试者必须检查程序的内部结构,
从检查程序的逻辑着手,得出测试数据。
4、测试按阶段划分,主要分为那几个阶段
主要分为:单元测试,集成测试,系统测试,验收测试;
5、怎么理解等价类和边界值
等价类分为有效等价类和无效等价,而边界值是作为等价类的补充说明,例如:一年有12个月,有效等价类是1-12,无效等价类是大于12,小于1的数字,
6、请描述一个完整的测试流程
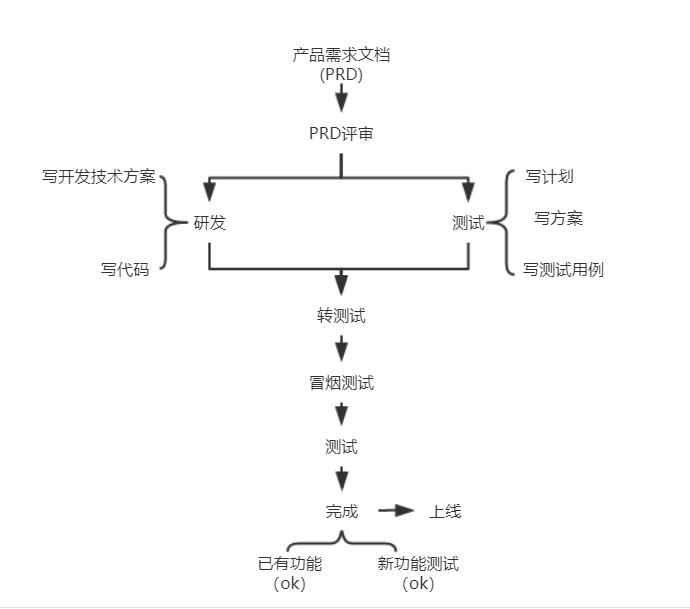
UI自动化测试:
1、常用的元素定位有那几种方法,请举例说明
常用的元素定位得方法有八种,(1)其中有七种是单元素定位,如:ID、NAME、CLASS-NAME、XPATH、CSS-SELECTOR、LINK-TEXT、PARTIAL-LINK-TEXT;
(2) 还有一种是多元素定位,如:TAG-NAME
比如:百度搜索框,
(1)通过id来定位搜索框;
from selenium import webdriver
from selenium.webdriver.common.by import By
import time as t
'''通过ID来定位'''
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
driver.find_elements_by_id('kw').send_keys("hello world")
t.sleep(5)
(2)、通过name来定位;
from selenium import webdriver
from selenium.webdriver.common.by import By
import time as t
'''通过name来定位'''
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
driver.find_element_by_name('wd').send_keys("hello world")
t.sleep(5)
(3)、通过class_name来定位;
from selenium import webdriver
from selenium.webdriver.common.by import By
import time as t
'''通过class_nam来定位'''
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
driver.find_element_by_class_name('s_ipt').send_keys("hell world")
t.sleep(5)
(4)、通过xpath来定位;
from selenium import webdriver
from selenium.webdriver.common.by import By
import time as t
'''通过xpath的定位方式'''
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
#先定位到需要的代码行处,鼠标右键copy——>copy Xpath
driver.find_element_by_xpath('//*[@id="kw"]').send_keys("hell world")
t.sleep(5)
(5)、通过css_selector来定位;
from selenium import webdriver
from selenium.webdriver.common.by import By
import time as t
'''通过css_selector来定位'''
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
#先定位到需要的代码行处,鼠标右键copy——>copy css_selector
driver.find_element_by_css_selector('#kw').send_keys("hell world")
t.sleep(5)
(6)、通过link_text来定位;
from selenium import webdriver
from selenium.webdriver.common.by import By
import time as t
'''通过LINK_TEXT来定位(精准定位)'''
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
driver.find_element_by_link_text('直播').click()
t.sleep(5)
(7)、通过partial_link_text来定位;
from selenium import webdriver
from selenium.webdriver.common.by import By
import time as t
'''通过PARTIAL_LINK_TEXT来定位(模糊定位)'''
driver=webdriver.Chrome()
driver.get('http://www.baidu.com')
driver.find_element_by_partial_link_text('播').click()
t.sleep(5)
(8)、通过tag_name来定位;
from selenium import webdriver
from selenium.webdriver.common.by import By
import time as t
'''通过tag_name来定位(多个元素定位的方式)'''
driver=webdriver.Chrome()
driver.get("http://www.baidu.com")
tag=driver.find_elements_by_tag_name('input')
tag[7].send_keys('hello world')
t.sleep(5)
driver.quit()
2、单个元素定位与多个元素定位的区别是什么?
(1)单元素定是按照元素属性定位的。
(2)多元素定位的结果是以列表的形式呈现的,是按照列表的来定位到具体元素的索引。
3、如果是iFrame的框架,如何来定位里面的元素属性的对象
需要先调用switch_to.frame()的方法通过索引或者ID的方式进入框架里面,然后再定位元素属性。
4、怎么理解页面对象设计模式
页面对象设计模式:每个页面都建对应的class,类中包含了页面的输入框、标题、元素等元素,测试代码中测试这个页面时,只需要调用这个页面类(页面对象)里的页面元素即可,这样实现了将测试对象(页面对象)和测试脚本(用例脚本)分离,如果元素ID等发生变化时,不需要去修改测试代码,只需要在页面类中修改即可,利于维护所有脚本。
5、怎么理解显式等待和隐式等待
(1)显示等待:显示等待是单独针对某个元素,设置一个等待时间如5秒,每隔0.5秒检查一次是否出现,如果在5秒之前任何时候出现,则继续向下,超过5秒尚未出现则抛异常
element = WebDriverWait(driver,5,0.5).until(EC.presence_of_element_located(By.ID,‘kw’))
element.sendkeys("xxx")
(2)隐式等待:隐式等待是全局的是针对所有元素,设置等待时间如10秒,如果10秒内出现,则继续向下,否则抛异常。可以理解为在10秒以内,不停刷新看元素是否加载出来。
driver.implicitly_wait(10)
6、在测试中遇到多窗口,具体怎么解决,请描述具体的步骤和编写具体的案例代码
比如在网易邮箱界面,我们需要注册一个新的帐户,首先我们需要进入到网易邮箱的登录界面,然后通过XPATH或者LINK-TEXT的方式来获取注册网易邮箱的元素定位,这时就出现了多窗口的情况,我们需要先获取当前注册网易邮箱的窗口,然后再获取所有的窗口,循环所有的窗口,再判断是否当前的窗口是否是点击注册网易邮箱后跳转后的注册网易免费邮箱窗口,进入这个窗口,再获取当前窗口的地址,断言后退出。
#导入webdiver
from selenium import webdiver import time as t #打开浏览器Chrome driver=webdriver.Chrome() #窗口最大化 driver.maximize_window() #获取网易邮箱地址,打开网易邮箱页面 driver.get('https://mail.163.com/') #进入iframe框架 driver.switch_to.frame(0) #缓冲两秒的时间 t.sleep(2) #获取注册网易邮箱界面 now=driver.current_window_handle #定位网易邮箱元素并点击注册网易邮箱 diver.find_element_by_link_text('网易邮箱注册').click() #获取所有的窗口 all=driver.window_handles #循环所有的窗口 for handler in all: #判断当前窗口(是不是点击网易邮箱后跳转的注册网易免费邮箱界面) if handler!=now: #进入当前窗口 driver.switch_to.window(handler) #获取当前窗口得地址 url=driver.current_url print(url.endswith('utm_source=163mail')) #断言,如果是当前窗口,执行代码后返回一个Ture值 assert=url.endswith('utm_source=163mail')==True #缓冲两秒的时间 t.sleep(2) #退出 driver.quit()
单元测试框架:
1、unittest与pytest的框架

2、unittest的常用组件有哪些
常用的组件有:测试固件(TestFixture),测试用例(TestCase),测试执行(TestRun),测试套件(TestSuit),测试报告(TestReport)
3、unittest中怎么理解测试固件
测试固件:用于处理初始化操作
4、怎么理解setUp(),tearDown()与类测试固件的测试
一种是每执行一个测试用例,测试固件都会被执行到;
另一种就是不管有多少测试用例,测试固件只执行一次;
5、在unittest测试框架中,加载所有的测试模块使用到的方法是什么?具体参数是什么?
加载所有模块使用的方法是discover()。
具体的参数一共有三个:第一个参数是start_dir是测试模块的路径,存放在testCase包中;(start_dir=os.path.dirname(_file_))
第二个参数是pattern用来获取testCase包中所有以test开头的模块文件 (pattern='test_*.py')
第三个参数是top_level_dir在调用的时候直接给默认的None值 (top_level_dir=None)
6、在unittest中使用那个库来生成对应的测试报告
使用的库是:HTMLTestRunner
7、一个完整的测试用例包含哪些步骤
拿到测试用例——>分析测试需求——>编写测试用例——>划分优先级
8、怎么理解参数化
在一个测试点有多个测试用例的情况下,会使用参数化parameterized,参数化是先循环列表里的值,然后再把param元组里面的值赋给
测试方法里面对应的参数
9、一个完整的自动化测试用例包含哪些?
1、 初始化 2、 测试步骤 3、断言 4、清零
10、测试用例之间可以依赖吗?
不能依赖,每个测试用例都需要独立存在

 浙公网安备 33010602011771号
浙公网安备 33010602011771号